はじめに
初めまして。Givery AIラボでPM/AIエンジニアをしている鈴木です。
2024年を振り返ってみると、生成AI関連ではRAGに関連したプロジェクトやセミナー、研修が非常に多かったです。
そこで、実際にお客さんやセミナー参加者から多く寄せられたRAG関連の質問と、我々からの解答を共有させてもらいます。
少しでも、RAG関連のプロジェクトに入っている / 入る予定のある方への手助けになれば幸いです。
ちなみにそこまで技術的に深掘はしておりません。詳しくは、リンク先等をご参照下さい。
この記事の対象者
- これからRAGを導入しようとしており、RAGの作り方や仕組み等基本的な所から知りたい方
- RAG関連のプロジェクトにPMとして入る予定で、どういった所が課題なのか等を把握しておきたい方
- RAGには関係無い仕事だが、知識として全体感をつかんでおきたい方
RAG全般について
RAGの盛り上がりについて
まずは、こちらの図をご覧下さい。

"RAG"のGoogle Trends
こちらは、"RAG"と言うキーワードでGoogle Trendsにかけた結果です。ご覧頂けるように、2023年後半から現在にかけて上昇し続けています(こちらは日本での結果ですが、海外でも同様でした)。
実感としても、今年はお客さんからRAGについての問い合わせが多かったです。特に、社内データを効果的に取り出して参照したい、というニーズが非常に高かったです。
RAGとは何か
ここで、そもそもRAGとは何かについてご説明します。
RAGは"Retrieval-Augmented Generation"の略で、検索拡張生成と訳されます。
一言で言うと、知識ベースから関連情報を検索し、それを活用して特定の業務やニーズに応じた回答を生成する技術です。
例えば以下の図のように、そのままではChat GPTのようなLLMが解答出来ないような質問に対して、社内の知識ベースを参照して正確な回答を返します。

RAGとは
RAGの活用例
上記のような社内の知識ベース参照以外にも、例えば顧客の要望に対して、適切な提案を行う事も可能です。
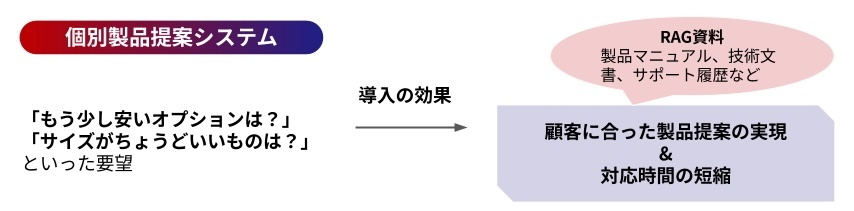
RAGの活用例
RAGの仕組み
ここでは、RAGの仕組みについて解説します。
知識ベース作成
RAGを行うにあたっては、まずは何よりRAG用の知識ベースを作成する必要があります。
具体的には、以下のような手順を踏みます。
- RAGで検索したいドキュメントを一定のサイズに区切る(チャンク化)
- チャンクごとにベクトル化する
- これらのベクトル情報を知識ベースに格納する

RAGの仕組み(知識ベース作成)
ちなみにベクトル化とは、文章を数値化する技術です。
これにより、システムが検索をするための様々な計算が可能になります。

ベクトル化
全体フロー
RAGの全体フローは以下の通りです。
- ユーザーの質問がクエリに変換される
- 作成済みの知識ベースとクエリが照合され、最も関連度の高い文章が取得される
- その文章とクエリを元にChat GPT等のLLMが回答を生成する
例えば以下のように「有給申請の方法」を尋ねた際には、社内ポータルやFAQが参照され、正確な情報を基に的確な回答が生成されます。

RAGの仕組み(全体フロー)
よく聞かれたRAGの質問&回答集
ここからは、RAG関連でよく聞かれた質問と、その回答をお伝えします。
よく聞かれた質問① : Azure上でのRAGの作り方は?
質問①とその回答
❓質問①
Azure上でRAGのシステムを手軽に作成するには、以下のどちらが適していますか?
① ”Azure OpenAI on Your Data”を利用する方法
② Azureのサービスを組み合わせて独自構築する方法
💡回答
・社内用や実験用にクイックに構築するには「Azure OpenAI on Your Data」がおすすめです。
・より高度な前処理や柔軟なカスタマイズが必要なら、Azureのサービス組み合わせによる独自構築を推奨します。
質問①の解説
Azure OpenAI on your dataとは?
Open AIモデルをベースにしたRAGシステムを、独自の企業データをベースにして手軽に実装出来る機能を持つAzure上のサービスです("on your data"という事で、自分たちのデータと統合出来ますよ、といったニュアンス)。Azure AI SearchやCosmos DB、Blob Storageなどの各種Azureリソースや、サードパーティのデータベースも統合する機能もあります。

