初めまして、Givery AI Lab所属AIエンジニアの李と申します。
今回は、社内(株式会社ギブリー)の業務プロセスを改善し、効率を向上させるためにGivery AIラボで開発した、法務業務に特化した「法務アシスタントAI」についてご紹介します。メイン機能の説明から、使いやすさを追求したUXの工夫、LLM(大規模言語モデル)の精度評価に対する取り組みまで、幅広くお伝えしたいと思います!
「法務アシスタントAI」とは?
今回の開発プロジェクトの目的である社内業務の効率化にて、AIラボが注目したのは次の2つコア機能です。
- 案件管理機能:Slackのスレッド立ち上げをトリガーに、Notion上にワークスペースを自動作成・登録し、Google Driveにアーカイブを作成して関連ファイルを保存する一連のプロセスを自動化
- 修正提案機能:LLMによる業務関連ファイルの修正が必要な箇所の検出と修正提案
これらは特定の業務に限定されたものではなく、さまざまな分野や会社でよく見られる一般的なワークフローに応用できるものです。例えば、「営業担当者が契約案件を取得し、取引先との契約書を社内法務チームに確認依頼する」というケースが挙げられます。
今回、Givery AIラボはさまざまな業務の中でも社内法務チームの声に耳を傾け、「法務契約案件管理」のアシスタントAI、略して「法務AI」を開発してみました!
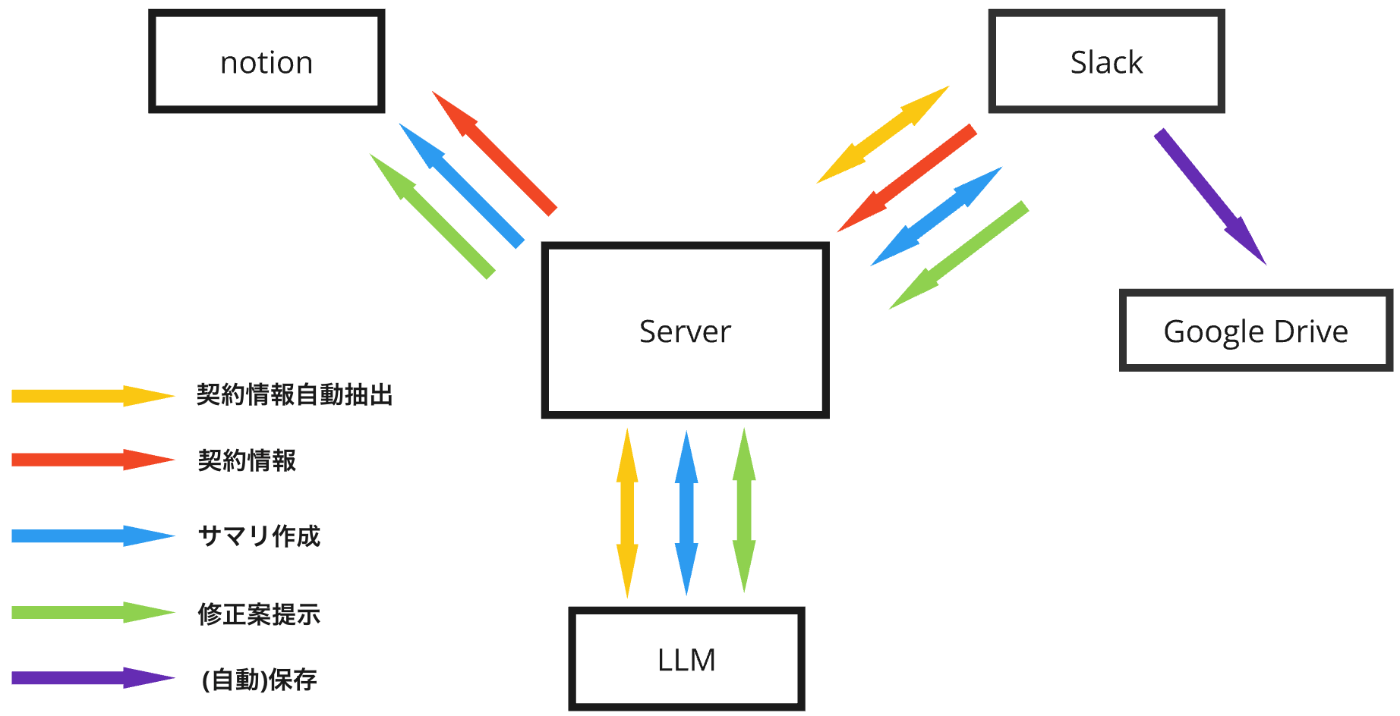
<図1:法務契約案件管理のアシスタントAI、「法務AI」>
SlackやNotion、Google Driveなどのツールを連携した形の「法務AI」ですが(<図1>を参照)、実際に社内ユーザーからは、「契約書ファイルの確認やワークスペースの作成・登録、適切なアーカイブの検索とファイルの保存をシステムが一括処理してくれる」と好評をいただいており、この開発経験を皆さんとシェアしたいと思います。
