100日チャレンジ day26 (時系列DB)
昨日
100日チャレンジに感化されたので、アレンジして自分でもやってみます。
やりたいこと
- 世の中のさまざまなドメインの簡易実装をつくり、バックエンドの実装に慣れる(dbスキーマ設計や、関数の分割、使いやすいインターフェイスの切り方に慣れる
- 設計力(これはシステムのオーバービューを先に自分で作ってaiに依頼できるようにする
- 生成aiをつかったバイブコーティングになれる
- 実際にやったことはzennのスクラップにまとめ、成果はzennのブログにまとめる(アプリ自体の公開は必須ではないかコードはgithubにおく)
できたもの
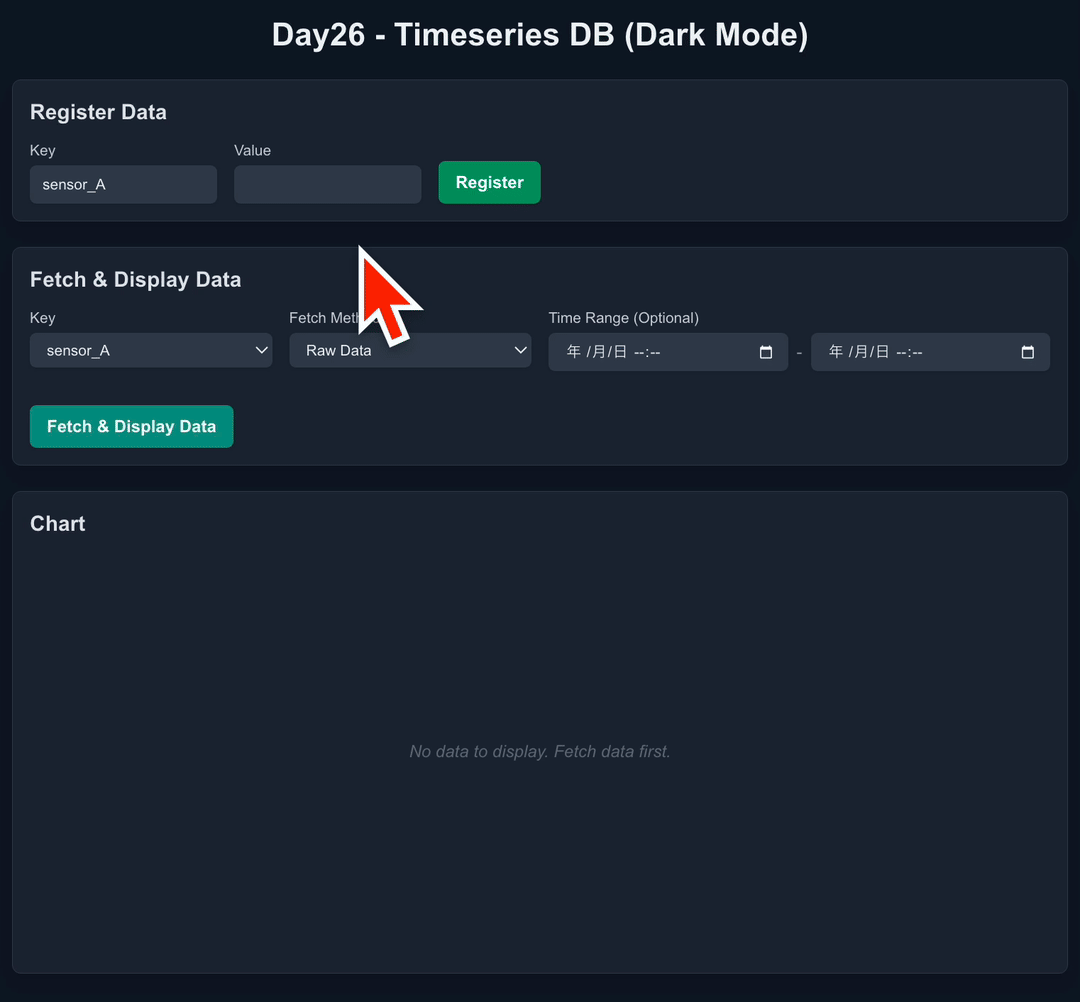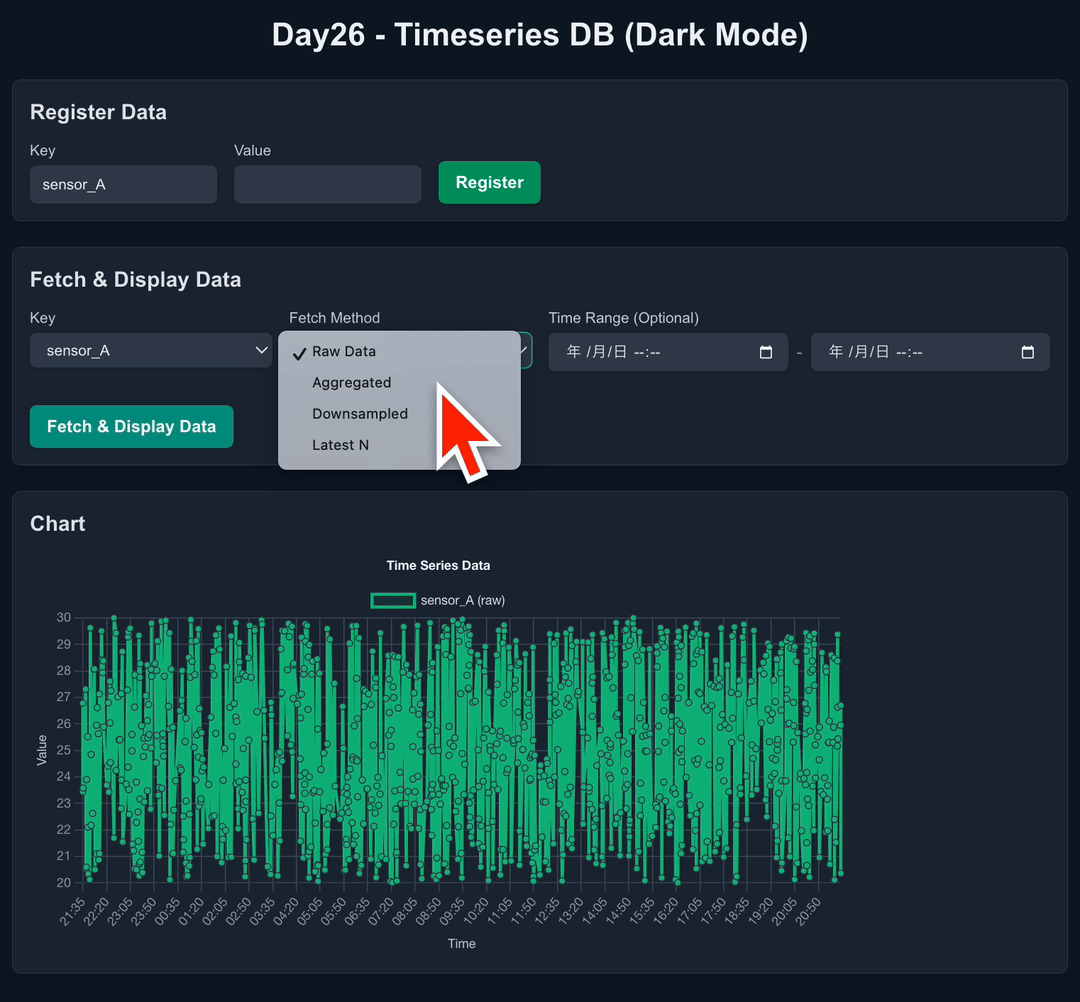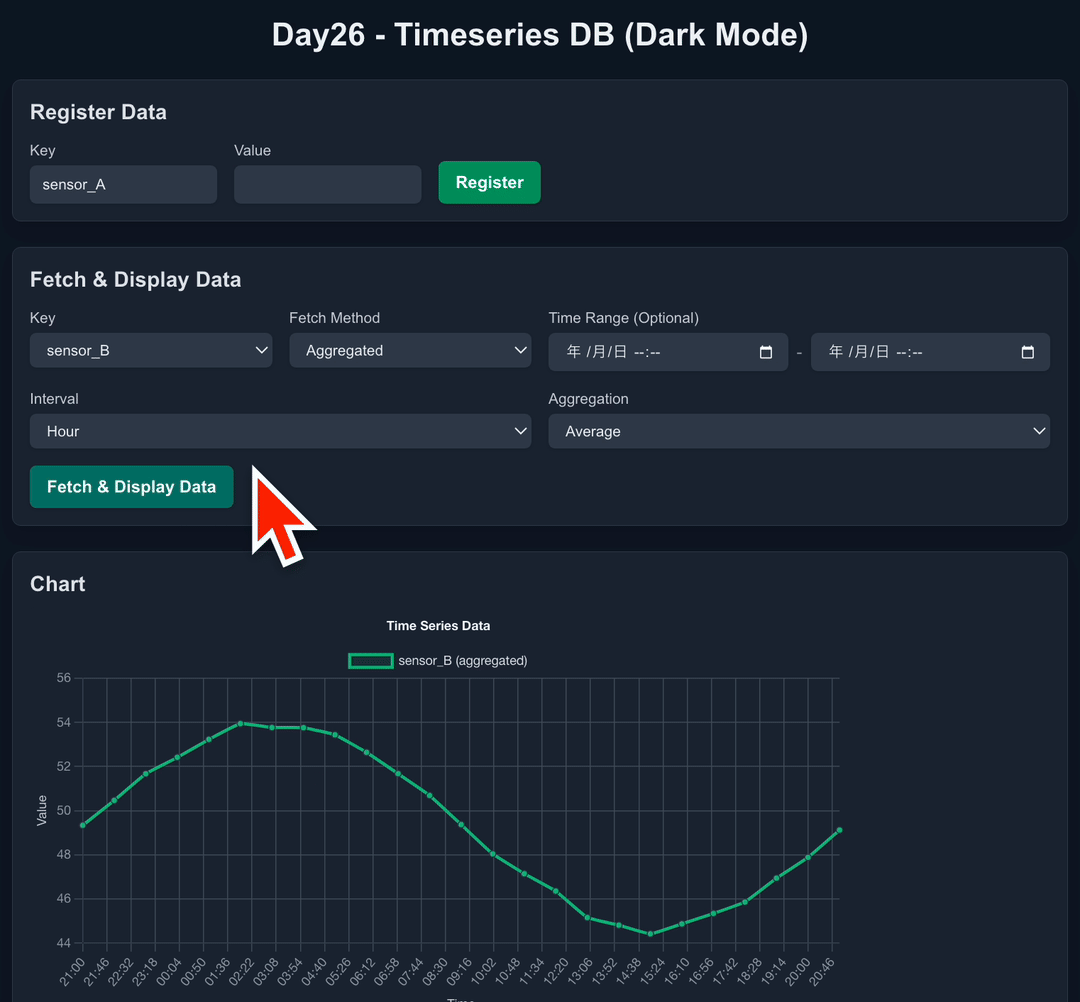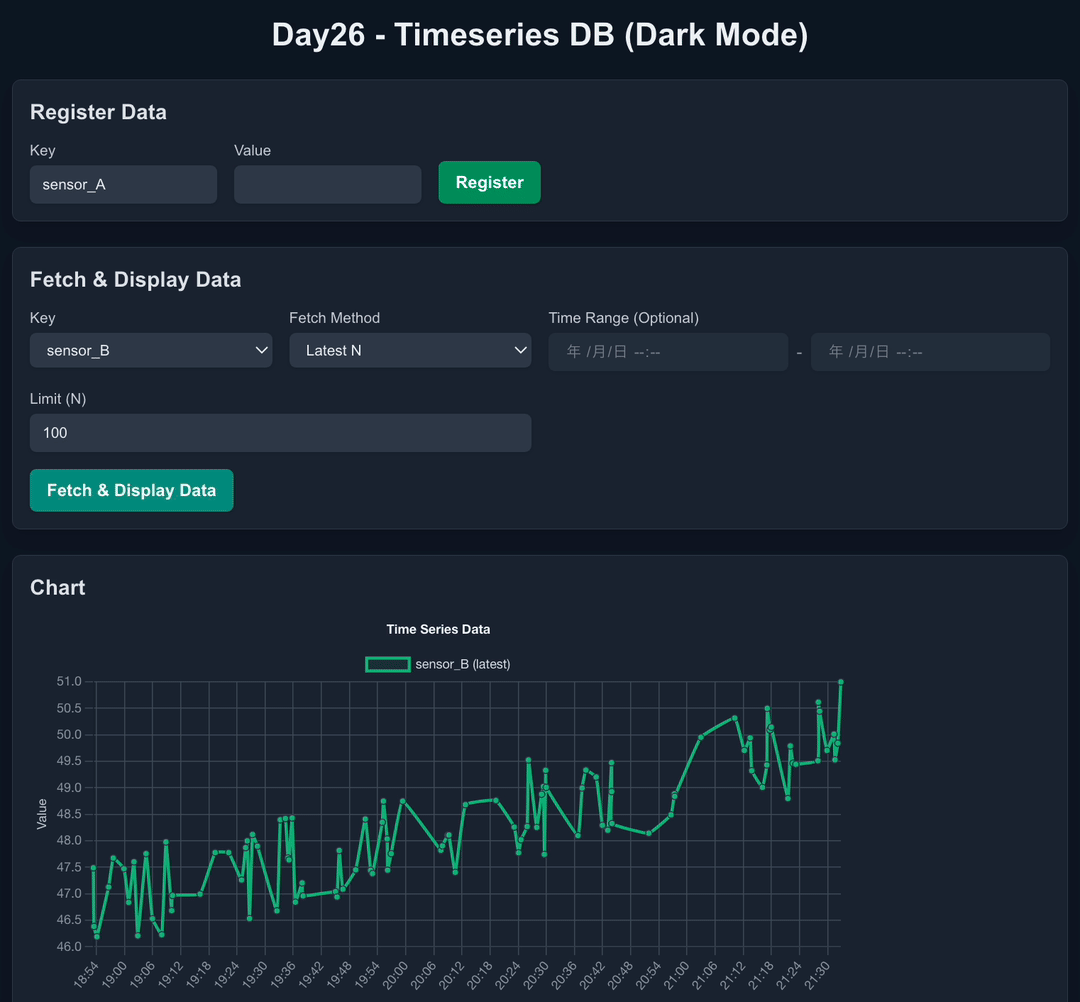
SQLiteで時系列DBみたいなことができるらしい
承知しました。「簡易 時系列データベース on SQLite」でいきましょう!
SQL に精通されているとのことですので、単なる CRUD + α だけではなく、SQLite の機能をもう少し深掘りするような、目新しさを感じられる要素を盛り込んでいきましょう。
特に、SQLite でも比較的新しいバージョンでサポートされたウィンドウ関数 (Window Functions) を活用したり、時系列データ特有の処理(ダウンサンプリングやギャップフィル)を SQL でどう実現するか、といった点に焦点を当てると面白いかもしれません。Prisma を使いつつも、複雑なクエリは prisma.$queryRaw などで生の SQL を書く場面も出てくるでしょう。
実装する機能案(目新しさ重視):
-
基本 API:
- データ登録 (
POST /api/data): key, timestamp (Unix秒), value を登録。 - 時間範囲データ取得 (
