100日チャレンジ day2 (ECサイト)
昨日
100日チャレンジに感化されたので、アレンジして自分でもやってみます。
やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
できたもの
前回の振り返り
- いまのところAIに依頼するより自分でやった方がはるかに楽
- openapiのスキーマを出すのは1発だが、そのあとハンドラー、ユースケース、モデル、リポジトリ、DBをだすのにしこたま時間がかかる(明らかに得意不得意がある)
- なるべくMVCによせて作るものを減らす工夫がいる
- 作る順番をAIが理解しやすい順にする。たとえばスキーマ、API設計、モデル、db、コントローラーって感じかな
- webui作るところが html/templateだとしんどかったので、開き直ってreactやjqueryにしてみる?
- goのhot reloadである airの使い勝手があんまり良くない(bindエラーが頻発
- dbの永続化が複雑さを増してる。sqliteにすればコンテナは不要になる。最悪オンメモリでも良い
- 生成aiを変えると丸ごと作り直しぐらいのことしてくる。また途中までできたやつを完成に持っていこうとするとてんでダメ
- go.mod の tool ディレクティブでコマンド管理できるが go tool を毎度つけないといけないのが面倒
改善案
- Next.js(使ったことないけど) + TypeScript でフロント・バックエンドどっちも実装する
- js に寄せることでコマンドのインストールも npm に寄せる
- db は sqlite を利用しコンテナ不要で動かせるようにする
- デザインパターンをもっとシンプルなものにする
まずは知識がなさすぎるので技術選定を手伝ってもらう
生成AIの100日チャレンジに感化されたので、アレンジして自分でもやってみます。
## やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
毎日フロント+バックエンドのシンプルなアプリを作りたいです。
## 相談
一回 Go でやってみたのですが (day1_todo_app 配下)以下の問題がありました
- いまのところAIに依頼するより自分でやった方がはるかに楽
- openapiのスキーマを出すのは1発だが、そのあとハンドラー、ユースケース、モデル、リポジトリ、DBをだすのにしこたま時間がかかる(明らかに得意不得意がある)
- なるべくMVCによせて作るものを減らす工夫がいる
- 作る順番をAIが理解しやすい順にする。たとえばスキーマ、API設計、モデル、db、コントローラーって感じかな
- webui作るところが html/templateだとしんどかったので、開き直ってreactやjqueryにしてみる?
- goのhot reloadである airの使い勝手があんまり良くない(bindエラーが頻発
- dbの永続化が複雑さを増してる。sqliteにすればコンテナは不要になる。最悪オンメモリでも良い
- 生成aiを変えると丸ごと作り直しぐらいのことしてくる。また途中までできたやつを完成に持っていこうとするとてんでダメ
- go.mod の tool ディレクティブでコマンド管理できるが go tool を毎度つけないといけないのが面倒
そのため以下の改善をしたいです。
- Next.js(使ったことないけど) + TypeScript でフロント・バックエンドどっちも実装する
- js に寄せることでコマンドのインストールも npm に寄せる
- db は sqlite を利用しコンテナ不要で動かせるようにする
- クリーンアーキテクチャではなくデザインパターンをもっとシンプルなものにする
## お願いしたいこと
Next.js 周りの知見(ORMやその他のツール)について何も知見がないため、どのような技術スタックが2025/04/15現在推奨なのか(極力シンプルに作りたい)、またどのようなディレクトリ構成がよいのか?を考えてください
承知しました。Next.js と TypeScript を使って、シンプルかつ効率的に日々のアプリ開発を進めるための技術スタックとディレクトリ構成について提案します。シンプルさを重視し、学習コストを抑えつつ、目的であるバックエンド実装の練習に集中できる構成を目指します。
推奨技術スタック (2024/04/15時点)
| 種類 | 使うもの | 理由 |
|---|---|---|
| フレームワーク | Next.js (App Router) | フロントエンドとバックエンドを同一プロジェクトで管理でき、Reactベースで開発しやすい。現在の主流。 |
| 言語 | TypeScript | 型安全性により開発効率とコード品質を向上させる。Next.js との親和性も高い。 |
| データベース | SQLite | ご要望の通り。コンテナ不要でセットアップが容易。ローカル開発に最適。 |
| ORM | Prisma | TypeScript との相性が抜群に良く、型安全なDBアクセスが可能。マイグレーション機能も強力で扱いやすい。 |
| スタイリング | Tailwind CSS | ユーティリティファーストで迅速なUI構築が可能。Next.js が標準でサポートしており導入が容易。 |
| API実装 | Next.js Route Handlers (API Routes) | Next.js に組み込まれており、追加ライブラリ不要で簡単にAPIエンドポイントを作成できる。 |
| エラーハンドリング | 標準の try...catch / カスタムError |
シンプルなエラー処理で十分。必要に応じて特定の状況に対応するカスタムErrorクラスを作成する。 |
| ロギング | console.log / pino (必要に応じて) |
開発初期は console.log で十分。より高度なログが必要になった場合に pino などの軽量ロガーを導入。 |
| タスクランナー | npm scripts |
package.json で完結し、追加ツールの学習コストが不要。 |
推奨ディレクトリ構成
Next.js App Router の標準的な構成をベースに、シンプルさを保ちます。
/
├── app/ # App Router ディレクトリ (ルーティングとUIの中心)
│ ├── api/ # API Route Handlers (バックエンドAPI)
│ │ └── [entity]/ # 例: /api/tasks
│ │ └── route.ts # 各HTTPメソッド(GET, POST, PUT, DELETE)に対応する処理
│ ├── (pages)/ # UIページ (便宜的なグループ化)
│ │ └── [page_name]/ # 例: /tasks
│ │ ├── page.tsx # ページのUIコンポーネント (サーバー or クライアント)
│ │ └── components/ # そのページ固有のUIコンポーネント (任意)
│ ├── layout.tsx # アプリケーション全体の共通レイアウト
│ ├── globals.css # グローバルなCSS定義 (Tailwind CSSのベースなど)
│ └── page.tsx # ルート('/')のページ
├── components/ # アプリケーション全体で共有するUIコンポーネント
├── prisma/ # Prisma関連ファイル
│ ├── schema.prisma # DBスキーマ定義、データモデル定義
│ └── migrations/ # Prisma Migrateによって自動生成されるマイグレーション履歴
├── lib/ # 共通ロジック、ヘルパー関数、DBクライアントなど
│ └── db.ts # Prisma Client のインスタンス生成・管理
├── public/ # 静的ファイル (画像など)
├── .env.local # 環境変数 (DB接続情報など、.gitignoreに含める)
├── next.config.mjs # Next.js の設定ファイル
├── package.json # プロジェクト情報、依存パッケージ、npm scripts
├── tsconfig.json # TypeScript の設定ファイル
└── README.md # プロジェクトの説明
開発の進め方(例)
-
DBスキーマ定義:
prisma/schema.prismaにデータモデルを定義します。 -
マイグレーション:
npx prisma migrate dev --name initを実行して、スキーマ定義に基づいてSQLiteデータベースファイルとテーブルを作成します。(初回以降もスキーマ変更時に実行) -
API実装:
app/api/[entity]/route.tsにAPIエンドポイントを作成します。-
lib/db.tsから Prisma Client をインポートし、データベース操作(CRUD)を実装します。
-
-
UI実装:
app/(pages)/[page_name]/page.tsxにページのUIコンポーネントを作成します。-
fetchAPI やreact-query,swrなどのライブラリを使って、作成したAPIエンドポイントからデータを取得・表示・更新します。 - 共通化できるUI部品は
components/ディレクトリに作成します。
-
- スタイリング: Tailwind CSS のクラスを使ってUIの見た目を整えます。
シンプルさを保つためのポイント
-
アーキテクチャ: クリーンアーキテクチャのような厳密なレイヤー分けはせず、API Route Handlers 内で直接
lib/db.tsの Prisma Client を呼び出すなど、シンプルな構成を維持します。ロジックが複雑化してきたらlibディレクトリに関数を切り出す程度で十分でしょう。 - 状態管理: グローバルな状態管理が必要になった場合、まずは React Context API や Zustand のようなシンプルなライブラリから検討します。
- 認証: ユーザー切り替え機能で代替する方針が良いと思います。これも Context API や Zustand でユーザーIDを管理する程度で実現可能です。
この構成により、Go + OpenAPI の構成よりも学習コストを抑え、フロントエンドとバックエンドの開発をスムーズに行き来しながら、目的であるバックエンド実装の練習に集中できるかと思います。
Next.js プロジェクトの初期セットアップから始めますか? それとも、この構成案についてさらに質問はありますか?