案件管理機能
まずは、「法務AI」の具体的な機能についてご紹介します。案件管理機能は、Slack上での契約案件の確認依頼からNotionワークスペースの作成・管理、契約書ファイルのGoogle Drive保存までの一連のプロセスを代表とする機能です。
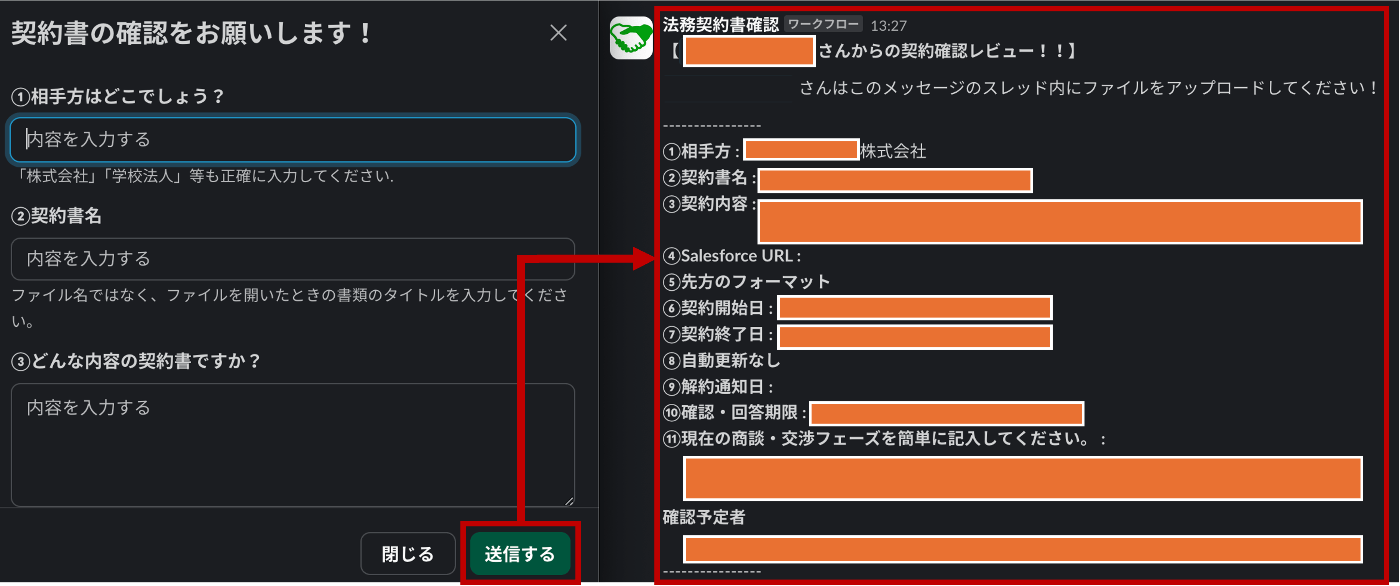
<図2:Slackを通じた案件の確認依頼>
(左)Slackワークフローを入力することで、(右)契約案件の確認依頼スレッドが生成される。
<図2>は、Slackを通じて案件の確認を依頼する一例です。Slackの特定チャンネルにワークフローを入力することで契約案件の確認依頼スレッドが生成されます。続けて、生成されたスレッドに契約書ファイルをアップロードすることで、法務チームへの案件依頼は完了となります。
依頼スレッドが立ち上がると、Slack APIのイベントハンドラーが案件情報を読み取り、Notion APIを通じてワークスペースを作成します<図3>。
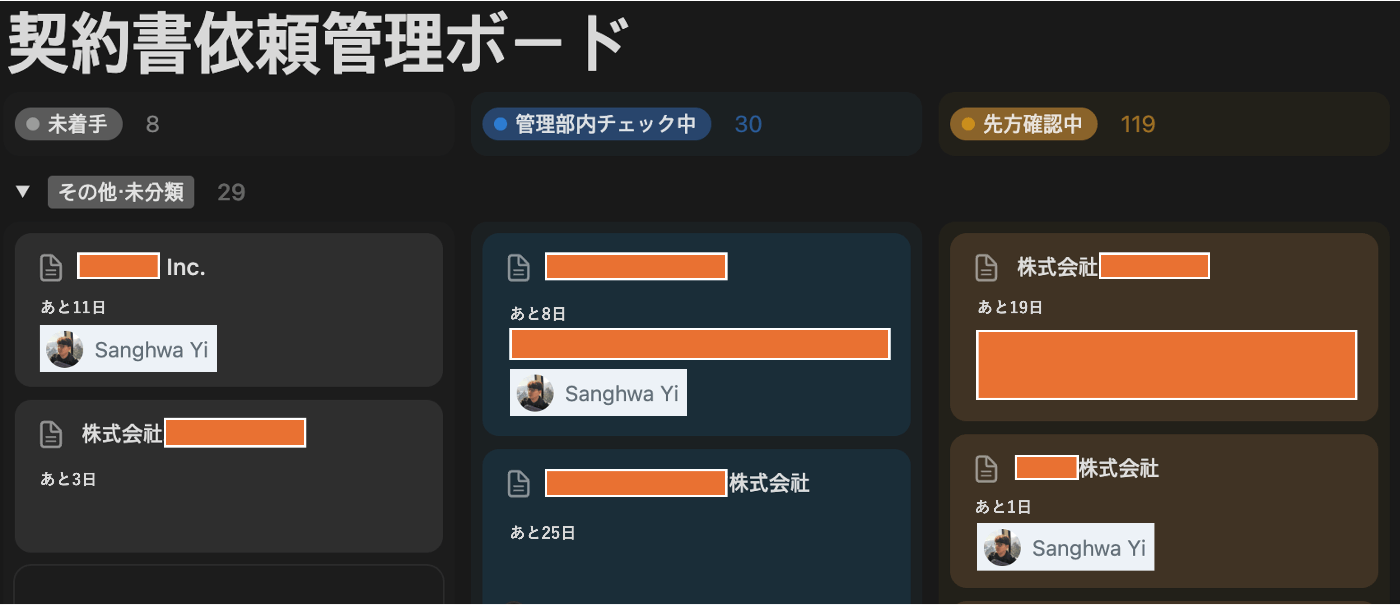
<図3:依頼スレッドから自動生成されたNotionのワークスペース>
同時に、アップロードされた契約書ファイルは相手方の企業名を基準に適切なGoogle Driveのアーカイブに自動保存されます。
取り組みポイント
案件管理機能を開発する際に、Givery AIラボで常に意識していたポイントは、「これまで人が手作業で行っていたワークフローを、いかに柔軟性のあるシステムとして実装できるか」です。その一例が「Slackスタンプによる管理機能」です。
<図4:システムが付けるスタンプの例>
(左)メール箱:ファイル自動保存の完了通知 /(右)ロボット:LLMによる修正提案の完了通知。
