Triton - ONNX Backend の検証
Triton Inference Server の動作検証シリーズの第 3 弾.今回は,Triton Inference Server の ONNX Backend に関して簡単な動作検証をした.やったこととハマったことを備忘録として残していく.
ONNX Runtime Backend
Triton Inference Server で,ONNX 形式のモデルを実行する際に選択するバックエンド.使用される推論用フレームワークは,ONNX Runtime である.
ONNX Backend の基本実装
フォルダ構成[1][2]
Triton の model repository のレイアウト[1:1]に従う.対象モデルの設定ファイルとしてconfig.pbtxtと,<version>/ ディレクトリ以下に,対象モデルの ONNX ファイルを配置する.ONNX のファイル名は model.onnx.他のファイル名にする場合は,設定ファイルの default_model_filename にて指定する.
<model-repository-path>/
<model-name>/
config.pbtxt
1/
model.onnx # 異なるファイル名を使用する場合は,`default_model_filename` で変更可能
Model Configuration (config.pbtxt)
Model Configuration のバックエンド共通の設定は,Model Configuration を参照.ONNX Runtime Backend を使用する際は,backend に, onnxruntime を指定する.入出力と max_batch_size は自動生成も可能であるため,空欄にしておいても良い[3].
name: "simple_cnn"
backend: "onnxruntime"
max_batch_size: 0 // 固定BatchをOFF. Dynamic Batchingを有効化する場合は1以上を設定.
default_model_filename: "model.onnx"
input [ ... ]
output [ ... ]
instance_group [
{
count: 1
kind: KIND_AUTO
}
]
起動方法
基本的には,tritonserver コマンドにオプションでモデルリポジトリのパスを指定すれば良い (--model-repository).
ただし,ONNX の入力バッチサイズが可変になっている場合は注意が必要.入力の shape を ONNX ファイルから推定するオプションを有効化されていれば ONNX ファイルで設定されている最大値が適用されている.そうでない場合は,default-max-batch-size を設定する必要がある[4].デフォルト値は 4.本番環境で運用するなら確実に設定が必要だと思われる.このほかに,thread の作成に関してもオプションが用意されている.
tritonserver \
--model-repository=model_repository \
--backend-config=onnxruntime,default-max-batch-size=8
実装サンプル
下記の図に示す CNN (Simple CNN) と Transformer (Simple Transformer; Encoder)を ONNX で実装する.サンプルコードは以下の通り.この実装で使用した ONNX ファイルは,colum2131 さんの記事[5]を参考に作成した.(クライアント側の実装に関しては,リファクタリング後に別記事で解説したい.)
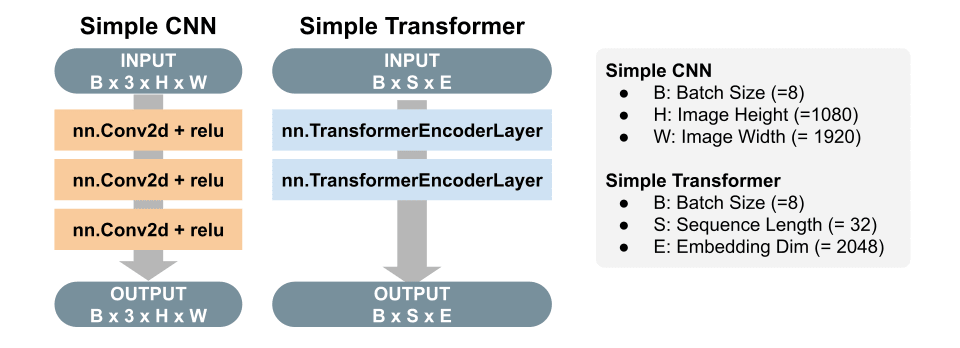
Sample Model Architecture
全体の処理の流れは以下の通り:
- [Client] 入力画像を CUDA Shared Memory にセット
- [Client] Inference Request を送信 (= Input/Output のテンソルへのポインタを送る.)