template を Next.js に
rule も変更
今日のテーマは 「ECサイト」
以下AI出力。ここから削ぎ落とす
シンプルECサイト(day2)の要件案
基本機能
- 商品一覧表示
- 商品詳細表示
- カート機能(追加・削除・数量変更)
- 注文確定プロセス
- 注文履歴表示
データモデル
- 商品(Product):名前、説明、価格、画像URL、在庫数
- カート(Cart):ユーザーID、商品ID、数量
- 注文(Order):ユーザーID、注文日、合計金額、ステータス
- 注文明細(OrderItem):注文ID、商品ID、数量、価格
UI
- ヘッダー:ロゴ、カートアイコン、ユーザー切替
- 商品一覧ページ:カード形式の商品表示、フィルター機能
- 商品詳細ページ:商品情報、カートに追加ボタン
- カートページ:カート内商品一覧、数量変更、合計金額表示
- 注文確認ページ:お届け先情報入力、注文内容確認
- 注文完了ページ:注文番号表示、ありがとうメッセージ
- 注文履歴ページ:過去の注文一覧
追加機能(オプション)
- 商品カテゴリー分類
- 商品検索機能
- 在庫管理(購入時の在庫チェック)
- お気に入り機能
- 簡易管理画面(商品登録・編集)
- 割引/クーポン機能
技術的要件
- レスポンシブデザイン
- API設計(商品取得、カート操作、注文処理)
- データベーススキーマ設計(Prisma)
- サーバーサイドとクライアントサイドの適切な分離
一旦追加機能入らないのでそれ以外のところからかな。
今日は作成計画もAIに建ててもらおう
Webアプリケーション開発の理想的な順序(プロンプト形式)
1. **プロジェクト設計と初期化**
- プロジェクト構造の設計
- 開発環境のセットアップ
- 基本レイアウトとグローバルスタイルの作成
2. **データモデリングとバックエンド基盤**
- エンティティの特定と関係性の定義
- データベーススキーマの設計
- マイグレーションとシードデータの作成
3. **コアAPIエンドポイント実装**
- 基本的なCRUD操作のAPI実装
- エンティティ間の関連操作の実装
- APIのテストと検証
4. **認証・認可システム**
- ユーザー管理機能の実装
- 認証メカニズムの構築
- 権限管理の実装
5. **コアUIコンポーネント開発**
- 再利用可能な基本コンポーネント作成
- ページレイアウトの構築
- データ表示コンポーネントの実装
6. **主要機能のフロントエンド実装**
- 一覧表示と詳細表示の実装
- フォームとデータ送信機能の実装
- ユーザーフロー(主要業務フロー)の実装
7. **状態管理とデータフロー**
- アプリケーション状態の設計
- データ取得と更新の最適化
- クライアント-サーバー間の連携強化
8. **エラーハンドリングと検証**
- 入力検証の実装
- エラー表示とフィードバック機能
- エッジケースの処理
9. **UI/UXの改善**
- レスポンシブデザインの調整
- アクセシビリティの向上
- ユーザー体験の最適化
10. **テストと最終調整**
- ユニットテストと統合テスト
- パフォーマンス最適化
- 最終的なコードレビューと修正
この順序に従うことで、基盤から機能へ、そして洗練へと段階的に構築でき、各ステップが前のステップに依存する形で効率的に開発を進められます。
7 以降については完成度を求めないのでいらないかな。
そういえば gemini2.5 を使っていたのだがエラーがではじめたので今日は sonnet 3.7
Turbopackとは何かっていうと、JavaScriptとTypeScriptのために最適化された、Rustで書かれたインクリメンタルなバンドラーのことを指します。このTurbopackはNext.jsに組み込まれているんですよ。
Rustで書かれたTurbopackは、生産にのみ必要な最適化作業をスキップすることで、より高速にバンドルを行うことができるとのこと。Turboビルドエンジンで、スケジュールされたすべての関数の結果をキャッシュし、同じ作業を二度行う必要がないようにしているようです。
「そもそもバンドラーって何?」って思いますよね。ざっくり言うと、バンドラーは、複数のJavaScriptファイルやモジュールを、一つまたは複数の出力ファイルにまとめ上げてくれるツールのことを指します。このまとめ上げ作業を高速化するのが、このTurbopackの役目なんです。