Slack環境を主に利用しているユーザー層に合わせ、Slackのスタンプ操作とシステム機能を連携させました。例えば、契約書ファイルの保存やLLMによる修正提案が完了した際に、システムが自動でスレッドにスタンプを付けて通知したり(<図4>を参照)、逆にユーザーがスタンプを押してNotionワークスペースを制御するなど、ユーザー層の慣れた方式でシステム機能を実装し、アクセシビリティを最大にしました。
また、依頼側のユーザにも同様に使いやすさを追求し、doc/docx/pdf形式のファイルであればどのような様式でも前処理無くそのまま処理可能にしたところも、当機能の実装にて工夫したポイントの一つです。
もう一つ、細かい点ではありますが、実は「契約書ファイルをGoogle Driveの適切なアーカイブに保存する」というプロセスにも、アーカイブを検索する際にGPTの類似度検索を活用しています。このようなAIネイティブな発想を大切にし、それを実現できるのがGivery AIラボの強みです。
修正提案機能
続いて、「法務AI」のAIによるデータ検討および修正機能、つまり法務契約書のレビューと修正提案機能についてご紹介します。

<図5:GPT-4oによる契約内容のサマリー作成機能>
まずは、アップロードされた契約書ファイルのサマリー作成です。新しい契約案件の依頼が届いた際に、短時間で内容を把握し、案件の優先順位を決定するのに役立つ機能です。
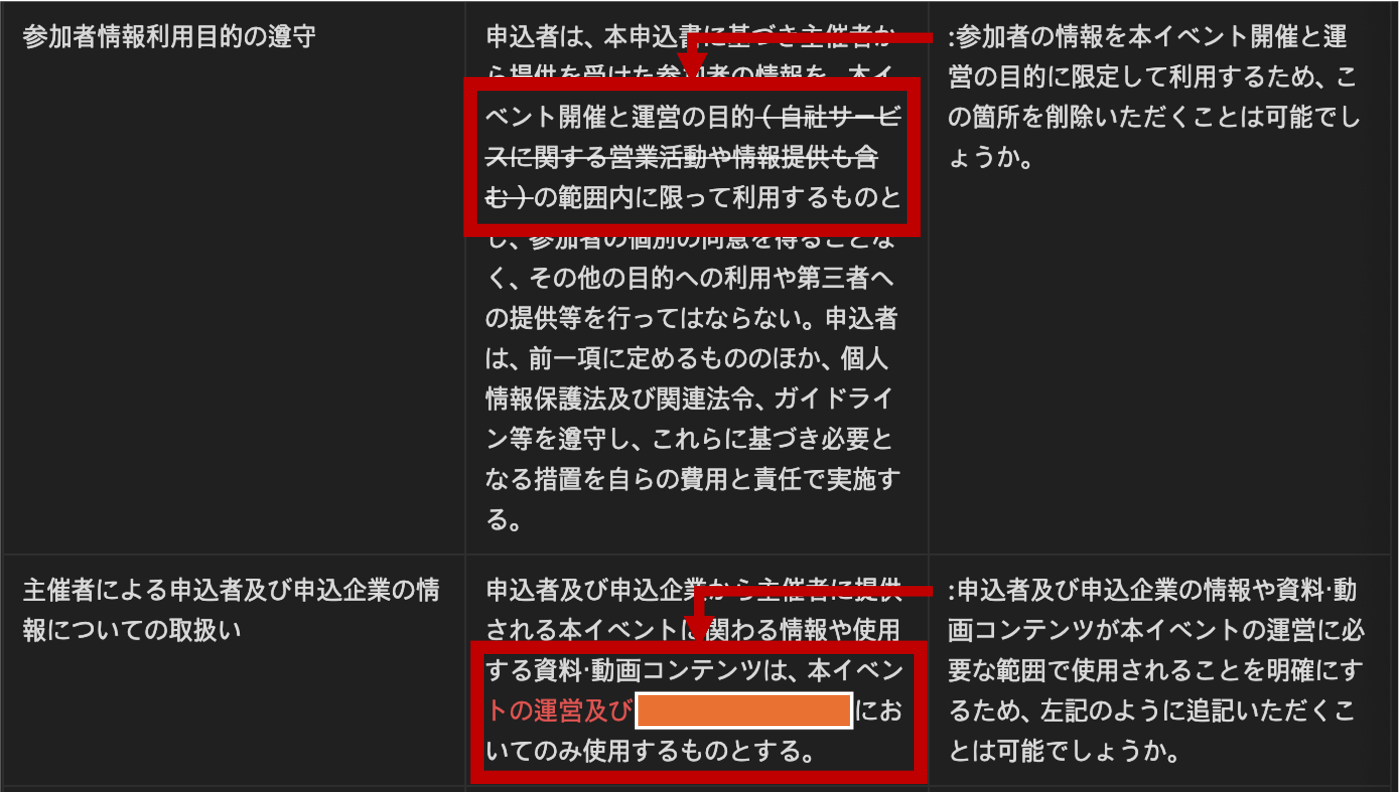
<図6:GPT-4oからの契約内容の修正提案>
(左)契約条項 /(中)修正内容:追加は赤く・削除は横線で表示 /(右)提案に対するコメント
次に、契約書の内容をレビューし、会社に損害や重大な責任をもたらす可能性のある条項を検出し、修正案を提案する機能があります。GPTによって生成される修正提案はテキスト量が多いため、Slack上ではスレッドが流れてしまうことがあります。そのため、Notionのワークスペース上にテーブル形式で一目でわかるように出力する工夫をしています<図6>。また、各修正案に対して、なぜ修正が必要かを解説するコメントも付け加えました。
