100日チャレンジ day0~day1 (ToDoアプリ)
100日チャレンジに感化されたので、アレンジして自分でもやってみます。
やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
できたもの
ここにプロジェクトテンプレートを作ってもらった
プロンプト
では早速 day1 として todo アプリを作ってみましょう。
要件
- web で操作可能な todo アプリです
- ユーザごとに個別のデータを管理してください
- todo の操作は追加 / 削除 / 更新 / 閲覧です
- todo にはタイトル、詳細、状態(not started / inprogress / done / pending / cancel) / 作成日時を用意してください
- todo はユーザが web で直感的にソートできるようにしてくださいその内容は永続化してください
- todo の削除は後で復活できるようにアーカイブにしてください
- 閲覧は基本は追加日の降順ですがユーザが種痘で並び替えたらそれを優先してください
- 閲覧は最大 20 件で、スクロールしたら次のが出てくる感じにしてください
以上の要件をまずは整理し設計書に落とし込んでください。
また、この時はどうすべきか?という仕様についての質問を考えて質問してください
ページネーション実装方法の違い
オフセットベース
SELECT * FROM todos
WHERE user_id = ? AND is_archived = false
ORDER BY sort_order DESC, created_at DESC
LIMIT 20 OFFSET 0
メリット
- 実装がシンプル
- ページ番号を直接指定できる
- 全ページ数が計算可能
デメリット
- データの追加/削除があると、同じページ番号でも表示内容が変わる可能性がある
- 大量のデータがある場合、OFFSETが大きくなるとパフォーマンスが低下する
カーソルベース
SELECT * FROM todos
WHERE user_id = ?
AND is_archived = false
AND (sort_order < ? OR (sort_order = ? AND created_at < ?))
ORDER BY sort_order DESC, created_at DESC
LIMIT 20
メリット
- データの追加/削除があっても、表示の一貫性が保たれる
- パフォーマンスが安定している
- 無限スクロールとの相性が良い
デメリット
- 実装が若干複雑
- ページ番号を直接指定できない
- 全ページ数が計算できない
推奨
今回のTodoアプリの要件では、以下の理由からカーソルベースを推奨します:
- 無限スクロールの実装が要件
- Todoの追加/削除が頻繁に行われる可能性がある
- パフォーマンスの安定性が重要
ご質問ありがとうございます。オフセットベースのページネーションでデータ量が増えるとパフォーマンスが低下する理由について、特にB-treeインデックスとの関連で解説します。
オフセットベースのパフォーマンス低下の理由
LIMIT N OFFSET M(M行スキップしてN行取得)のようなクエリが遅くなる主な理由は、データベースが実際にM行を読み飛ばす必要があるからです。
-
データの特定: まず、
WHERE user_id = ? AND is_archived = falseの条件に合うデータを探します。ここにはインデックス(例:user_idとis_archivedの複合インデックス)が有効に働く可能性があります。 -
データのソート: 次に、特定されたデータを
ORDER BY sort_order DESC, created_at DESCに従って並べ替えます。ここでも、ORDER BY句に合致するインデックス(例:(user_id, is_archived, sort_order, created_at)のような複合インデックス)があれば効率的に処理できますが、そうでなければデータベースは取得したデータに対してソート処理を実行する必要があります。これはデータ量が多い場合にコストがかかります。 -
行のスキップ (OFFSET M): ここがボトルネックです。 データベースは、ソートされた結果セットの先頭から
M行を実際にたどり、**読み込んでから破棄(スキップ)**します。OFFSETが大きくなるほど(つまり、後のページに進むほど)、この読み込んで破棄する行数が増えます。たとえインデックスを使って効率的にソート順にアクセスできたとしても、M行分のデータを内部的に処理する必要があるため、Mが大きくなるほど時間とリソース(I/O、CPU)がかかります。 -
行の取得 (LIMIT N): M行をスキップした後、続く
N行を取得して結果として返します。
なぜ B-tree が「M番目の行に直接ジャンプ」できないのか?