Azure OpenAI on your dataについて
参考 :
on your data VS 自社開発比較表
下の表は、on your dataと自社開発の機能比較です。両者ともRAG機能やデータベース接続に対応していますが、自社開発は他モデルやAzureサービスとの柔軟な連携が可能です。
| on your data | 自社開発 | |
|---|---|---|
| RAG機能 | ⭕️ | ⭕️ |
| データベース接続 (Cosmos DB, Blob Storage) |
⭕️ | ⭕️ |
| Open AI以外のモデルの使用 | ✖︎ | ⭕️ |
| 他Azureサービスとの接続柔軟性 | ✖︎ | ⭕️ |
結論、on your dataは簡単にRAG環境を作れるという点では優れていますが、それ以上のカスタマイズ性等が必要な場合は、自社開発がおすすめです。
よく聞かれた質問② : AOAI / AI Search側でRAGの回答精度に影響する項目は?
質問②とその回答
❓質問②
RAGの回答精度を向上させるために、Azure OpenAI ServiceやAI Search で設定すべき項目はありますか?
💡回答
主要な項目は、以下の3点です。
1.モデルの種類
2.検索手法
3.温度(Temperature)
質問②の解説
3種類の検索方法とセマンティックランク付けについて
Azure AI Searchでは、以下のような検索方法が用いられます。
・フルテキスト検索 : キーワードをベースにした検索。処理負担が軽い一方、意味をとらえるのが難しい場合がある。Azure AI SearchではBM25というアルゴリズムが使用される。
・ベクトル検索 : ベクトルをベースにした検索。処理負担は増えるが、意味をとらえる事が出来る。
・ハイブリッド検索 : 上記2つを掛け合わせた検索

Azure AI Searchでの各種検索手法
さらに、検索結果をMicrosoft独自のモデルを使用してさらに最適な順番に並び変えるセマンティックランク検索というものもあります。
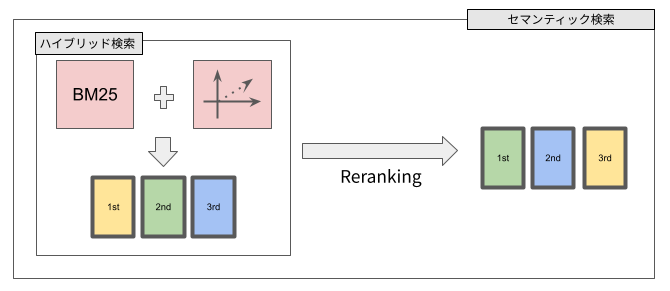
セマンティックランク検索
基本的にはセマンティックランク検索をオンにしておくのが最も精度が高く、推奨となります。
温度(Temperature)について
温度とは、生成文の「多様性」を左右するパラメータで、通常0~1の範囲で数値を調整します。
0付近では毎回の出力がほぼ同様となり、逆に1付近では多様かつ創造的な出力が得られます。
RAGのように正確性が重要な場合はなるべく低く設定するのが一般的です。

温度のイメージ
よく聞かれた質問③: RAG用データの最適なフォーマットは?
質問③とその回答
❓質問③
RAGシステムにFAQのようなデータを格納する際に、精度が上がる形式やフォーマットはありますか?
💡回答
メタデータの付与や、JSONなどの構造化データへの変換を推奨します。
質問③の解説
メタデータとは?
RAG用の各データを管理、検索しやすくするために、補助的に付随する情報です。
下記は、JSON形式で管理される場合の例です。
単純な質問と回答だけでなく、カテゴリーや部署といった情報も付与されているのが分かります。
{
"faq_id": "001",
"category": "社内規定",
"tags": "就業規則,休暇",
"question": "有給休暇の申請方法を教えてください。",
"answer": "有給休暇の申請は、社内ポータルサイトにログインし、休暇申請フォームに必要事項を入力して送信してください。",
"last_updated": "2024-12-10",
"department": "総務部",
}
このようにする事で、例えばRAGの際に、
department -> 総務部のみ
category -> 社内規定のみ
という風に、対象となる文書を絞り込んで検索する事が出来ます。
これにより、RAGの精度の向上が見込めます。
メタデータの作成方法 - Azure AI Search
例えばAzure AI Searchの場合、以下のようにフィールドという名前でメタデータを作成する事が出来ます。

AI Searchのフィールド
ちなみに、LangChainでも実装する事が可能です。
興味のある方は以下をご参照ください。
複雑な形式のデータ変換(Excel)
例えば以下のように結合セルを含むExcelデータは、このまま取り込むとうまくRAGしてくれない事があります。