取り組みポイント
今回の開発におけるGivery AIラボの柔軟性の高いシステム作りへの取り組みは、ここにも現れています。先ほど紹介した案件管理機能と同様に、「doc/docx/pdf形式のファイルであれば、どのような様式の契約書でも前処理なしで処理できる」とお伝えしましたが、これはGPTによる契約書のサマリー作成や各契約条項の検討、修正提案でも同様です。
精度の評価
記事を読んで、AIが生成するテキストの精度や提案内容の質に疑問を感じた方もいるかもしれません。「法務契約書の検討および修正」という高度な専門知識を要するタスクに対して、GPTがどの程度の質の高い提案ができるのか、私たちの経験と情報をシェアします。
まず、「法務AI」が生成した契約条項の修正提案内容を、社内のスペシャリストに定量的に評価してもらいました。法務チームで数年以上の経験を持つプロフェッショナルによる評価では、GPTの修正提案は5点満点中3点を獲得しました。
次に、「法務AI」が生成した内容をGPTに定量評価させてみました。これは2023年、Microsoft研究チームが提案したG-eval(論文リンク)というLLMの評価法で、「人間の判断に近い形でLLMが生成するテキストのクオリティを評価する」という、面白い発想の手法です。
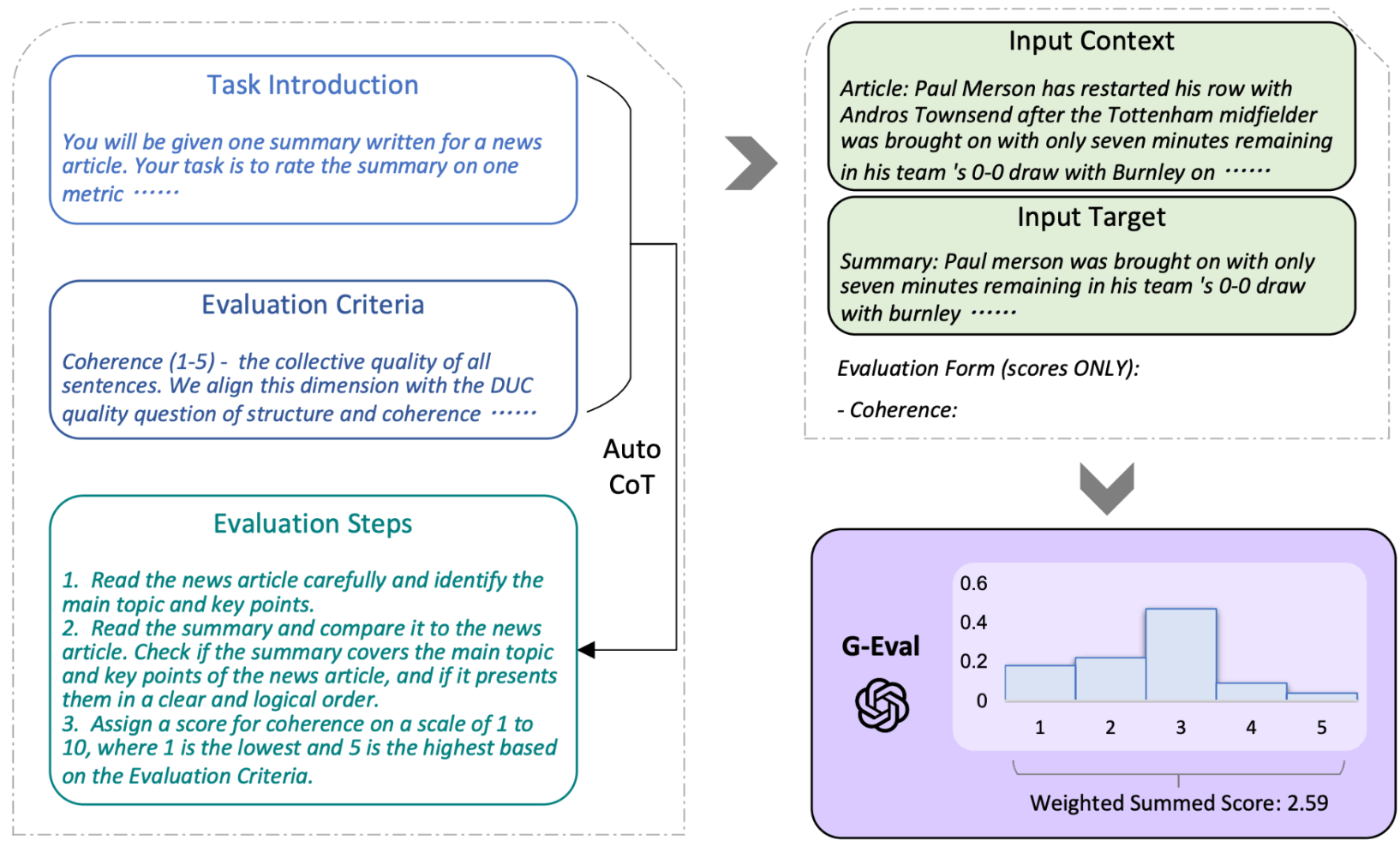
<図7:G-evalの仕組み>
評価内容および基準を定義し評価の過程を明確に提示するのがポイントです。
具体的には、「Chain of Thought (CoT)」という推論過程を評価プロセスに取り入れることで、既存の手法よりも直観的かつ精度の高い評価法として注目されています(<図7>を参照)。G-evalによる「法務AI」の評価は5点満点中3.48点でした。
- 人の専門家による評価:3.00/5