いきなりそれっぽいやつができた
うーん画像どうやって集めようか。
いらすとや mcp が欲しいな〜
画像は svg を採用し、svg の中身をそれっぽくつくってもらうことにする
Prisma Seed データ
seed って使ったことなかったけど初期から入れたいパラメータのことか。
テストデータ入れるのにぴったりだ。
ゲームやエンタメだとマスターデータがあるので seed 使わないけど他のやつはこうするのか
svg の作成を工夫してもらったらめっちゃいい感じになった

どこに fetch してるの?
fetch('/api/orders?userId=${currentUser.id}') のように 相対パス (/ で始まるパス) を指定した場合、fetch は自動的に 現在表示しているページのオリジン (origin) を基準にして絶対URLを組み立てます。
開発環境 (npm run dev などで起動した場合) では、Next.js アプリケーションは通常 http://localhost:3000 で動作しています。
したがって、ブラウザで http://localhost:3000/some-page のようなページを開いている状態で fetch('/api/orders') を実行すると、ブラウザは自動的に現在のオリジンである http://localhost:3000 を補完し、結果的に http://localhost:3000/api/orders という URL にリクエストを送信します。
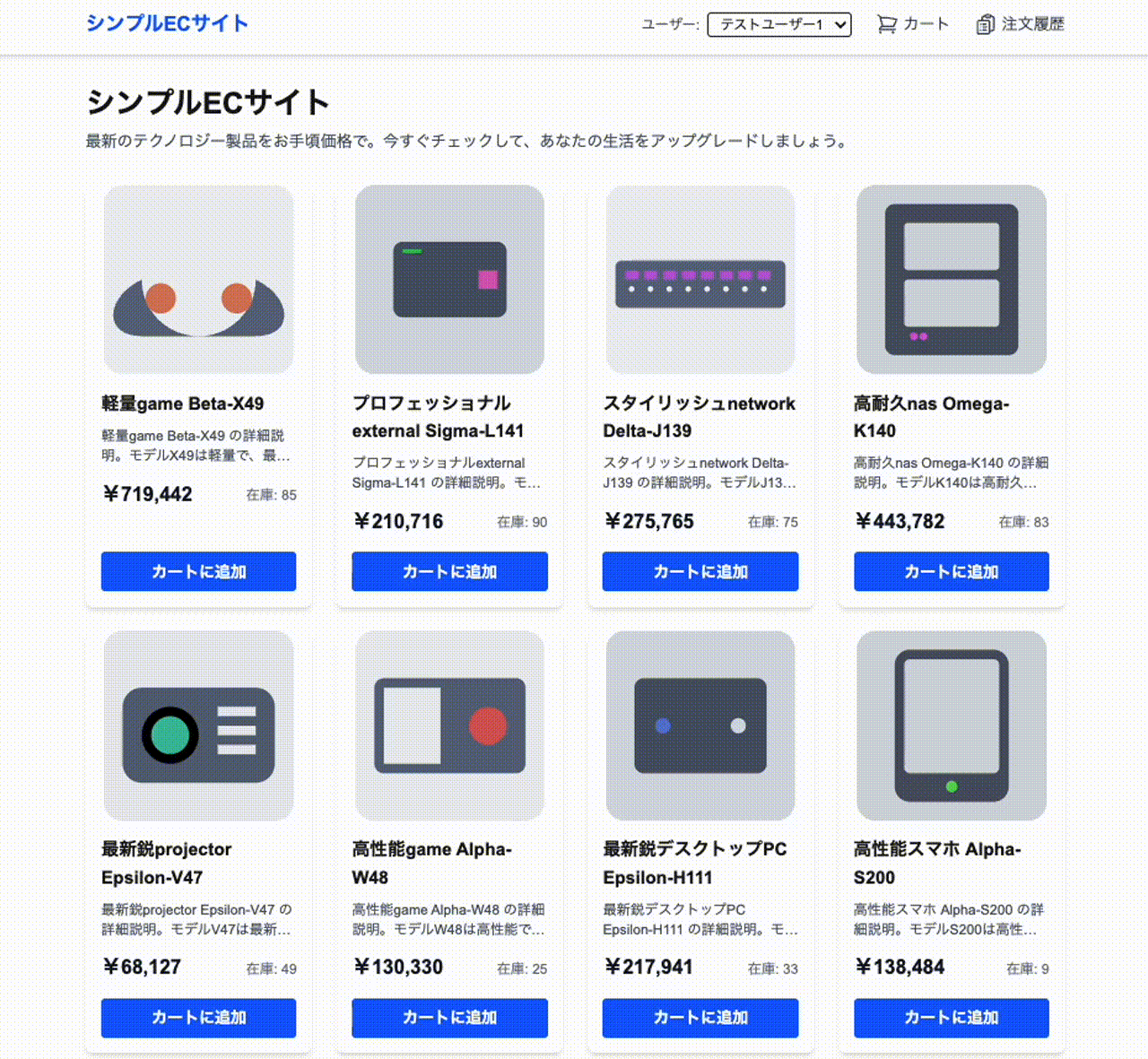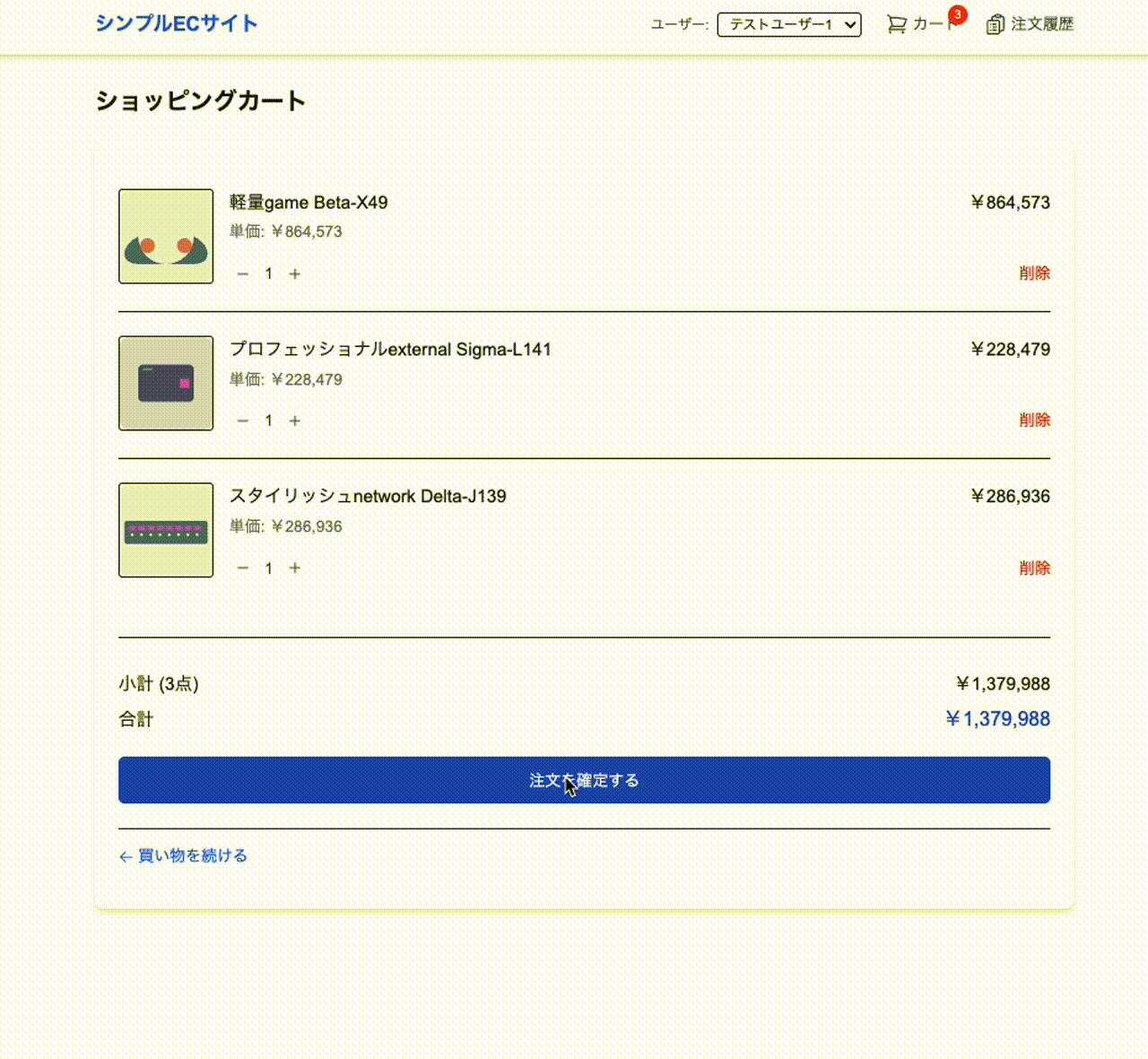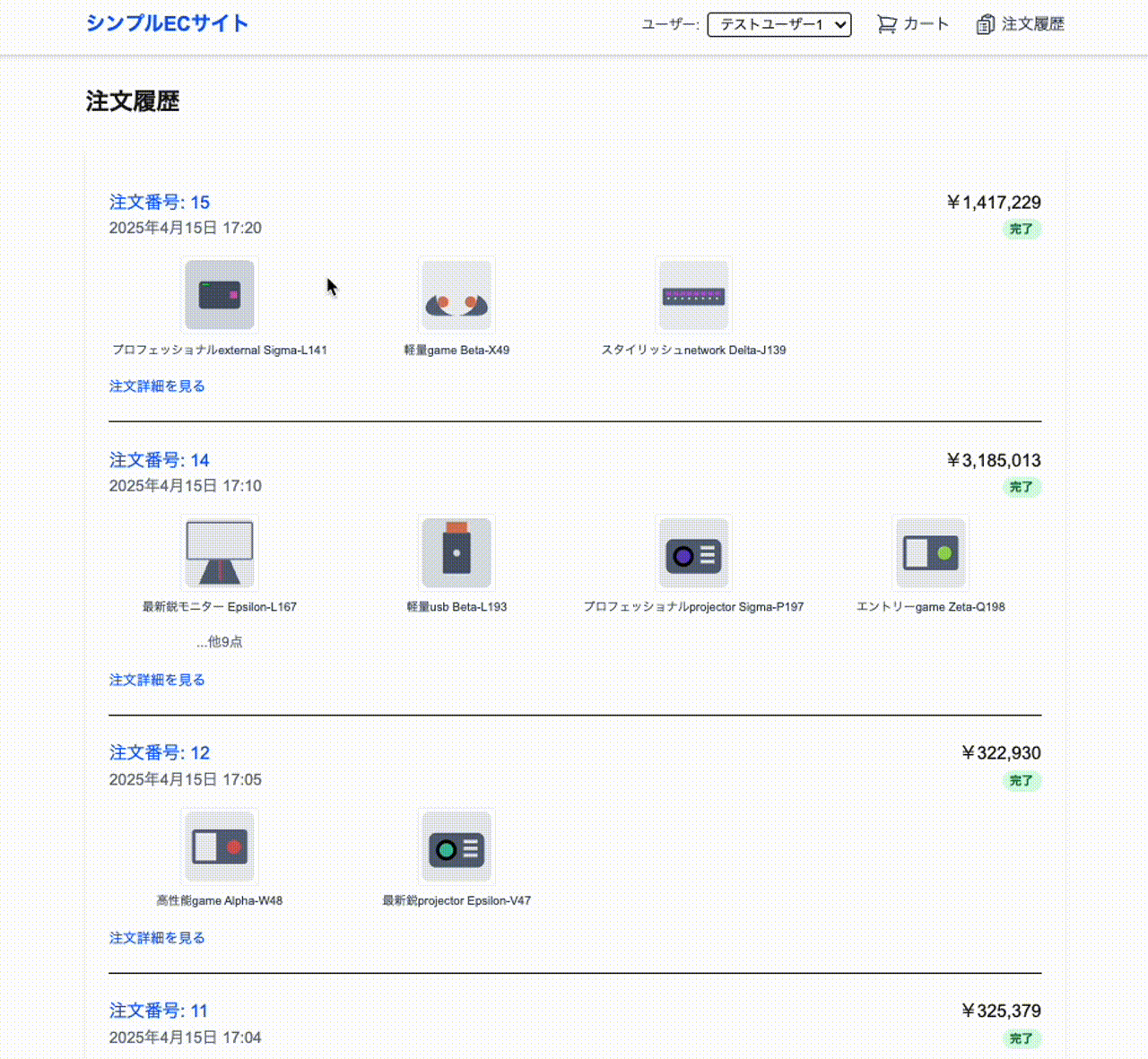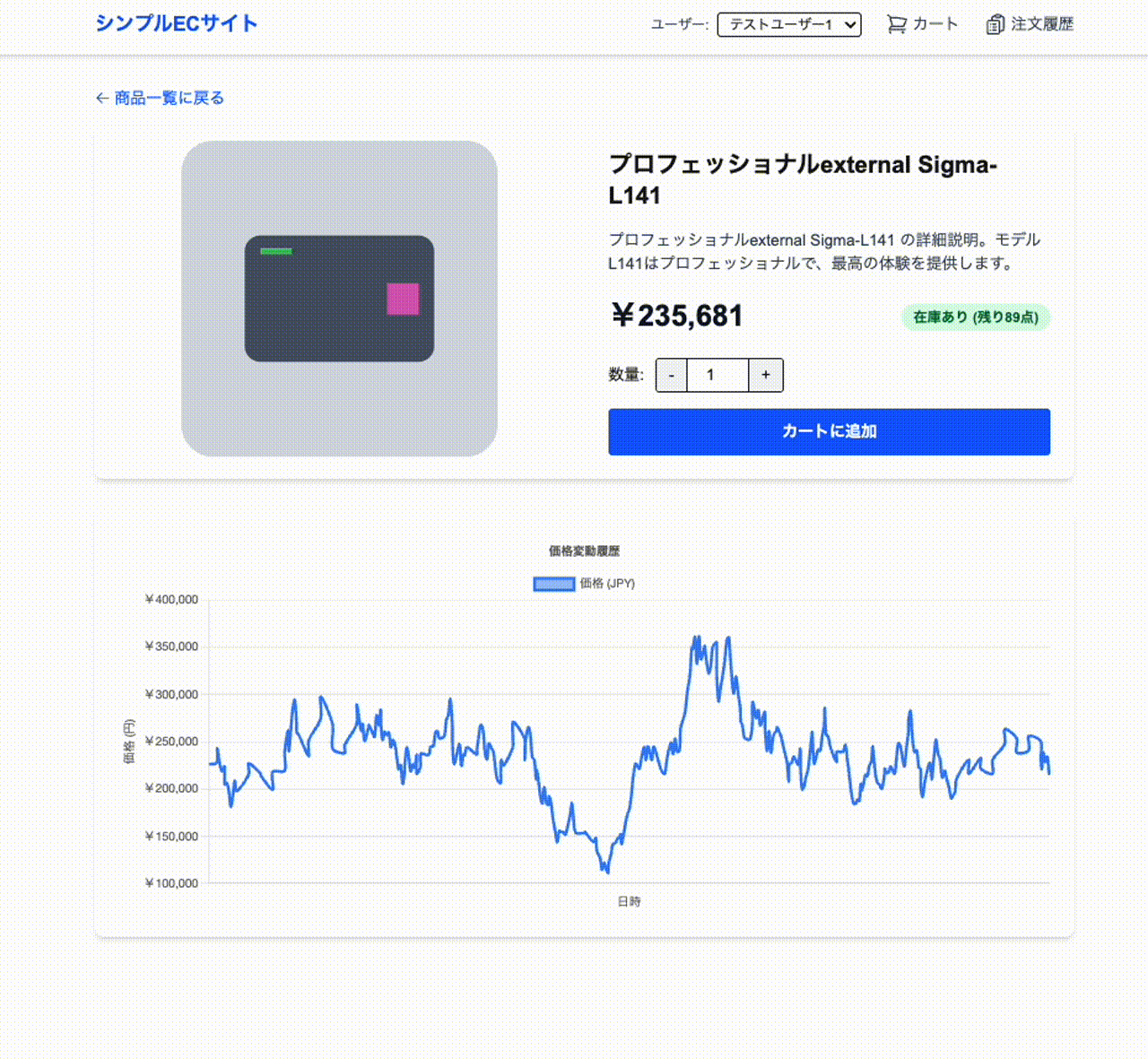
[追加機能] 価格を変えられるようにする
現状価格が商品にくっついてしまっており価格を変えられないので対応する。
以下AI
なるほど、価格変更の要件について理解しました。過去の注文履歴に影響を与えず、かつ価格変動を自動化する、より実践的な設計を考えます。
機能概要:
商品の価格は時間とともに変動するものとし、その履歴を記録します。過去の注文はその注文時点での価格を参照します。価格の変動は、システムによって定期的に自動実行されるバッチ処理によって行われます。
設計詳細:
-
データベーススキーマ変更 (
prisma/schema.prisma):-
Productモデル:- 既存の
priceフィールドを 削除 します。商品自体には固定の価格を持たせず、価格履歴を参照するようにします。
- 既存の
-
新規モデル
ProductPrice:- 商品の価格履歴を記録するための新しいモデルを作成します。
- フィールド:
-
id: Int (Primary Key, 自動インクリメント) -
price: Int (その時点での価格) -
startDate: DateTime (この価格が有効になった日時、デフォルトは現在時刻) -
productId: Int (どの商品に対する価格かを示す外部キー) -
product:Product(上記productIdに対応するリレーション)
-
- リレーション:
Productモデル側にprices: ProductPrice[]を追加します。 - インデックス:
productIdとstartDateにインデックスを設定すると、特定商品の最新価格の取得が効率的になります (@@index([productId, startDate]))。
-
OrderItemモデル:-
priceフィールドは そのまま保持 します。注文作成時に、その時点での有効な商品価格をこのフィールドに コピーして記録 します。これにより、ProductPriceが後で更新されても、注文履歴上の価格は不変になります。
-
-
マイグレーション: 上記変更を反映させるために
npx prisma migrate dev --name add_product_price_historyを実行します。
-
-
価格取得ロジックの変更:
- 商品一覧や詳細ページで「現在の価格」を表示する場合:
- 該当する
productIdを持つProductPriceレコードの中から、startDateが 最も新しい レコードを取得し、そのpriceを表示します。 - Prisma のクエリ例:
const latestPrice = await prisma.productPrice.findFirst({ where: { productId: targetProductId }, orderBy: { startDate: 'desc' }, }); const currentPrice = latestPrice ? latestPrice.price : 0; // 価格が見つからない場合のデフォルト値
- 該当する
- このロジックは、価格を表示するすべてのコンポーネントやAPIで共通して利用できるように、
libディレクトリなどにヘルパー関数として実装するのが望ましいです (例:getCurrentProductPrice(productId: number))。
- 商品一覧や詳細ページで「現在の価格」を表示する場合:
-
注文作成ロジックの変更 (
/api/ordersの POST ハンドラーなど):- ユーザーが商品をカートに入れて注文を確定する際:
- 注文処理の中で、カート内の各商品について 現在の有効価格 を
ProductPriceテーブルから取得します (上記2と同じロジック)。 - 取得した価格を、作成する
OrderItemレコードのpriceフィールドに 設定 します。 - これにより、注文確定時の価格が
OrderItemに永続化されます。
- 注文処理の中で、カート内の各商品について 現在の有効価格 を
- ユーザーが商品をカートに入れて注文を確定する際:
-
自動価格更新機能 (バッチ処理):
-
価格更新スクリプト:
-
prisma/updatePrices.tsのような独立したTypeScriptスクリプトファイルを作成します。 - このスクリプトは Prisma Client を利用してデータベースに接続します。
- 処理内容:
- 価格を更新したい商品群を取得します (例: 全商品、特定のカテゴリの商品など)。
- 各商品について、現在の最新価格 (
ProductPriceの最新レコード) を取得します。 - 新しい価格を決定するロジックを適用します。
- シンプルな例: 最新価格に対して ±N% の範囲でランダムに変動させる。
- より複雑な例: 在庫数、売上動向、期間などを考慮したルールベースの価格決定(初期実装ではシンプルにランダム変動が良いでしょう)。
- 決定した新しい価格で、新しい
ProductPriceレコードをprisma.productPrice.create()を使って作成します。startDateは自動的に現在時刻が設定されます。古い価格レコードは削除せず、履歴として残します。
-
-
定期実行:
-
方法1 (Node.jsライブラリ):
node-cronのようなライブラリをプロジェクトに追加し、上記スクリプトを定期実行するジョブを設定します。このジョブはNext.jsのプロセスとは別に実行する必要があります。 - 方法2 (外部サービス): Vercel Cron Jobs や GitHub Actions Schedule、またはOSのcronなど、外部のスケジューリングサービスを利用して、特定のAPIエンドポイント(このためだけに用意する)を叩くか、直接スクリプトを実行します。
-
方法3 (手動実行):
package.jsonのscriptsに"update-prices": "npx ts-node prisma/updatePrices.ts"のようなコマンドを追加し、当面は開発者が手動で実行します。自動化は後から導入することも可能です。
-
方法1 (Node.jsライブラリ):
- 初期実装: まずは 方法3 (手動実行) を実装し、価格更新スクリプトのロジックを確立するのが現実的です。
-
価格更新スクリプト:
この設計による影響:
-
メリット:
- 価格変更が過去の注文に影響を与えなくなります。
- 価格の変動履歴がデータベースに記録されます。
- 価格変動を自動化する基盤ができます。
-
デメリット:
- データベース構造が少し複雑になります。
- 価格を取得するクエリが若干複雑になります (常に最新のものを探す必要がある)。