結合セルを含むExcel
理由は、例えばこちらをそのままcsvデータに変換すると、以下のようにセル同士の関連情報が失われてしまう場合があるからです。
これだと、どの原因に対してどの対応方法が適切か、が分かりづらいですね。
ID,問題,原因,対応方法
1,機器が異常音を発する,"①ファンに異物が絡まっている
②ファンモーターが故障している","機器を停止し、ファン周辺を点検・清掃してください。
ファンモーターを点検し、必要に応じて交換してください。"
このような場合は、以下のようにJSON等の構造化データに変換する事がおすすめです。
セル同士の関連情報がキープされ、精度向上が期待できます。
[
{
"ID": 1,
"問題": "機器が異常音を発する",
"原因": [
"ファンに異物が絡まっている",
"ファンモーターが故障している"
],
"対応方法": [
"機器を停止し、ファン周辺を点検・清掃してください。",
"ファンモーターを点検し、必要に応じて交換してください。"
]
}
]
参考 :
よく聞かれた質問④: RAGの評価指標・評価手法・ツールを知りたい
質問④とその回答
❓質問④
RAGの精度評価の指標や手法、そのためのツールを教えてください。
💡回答
評価指標には例えば以下のようなものがあります。
•Faithfullness(回答の忠実性)
•Answer Relevance(回答の質問適合性)
•Context Relevance(文脈適合性)
評価手法としては、LangSmith、RAGAS等のツールを活用したり、独自コードによる評価実装も行われます。
質問④の解説
評価指標について
こちらの図は、基本的なRAGの評価指標を図示したものです。

RAGの評価指標
クエリ・コンテキスト・回答については以下の通りです。
| 項目 | 内容 |
|---|---|
| クエリ | ユーザーからの質問や要求 |
| コンテキスト | クエリに対して参照される知識ベース内の文章(=チャンク) |
| 回答 | クエリとコンテキストの内容を踏まえ、ユーザーに返される最終的な応答 |
次に、RAGの評価指標となる代表的な3つの観点を見ていきましょう。
| 評価指標 | 説明 |
|---|---|
| 回答関連性 (Answer Relevance) |
クエリに対して生成された回答の関連性を評価する指標です。 不完全な回答や冗長な情報を含む回答には低いスコアが付けられます。 |
| 文脈関連性 (Context Relevance) |
参照先のコンテキストが、クエリとどの程度関連しているかを示します。 |
| 忠実性(Faithfulness) | 回答がコンテキストの情報を正しく反映しているか、誤情報や言い換えの歪みがないかを評価する点です。 |
これら3つの指標を総合的に評価することで、ユーザーの求める内容に対して正確かつ信頼性の高い回答が提供できているかを判断します。
また、これ以外にも様々な指標があります。
以下のRAGASやLangSmithのページでも紹介されていますので、興味のある方はご欄ください!
RAG評価に使用されるツール

RAG評価に使用されるツール
LangSmithはRAGの評価ツールとして、現場で実際に利用されています。
RAGASは検索する限りではポピュラーな選択肢として注目されていますが、今の所現場での使用実績は未確認です。
また、ツールを使わずに自前でロジックを実装するケースも多く見られます。
終わりに
ここまで、RAGに関する基礎知識や、よく聞かれる質問への回答をまとめてお伝えしました。
RAGはLLMの能力をさらに引き出し、実用性を高める強力なアプローチです。その一方で、効果的なデータの管理や評価指標の設定等が重要です。この記事が、これからRAGを導入する方や関連プロジェクトに携わる方の一助となれば幸いです。
また、今後のRAGについては、以下のような観点も注目されています。
引き続き学び、キャッチアップを続けながら、それぞれのプロジェクトに最適な方法を模索していければと思います。
また、Givery AI Labが独自保有するフリーランス・副業の高単価AI案件や、随時開催しているセミナーやパーティなどのイベントにご興味ございましたら、ぜひTrack Worksのアカウント登録いただき、最新情報を受け取ってください!
「Track Works」とは?
Givery AI Labの運営会社である株式会社ギブリーが提供する、AI時代のフリーランスエンジニアとして「スキル」と「実績」を強化できる実践的なAI案件を、ご経歴やスキルに合わせてご紹介するフリーランスエンジニア案件マッチングサービスです。Givery AI Labが独自保有するフリーランス・副業案件を紹介したり、AI関連技術やエンジニアのキャリアに関するイベントを随時開催しています。
また、Givery AI Labメンバーとして就職・転職をご検討いただく場合は、下記からご応募くださいませ! (運営会社である株式会社ギブリーのエンジニア向け求人一覧ページです)
【企業のご担当者様へ】
Givery AI Labでは、PoCで終わらせない「AIの社会実装」を実現するため、AI開発プロジェクトのPoCから本格実装・運用まで、幅広く伴走支援しております。ぜひお気軽にお問合せください。
・AI開発プロジェクト伴走支援サービス:https://givery.co.jp/services/ai-lab/
・生成AI技術に関するお悩み解決サービス「Givery AI 顧問」:https://givery.co.jp/services/ai_advisor/

Discussion