- GPTによる評価(G-eval):3.48/5
この二つ点数を比べると、「人の専門家による客観的な判断結果」と「LLMによる人の判断過程の模倣結果」の間に多少の距離はあるものの、大きくはずれていないことがわかります。
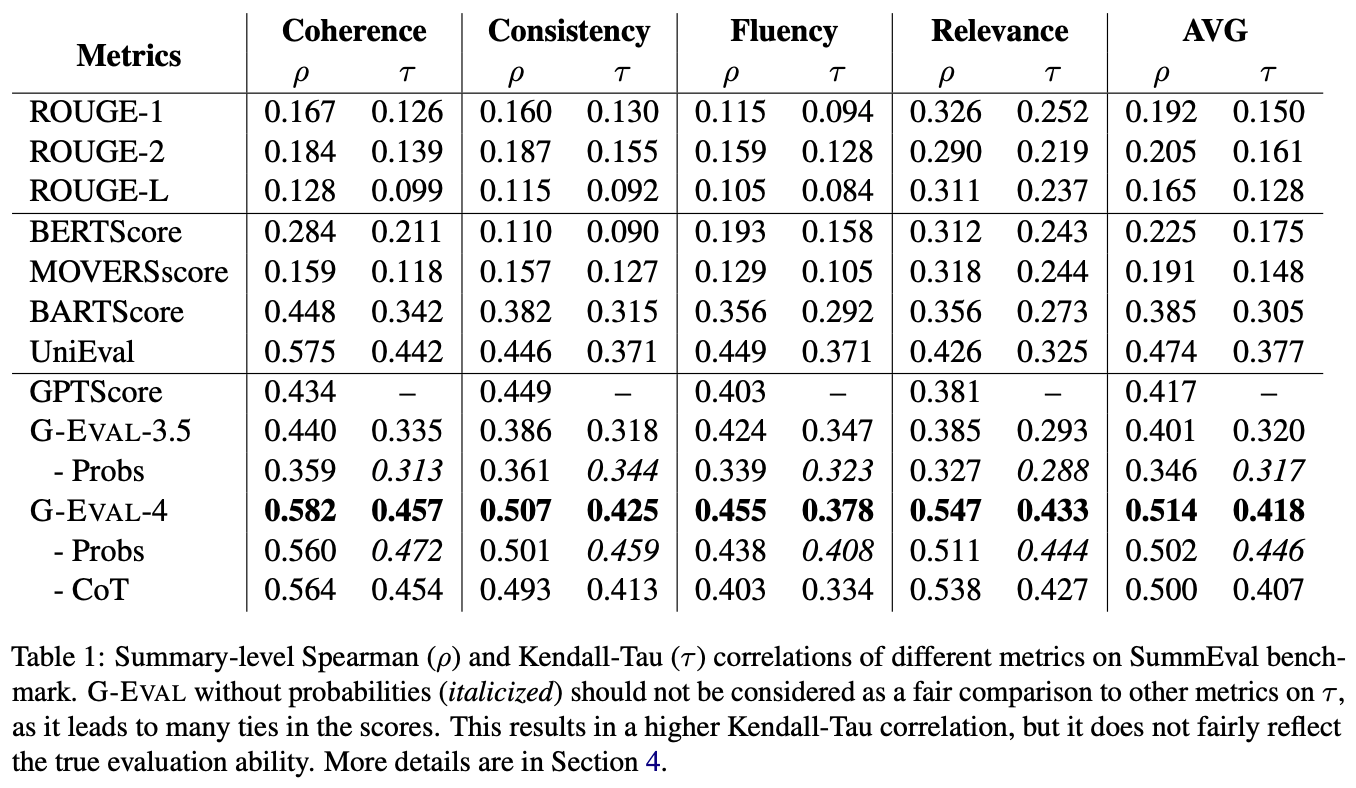
<図8:既存のLLM評価手法とG-eval評価の比較>
ニュース・新聞記事のサマリー作成にて、作成物の人による評価と各評価手法の相関係数)を表したテーブル。
GPT-4を使ったG-evalによる評価が全ての項目にて一番高い数値を記録。
実際に、G-evalによるLLMの評価は、さまざまなベンチマーク環境で既存の手法より正確(人間の判断による評価により近い)ことが示されています<図8>。個人的には、G-evalの「LLMに人間の思考過程を模倣させ、LLMの評価を依頼する」というアプローチは、今後LLMモデルの進化により、より信頼性の高い評価手法として注目される可能性が高いと思います。
精度向上への工夫
話を戻し、今回「法務AI」が記録した3.48のG-eval評価点がどの程度意味を持つのかを理解するため、G-evalの論文を参照してみました。
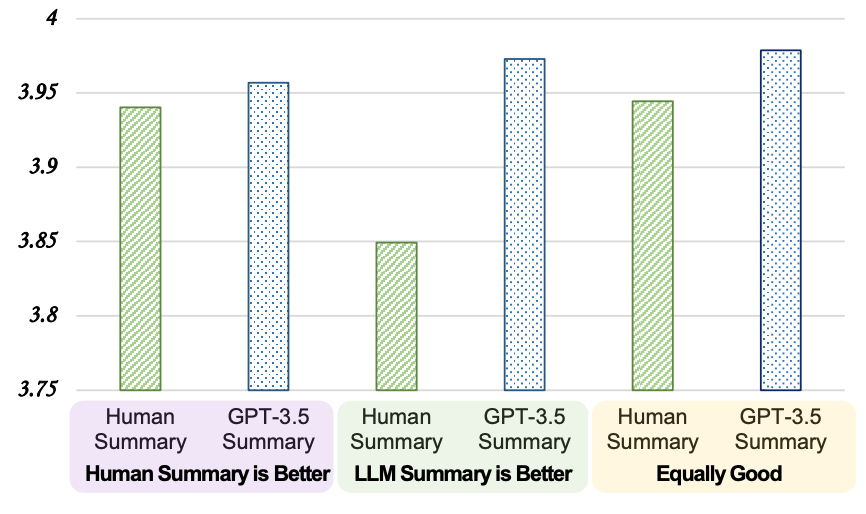
<図9:GPT-3.5による「新聞記事のサマリー作成」のG-eval評価点(3つの青いバー、平均で約3.96点)>
著者が行った「新聞記事のサマリー作成」をGPT-3.5に実行させた実験では、約3.96点を記録していました<図9>。「記事のサマリー作成」と「法務契約書の検討および修正」ではタスク難易度も、採用しているLLMモデル(「法務AI」ではGPT-4oを使用)も異なるため、「法務AI」の3.48点を単純に比較するのは難しいのですが、AIラボではこのG-evalスコアを向上させるために工夫を重ねました。
