シンプルな ML Pipeline を OpenTelemetry で監視する
はじめに
最近話題のオブザーバビリティのフレームワークとして、OpenTelemetry (通称 OTel; おーてる) の存在を少し前に知りました。本業はオンプレの機械学習パイプラインの構築なので、OTel が重宝されるクラウドコンピューティング・マイクロサービスアーキテクチャなどとは真逆のエリアで仕事をしています。しかしながら、調べていくと、オンプレの単一サーバ構成でも色々とメリットがあるのではないかと思い、勉強を兼ねて手を動かしてみました。
私は「OTel」と「オブザーバビリティ」の両方とも初心者ですので、間違い等あればご指摘いただけると幸いです。
OpenTelemetry とは?
オブザーバビリティのフレームワークです。ベンダーやツールに縛られない様に設計された、API・SDK・ツールのコレクションです。詳細な説明は、下記のブログをお読みください。
前提条件
学生時代の研究で、OpenPack Dataset という、産業ドメインの行動認識データセットを作成しました。一部公開できていない動画データがあるのでオープンにしたいのですが、被験者の顔にマスクをかけて匿名化する必要があります[1]。今回はこのパイプラインを、リニューアルしながら OTel を使ってみたいと思います。
匿名化の方針
今回は、動画の中から人物を検出し、骨格推定を行います。検出した鼻のキーポイントを中心として、その周囲を黒く塗りつぶすことで、顔を匿名化します。

(結果として精度以前のアプローチの方が安定していたので、こちらの手法もコツコツ改善していこうと思います。)
ML Pipeline の構成
OTel で取得したい情報
- 1 フレーム全体と、その中の各モデルの推論時間 (trace & metrics)
- 検出された人数 (= Bounding Box の数) (metrics)
- GPU の Utilization とメモリ使用量 (metrics)
OTel と一緒に、オブザーバビリティについて調べた結果、1 つ目と 2 つ目は trace とそれを集計した metrics、最後は metric として収集するのが良いと思いました。
実装
最終的なコードはこちらを参照してください。ここでは OTel 周りを中心に説明していきます。
Docker
構成としては、Pipeline を実行するコンテナがまずあり、テレメトリを集約する Connector、トレースの可視化に Jaeger、メトリクスの収集と可視化に Prometheus、Grafana を使います。
GPU 関係のメトリクスの取得には、OpenLIT という OpenTelemetry Native な LLM パイプライン構築用のライブラリから、OpenTelemetry GPU Collector を拝借します。
Connector は、ベンダー依存しない方法でテレメトリを Recieve・Process・Export するためのコンポーネントです。今回は勉強も兼ねて、Pipeline から直接 Jeager/Prometheus にテレメトリを送信するのではなく、すべてを Connector に集約してから送信するようにワークフローを組みました。
docker-compose.yml
services:
pipeline:
build:
context: ./app/docker
dockerfile: Dockerfile
image: getty708/mlops-sandbox:24.08-py3-otel
container_name: va-pipeline
working_dir: /workspace/mlops-sandbox/pipelines/video_anonymization/app
command: /bin/bash
tty: true
volumes:
- ../../:/workspace/mlops-sandbox/
networks:
- va-network
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
jaeger:
image: jaegertracing/all-in-one:${JAEGER_IMAGE_TAG:-latest}
container_name: va-jaeger
volumes:
- "./infra/jaeger/jaeger-ui.json:/etc/jaeger/jaeger-ui.json"
command: --query.ui-config /etc/jaeger/jaeger-ui.json
ports:
- "16686:16686"
networks:
- va-network
prometheus:
container_name: va-prometheus
env_file:
- .env
image: prom/prometheus:latest
volumes:
- ./infra/prometheus/config/prometheus.yaml:/etc/prometheus/prometheus.yml
- prometheus-data:/prometheus
ports:
- 9090:9090
networks:
- va-network
grafana:
container_name: va-grafana
labels:
prometheus-scrape.enabled: "false"
service: "grafana"
env_file:
- .env
image: grafana/grafana-oss:latest
volumes:
# TODO: Remove unnecesary volumes.
- ./infra/grafana/datasources:/etc/grafana/provisioning/datasources
- grafana-data:/var/lib/grafana
ports:
- "${GRAFANA_PORT}:${GRAFANA_PORT}"
environment:
GF_SECURITY_ADMIN_PASSWORD: admin
networks:
- va-network
otel-collector:
container_name: va-otel-collector
image: otel/opentelemetry-collector-contrib:latest
ports:
- "4317:4317"
- "55680:55680"
- "8000:8000"
volumes:
- ./infra/otel-collector/config/otel-collector-config.yaml:/etc/otel-collector-config.yaml
command:
- --config=/etc/otel-collector-config.yaml
networks:
- va-network
otel-gpu-collector:
container_name: va-otel-gpu-collector
image: ghcr.io/openlit/otel-gpu-collector:latest
environment:
GPU_APPLICATION_NAME: ml-pipeline
GPU_ENVIRONMENT: dev
OTEL_EXPORTER_OTLP_ENDPOINT: http://otel-collector:55680
OTEL_EXPORTER_OTLP_HEADERS: null
networks:
- va-network
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
grafana-data: {}
prometheus-data: {}
networks:
va-network:
Pipeline の実装
Pipeline はすでに実装済みとして、OTel の導入をしていきます。最初の TraceProviderとMeterProviderの設定以外は、非常に直感的に実装できました。
Trace の収集
トレースを収集するためには、TraceProviderを準備しなければいけません。Resourceは、テレメトリを生成するシステムやサービスの情報を表現します。まずは、このリソース上でトレースを収集するTracerProviderを初期化します。次にトレースの送り方と送り先を指定します。BatchSpanProcessorでまとめてデータを送信するようにし、実際にデータ送信の処理を行う OTLPSpanExporter をインジェクトします。 具体的には、次の様な実装になります。これでトレースを収集するための初期設定は完了です。
from opentelemetry import metrics, trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
resource = Resource.create({"service.name": "my-ml-pipeline"})
# == Trace ==
tracer_provider = TracerProvider(resource=resource)
trace.set_tracer_provider(tracer_provider=tracer_provider)
# Send traces to OtelCollector.
tracer_provider.add_span_processor(
span_processor=BatchSpanProcessor(
span_exporter=OTLPSpanExporter(endpoint="otel-collector:4317", insecure=True)
)
)
tracer = trace.get_tracer_provider().get_tracer(__name__)
トレースの収集は、まず tracer.start_as_current_span() でフレーム全体の処理を表現するスパンを作成し、その中でさらに tracer.start_as_current_span("model-name")を呼ぶことで、span がネストされていき、処理の親子構造などを表現できます。基本的には with 環境を使用するのがよさそうです。この1行足すだけで、トレースを収集していけるの手軽すぎますね。
# == Model Inference ==
with tracer.start_as_current_span("process_single_frame"):
with tracer.start_as_current_span("person_detection"):
bboxes_xyxy = self.detector(img_tensor)
with tracer.start_as_current_span("pose_estimation"):
keypoints = self.pose_estimator(img_tensor, bboxes_xyxy)
Metrics の収集
Pose Estimation などは Bbox ごとの処理になるので、理想的には Bbox あたりの処理時間を可視化したいというモチベーションで検出された人数を収集したいと思いました。
今回一番理解に苦労したのがここかもしれません。いまだに正しい方法がわかっておらず、ひとまず実装したというレベルです。
検出された人数は、最初トレースのアトリビュートに含めれば良いのかと思い実装していましたが間違っていました。次で説明する Span Metric Connector は、トレースの attribute の値をメトリクスに変換してくれません。したがって、別途メトリクスとして記録する必要があります。今回は UpDownCounterを用いて、検出された人数を記録しました。各時点で固有の値を記録することはメトリクスの守備範囲外で (どちらかというとログ?)、PeopeleCounter クラス内で差分を計算し、UpDownCounter に記録するという方法を取りました。だいぶ汚いアプローチだと思うので、再検討したいです。
reader = PeriodicExportingMetricReader(
OTLPMetricExporter(endpoint="otel-collector:4317", insecure=True),
export_interval_millis=1000,
)
metrics.set_meter_provider(MeterProvider(resource=resource, metric_readers=[reader]))
meter = metrics.get_meter_provider().get_meter(__name__)
people_counter = meter.create_up_down_counter(
name="detected_people_count",
description="Number of people detected in the frame",
unit="1",
)
class PeopeleCounter:
def __init__(self):
self.current_peopel_count = 0
def add(self, new_value):
difference = new_value - self.current_peopel_count
people_counter.add(difference)
self.current_peopel_count = new_value
....
class Pipeline:
def process_single_frame(self, img: np.ndarray, draw_model_outputs: bool = False) -> np.ndarray:
...