- 自動更新のためのバッチ処理(スクリプトと実行環境)の準備が必要です。
次のステップ:
この設計案で進める場合、以下の手順になります。
-
prisma/schema.prismaを修正 (Product.price 削除、ProductPrice モデル追加)。 -
npx prisma migrate dev --name add_product_price_historyを実行。 -
prisma/seed.tsを修正。商品作成時にpriceを直接設定する代わりに、初期価格を持つProductPriceレコードを作成するように変更。 - 価格表示箇所(商品一覧、詳細など)で、最新価格を
ProductPriceから取得するように修正。 - 注文作成API (
/api/ordersの POST) で、OrderItem.priceに注文時の最新価格を設定するように修正。 - 価格自動更新スクリプト (
prisma/updatePrices.ts) を作成。 -
package.jsonに手動実行用のスクリプトコマンドを追加。
この設計案でよろしければ、まずはスキーマ変更とマイグレーションから進めましょう。
定期的な価格の更新を別のジョブ使うのしんどいのでフロントから定期的に更新する形とする
npx prisma migrate dev で y/n がでるので止まるのが困る。
なんとかする。 expect はいや
↓
- DBスキーマを変更した場合は
prisma migrate deployでお願いします。(prisma migrate devだと安全ではありますが、interactive になって生産性が落ちるため)
価格のグラフを出せるようにした
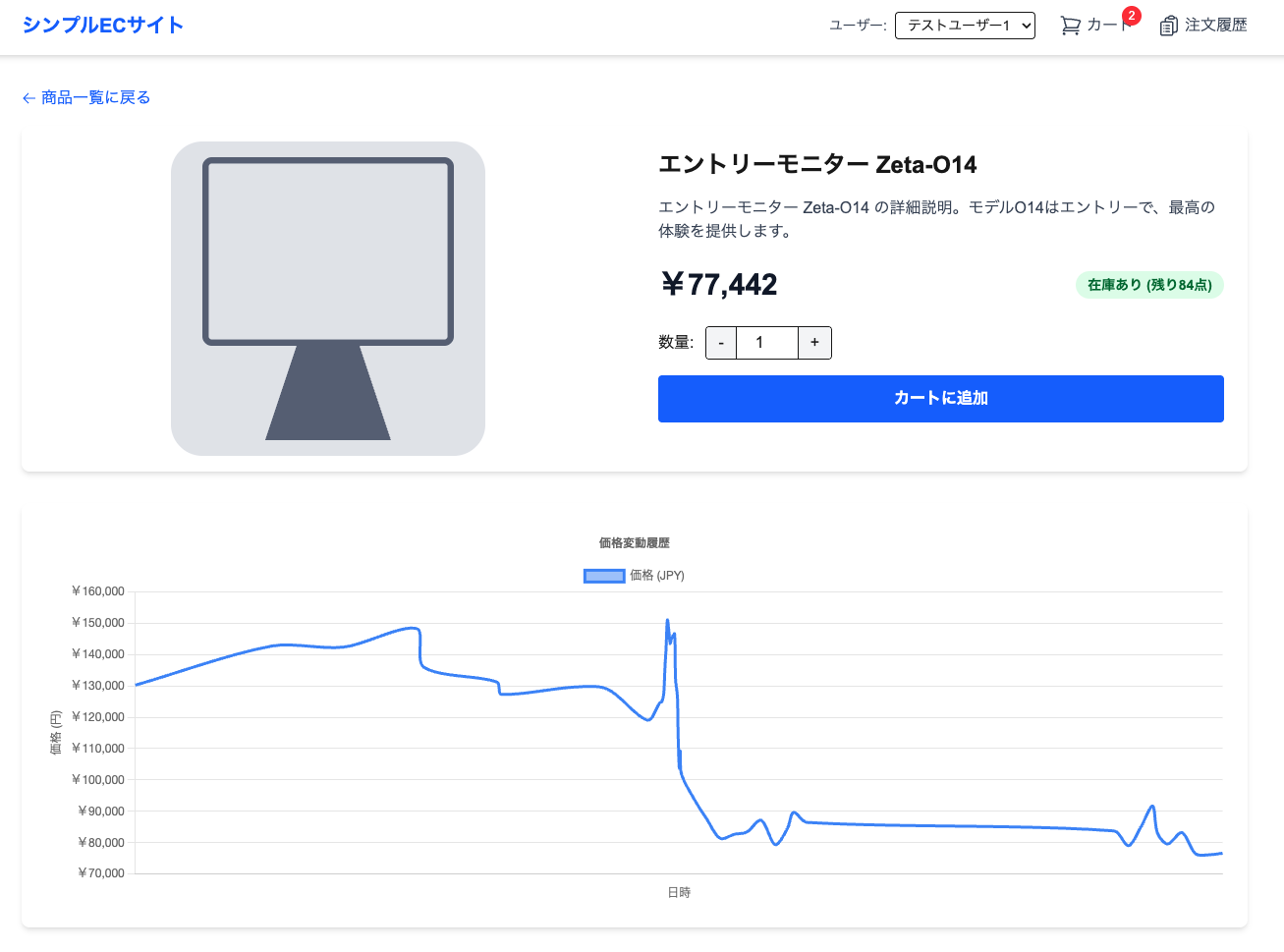
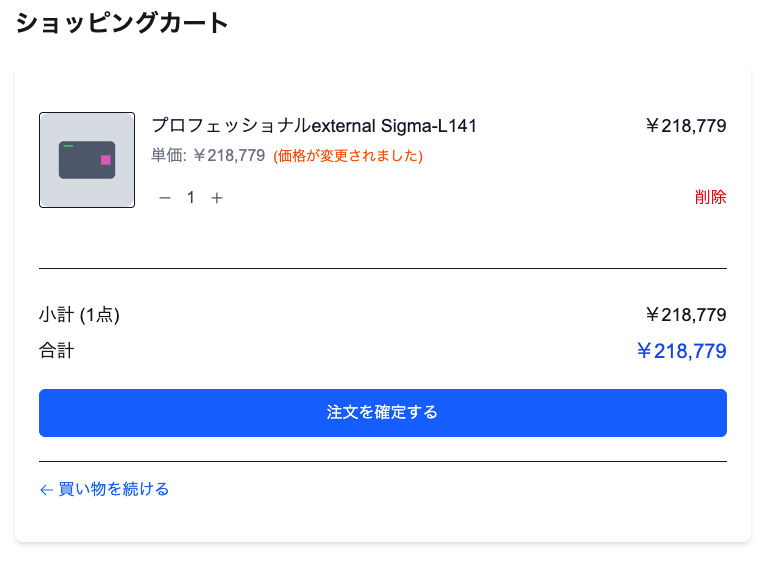
カートに入れた後に価格が変わると、その価格で支払いが発生してしまう問題が起きた
これな〜。どっちがいいんだろう。価格変わったら買わせたくないよなあ。
一般的にどっちなのか調べてみよう
ECサイトでカートに入れた商品の価格が更新された場合の対応は、ユーザー体験(UX)とビジネス上の判断(利益、運用コスト)のバランスを取る必要があり、いくつかの一般的なパターンがあります。
ユーザーが挙げた選択肢と、それ以外の一般的な方法を考慮すると、以下のような対応が考えられます。
1. カート内で価格を更新し、変更があったことを明示的に伝える(最も一般的で推奨される方法)
- 挙動: ユーザーがカートページを開いた時点、またはチェックアウトに進む時点で、システムはカート内の商品の現在の価格をチェックします。もしカート追加時と価格が変わっていれば、カート内の表示価格を新しい価格に更新します。
-
通知方法:
- 価格が変わった商品に対して、「価格が更新されました」「値下げ/値上げされました」といったメッセージを表示する。
- 可能であれば、以前の価格(カート追加時の価格)と新しい価格の両方を表示する(例:
<strike>¥1,000</strike> → ¥1,200や¥1,000 から ¥900 に値下げ)。 - 特に価格が上がった場合は、ユーザーが意図しない高額な請求を避けるためにも、明確に伝えることが重要です。
- 価格が下がった場合は、ポジティブな情報として伝えることができます。
-
メリット:
- 透明性が高い。ユーザーは常に最新の正しい価格で購入することになる。
- 最終確認画面での不意打ちを防ぎ、カート段階でユーザーに判断を委ねられる。
- ビジネス側は常に最新の価格で販売できる。
-
デメリット:
- 価格が上がった場合、ユーザーが購入をためらう可能性がある(ただし、これはどのタイミングで伝えても起こりうること)。
2. 購入手続きの最終確認画面で価格が変わったことを伝える
- 挙動: カートページでは古い価格のまま、または更新されているが特に通知せず、最後の「注文確定」ボタンがある画面で、「〇〇の価格が¥XXXから¥YYYに変更されました」と最終警告を出す。
-
メリット:
- 最新の価格は反映される。
-
デメリット:
- 購入プロセスの最終段階での予期せぬ価格変更は、ユーザーの不満や離脱(カゴ落ち)に繋がりやすい。カート画面で気づけた方が親切。
- UX的にはあまり推奨されない。