精度向上に向け、次のような仮説を立てました。
1. 「法務契約書の検討および修正」は、数年以上の経験を要する非常に専門性が高く、難しい作業である
2. GPTは汎用性目的で学習されたため、実務レベルの「法務契約書の検討および修正」の専門性が不足している
つまり、「汎用性を前提に学習されたGPTモデルでは、法務契約書の検討および修正という専門性の高いタスクを完遂するには限界があり、そのためには専門的なデータを追加で提供する必要がある」ということになります。
OpenAIでは、学習済みのGPTモデルに追加データを与える手段として、主に「Few-shot Prompting」「ファインチューニング」「Retrieval-augmented Generation (RAG)」の3つを提供しています。
| メリット | デメリット | |
|---|---|---|
| Few-shot | 追加の学習やモデルの再構築が不要、手軽で迅速 | 長いコンテキストでは性能が低下しやすく、専門的なタスクには限界がある |
| ファインチューニング | 特定のデータや専門的なタスクに対してモデルをFitさせ、精度の向上を期待できる | 多くのデータが必要で、時間と費用のコストがかかる |
| RAG | 外部データにリアルタイムでアクセスし、モデルサイズやトークン制限に関わらず豊富な情報に基づいた質の高い応答を期待できる | 充分な量の外部データベースが必要となり、システムが複雑化して構築や管理が難しい |
それぞれにメリットとデメリットがありますが、ラボで試した結果、最も高いG-eval評価を得たのはFew-shot Promptingによるもので、3.65のG-eval評価点を記録しました。今回、「法務AI」におけるファインチューニングとRAGの実装で利用可能だった契約書データは163条(約138万トークン分)でしたが、特に学習に大きく影響する「実際に契約条項を修正した」データの数は少なかったため、ファインチューニングやRAGによって大幅な精度向上は難しいという結論に至りました。
