2023年は「Cloud Run を触って覚える」をテーマとした一人アドベントカレンダーを一人で開催しており、Cloud Run のさまざまな機能や、Cloud Run でよく使う構成などを実際の使い方と一緒にご紹介しています。
14日目は Cloud SQL にプライベート接続する方法についてご紹介します。Cloud Run から VPC 内のリソースにプライベート接続する方法は、今年 (2023年) にプレビューで提供を開始した「ダイレクト VPC 下り (外向き)」を使います。
Cloud Run の概要は技術評論社さまのブログ「gihyo.jp」に寄稿した記事で解説していますのでこちらもぜひご覧ください。
Cloud SQL にプライベート接続する方法
まず、Cloud Run サービスから Cloud SQL にプライベート接続するにはどのような構成になるか解説します。
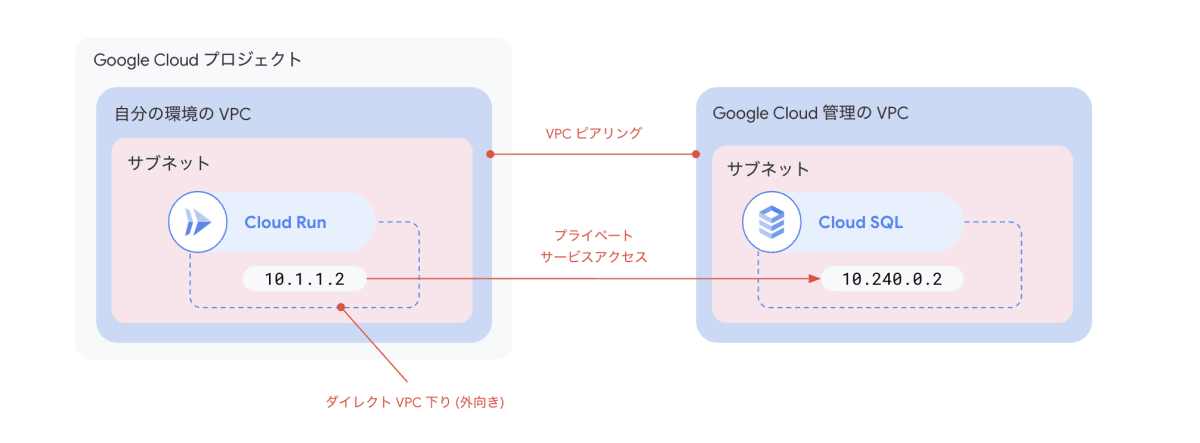
Cloud SQL へのプライベート接続
まず Cloud SQL インスタンスのプライベート接続について見てきましょう。
Cloud SQL インスタンスは Google Cloud が管理する VPC ネットワーク内に作成されます。このインスタンスを自分の環境 (Google Cloud プロジェクト) の VPC からアクセスできるようにするには、Google が管理する VPC と自分の VPC を VPC ピアリングする形で実現しています。これを プライベート サービス アクセス と呼びます。
プライベート サービス アクセスを使って自分の環境の VPC 内から Cloud SQL インスタンスに対してプライベート接続ができるようにした上で、Cloud Run サービスからは VPC 内のリソースに接続するための構成を用意する必要があります。具体的な方法は次の記事で紹介しています。
「サーバーレス VPC アクセス」と「ダイレクト VPC 下り (外向き)」のいずれかの方法によって接続できます。この記事では「ダイレクト VPC 下り (外向き)」を使って接続する手順を紹介します。
Cloud SQL インスタンスの準備をする
Cloud SQL インスタンスを準備しましょう。この節では、Cloud SQL インスタンスの作成とデータベースの作成を行います。
Cloud SQL インスタンスを作成する
まずは Cloud SQL のコンソールを開きます。
[インスタンスを作成] をクリックします。

インスタンスの作成
[データベース エンジン] は [PostgreSQL] を選択します。

PostgreSQL の選択
[インスタンス ID] は quickstart にします。[パスワード] は [生成] をクリックすると、ランダムなパスワードが生成されます。

インスタンス ID とパスワード
[Cloud SQL エディションの選択] では [Enterprise Plus] がデフォルトで選択されていますが [Enterprise] に変更します。

Cloud SQL エディションの選択
[エディションのプリセット] を使うと、CPU やメモリなどの設定について、ユースケースに合ったデフォルト値を一括で設定できます。Cloud SQL は様々な設定項目がありますが、ユースケースに合わせてざっくりクイックに設定することができ便利です。ここでは [サンドボックス] を選択します。

エディションのプリセット
[リージョン] は asia-northeast1 (東京) を、[ゾーンの可用性] は [シングルゾーン] のままにします。

リージョンとゾーン
Cloud SQL はデフォルトでパブリック IP のみが設定されるようになっているため、プライベート IP のみを許可するように設定します。[インスタンスのカスタマイズ] の [構成オプションを表示] をクリックして展開し、[接続] の [インスタンス IP の割り当て] の [プライベート IP] にチェックを付けます。[ネットワーク] は default を選びます。