- [Triton] CUDA Shared Memory へのポインタを受け取り,このメモリを入力として推論を実行.
- [Triton] ONNX Runtime で推論を実行
- [Triton] CUDA Shared Memory に出力をセット
- [Triton] Inference Response を返す.
- [Client] CUDA Shared Memory にセットされた出力を取得

System Architecture
プロファイリング (by Nsight)
GPU のプロファイリングツール NVIDIA Nsight Systems を使って,GPU 上でどのように処理が行われているか確認した.Triton の起動コマンドの前に以下のコマンドを足すことで,プロファイリングを作成することができる.
nsys profile -t nvtx,osrt,cuda,cudnn,cublas \
--backtrace=dwarf --force-overwrite=true \
tritonserver <Tritonの起動オプション>
SimpleCNN のプロファイリング結果 (1 Batch 分) は以下の通り.SimpleCNN は Conv2d 3 層のモデルなので,Conv2d に対応するカーネル (conv2d_grouped_direct_kernel) がバッファなく実行されていることが確認できる.Kernel を実行している間,CPU 側の Triton のプロセス (下の緑) は待ち状態 (cudaStreamSynchronized) になっている.

Profiling Results of SimpleCNN
Transformer のプロファイリング結果もおおよそ同じ結果である.
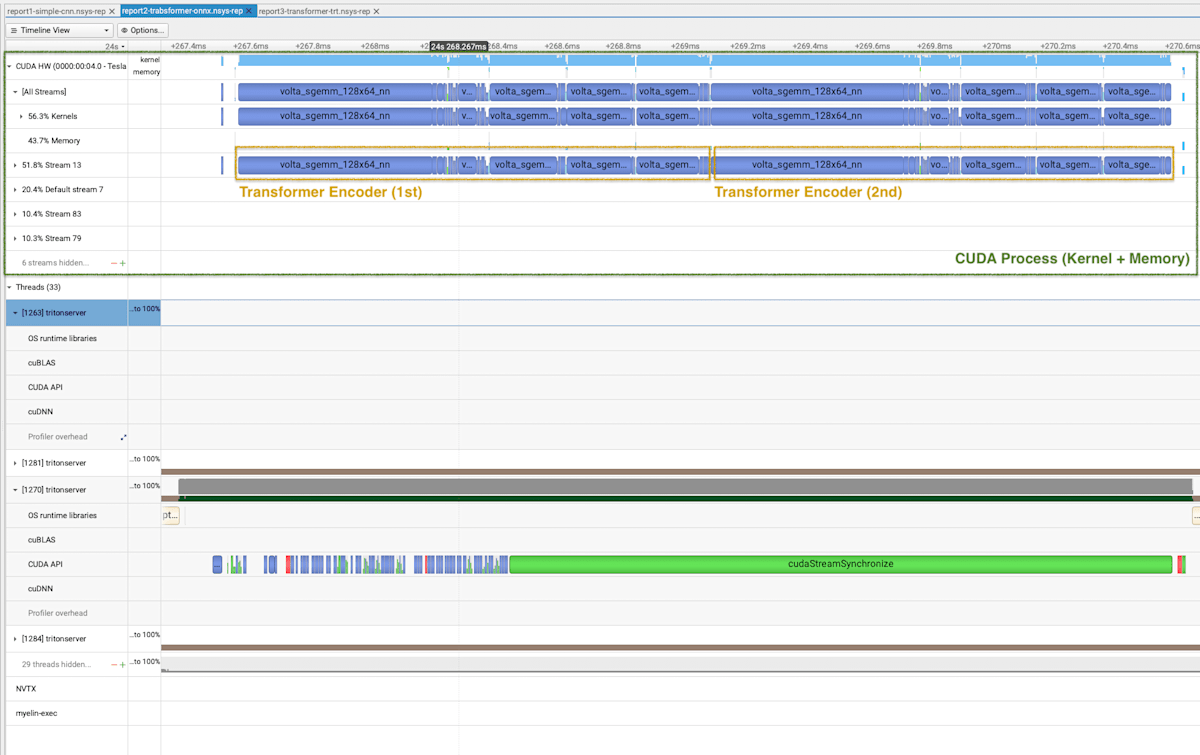
Profiling Results of SimpleTransformer
今回は推論速度の評価は,モデルがシンプルすぎて差分を確認しにくいので行わない.別途,別の処理が重いモデルを用いて,どの程度推論速度に差が出るか,自分で手を動かして出るか調べていきたい.