| G-eval評価点(5点満点) | |
|---|---|
| Zero-shot | 3.482 |
| Few-shot | 3.653 |
| Few-shot + Role-playing | 3.962 |
Few-shotプロンプトに、LLMに役目を付与するプロンプト技術であるロールプレイングを加え、プロンプト最適化を行った結果、最終的に3.96のG-eval評価点を得ることができました。これはG-eval論文の著者が行った実験<図9>結果とほぼ同じ数値となります。
現在、Givery AIラボでは「GPTに過去の類似度の高い契約書の修正履歴を参考にさせ、より質の高い修正内容を生成する」方向で研究開発を進めています。このアプローチでは、現状のFew-shot Promptingよりも多く、かつ長い文脈情報をGPTに提供できるため、限られたデータ量の環境でもより高い精度を得られると期待しています。また、情報の追論にてGPT-4oを圧倒するOpenAI-o1モデルを採用した場合にどのような結果が得られるかも注目すべきポイントの一つです。
まとめ
今回の記事では、AIによる業務プロセスのDX化を目指した「業務特化型アシスタントAI」、具体的には「法務AI」を用いた法務契約書の検討および修正をサポートするシステム開発の事例を共有しました。
「法務契約書の検討および修正」という非常に専門性の高いタスクに対して、現状のGPT-4oだけでは人のスペシャリストを超えるパフォーマンスは期待できないものの、アシスタントとしての機能は果たしているという事例から、「LLMにLLMの評価をさせる」というユニークな試みも紹介しました。
テキストを生成するLLM自体も、そのLLMを評価する手法もまだまだ研究が必要ですが、今後の進化の速度を考えると、「テキストの生成から評価まで自己完結し成長する」LLMが実現される日もそう遠くないかもしれません。