# == Model Inference ==
with tracer.start_as_current_span("person_detection"):
bboxes_xyxy = self.detector(img_tensor)
self.people_counter.add(len(bboxes_xyxy)) # Added!!
別案ですが、トレースに値を入れておいて、自作 Processor でメトリクスとして抽出する方が正攻法なのでしょうか?ぜひコメントをお願い致します。
Connector の設定
テレメトリが生成できるようになったので、次はパイプラインと GPU 関連のテレメトリを集約し、Jaeger と Prometheus に送信する Connector の設定です。
otel-collector-config.yaml
receivers:
otlp:
protocols:
grpc:
endpoint: "0.0.0.0:4317"
http:
endpoint: "0.0.0.0:55680"
exporters:
prometheus:
endpoint: "0.0.0.0:8000"
namespace: "otel"
otlp:
endpoint: "jaeger:4317"
tls:
insecure: true
connectors:
spanmetrics:
histogram:
explicit:
buckets: [50ms, 100ms, 150ms]
aggregation_temporality: "AGGREGATION_TEMPORALITY_CUMULATIVE"
metrics_flush_interval: 1s
metrics_expiration: 10s
service:
pipelines:
traces:
receivers: [otlp]
exporters: [spanmetrics, otlp]
metrics:
receivers: [otlp, spanmetrics]
exporters: [prometheus]