ONNX モデルの注意点
PyTorch モデルの ONNX への変換には,現在 2 種類の方法が提供されている.CNN のモデルはtorch.onnx.dynamo_export() で変換したモデルも実行できたが,Transformer はtorch.onnx.export() でコンパイルしたものしか Triton 上で実行することができなかった.ONNX への変換方法はこの記事のスコープ外なので,別途調査する.
-
TorchDynamo-based ONNX Exporter ...
torch.onnx.export() -
TorchScript-based ONNX Exporter ...
torch.onnx.dynamo_export()
TensorRT による最適化
ONNX モデルを Triton 側で TensorRT にコンパイルし実行してくれるオプションがある.使い方はシンプルで,config.pbtxtに optimizationの項目を追加すれば良い.TensorRT への変換関係で設定可能なパラメタの一覧は GitHub 参照.
name: "simple_transformer_trt"
backend: "onnxruntime"
max_batch_size: 0
default_model_filename: "simple_transformer_optimized.onnx"
input [ ... ]
output [ ... ]
instance_group [ ... ]
optimization { // 追記
execution_accelerators {
gpu_execution_accelerator : [
{
name : "tensorrt"
parameters { key: "precision_mode" value: "FP16" } // 浮動小数点の精度
parameters { key: "max_workspace_size_bytes" value: "1073741824" } // モデルが使用できるGPU上のメモリサイズの最大値
parameters { key: "trt_engine_cache_enable" value: "1" } // TensorRTに変換したモデルがキャッシュされている場合は,モデルを再変換せずにそれを使う.
}
]
}
}
SimpleTransoformer を,TensorRT の最適化オプションを追加してデプロイした結果を以下に示す.推論速度に大きな差は見られなかったが,実行されているカーネルブロックの数が減り,大きなブロックに統合されているように見える (赤部分).これが最適化の結果だろうか?ONNX TRT の最適化に関しては,別途確認したい.
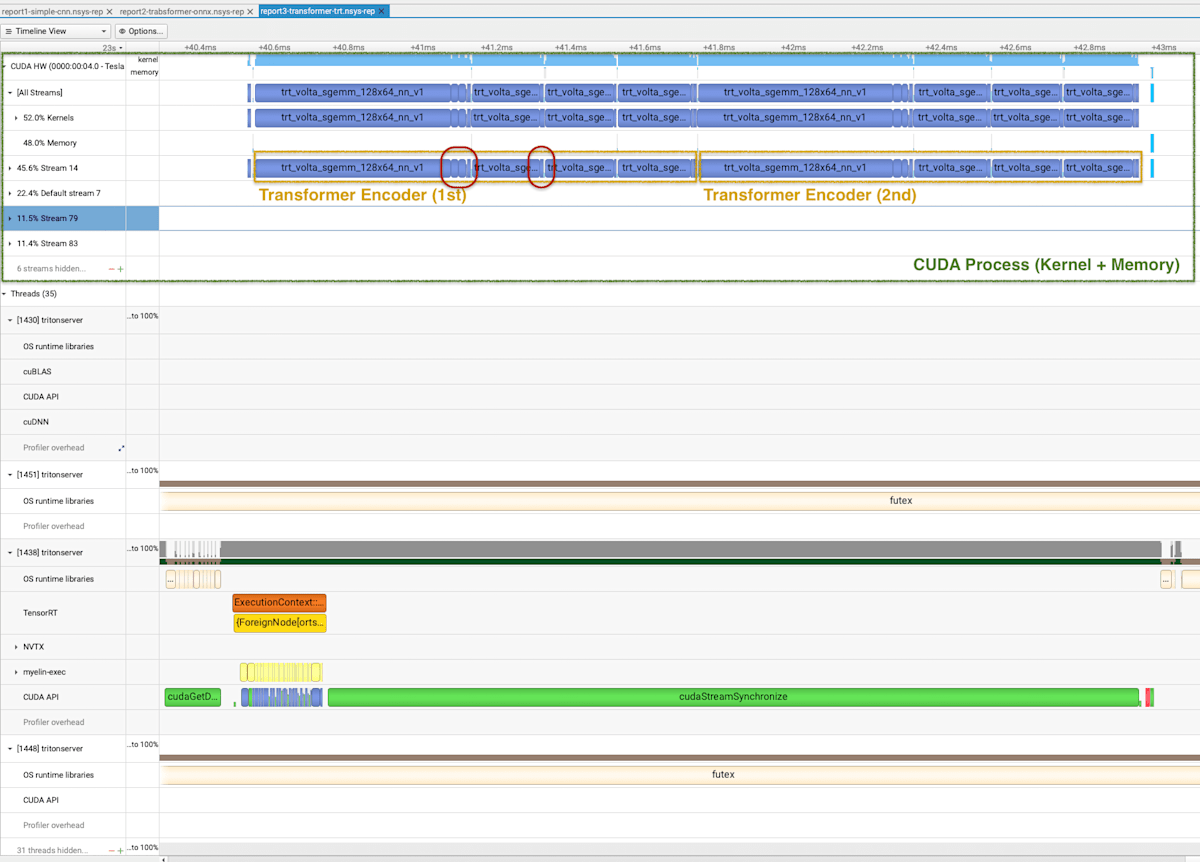