また、Givery AIラボのAIネイティブな考え方や開発力、ユーザー体験の最大化に対する思いも伝わっていれば幸いです。最後まで読んでいただきありがとうございました!
Givery AI Labについて
Givery AI Labが独自保有するフリーランス・副業の高単価AI案件や、随時開催しているセミナーやパーティなどのイベントにご興味ございましたら、ぜひTrack Worksのアカウント登録いただき、最新情報を受け取ってください!
「Track Works」とは?
Givery AI Labの運営会社である株式会社ギブリーが提供する、AI時代のフリーランスエンジニアとして「スキル」と「実績」を強化できる実践的なAI案件を、ご経歴やスキルに合わせてご紹介するフリーランスエンジニア案件マッチングサービスです。Givery AI Labが独自保有するフリーランス・副業案件を紹介したり、AI関連技術やエンジニアのキャリアに関するイベントを随時開催しています。
また、Givery AI Labメンバーとして就職・転職をご検討いただく場合は、下記からご応募くださいませ! (運営会社である株式会社ギブリーのエンジニア向け求人一覧ページです)
【企業のご担当者様へ】
Givery AI Labでは、PoCで終わらせない「AIの社会実装」を実現するため、AI開発プロジェクトのPoCから本格実装・運用まで、幅広く伴走支援しております。ぜひお気軽にお問合せください。
・AI開発プロジェクト伴走支援サービス:https://givery.co.jp/services/ai-lab/
・生成AI技術に関するお悩み解決サービス「Givery AI 顧問」:https://givery.co.jp/services/ai_advisor/
参考文献
G-eval論文
G-evalソースコード

Discussion