この記事は Google Cloud Japan Advent Calendar 2022 の 13 日目の記事です。

2022 年は本番環境で Cloud Run を利用した事例を良く見た 1 年でした。新機能のリリースだけでなく、CPU やメモリの選択肢が増えたのも印象的です。
ところで、Cloud Run を構築するのに、何を使っていますか?gcloud CLI でデプロイする、または、Terraform で定義して CI 環境から実行するのも、管理がしやすく良いと思います。
一方、初めて Cloud Run を触る時や、細かいオプションを確認したい時など、コンソール画面で操作するのも見やすくて良いですね。
ということで、今回は Cloud Run コンソール画面でサービスを作成する際の設定項目を 1 つずつ解説していきます!Cloud Run にはバッチ用途のジョブ(Cloud Run jobs)がありますが、そちらについては、以前書かれたブログも参照してみてください。
また、1 つ 1 つ詳細に触れることで難しそうに見えるかもしれないですが、Cloud Run は高速にコンテナアプリをデプロイすることができます。最初はサンプル コンテナで試すとイメージしやすいと思います。
Cloud Run サービス(services)の作成
Cloud Run のコンソール画面にある、以下のボタンからサービスを作成します。

サービスは固有のエンドポイントを公開し、受信リクエストを処理するため、基盤となるインフラストラクチャを自動的にスケールします。サービス名とリージョンは後で変更できません。

実行するコードの指定
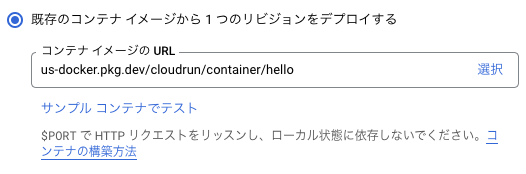
コンテナ イメージを指定する
サービスで利用するコンテナ イメージが既にビルド済みで、Artifact Registry、または Container Registry に登録されているのであれば、それを指定するだけです。試すだけであれば、サンプルのコンテナ イメージも用意されています。
ソース リポジトリから新しいリビジョンを継続的にデプロイする
コンテナ イメージをまだ登録していない、または、Cloud Build を利用した CI/CD も同時に構築したい場合、このオプションを利用すると便利です。
Cloud Build による継続的デプロイを使用すると、ソース リポジトリに対する変更をトリガーに Container Registry へコンテナ イメージが自動的に push され、Cloud Run にデプロイされます。
まず、連携先の Git リポジトリ プロバイダと、対象リポジトリを指定します。この画面で設定できるのは以下 3 つです(Cloud Build として設定可能なトリガーは、他にもいくつか存在します)。
- Cloud Source Repositories
- GitHub(Cloud Build GitHub アプリ、または Cloud Source Repositories にミラーリング)
- Bitbucket(Cloud Source Repositories にミラーリング)
その後、Build Configuration として、ブランチと Build Type を指定します。

-
ブランチ
正規表現で指定します。デフォルトでは、main ブランチに完全一致する形で定義されているため、他ブランチを利用する場合は編集する必要があります。 -
Build Type
-
Dockerfile
Dockerfile の path を指定し、定義に従ってビルドされます。リポジトリ直下に Dockerfile がある場合、定義は/Dockerfileとなります。 -
Go、Node.js、Python、Java、.NET Core、Ruby(Google Cloud Buildpacks を使用)
(対応言語に制限がありますが)Dockerfile が無くても、コードから推測してビルドを行う OSS を利用します。Dockerfile のメンテをしたくない方は、こちらを採用するのも良いかもしれません。
-
Cloud Run サービス名
同一プロジェクトのサービス名は、リージョン内でユニークである必要があります(別リージョンであれば名前被りは OK)。サービス名を見るだけで、どういったアプリケーションなのか推測できる名前が良いでしょう。
リージョン
サービスを提供する地域に近いリージョンを選択しましょう。
日本であれば asia-northeast1(東京) と asia-northeast2(大阪) が選択可能です。
CPU の割り当てと料金
Cloud Run には、CPU の割り当てに 2 つの選択肢があります。Cloud Run の費用の多くは CPU と Memory を利用している時間に応じてかかってきます(無料枠もあります)が、その割り当て方式が、リクエストベースなのか、時間ベースなのか、といった違いになります。料金の詳細についてはこちらをご参照ください
1. リクエストの処理中にのみ CPU を割り当てる
リクエストを受信したら CPU を割り当て、レスポンスを返したら解放します。
リクエストが全くない時間は Cloud Run サービスに料金はかかりません。管理画面の用途や、リクエスト数が時間によって偏る(深夜には全くリクエストが来ない、など)場合、こちらの方がコストが最適化される場合が多いです。