Profiling Results of SimpleTransformer (with TRT Optimization)
SimpleCNN に関しては,TensorRT への変換エラーが出てきたため実行できなかった.ONNX への変換方法についてさらなる調査が必要のようだ.
ONNX には変換できない 前処理・後処理の実装
前処理・後処理は,モデルとは別に用意されているケースや,そもそも ONNX 変換することが難しいケースがある.その場合は,前処理・後処理を Python Backend で実装し,Ensemble Models を使用して一つのパイプラインとして動かす.
(調査中) Model Configuration において,backend と platformのどちらを指定すべきか?
Triton のtutorialsの Conceptual Guide を見ると, Part 4 では, backend を使用して ONNX Runtime Backend を指定しているが, Part 6 では platform を使用して Backend を指定している.
model_config.proto におけるそれぞれの説明は下記の通り.
- platform (
str): The backend used by the model - backend (
str): The name of the backend library file used by the model.
また, Triton Inference Server Backend - GitHubには下記の記述がある.
For all other backends, backend must be set to the name of the backend. Some backends may also check the platform setting for categorizing the model [6]
platform を指定すると追加で設定を見に行く模様.つまり,Platform の方がより抽象度が高い設定だと思われる.具体的な違いについては,今後詳細を確認したい.
まとめ
今回のサンプル実装は,Triton の実装よりも,モデルの ONNX 変換に多くの時間を費やした.ONNX Backend は ONNX モデルをデプロイするには非常に有効.ただし,モデルを ONNX に変換さえできればの話である.
TODO (追加で調査したい項目)
- Model Configuration で,
backendとplatformのどちらを指定するべきか?また違いはあるのか?[6:1] - SimoeCNN を TensorRT に変換できる ONNX に変換する方法.(また,変換できない理由の調査)
Discussion