3. 以前の価格(カート追加時の価格)のまま購入できる
- 挙動: ユーザーがカートに追加した時点での価格を記録しておき、その価格で購入できるようにする。
-
メリット:
- ユーザーにとっては非常に親切。価格変動による不満が生まれない。特に価格が上がった場合に有効。
-
デメリット:
- 価格が上がった場合、サイト運営側の利益が減る。
- 価格が下がった場合、ユーザーは損をした気分になる可能性がある(この場合だけ新価格を適用する、というハイブリッドも考えられるが、実装が複雑になる)。
- カート追加時の価格をユーザーセッションやアカウントに紐づけて保持する必要があり、システムが複雑になる。
- 長期間カートに保持された場合の価格乖離リスクがある(例: セール価格でカートに入れ、セール終了後もその価格で買えてしまうなど)。これを防ぐには「カート追加から〇時間以内」などの有効期限ルールが必要になる場合がある。
- 一般的な価格改定(仕入れ値変動など)でこの方式を採用しているケースは稀。期間限定セールなどで一時的に採用されることがある程度。
4. 勝手に新しい価格になる(通知なし)
- 挙動: カート内や購入確認画面で、ユーザーに特に通知せずに価格が新しいものに更新されている。
-
メリット:
- 実装は(通知部分を作らないなら)比較的単純。
-
デメリット:
- 絶対に避けるべき方法。 ユーザーの信頼を著しく損なう。「気づかずに高い値段で買わされた」と感じさせ、クレームやサイト離脱の原因になる。不親切で、場合によっては不誠実とみなされる。
5. カートから該当商品を削除する
- 挙動: 価格が変更された(特に値上げされた)商品をカートから自動的に削除し、「〇〇は価格が変更されたため、カートから削除されました」のような通知を出す(あるいは通知も出さない)。
-
メリット:
- 意図しない価格での購入は防げる。
-
デメリット:
- ユーザーが購入しようとしていた商品を勝手に削除されるのは、非常に悪いUX。ユーザーは再度商品を探してカートに入れ直す手間がかかるか、購入意欲を失う。これも避けるべき方法。
結論として
最も一般的でバランスの取れた方法は「1. カート内で価格を更新し、変更があったことを明示的に伝える」です。
- 透明性: ユーザーは常に最新の価格情報を把握できます。
- UX: 購入最終段階での不意打ちを防ぎ、早い段階でユーザーに情報を提供します。
- ビジネス: 常に最新の価格で販売できます。
実装としては、カートページを表示する際やチェックアウトプロセスに進む際に、カート内の各商品の現在のマスター価格を再取得し、カート追加時の価格と比較して差分があれば表示を更新し、変更通知を表示する、という流れになります。
リロードすれば価格の変更がわかるようになった
これを入れてたんだけど、結構エラーになるので消した。
AI生成なら問題ないでしょ
ずっと同じエラーに悩まされ続けたが gemini2.5 から claude 3.7 に変えたら直してくれた。
ハマったら LLM をかえるというアプローチか
ec サイト作ったこともないし、next や prisma もわからんけど、なんか勘所とか ai のサポートがあればなんとなく作れるな〜〜
next の hotreload が便利すぎて。。。
なんかフロントとバックエンドにまたがる新機能を作ってと依頼したら結構苦労してる。
これはもう少し明確に指示を出さないとダメかもしれない。
ある程度ロジックを考えてあげて一緒にやるのがいいのだろうか
※next よくわからん
cursor のLLMを途中で切り替えてもコンテキストを残せるのって、毎度全部なげてるのかなあ
ai が価格変わった時に 409 をつかってた
HTTP 409 Conflict はクライアントエラーレスポンスのステータスコードで、リクエストが現在のサーバーの状態と競合したことを示します。
ちょっと踏み込んだ感じでお願いしたらめっちゃ良い感じに作ってくれた

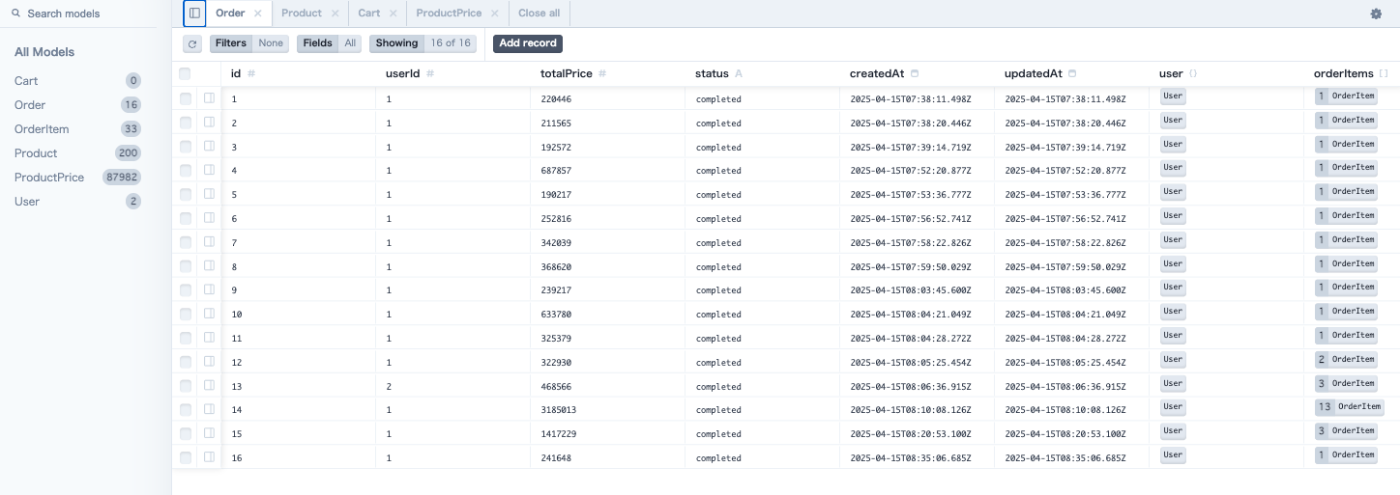
prisma studio 便利すぎる
npx prisma studio
疑問
amazon って大量の商品があり、それに紐づく価格があると思うのだけどそれってどういうDBとアーキテクチャで管理してるのかな? aurora に水平スケールしてるのだろうか?