2. CPU を常に割り当てる
リクエストがない時間帯でも CPU が常に割り当てられます。そのため、レスポンスを返した後に非同期でバックグラウンド処理を実行する、などの処理が可能になります。
Cloud Run の自動スケーリングは引き続き有効であり、受信トラフィックの処理に必要ないコンテナ インスタンスは停止できます。リクエスト処理後 15 分を過ぎるとインスタンスのアイドル状態は解除されるため、15 分以上常にアクティブ状態で CPU を割り当てる場合、後述の最小インスタンス数も指定することで有効化できます。
リクエストが無い時間帯でも料金計算の対象となりますが、時間あたりの単価は 1 のリクエスト ベースよりも安くなっています。そのため、常にリクエストがくるようなユースケースであれば、こちらの割り当て方式の方がコストパフォーマンスが良くなる可能性があります。

自動スケーリング
Cloud Run サービスは、設定項目やリクエストを処理するインスタンスの CPU 使用率に基づいて自動スケーリングが行われます。ここでは、自動スケーリングの最小値と最大値を設定します。
インスタンスの最小数(min=0)
この値を 1 以上にすることで、コンテナ インスタンスをゼロスケール(下図の Cold 状態)せずに、設定値だけアイドル状態で維持させることができます。これにより、トラフィックの急増時などで発生する、コールド スタートを緩和させることができます。
待機中のコンテナ インスタンス(下図の Warm 状態)にかかる CPU の料金は、稼働中(active)と比べておよそ 1 割程度になります。かかる費用と、応答時間のレイテンシのバランスを考えて設定しましょう。
(最小インスタンスが 0 の場合でも、Go や Python のような軽量言語で実装されていればコンテナ起動は非常に高速です)

インスタンスの最大数(max=1000)
最小数とは反対に、スケールする最大値を制限します。
これは、コストをある程度制限したい場合や、コンテナ インスタンス(≒ アプリ)が MySQL / PostgreSQL への接続でコネクション プーリングを利用する場合、プール数を一定数以下に制限したい、といった観点で考慮すべき値です。
制約がなく、スケール性能を優先で考えると、上限である 1000 を指定すると良いでしょう。
Ingress
Cloud Run でサービスを作成すると、外部に公開されるドメイン(https://xxxxx.a.run.app)が必ず払い出されます。開発者体験として非常に便利ですが、外部アクセスは Cloud Load Balancing を通したい場合や、内部からのアクセスで十分な場合に外部からのアクセスを受け付けないようにしたい、などネットワーク アクセスを制限する必要があることもあります。
選択肢として下記 3 つがあります。
1. すべてのトラフィックを許可する
デフォルトの設定です。払い出された Cloud Run サービスの URL に、外部から直接アクセス可能なため、開発者はコンテナ アプリをデプロイするだけで簡単にサービスを公開することが出来ます。
2. 内部トラフィックと Cloud Load Balancing からのトラフィックを許可する
公開する Cloud Run サービスに対し、WAF の機能で IP 制限をかけたり DDoS 対策を行いたい場合があります。それは Cloud Load Balancing で設定可能な Cloud Armor を連携することで、実現可能です。
Cloud Load Balancing のバックエンド サービスとして Cloud Run を設定する(厳密には Serverless NEG を指定しますが、Cloud Run サービスと 1 対 1 の関係なので、ほぼ Cloud Run サービスと同義)ことで、LB に流れてきたトラフィックを Cloud Run サービスへ流すことが可能です。
また、Cloud Load Balancing をトラフィックの入り口とすることで、ホストやパスベースで複数の Cloud Run サービスへルーティングすることも可能です。
この場合、Cloud Run サービスに直接リクエストが来てしまうと、Cloud Load Balancing で設定した機能を通すことが出来なくなってしまいます。そのため、トラフィックの入り口を Cloud Load Balancing と内部トラフィックに制限する、というのがこの設定になります。

Cloud Load Balancing を統合する場合は、必ずこの設定を選択しましょう。
3. 内部トラフィックのみを許可
サービスの呼び出し元が外部エンドユーザーでない場合にこちらを選択します。内部とは、Google Cloud の VPC からや、内部ロードバランサーや Private Service Connect 経由、そして Google Cloud の下記プロダクトからのアクセスを指します。
VPC 内やオンプレ環境のアプリ、上記 Google Cloud プロダクトからのリクエストを受け付けるサービスは、アクセス範囲を最小にするために、こちらの設定をしておきましょう。