GET /api/data): key, start, end を指定して生データを取得。
- データ登録 (
-
集計 API (
GET /api/data/aggregated):- パラメータ:
key,start,end,interval(minute, hour, day),aggregation(avg, max, min, sum, count)。 - SQLite の
strftimeや算術演算、GROUP BY、集計関数を活用。
- パラメータ:
-
ダウンサンプリング API (
GET /api/data/downsampled):- パラメータ:
key,start,end,method(every_nthまたはaggregate),factor。 -
every_nth: ウィンドウ関数ROW_NUMBER()を使って N 件ごと (factor) にデータを抽出。SQLでの実現。 -
aggregate: 指定した時間間隔 (factor) で集計 API と同様の処理。SQLでの実現。
- パラメータ:
-
最新 N 件取得 API (
GET /api/data/latest):- パラメータ:
key,limit。 -
ORDER BY timestamp DESC LIMIT N。
- パラメータ:
-
(発展) ギャップフィル API (
GET /api/data/gapfilled):- パラメータ:
key,start,end,interval,fill_method(previousまたはfixed_value)。 -
previous: ウィンドウ関数LAG()を使って、データがない場合に直前の値で補完する。SQL での実現を目指す。 -
fixed_value: データがない場合に指定した固定値で補完する。(これは比較的簡単) - 線形補間 (
linear) は SQL だけでは複雑なので、今回は見送るか、取得後にサーバーサイドで処理する形にします。
- パラメータ:
-
UI:
- データ登録フォーム。
- データ表示・グラフ化 (Chart.js) エリア。
- キー選択、時間範囲選択。