B-treeインデックスは、特定のキーの値(例: user_id = 123)やキーの範囲(例: created_at > '2024-01-01')を効率的に見つけるのに非常に優れています。また、インデックスのキー順にデータを読み出すことも得意です(ORDER BY がインデックス順と一致する場合)。
しかし、B-treeは「WHERE条件を満たし、ORDER BY で並べた結果のM番目の行」という相対的な位置を直接知っているわけではありません。
-
絶対位置ではない: B-tree内の物理的な位置や論理的な位置が、
WHEREとORDER BYを適用した後の結果セットにおける「M番目」と直接対応するわけではありません。特にWHERE句で多くの行がフィルタリングされる場合はなおさらです。 -
カウント処理: データベースは、「M番目の行」を見つけるために、条件に合致する行を
ORDER BY順に読み進めながら、1行、2行、...とカウントし、M行読み飛ばすという地道な処理を行う必要があります。Treeの幅(ノードあたりの子ノード数)が分かっていても、各ノードに実際に存在するデータのうち、WHERE条件を満たし、かつ最終的なソート順で何番目になるかは、実際にたどってみないと確定できません。
カーソルベースが高速な理由
カーソルベース(キイセットページネーションとも呼ばれます)は、この問題を回避します。
-- 前ページの最後の行の sort_order が last_sort_order, created_at が last_created_at だった場合
SELECT * FROM todos
WHERE user_id = ?
AND is_archived = false
AND (sort_order < last_sort_order OR (sort_order = last_sort_order AND created_at < last_created_at)) -- ここが重要
ORDER BY sort_order DESC, created_at DESC
LIMIT 20
この方法では、OFFSET を使いません。代わりに、前回のページの最後の行の値を使って、WHERE句で「それよりも前の行(ORDER BY DESC なので値が小さいか、同じsort_orderならcreated_atが小さい)」という条件を指定します。
データベースは、ORDER BY に使われているカラムを含むインデックス(例: (user_id, is_archived, sort_order, created_at))を使い、このWHERE句の条件を満たす最初の行(つまり、前回の最後の行の次の行)に効率的に**直接アクセス(シーク)**できます。そこから LIMIT 20 行を読み取るだけなので、何ページ目であっても処理量がほぼ一定になり、パフォーマンスが安定します。M行を読み飛ばす必要がありません。
まとめ
-
オフセットベースの遅延: データベースが
OFFSET Mを処理するために、実際にM行分のデータを読み込み、破棄する必要があるため、Mが大きい(ページ番号が大きい)ほど遅くなる。 - B-tree の役割: B-treeはデータの検索やソート順の維持には役立つが、「結果セットのM番目」への直接ジャンプは提供しない。
-
カーソルベースの利点: 前ページの最後の行の値を
WHERE句に含めることで、次のページの開始位置にインデックスを使って効率的にアクセスでき、大量の行を読み飛ばす必要がないため、パフォーマンスが安定する。
したがって、Todoアプリのようにデータの追加削除が頻繁で、無限スクロールが求められ、パフォーマンスの安定性が重要な場合には、カーソルベースの実装が推奨されるのは理にかなっています。
template に逃すやつ
- 実際に使うツール類の設定 (ogen とか
さっきまで auto select にしてたんだけど、そのせいかなんかいざ動かそうと思ったらバグがしんどかった。gemini 2.5 にしたらなんとかなりそう

アクセスログの発行は middleware にして共通化しよう
やり直して設計してもらう
承知いたしました。day1のTodoアプリ開発、始めましょう!