認証
Cloud Run サービスへアクセスする呼び出し元に、認証を要求するかどうかを選択する設定です。呼び出し元のユーザーが、Cloud Run サービスを呼び出す権限があるかどうかの認可も行われます。
1. 未認証の呼び出しを許可
認証なしでエンドポイントを公開する場合、こちらを指定します。
2. 認証が必要
Cloud IAM を使用して承認済みユーザーだけがアクセス可能になります。

呼び出し元はユーザーだけでなく、サービスアカウントも同様です。
Cloud Scheduler や Pub/Sub などを呼び出し元に設定する場合や、Cloud Run でサービス間通信を行う場合、呼び出し元に設定したサービスアカウントに対し、呼び出し先サービスを実行できる権限として roles/run.invoker ロールを付与します。
Cloud Run サービス作成後の設定になりますが、コンソール画面だと、Cloud Run サービス一覧画面でサービスを選択し、右にある「情報パネルを表示」から設定することができます。プリンシパルの追加 で該当サービスアカウントを入力し、Cloud Run 起動元 ロールを付与しましょう。

コンテナ
アプリが実行するコンテナ インスタンスに対する設定をします。
全般
コンテナポート
デフォルトで 8080 ポートが設定されます。
アプリが Listen するポート番号(1~65535)に変更可能です。アプリからは、環境変数の $PORT で取得可能なため、特定の静的ポート番号ではなく、 $PORT 上でリッスンすることをおすすめします。
コンテナ コマンド
ENTRYPOINT で実行される CMDを動的に定義します。
コンテナ イメージで定義されているエントリ ポイント コマンドを使用するには、空欄のままにします。
コンテナの引数
エントリ ポイント コマンドに渡される引数を指定します。
コンテナ コマンドと同様、引数は必要がなければ空欄のままで大丈夫です。
起動時の CPU ブースト(2022/12 時点でプレビュー)
起動中に、より多くの CPU がコンテナに動的に割り振られて、より迅速にリクエストの処理を開始できます。特に Java 言語でコンテナ アプリケーションを実行する際に有用です。