プライベート IP の設定
プライベート サービス アクセスを設定します。[接続を設定] をクリックします。

プライベート サービス アクセスの接続設定
Service Networking API を有効化する必要があるので [API を有効化する] をクリックします。

Service Networking API を有効化
Cloud SQL インスタンスに割り当てる IP 範囲を設定します。細かい要件が特になければ [自動的に割り当てられた IP 範囲を使用する] が簡単です。/20 の IP 範囲を自動的に割り振るようになります。選択し、[続行] をクリックします。

IP 範囲の設定
[接続] をクリックし、設定を完了します。接続を作成するまでには数分かかります。

プライベート サービス アクセスの接続設定の完了
接続の作成が完了すると、プライベート サービス アクセスの設定が正常に作成できていることが確認できます。

プライベート サービス アクセスの確認
最後に最下部までスクロールし [インスタンスを作成] をクリックします。

インスタンスの作成
Cloud SQL インスタンスが作成されるまでには数分かかります。数分後、インスタンスの作成が正常に完了していることを確認します。
インスタンスの確認
データベースを作成する
次に、Cloud Run サービスで使用するデータベースを作成します。
Cloud SQL インスタンスの作成後に表示されている詳細画面の [データベース] メニューを開き [データベースの作成] をクリックします。

データベースの作成
[データベース名] は db にします。

データベース名の設定
以上でデータベースの準備は完了です。
Cloud Run サービスを作成する
次に Cloud SQL に接続する Cloud Run サービスを作ります。
この記事では Node.js のサンプルアプリをデプロイします。Web アプリケーション フレームワークとして Express を、OR マッパーとして Prisma を使用します。
サンプル アプリケーションのコンテナ イメージを作成する
Prisma のサンプルとして公開されているアプリ テンプレートを使用します。テンプレートはたくさん用意されていますが、今回はその中からシンプルな Express アプリケーションである rest-express を使います。
try-prisma というパッケージを使うと、テンプレートを元にしたアプリ プロジェクトを生成できます。
まずは Cloud Shell を起動し、次のコマンドを実行します。
npx try-prisma@latest --template typescript/rest-express
作成するアプリのセッティングを対話形式で行います。ここでは quickstart という名前にしました。
? Should we automatically install packages for you? No
? What should the project be named? quickstart
? Where should the new folder be created? .
アプリが作成できたら、アプリ プロジェクトのディレクトリに移動します。
cd quickstart
prisma/schema.prisma ファイルを開き、データベースの接続先 URL を DATABASE_URL 環境変数から設定するように修正します。
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
package.json にマイグレーション用のコマンドと起動用のコマンドを追加します。下記は package.json の一部です。scripts に start と migrate を加えます。
本来であればマイグレーションは Cloud Run サービスのデプロイ前に行ったほうが良いですが、今回は簡易的に行う予定のため Cloud Run のコンテナ インスタンスからマイグレーションが行えるようにしておきます。
"scripts": {
"start": "ts-node src/index.ts",
"migrate": "prisma migrate deploy && yarn start",
"dev": "ts-node src/index.ts"
}
デプロイの前に、ローカルで一度マイグレーションを実行し、マイグレーションファイルを作成しておく必要があります。
ローカルで PostgreSQL のコンテナを起動します。
docker run --name postgres -e POSTGRES_PASSWORD=postgres -p 5432:5432 -d postgres:15.4
DATABASE_URL の環境変数をローカルで起動した PostgreSQL のコンテナに向けるように設定した上でマイグレーションを実行します。正常に終了すると prisma/migrations 配下にマイグレーションごとのフォルダと sql ファイルが作られます。
export DATABASE_URL=postgresql://postgres:postgres@localhost:5432/db
npx prisma migrate dev --name init
次に、コンテナとしてデプロイできるよう Dockerfile を追加します。
FROM node:20
WORKDIR /app
COPY . .
RUN npm install
EXPOSE 3000
CMD ["npm", "start"]
次のコマンドでコンテナ イメージをビルド・プッシュします。
gcloud builds submit --region=asia-northeast1 --tag gcr.io/PROJECT_ID/quickstart .
以上でコンテナ イメージの準備が終わりました。
Cloud Run サービスを作成する
次に Cloud Run サービスを作成します。Cloud Run のコンソールに移動し [サービスの作成] をクリックします。

サービスの作成
Cloud Run サービスの基本的な設定は こちらの記事 で紹介していますので、この記事では割愛しつつ Cloud SQL への接続に必要な設定にフォーカスしてご説明します。
コンテナ イメージは先ほどプッシュしたものを選択します。

コンテナ イメージの設定
[コンテナ、ボリューム、ネットワーキング、セキュリティ] を展開します。[コンテナ ポート] を 3000 に変更します。

コンテナ ポートの変更
[コンテナ コマンド] に yarn migrate を設定します。この設定によって、Dockerfile に記載してある CMD が上書きされます。このリビジョンではマイグレーションとアプリケーションの起動が行われるようになります。