まず、いただいた要件を整理し、基本的な設計方針と、いくつか確認したい仕様についてまとめます。
Todoアプリ 設計概要
1. 基本機能
- Webインターフェースを通じたTodoのCRUD操作 (作成、閲覧、更新、削除)
- ユーザーごとのデータ管理 (セッションを利用した簡易的なユーザー切り替え)
2. データモデル
-
User:
-
ID: ユーザー識別子 -
Name: ユーザー名 (表示用)
-
-
Todo:
-
ID: Todo識別子 -
UserID: 紐づくユーザーのID -
Title: Todoのタイトル (必須) -
Detail: Todoの詳細内容 (任意) -
Status: Todoの状態 (not_started,inprogress,done,pending,cancelのいずれか) -
CreatedAt: 作成日時 -
UpdatedAt: 最終更新日時 -
ArchivedAt: アーカイブ日時 (NULLの場合は未アーカイブ) - 論理削除用 -
DisplayOrder: ユーザーが指定する表示順序 (整数値)
-
3. 主要な機能要件と設計方針
-
ユーザー管理:
- ログイン/認証機能は実装せず、セッションにユーザーIDを保持します。
- 画面上部にシンプルなドロップダウンなどを設け、登録済みのユーザーを切り替えられるようにします。
-
Todo操作:
-
追加: タイトル、詳細を入力して新しいTodoを作成します。作成時は
Statusをnot_started、DisplayOrderをよしなに設定します (例: 現在の最大値+1など)。 -
閲覧:
- 基本は
CreatedAtの降順で表示します。 - ユーザーが
DisplayOrderを手動で並び替えた場合は、その順序を最優先します。 - アーカイブされていないTodoのみを表示します。
- 一度に表示する最大件数は20件とし、スクロールに応じて次の20件を読み込む「無限スクロール」方式を採用します。
- 基本は
- 更新: タイトル、詳細、状態を更新できるようにします。
-
削除 (アーカイブ):
- Todoを物理削除せず、
ArchivedAtに日時を設定することでアーカイブ状態とします。 - アーカイブされたTodoは通常の一覧には表示しません。
- 別途、アーカイブ済みTodoを一覧表示し、そこから元に戻せる(
ArchivedAtをNULLにする)機能を提供します。
- Todoを物理削除せず、
-
並び替え:
- Web画面上で、ドラッグ&ドロップなどの直感的な操作によりTodoの表示順 (
DisplayOrder) を変更できるようにします。 - 変更された
DisplayOrderはデータベースに永続化します。
- Web画面上で、ドラッグ&ドロップなどの直感的な操作によりTodoの表示順 (
-
追加: タイトル、詳細を入力して新しいTodoを作成します。作成時は
- 技術スタック: Cursor Rules に記載の技術 (Go, ogen, gorm/gen, mysql, html/template, tailwindcss, etc.) を使用します。
-
アーキテクチャ: クリーンアーキテクチャを意識し、
domain,usecase,interface,infraに責務を分離します。 - データベース: DockerでMySQLコンテナを起動し、gorm/genでモデルとクエリ生成を行います。マイグレーションは行わず、起動時にテーブルを再作成します。
- API: ogen を使用して OpenAPI スキーマからサーバーコードとクライアントコード(必要であれば)を生成します (スキーマ駆動開発)。
-
フロントエンド: Go の
html/templateを使用してサーバーサイドレンダリングを行います。CSSフレームワークとしてTailwind CSSをCDN経由で利用します。
4. ディレクトリ構成案
day1_todo_app/
├── cmd/
│ └── server/ # main.go: サーバー起動
├── pkg/
│ ├── domain/ # ドメインモデル (user.go, todo.go) とリポジトリインターフェース
│ ├── infra/ # DB接続、gorm実装、ロガーなど
│ ├── usecase/ # アプリケーションロジック (todo_usecase.go, user_usecase.go)
│ └── interface/
│ ├── handler/ # HTTPハンドラ (ogen生成コード + 実装)
│ ├── repository/ # リポジトリインターフェースの実装 (infraへのアダプタ)
│ └── web/ # HTMLテンプレート、静的ファイル (CSS, JSなど)
├── go.mod
├── go.sum
├── Dockerfile # (オプション: アプリケーションコンテナ用)
├── docker-compose.yml # MySQLコンテナ起動用
├── taskfile.yml # Task ランナー設定
├── api/ # OpenAPI スキーマファイル (e.g., openapi.yaml)
└── .air.toml # ホットリロード設定
仕様に関する質問
設計を進めるにあたり、いくつか確認させてください。
- ユーザー: 最初はどのように作成・管理しますか? アプリケーション起動時に固定のユーザーリストを作成しておく、あるいは画面から簡易的に追加できるようにするなど、想定はありますか?