新しい起動時 CPU ブーストにより Cloud Run と Cloud Functions のコールド スタートが改善
容量(日本語訳が分かりづらいですが、意味としてはリソースです)
CPU
各コンテナ インスタンスに割り当てる vCPU の数です。 0.08〜8 vCPU が指定可能です。
メモリ
各コンテナ インスタンスに割り当てるメモリです。 128 MiB〜32 GiB が指定可能です。
【参考】CPU とメモリの設定可能範囲における制約
| CPU | メモリ | 補足 |
|---|---|---|
| 0.5 未満 | 128 MiB 〜 512 MiB | |
| 0.5 以上 1 未満 | 128 MiB 〜 1 GiB | |
| 1 | 128 MiB 〜 4 GiB | |
| 2 | 128 MiB 〜 8 GiB | |
| 4 | 2 〜 16 GiB | |
| 6 | 4 〜 24 GiB | プレビュー (2022/12 時点) |
| 8 | 4 〜 32 GiB | プレビュー (2022/12 時点) |
リクエスト タイムアウト
1 〜 3600 秒(1 時間)の間で設定可能です。Web アプリや API であれば長くても数十秒、長時間実行処理を行う場合は 1 時間で設定するなど、用途に合わせて設定しましょう。
コンテナあたりの最大リクエスト数
ここでいう コンテナ は、コンテナ インスタンスと同様と考えて大丈夫です。
1 コンテナ インスタンスで同時に受け付けることができる最大リクエストの値を設定します。コンカレンシー(concurrency)とも言います。1 より大きい値を設定することで、いくつかのメリットがあります。
-
リソースとコストの最適化
Cloud Run の利用料は、主にコンテナ インスタンスに割り当てられたリソース(CPU / メモリ)の利用時間に比例します。1 コンテナ インスタンスで、なるべく多くのリクエストを処理することで、コスト パフォーマンスが高くなる、と言えます。
コンカレンシーの値を多く設定してしまうと、指定リソースでは処理しきれずにリクエストが詰まってしまうのでは、、、と思うかもしれないですが、大丈夫です。自動スケーリングは、CPU の使用率を 60% に維持するような挙動のため、リクエスト数の上限を待たずに自動スケーリングしてくれます。調整は負荷試験などで行うべきですが、最初から厳密に小さくしすぎなくても良いと思います。
逆に、アプリケーションでクライアント数の上限を指定している場合などは、それに合わせるようにしておきましょう。 -
DB(e.g. MySQL, PostgreSQL)への接続数の抑制
MySQL や PostgreSQL をアプリの DB として利用している場合、コネクション プールを再利用することがあると思います。その場合、リクエスト毎に別コンテナ インスタンスで処理が行われてしまうと、接続数が急激に増加します。
1 コンテナ インスタンスで複数リクエストを処理することで、接続数の上限に対して心配が減り、プールを再利用することが出来ます。
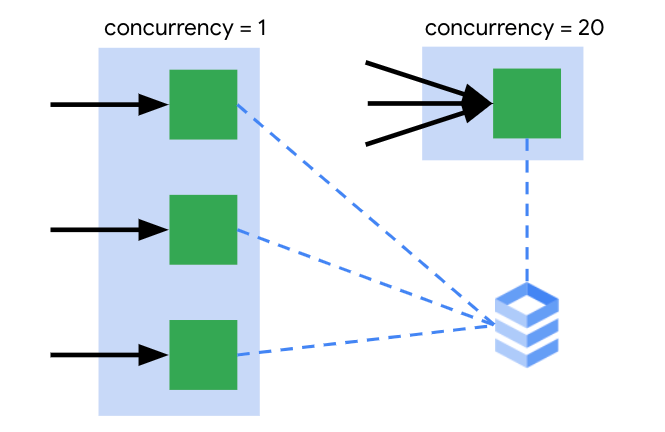
水色枠=リビジョン、緑枠=コンテナ インスタンス
実行環境
2021 年に Cloud Run の新しい実行環境として、第 2 世代の実行環境が選択可能になり、今月(2022/12)GA となりました(日本語設定だとプレビューと出てるかもしれないですが、GA です)。
1. デフォルト
明示的に特定の機能を使うわけではない場合、デフォルトを選択しておけば大丈夫です。Cloud Run が適切な実行環境を選択します。
2. 第 1 世代
第 2 世代が登場するまでの Cloud Run 実行環境のことを指します。新しい実行環境である第 2 世代のメリットは多いですが、第 1 世代の方がコンテナの起動が少し高速で、コールド スタートを優先して対処したい場合、こちらの環境を選んだ方が有効的です。
第 1 世代の方が向いているケースとして、以下があります。
- Cloud Run サービスにトラフィックが急増しており、コールド スタート時間の影響を受けやすいので、CPU パフォーマンスよりも、スケールするコンテナ インスタンスの起動速度を優先したい。
- Cloud Run サービスに、ゼロからのスケールアウトを頻繁に発生させる頻度の低いトラフィックがある(トラフィックが極端に変動的)。
- 512 MiB 未満のメモリを使用したい(第 2 世代の実行環境では 512 MiB 以上のメモリが必要)。
3. 第 2 世代
第 2 世代の実行環境では、Linux の互換性が実現されることで、以下が実現されています。
- CPU パフォーマンスの高速化
- ネットワーク パフォーマンスの高速化(特にパケットロスがある場合)
- すべてのシステムコール、名前空間、cgroup のサポートを含む、Linux との完全な互換性
- ネットワーク ファイル システムのサポート
第 2 世代が向いているケースとして、以下があります。
- サービスでネットワーク ファイル システム(Filestore など)を使用する必要がある(第 2 世代でのみサポート)。
- サービスへのトラフィックがかなり安定しており、多少のコールド スタートは許容できるので、CPU またはネットワーク パフォーマンスの高速化を優先させたい。
- 実装されていないシステムコールのため、第 1 世代で実行すると問題のあるソフトウェアをサービスで使用する必要がある。
- サービスで Linux cgroup 機能が必要。
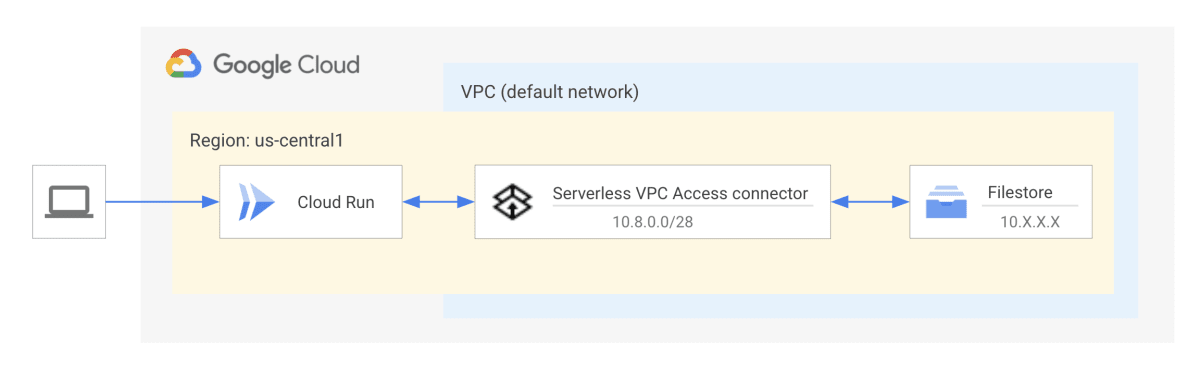
チュートリアル: Cloud Run での Filestore の使用
環境変数
コンテナアプリ開発では、動的な変数はアプリ内で定義せず、環境変数から読み込むのが一般的です。開発環境とプロダクション環境など、環境毎に設定する必要のある値は、こちらで定義してアプリケーションで読み込み、コードでの分岐は無くしましょう。
シークレット
シークレットを使用すると、API キー、パスワード、証明書、その他の機密データを安全に保存できます。 サービスでは Secret Manager の 1 つ以上のシークレットを使用できます。
環境変数として参照するか、ボリューム マウントで参照するかを選択でき、パスワードなどは環境変数、証明書などはマウントさせる、といったことが可能です。
Cloud Run の権限はあるが、Secret Manager の権限を持たないデベロッパーの場合、読み込む環境変数の名前や、マウントするパスしか設定しないため、値となる機密データが画面に表示されることはありません(下図の sample-password は値ではなく、Secret Manager 側のシークレットの名前)。