Amazonほどの巨大なECサイトが、膨大な商品カタログとそれに紐づく価格情報をどのように管理しているか、その正確な内部アーキテクチャは公開されておらず、最高レベルの企業秘密の一つです。したがって、これから述べることは、一般的な大規模システムの設計原則やAWSのサービス群から推測される、可能性の高い構成についての考察になります。
結論から言うと:
- Amazonが商品カタログや価格管理のすべてをAuroraだけで、単純な水平スケール(リードレプリカの追加)だけで賄っている可能性は極めて低いと考えられます。
- 実際には、複数のデータベース技術(Polyglot Persistence)を組み合わせた、非常に高度なマイクロサービスアーキテクチャを採用している可能性が非常に高いです。Auroraもその一部として特定の役割で使われている可能性はありますが、中心的な役割を担うのはNoSQLデータベース、特にDynamoDBであると推測するのが最も合理的です。
考慮されるであろうアーキテクチャ要素とデータベースの役割:
-
マイクロサービスアーキテクチャ:
- 商品カタログ、価格設定、在庫管理、セラー情報、レビュー、注文処理などが、それぞれ独立したマイクロサービスとして構築されていると考えられます。
- 各マイクロサービスは、自身の要件に最適なデータストア技術を選択します。
-
データストアの使い分け (Polyglot Persistence):
-
商品カタログデータ (コア情報、属性):
- DynamoDB (NoSQL - Key-Value/Document): 最も可能性が高い選択肢です。数十億の商品、それぞれ異なる属性(書籍のISBN、服のサイズ・色、家電のスペックなど)を持つ柔軟なスキーマに対応でき、予測可能な低レイテンシで、ほぼ無限の水平スケーラビリティ(Read/Write)を提供します。Amazon自身がこの種の問題を解決するためにDynamoDBを開発した背景もあります。
-
価格データ:
- DynamoDB: 商品IDをキーとして価格を高速に読み書きするのに適しています。頻繁な価格更新(手動、自動価格調整、セール、マーケットプレイスの競合)に対応できるスケーラビリティがあります。Global Tablesを使えば、世界中のリージョンに低レイテンシで価格情報を複製できます。
- インメモリデータベース (例: Redis, Memcached): ユーザーがブラウジングする際の価格表示の超高速化のために、DynamoDBなどのプライマリDBの前段に、キャッシュとして多用されていることは間違いありません。
-
在庫データ:
- DynamoDB または Aurora: 在庫数はトランザクション整合性が重要(売り越しを防ぐ)であり、頻繁な更新が発生します。DynamoDBのトランザクション機能やアトミックカウンターを使うか、あるいは強い整合性が必要な部分ではAuroraのようなRDBが使われる可能性も考えられます。
-
検索インデックス:
- Amazon OpenSearch Service (Elasticsearch): 商品検索機能は、ほぼ間違いなく専用の検索エンジン基盤上に構築されています。商品データが更新されると、非同期で検索インデックスに反映されます。
-
リレーショナルデータ (セラー情報、注文データの一部、複雑なプロモーションルールなど):
- Aurora (RDB): 強い一貫性や複雑なJOIN、トランザクションが必要なデータ(例: 支払い処理、セラーアカウント管理、特定のプロモーションルールの管理など)には、Auroraのようなリレーショナルデータベースが使われている可能性は十分にあります。Auroraのリードレプリカによる水平スケール(Read)も活用されているでしょう。しかし、Amazon全体のカタログや価格の主要なデータストアとしては、NoSQLほどのスケーラビリティ(特にWrite)や柔軟性を提供できない可能性があります。
-
商品カタログデータ (コア情報、属性):
-
非同期処理とイベント駆動:
- 価格変更、在庫更新、新商品登録などは、イベントとして発行され、関連するマイクロサービス(キャッシュ更新、検索インデックス更新など)が非同期で処理を進めるイベント駆動型アーキテクチャが多用されているはずです (SQS, SNSなどを活用)。
-
キャッシュの徹底活用:
- CDN (CloudFront) でのコンテンツキャッシュ、アプリケーションレベルでのキャッシュ、データベースクエリキャッシュなど、あらゆるレイヤーでキャッシュを活用し、表示速度の向上とバックエンドDBへの負荷軽減を図っているはずです。特に価格のような頻繁に読み取られるデータはキャッシュされている可能性が高いです。
まとめ:
Amazonのシステムは、単一のデータベース技術に依存するのではなく、DynamoDBのようなNoSQLデータベースを中心に、インメモリキャッシュ、検索エンジン、そして部分的にAuroraのようなRDBを適材適所で組み合わせた、非常に洗練されたマイクロサービスアーキテクチャで構成されていると考えるのが自然です。Auroraの水平スケール(Read)も活用されている可能性はありますが、Amazonの桁違いの規模とデータ特性(特に商品カタログと価格)に対しては、DynamoDBのようなNoSQLデータベースが持つスケーラビリティと柔軟性が、より中心的な役割を果たしている可能性が高いと言えるでしょう。
dynamodb と検索エンジンとで同期取るのきつくない?また商品価格については強整合性が求められるだろうから、RDBMSに入ってる気がする。その場合って 3phase commit? みたいになるの?
dynamodb と検索エンジンとで同期取るのきつくない?
おっしゃる通り、異なるデータストア間でデータを同期させるのは、分散システムにおける典型的な課題であり、単純ではありません。しかし、「きつい」かどうかは、利用する技術や設計パターンによります。
一般的な解決策: DynamoDB Streams + Lambda
現在、最も一般的でAWSネイティブな解決策は DynamoDB Streams を利用するパターンです。
- DynamoDB Streamsの有効化: DynamoDBテーブルへの変更(追加、更新、削除)が発生すると、その変更内容が時系列で記録されたストリームが生成されます。
- Lambdaトリガー: このDynamoDBストリームのイベントをトリガーとして、AWS Lambda関数を起動します。
- Lambda関数による同期処理: Lambda関数は、ストリームから変更データを受け取り、そのデータに基づいて検索エンジン(Amazon OpenSearch Serviceなど)の対応するドキュメントを更新(または追加・削除)します。
この方法のポイント:
- 非同期処理: 同期は非同期で行われます。DynamoDBへの書き込みが完了してから、Lambdaが処理を行い検索エンジンに反映されるまでには、通常ミリ秒〜秒単位の遅延が発生します。これは結果整合性 (Eventual Consistency) と呼ばれる状態です。
- マネージドサービス: DynamoDB StreamsもLambdaもAWSのマネージドサービスなので、インフラ管理の手間は大幅に削減されます。開発者は主にLambda関数のロジックに集中できます。
- スケーラビリティ: DynamoDB StreamsもLambdaも高いスケーラビリティを持っています。
- 耐障害性: Lambdaが一時的に失敗しても、リトライ機構があるため、データの同期漏れのリスクを低減できます。
「きつい」かどうか?
- 実装の手間: 確かに、Lambda関数の開発、エラーハンドリング、監視などの実装・運用コストはゼロではありません。
- 結果整合性の許容: 検索結果がプライマリDBに対して常にミリ秒単位で最新であることを保証する必要がある場合は「きつい」かもしれません。しかし、ECサイトの商品検索のようなユースケースでは、通常、数秒程度の遅延は許容されることが多いです。
- 標準的なパターン: この方法は、AWSを利用したシステムでは非常に一般的で確立されたパターンであり、多くの実績があります。「不可能」や「過度に困難」というわけではありません。
また商品価格については強整合性が求められるだろうから、RDBMSに入ってる気がする。
これは非常に重要なポイントです。価格の整合性について考えてみましょう。
-
強い整合性 (Strong Consistency) が本当に常に必要か?
- ユーザーが商品をブラウジングしている時: この時点では、ミリ秒〜秒単位で古い価格が表示されても、致命的な問題にはなりにくいです。むしろ、表示速度の方が重要視される場合があります。結果整合性でも許容できるケースが多いでしょう。
- ユーザーが商品をカートに入れた時: この時点での価格は記録されるかもしれませんが、最終的な購入価格ではない可能性があります(前の質問の通り)。
- ユーザーが注文を確定する時: この瞬間が最も重要です。 ユーザーが「支払う」ボタンを押す時に表示されている価格、あるいはシステムが最終的に計算した価格は、正確でなければなりません。
-
DynamoDBでの強い整合性: DynamoDBは、オプションで強い整合性のある読み込み (Strongly Consistent Read) を提供しています。これは結果整合性のある読み込みよりもレイテンシが高くなる可能性があり、コストも少し高くなりますが、最新の書き込み結果を保証します。
-
RDBMSの利点: RDBMS (Auroraなど) は、デフォルトで強い整合性を提供し、複雑なトランザクション(例: 特定の条件下でのみ価格を更新する)を管理しやすいという利点があります。
考えられるアプローチ:
-
DynamoDB + 最終確認で強い整合性読み込み:
- 普段のブラウジングや検索では、キャッシュや結果整合性のある読み込みで高速表示。
- チェックアウトの最終確認画面や注文確定処理の内部では、カート内の商品の価格をDynamoDBから強い整合性のある読み込みで再取得し、正確な価格で決済に進む。
-
RDBMSに価格を保持:
- 価格データだけ、あるいは価格に関連する重要なデータ(プロモーションルールなど)をAuroraのようなRDBMSに保持し、強い整合性を保証する。商品カタログの他の柔軟性が求められる部分はDynamoDBに置く。
- この場合、注文処理時に商品情報(DynamoDB)と価格情報(RDBMS)の両方を参照する必要が出てくる可能性があります。
Amazonのような規模では?