- 集計、ダウンサンプリング、ギャップフィルのオプション選択。
- グラフ表示。
最近毎度同じデザイン作ってくるのでやめたい
毎回異なるモダンなデザイントレンド(例: ミニマリズム、グラスモーフィズム、ニューモーフィズム、ブルータリズムなど)を積極的に試すこと。過去のプロジェクトのデザインとは明確に差別化すること

変えてもらった
承知しました。各APIエンドポイントが内部でどのようなSQLクエリを実行しているか、具体的に説明します。
各APIエンドポイントが実行するSQLクエリ
以下に、各APIが実行する主なSQLクエリ(またはPrismaが生成するSQLクエリの意図)を説明します。パラメータ (? の部分) はリクエストに応じて変わります。
-
GET /api/keys- 目的: 登録されているユニークなキーの一覧を取得する。
-
方法: Prisma の
findManyとdistinctオプションを使用。 -
実行されるSQL (相当):
SELECT DISTINCT "key" FROM "TimeSeriesData" ORDER BY "key" ASC
-
POST /api/data- 目的: 1つまたは複数の新しい時系列データを挿入する。
-
方法: Prisma の
createManyを使用。 -
実行されるSQL (相当):(リクエストボディのデータ数に応じて
INSERT INTO "TimeSeriesData" ("key", "timestamp", "value", "createdAt") VALUES (?, ?, ?, ?), (?, ?, ?, ?), ...VALUES (...)が繰り返される)
-
GET /api/data(Raw Data)- 目的: 指定されたキーの生データを、任意で指定された時間範囲で取得する。
-
方法: Prisma の
findManyを使用。 -
実行されるSQL (相当):(