「sample-password」というシークレットを「DB_PASSWORD」という環境変数に設定する例
接続
Cloud Run サービスへの接続と、Cloud Run サービスからの接続設定をします。
HTTP/2 エンドツーエンドを使用する
コンテナが gRPC ストリーミング サーバーであるか、HTTP/2 クリアテキストでリクエストを直接処理できる場合に使用します。
Cloud Run サービスのデフォルトでは、Cloud Run は HTTP/2 リクエストをコンテナに送信する際に、リクエストを HTTP/1 にダウングレードします。そのようなダウングレードをせずにエンドツーエンドで HTTP/2 を使用するようにサービスを明示的に設定する場合、HTTP/2 用に構成できます。
REST API や Web アプリケーション用途のサービスの場合、特に有効化の必要はありません。
セッション アフィニティ(2022/12 時点でプレビュー)
同じクライアントからのリクエストを可能な限り、同じコンテナにルーティングする機能です(TTL = 30 日)。ただし、Cloud Run のコンテナ インスタンスが自動スケーリングによってスケールインした場合、該当コンテナにルーティングすることは出来ないため、新しいコンテナにルーティングされることに注意が必要です。
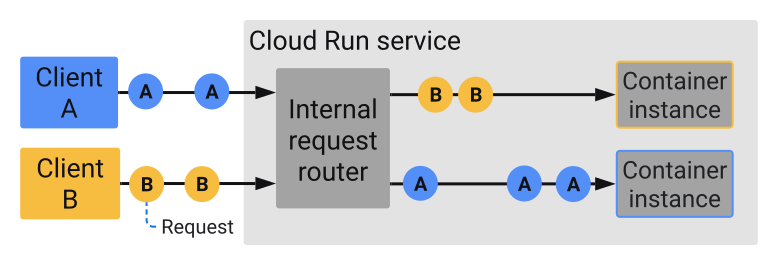
Cloud Run を利用する場合、Stateful なデータは外部(DB or Storage)に保存する必要がありますが、アプリケーションのメモリ内でキャッシュを最大化させたい場合や、WebSocket 用途でこの機能が使われることが多いです。
ちなみに、Cloud Run が提供するトラフィック分割とセッション アフィニティを併用した場合、同一リビジョンへの接続が保証されないことがドキュメントで書かれてありますが、トラフィック分割時も、リビジョンへのアフィニティが有効化されるよう議論がされているようです。
Cloud SQL 接続
Public IP を持つ Cloud SQL(MySQL / PostgreSQL / SQL Server)を DB として利用する場合に設定する項目です。
Cloud SQL インスタンスに接続する場合、Public IP ではなく、project:region:instance-id といった形式の名前で接続することが可能です。インスタンスの名前をここで選択することで、Cloud Run サービスから、該当 DB インスタンスに対して、名前での接続が可能になります。
なお、Cloud SQL ではなく、Firestore や Cloud Spanner といった Cloud Native DB は API(Cloud SDK)を介して操作を行うため、この設定は不要です。
Cloud Run は Project の VPC に所属しないサーバーレスな製品なので、接続周りの考慮が不要な Cloud Native DB とは非常に相性が良いと感じます。
VPC
Cloud Run は Project の VPC に所属しないため、VPC 上のリソースにアクセスする場合や、外部への通信を VPC 経由に変更したい場合、コネクタが必要となります。これを サーバーレス VPC アクセス コネクタ と呼びます。
- プライベート IP へのリクエストだけを VPC コネクタ経由でルーティングする
Cloud Run サービスが、VPC 内にある Cloud SQL や AlloyDB、Memorystore などに Private IP で接続する場合、接続するためのコネクタを別途作成して指定する必要があります。
コネクタの実態は VM インスタンスで、最小、最大インスタンス数の指定をするスケール設定が可能です。インスタンスは下記から選択可能です。
| マシンタイプ | 想定スループット範囲(Mbps) |
|---|---|
| f1-micro | 100〜500 |
| e2-micro | 200~1,000 |
| e2-standard-4 | 3,200~16,000 |