Amazonほどの規模と更新頻度を考えると、スケーラビリティの観点からDynamoDBのようなNoSQLをプライマリとし、重要な局面(決済時)で強い整合性読み込みを使うか、あるいはキャッシュ戦略と組み合わせる方が現実的かもしれません。ただし、価格設定ロジックが非常に複雑で、RDBMSのトランザクション機能が不可欠な部分があれば、そこだけRDBMSを使う可能性も否定できません。
その場合って 3phase commit? みたいになるの?
もし、価格情報がRDBMSにあり、商品情報や在庫情報が別のDB(例: DynamoDB)にあるような構成で、かつ「注文確定時に価格、在庫、注文ステータスなどを複数の異なるデータベースシステムにまたがってアトミックに更新」しようとするならば、分散トランザクションの問題に直面します。
-
2PC/3PC (2相/3相コミット): これらは分散トランザクションを実現するためのプロトコルですが、以下のような大きな欠点があります。
- 複雑性: 実装と管理が非常に複雑。
- パフォーマンス: 関係するすべてのシステム間で調整が必要なため、レイテンシが増大する。
- 可用性: 一つの参加ノードが応答しないだけで、トランザクション全体がブロックされる可能性がある(特に2PC)。
-
Sagaパターン: そのため、現代のマイクロサービスアーキテクチャでは、2PC/3PCのような強い一貫性を保証する分散トランザクションは避けられる傾向にあります。代わりに、Sagaパターンのような結果整合性をベースにしたアプローチがよく用いられます。
- Sagaは一連のローカルトランザクションで構成されます。各ローカルトランザクションは自身のDBを更新し、次のステップをトリガーするイベントを発行します。
- 途中のステップで失敗した場合、「補償トランザクション (Compensating Transaction)」を実行して、それまでに行った処理を取り消します。
- これにより、システム全体としては最終的に一貫した状態になりますが、トランザクションの途中では一時的に不整合な状態が存在し得ます。
結論として:
Amazonのような大規模システムでは、パフォーマンスと可用性を最大限に高めるため、2PC/3PCのようなコストの高い分散トランザクションは極力避け、DynamoDB Streamsによる非同期連携や、Sagaパターンによる結果整合性をベースにした設計を採用している可能性が高いと考えられます。価格の正確性が求められる「注文確定」の瞬間には、ターゲットを絞った強い整合性読み込みや、RDBMS内のローカルトランザクション、あるいは楽観的ロック/バージョン管理などのテクニックを駆使して整合性を担保していると推測されます。
振り返り/ 学び
- Next.js にしたら嘘のように順調に最初つくってくれた、今後これでいく
- 最初に仕様から考えてもらって、そこから人が削り、さらに実装方針を立ててもらうのがコツ
- エラーの沼にはまったら、LLM を変更する戦略はあり
- prisma がすごい便利
- hot reload が便利
- 作ってくれるデザインが個人的には好き
- SVG で画像生成させるのが素晴らしい(自由度が高いし高いクオリティで作ってくれる)
- ecサイトは商品価格の変更をユーザにどう見せるかが大事
- AIに丸ごと作ってもらうと全体の構造を理解してないので、不要なAPIリクエストをたくさん叩いてる気がする(非効率)
改善点
- ディレクトリレイアウト的にバックエンド / フロントエンドのコードが混ざっててみづらいので分けよう

- 少し複雑な機能(価格の更新が発生した時の注文確定周り)については、コードを書く前に先にどのような設計にするのかの詳細を詰めてから依頼をした方が良い。そうしないと整合性が取れないコードを書いてくることがある
- 特にうまくいかなくて方針転換するとゴミコードの上に別の処理追加することになるせいで整合性が余計にとりづらくなる
- prisma の migrate が intaractive で辛いので deploy を使うことにする(よくないけど)
- AI が急に止まってこっちの入力まちになることがある、なんで〜。
- AIがシーケンシャルにしか動かないので時間がかかる まあ1から作るとしょうがないのかなあ
- accept し忘れる
playwright mcp 使ってテストコード書いてもらったけど3回ぐらい修正してもテストが通らなかった
Next.js におけるディレクトリレイアウト
/
├── app/
│ ├── api/ # API Route Handlers (バックエンドAPI)
│ │ └── [entity]/
│ │ └── route.ts
│ ├── (pages)/ # UIページ (クライアントサイド寄り)
│ │ └── [page_name]/
│ │ ├── page.tsx # ページのUI (Server/Client Component)
│ │ └── components/ # そのページ固有のUIコンポーネント
│ ├── _actions/ # Server Actions (サーバーサイド専用ロジック)
│ ├── _lib/ # サーバーサイド専用のヘルパー関数やビジネスロジックなど
│ ├── layout.tsx # 全体の共通レイアウト
│ ├── globals.css # グローバルCSS
│ └── page.tsx # ルートページ
├── components/ # アプリケーション全体で共有するUIコンポーネント (クライアント中心)
│ └── ui/ # (オプション) shadcn/ui などのベースコンポーネント置き場
├── prisma/ # Prisma関連 (変更なし)
│ ├── schema.prisma
│ ├── migrations/
│ └── dev.db
├── lib/ # クライアント/サーバー共通で使う可能性のあるモジュール
│ ├── db.ts # Prisma Client インスタンス生成・管理
│ ├── utils.ts # 共通ユーティリティ関数
│ └── types/ # 共通の型定義
├── public/ # 静的ファイル (変更なし)
├── .env # 環境変数 (変更なし)
├── .gitignore # (変更なし)
├── next.config.mjs # (変更なし)
├── package.json # (変更なし)
├── postcss.config.mjs # (変更なし)
├── tailwind.config.ts # (変更なし)
└── tsconfig.json # (変更なし)
└── README.md # (変更なし)
おっしゃる通り、app ディレクトリ直下に UI を構成する page.tsx や layout.tsx と、バックエンド処理を行う api/ が同居しているのは、従来のフロントエンド/バックエンド分離の考え方からすると少し違和感があるかもしれませんね。
これは Next.js App Router の基本的な設計思想 に基づくものです。App Router では、特定のルート(URLパス)に関連するすべてのコード(UI、API、サーバーロジックなど)を同じ場所に配置(コロケーション)する ことを推奨しています。
理由としては:
-
関連性の明確化:
/dashboardというルートに関連する UI (app/dashboard/page.tsx)、そのルート専用の API (app/api/dashboard/.../route.tsや、app/dashboard/api/route.tsという形式も可能)、レイアウト (app/dashboard/layout.tsx)、ローディング状態 (app/dashboard/loading.tsx) などが、ファイルシステム上で近くにまとまるため、開発時にどこを見ればよいか分かりやすくなります。 -
ファイルベースルーティングの統一:
appディレクトリ以下の構造がそのまま URL パスや API エンドポイントに対応するというルールを、UI と API で一貫させています。 - Server Components との親和性: Server Components はサーバーサイドでレンダリングされる UI コンポーネントであり、API やサーバーサイドのロジックと密接に連携することが多いため、物理的に近い場所に配置する方が自然であるという考え方です。
違和感への対処:
ご提案した app/(pages)/ のような ルートグループ や、app/_lib/、app/_actions/ といった _ プレフィックス付きディレクトリ は、この App Router の規約の中で、視覚的に「これはUIページ」「これはサーバーサイドロジック」といった区別をしやすくするための工夫です。物理的には app ディレクトリ配下にありますが、論理的なグルーピングによって見通しを改善できます。
ですので、「api と layout/page が同じ階層にある」のは Next.js App Router の標準的な構成 と言えます。最初は戸惑うかもしれませんが、ルート単位で機能開発を進める際にはメリットがある構造とされています。
この説明で、App Router の考え方について少しクリアになりましたでしょうか?