-
並び替え: ユーザーが手動で並び替えた (
DisplayOrderを更新した) 後、新しくTodoを追加した場合、その新しいTodoのDisplayOrderはどのように決定するのが自然でしょうか? (例: リストの末尾を示す値にする、先頭を示す値にするなど) -
アーカイブからの復元: アーカイブされたTodoを復元する際、そのTodoの
DisplayOrderはどのように扱いますか? (例: アーカイブ前の値を保持する、復元時にリストの末尾になるよう再設定するなど) -
状態 (
Status):pendingとcancelの具体的な意味合いや使い分けについて、もう少し詳しく教えていただけますか? Todoアプリにおいて、どのような状況でこれらの状態が使われることを想定されていますか? - 無限スクロール: フロントエンドでの実装になりますが、スクロールイベントを検知して非同期で次のデータを取得する、という一般的な実装方法で問題ないでしょうか?
-
詳細 (
Detail): 詳細フィールドはプレーンテキストのみを想定していますか? それともMarkdownのような記法を許容しますか? (今回はシンプルにプレーンテキストを想定します) - エラー表示: ユーザー操作起因のエラー(例: タイトル未入力での保存など)は、画面上にどのように表示するのが望ましいですか? (例: フォームの近くにメッセージを表示、画面上部にアラートを表示など)
これらの点について、ご意見やご希望があれば教えてください。なければ、一般的な方法で実装を進めます。
まずはこの設計概要と質問をご確認ください。問題なければ、次にディレクトリ作成と基本的なファイル構成の準備に進みます。
シンプルなアプリをつくっているがクリーンアーキテクチャや openapi をやらせようとするとアプリが巨大になって全然終わらない。。。