- すべてのトラフィックを VPC コネクタ経由でルーティングする
サービス間通信のアクセスを VPC 内部経由のアクセスとして扱いたい場合や、Cloud Run サービスからの外部リクエストで IP アドレスを固定したい場合(Cloud NAT を利用)など、すべてのリクエストをコネクタ経由にすることも可能です。

セキュリティ
Cloud Run 周りのセキュリティ全般の設定になります。
サービス アカウント
デフォルトだと、Cloud Run のサービス アカウントは Compute Engine default service account([PROJECT_NUMBER]-compute@developer.gserviceaccount.com)が割り当てられています。
このサービス アカウントは、プロジェクトの編集者という非常に強い権限を持っているため、Cloud Run のサービス毎に必要な権限だけを持つ、新規サービス アカウントを作成すべきです(Cloud Run の画面から作成することも可能です)。
Binary Authorization を使用してコンテナのデプロイを確認する
Binary Authorization は、信頼できるコンテナ イメージのみをデプロイするためのセキュリティ コントロールの機能です。例えば、脆弱性の検査や QA チェックなどを通すワークフローの場合に、チェックが未実施のコンテナがデプロイされるのを防ぐことが出来ます。

ソフトウェアを安全に届けるための最新動向 2022 より抜粋
Binary Authorization の設定についての詳細は、ドキュメントをご参照ください。
暗号化
Cloud Run にデプロイされたコンテナ イメージは、デフォルトで Google が管理する鍵によって暗号化されます。自分で暗号化を管理する必要がある場合、顧客指定の暗号鍵(CMEK)を使用します。
鍵は、Cloud Run サービスと同じリージョン用に、Cloud KMS で作成された対称鍵にする必要があります。
-
Google が管理する暗号鍵を利用する
Google 管理の鍵でコンテナ イメージが暗号化されます。 -
顧客管理の暗号鍵(CMEK)を利用する(Google Cloud Key Management Service で管理)
Cloud Run のコンソール画面では、Cloud KMS のキーリング作成が行えないので、まず Cloud KMS 側で作成した後にこちらで選択します。

ここまで設定したら、サービスを作成しましょう。
Cloud Build の設定を一緒に行う場合、CI/CD をトリガーにした最初のデプロイが完了するまで数分程度かかると思います。
さいごに
最近、ワークショップで Cloud Run の説明をすることが多いのですが、コンソール画面の説明を 1 つずつ深掘りして説明すると、余裕で 1 時間以上かかります。
全部覚えるのは大変だと思うので、Cloud Run のサービス作成時に、この記事がリファレンス的に利用されると嬉しいです!
また、コンソール画面上では分かりづらいネットワーク周りや関連セキュリティ機能について、同僚のセッション動画が YouTube にアップされているので、ぜひこちらもご参照ください。

Discussion