コンテナ コマンドの変更
[変数とシークレット] タブに移動し、環境変数を設定します。[変数を追加] をクリックし DATABASE_URL を設定します。
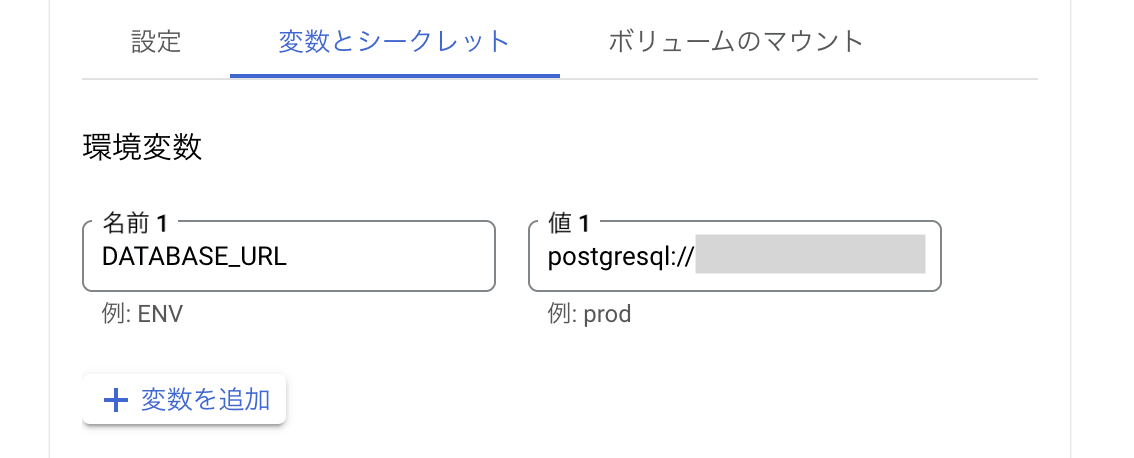
環境変数の追加
CloudSQL に接続可能な URL のスキーマは次のとおりです。
postgresql://USER:PASSWORD@localhost/DB_NAME?host=/cloudsql/PROJECT_ID:REGION:INSTANCE_NAME
それぞれ次のように設定します。
| 項目 | 値 |
|---|---|
USER |
PostgreSQL のユーザー名 |
PASSWORD |
USER に指定したユーザーのパスワード |
DB_NAME |
データベース名 (ここでは db になる) |
PROJECT_ID |
Google Cloud プロジェクト ID |
REGION |
Cloud SQL のリージョン |
INSTANCE_NAME |
Cloud SQL のインスタンス名 |
ここでは簡易的に環境変数として設定していますが、パスワードが含まれるので Secret Manager を併用してシークレットとして管理した方が適切です。設定方法は割愛しますが、具体的な手順は こちら を参照してください。
次に [Cloud SQL 接続] の [接続を追加] をクリックし、接続する Cloud SQL インスタンスを設定します。

Cloud SQL 接続の追加
上記を設定する上で [Cloud SQL Admin API] を使うため、まだ有効化していなければ有効化します。

Cloud SQL Admin API の有効化
次に [ネットワーキング] のタブを開きます。
[アウトバウンド トラフィック用の VPC に接続する] で [VPC に直接トラフィックを送信] を選びます。[ネットワーク] と [サブネット] は Cloud SQL と同じ VPC、サブネットを設定します。

以上で設定は終わりです。[作成] をクリックするとデプロイされます。
試す
実際に Cloud Run サービスを実行して見ましょう。curl で呼び出してみると実際にデータが保存できていることが確認できます。サンプル アプリケーションの API は README から確認できます。
POST /signup でユーザーを作成します。
curl \
-X POST \
-H "content-type: application/json" \
-d '{"name": "Example User", "email":"example@example.com"}' \
https://<RUN_URL>/signup
作成したユーザーが返却されます(確認しやすいように整形しています)。
{
"id":1,
"email":"example@example.com",
"name":"Example User"
}
POST /post で投稿できます。
curl \
-X POST \
-H "content-type: application/json" \
-d '{"title":"サンプル","content":"本文","authorEmail":"example@example.com"}' \
https://<RUN_URL>/post
作成した投稿が返却されます(確認しやすいように整形しています)。
{
"id":1,
"createdAt":"2023-12-14T19:54:09.754Z",
"updatedAt":"2023-12-14T19:54:09.754Z",
"title":"サンプル",
"content":"本文",
"published":false,
"viewCount":0,
"authorId":1
}
まとめ
Cloud Run と Cloud SQL を組み合わせた構成は汎用性が高いので、利用する機会も多いと思います。
「Cloud Run から VPC 内のリソースへの接続」と「Cloud SQL へのプライベート接続」の両方を構成しなければいけませんが、この記事がそれらの構成の理解の一助になれば幸いです。
マイグレーションの部分など本題とはずれる箇所は省略していますが、それはまた別の機会に解説できればと思います。

Discussion