長くなってる原因
-
ログの吐き出し
-
エラーハンドリングをちゃんとやってる
-
クリーンアーキテクチャによる文量の増加
- 引数が一致せずにエラー解決に時間かかってる
-
リッチな orm を使っていないので文量が増えている
-
db を使っているあたりで文量や、外部の設定ファイル、イニシャルの設定が増加
-
go が向いてない気がしてきた

動いた
go の html/template 周りに弱いみたい
最初からたくさんの機能を依頼すると大変なので、ちょっとづつ機能を足してってもらう方がいいのかなあ。
tailwind のせいなのか html/template で生のjsつかってるかわからないけど、性能よくないなあ

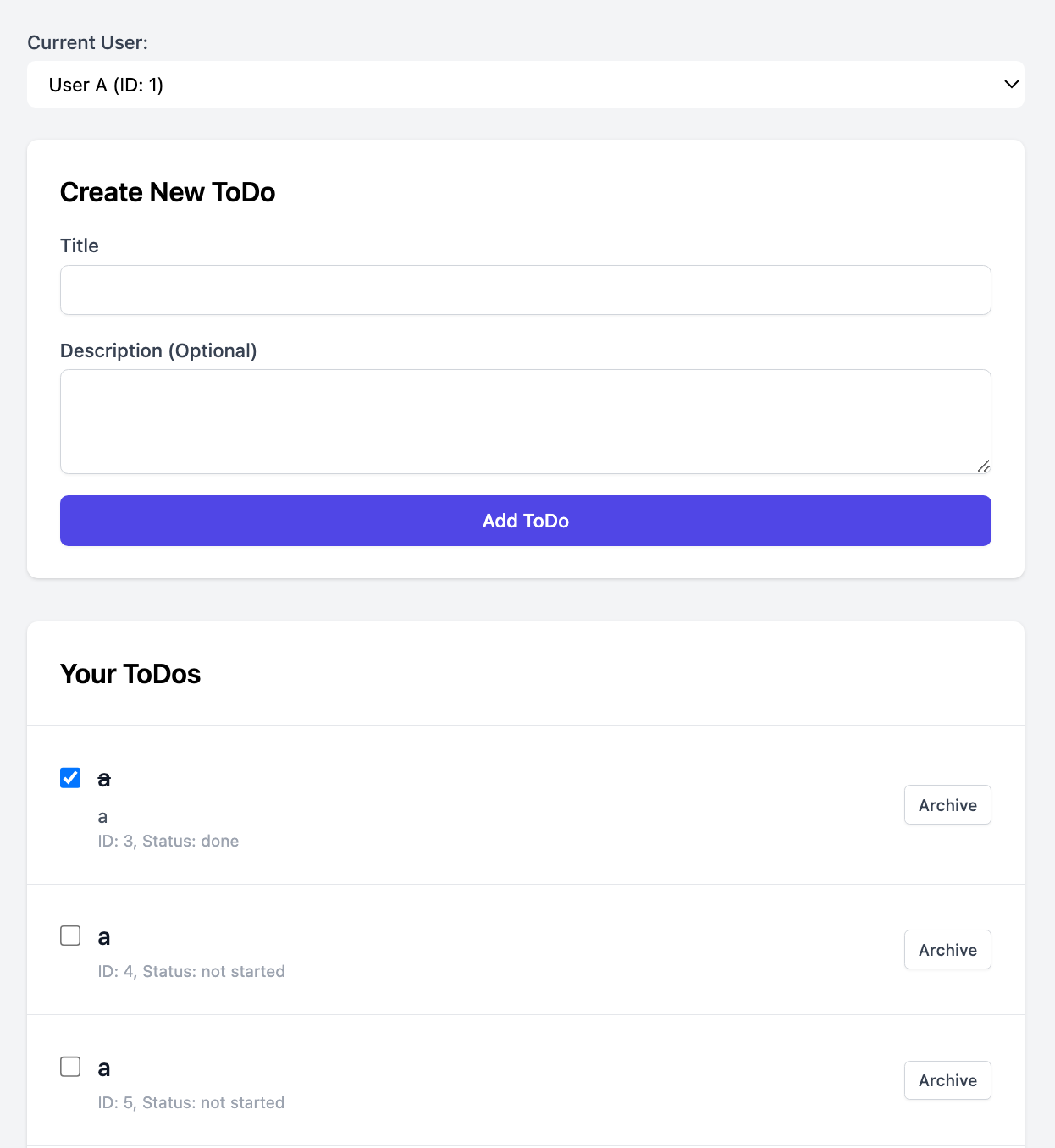
とりあえずやばいけど、これで終わり
コードはこれ
とりあえず学び
- AIに依頼するより自分でやった方がはるかに楽
- openapiのスキーマを出すのは1発だが、そのあとハンドラー、ユースケース、モデル、リポジトリ、DBをだすのにしこたま時間がかかる(明らかに得意不得意がある)
- なるべくMVCによせて作るものを減らす工夫がいる
- 作る順番をAIが理解しやすい順にする。たとえばスキーマ、API設計、モデル、db、コントローラーって感じかな
- webui作るところが html/templateだとしんどかったので、開き直ってreactにしてみる?
- goのhot reloadである airの使い勝手があんまり良くない(bindエラーが頻発
- dbの永続化が複雑さを増してる。sqliteにすればコンテナは不要になる。最悪オンメモリでも良い
- 生成aiを変えると丸ごと作り直しぐらいのことしてくる。また途中までできたやつを完成に持っていこうとするとてんでダメ