Pipeline から送信されるのテレメトリは、OTLP Receiver (otlp) で受け取り、Jaeger と Prometheus に送信します。service.pipelines に、受け取ったトレースとメトリクスの送り先が記述されています。Jaeger は OTLP Exporter (otlp) からデータを取得するので、exporters に otelが指定されています。Prometheus は、専用の Exporter (Prometheus Exporter) があるので、それを指定しています。
これ以外に spanmetrics があります。これは、Span Metrics Connector で、トレースを受け取って、処理時間などのメトリクスを取得するための Connector です。今回の場合、各モデルの処理時間のメトリクスをトレースから取得するために使用します。services.pipelinesには、traces.exportersからトレースを受け取り、Connector 内で処理を行った後、metrics.receiversに結果を返すというフローが記述されています。
service:
pipelines:
traces:
receivers: [otlp]
exporters: [spanmetrics, otlp]
metrics:
receivers: [otlp, spanmetrics]
exporters: [prometheus]
Span Metrics Connector の理解には以下の記事が参考になりました。
- 逆井(さかさい), "OpenTelemetry Collector の Span Metrics Connector を使ってメトリクスを生成してみる," Zen
Prometheus 設定
Connector から送信されたメトリクスは、Prometheus で受け取り、Grafana で可視化します。
Prometheus はprometheus.yaml に OTel Connector からデータを受け取る設定を記述します。これでメトリクスが収集・蓄積できます。
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "otel-gpu-collector"
static_configs:
- targets: ["otel-collector:8000"]
テレメトリの可視化
ようやくここに辿り着きました。パイプラインの実行状況を確認していきましょう。
トレースの可視化
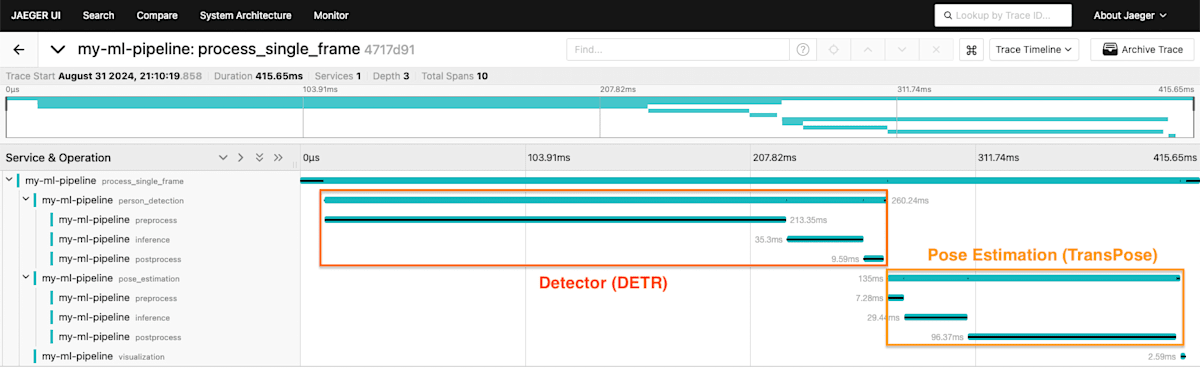