SELECT "id", "timestamp", "key", "value", "createdAt" FROM "TimeSeriesData" WHERE "key" = ? AND "timestamp" >= ? AND "timestamp" <= ? ORDER BY "timestamp" ASCAND "timestamp" >= ?とAND "timestamp" <= ?の部分は、start/endパラメータが指定された場合のみ追加される)
-
GET /api/data/aggregated- 目的: データを指定の時間間隔でグルーピングし、指定の集計関数を適用する。
-
方法:
prisma.$queryRawで生のSQLを実行。 -
実行されるSQL (例:
interval=hour,aggregation=avgの場合):(SELECT strftime('%Y-%m-%d %H:00:00', "timestamp", 'unixepoch') AS "interval_start", AVG("value") AS "aggregated_value" FROM "TimeSeriesData" WHERE "key" = ? AND "timestamp" >= ? AND "timestamp" <= ? GROUP BY "interval_start" ORDER BY "interval_start" ASCstrftimeのフォーマットはintervalパラメータに応じて、AVGの部分はaggregationパラメータに応じて変わる。WHERE句のtimestamp条件は任意。)
-
GET /api/data/downsampled- 目的: データを間引いて取得する。
-
方法:
prisma.$queryRawで生のSQLを実行。-
method=every_nthの場合: ウィンドウ関数ROW_NUMBER()を使用。(SELECT "timestamp", "value" FROM ( SELECT "timestamp", "value", ROW_NUMBER() OVER (ORDER BY "timestamp" ASC) as "rn" FROM "TimeSeriesData" WHERE "key" = ? AND "timestamp" >= ? AND "timestamp" <= ? ) WHERE "rn" % ? = 1 -- factor パラメータで割った余りが 1 の行を抽出 ORDER BY "timestamp" ASCWHERE句のtimestamp条件は任意。) -
method=aggregateの場合: Unixタイムスタンプの整数除算でグルーピング。(SELECT AVG("value") AS "aggregated_value", -- 現在は AVG 固定 ("timestamp" / ?) AS "time_group" -- factor パラメータで整数除算 FROM "TimeSeriesData" WHERE "key" = ? AND "timestamp" >= ? AND "timestamp" <= ? GROUP BY "time_group" ORDER BY "time_group" ASCWHERE句のtimestamp条件は任意。結果はJS側でtimestamp: Number(time_group) * factorに変換される。)
-
-
GET /api/data/latest- 目的: 指定されたキーの最新 N 件のデータを取得する。
-
方法: Prisma の
findManyとorderBy,takeを使用。 -
実行されるSQL (相当):(取得後、JS側で
SELECT "id", "timestamp", "key", "value", "createdAt" FROM "TimeSeriesData" WHERE "key" = ? ORDER BY "timestamp" DESC -- 最新が先頭に来るように降順 LIMIT ? -- limit パラメータで件数指定timestampの昇順に並び替え直している)
これらの説明で、各APIが内部でどのようなクエリを実行しているかご理解いただけたでしょうか?
なるほど、SQLって色々できるんだな〜〜〜。
うーんたまにしか使わないので忘れることを考えるとAIにお願いしたい