パイプラインを実行し、Jaeger にアクセスすると、以下のようなトレースを見ることができます。with を足すだけでここまで詳細に見れるのは、めちゃめちゃ手軽ですごい!感動しました。
DETR の推論が全体の 3 分の 2 程度を を占めていることが一目でわかります。また PoseEstimation では、モデルの推論より後処理に時間がかかっているようです。適当な実装をしていることが、一目瞭然ですね (汗)。
メトリクスの可視化
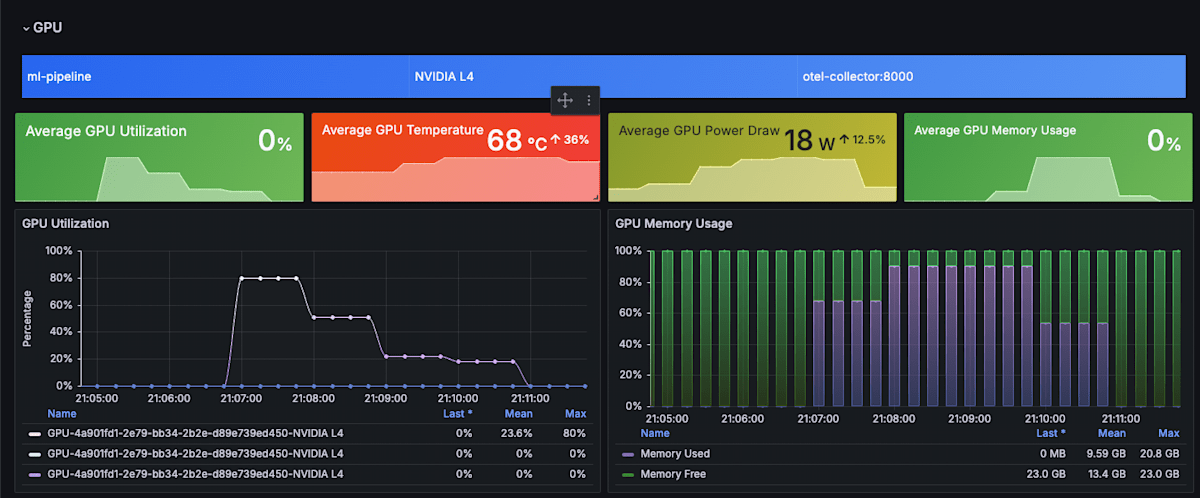
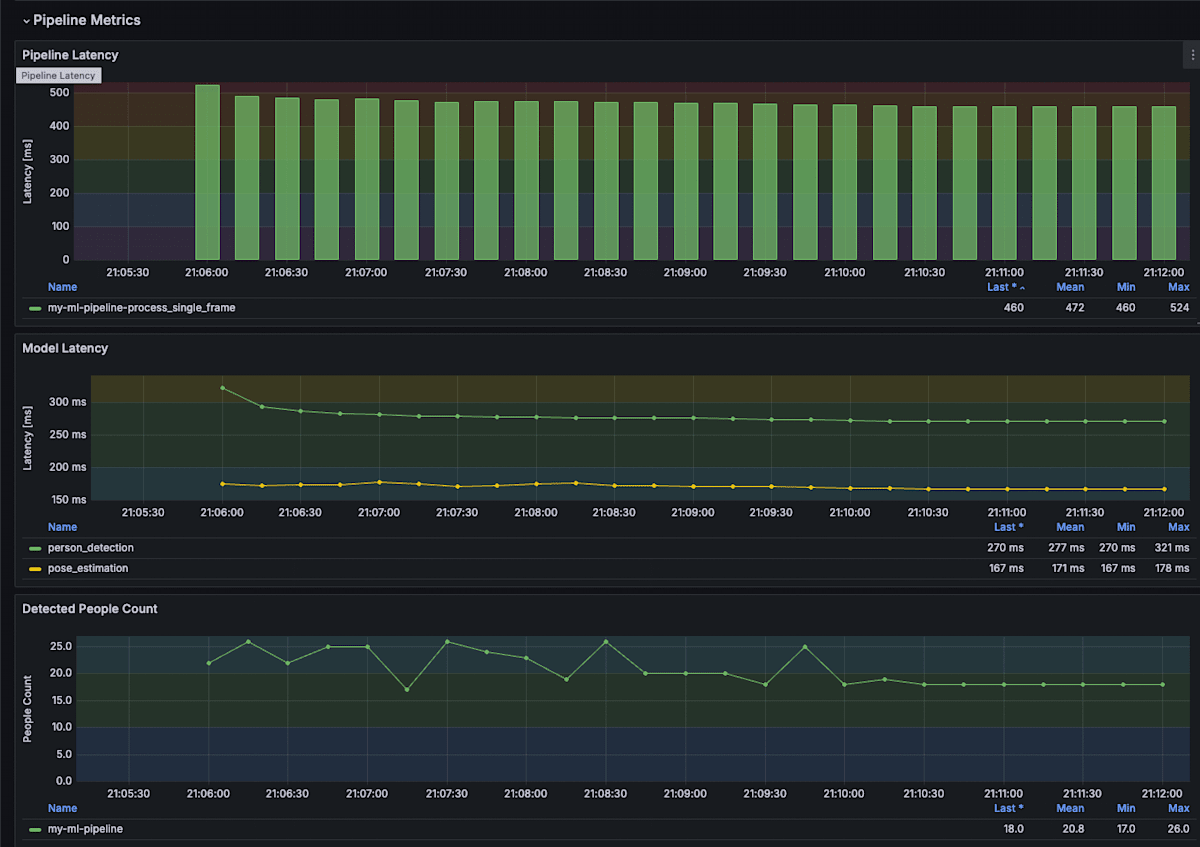
Grafana は、GPU 関連のメトリクスは OpenLITのダッシュボードを参考に作成しました。パイプラインの処理時間の部分は自作です。
パイプラインの実行中に、GPU のメモリ使用状況と検出された人数が同時に見れるのは、とてもありがたかったです。
TransPose は手を抜いて、全ての bbox をまとめて 1 バッチで処理しているので、検出された人数が多くなりすぎるとメモリ不足で落ちます (実際に落ちました)。そのときに、Grafana でメモリ使用量と検出人数が残っているので、どのくらいの人数までならメモリ不足を起こらないかすぐに検討をつけることができました。これまでであれば、パイプラインを再実行して、検出数を print しながら、nvidia-smi -lでメモリ使用量を確認する必要がありました。リアルタイムに結果が見れて、さらに値がグラフで残るので、非常に快適なデバッグでした。
Metrics on Grafana (GPU)
Metrics on Grafana (Latency)
OTel は単一サーバの ML Pipeline でも有用なのか?
結果が見れたところで、最初の問いに立ち戻りたいと思います。今回実装してみて、メリットだと感じた点は以下の通りです。
- トレースの可視化が簡単にできるので、パイプラインの処理時間のボトルネックを特定しやすい。
- かつては Log メッセージにトレース情報を吐き出して読み出していたので、その辺りのカスタム実装を省略できる。
- メトリクスの可視化が簡単にできるので、パイプラインの実行中の状況をリアルタイムで確認できる。
- 長めの動画を処理する際は、処理の状況を Grafana などのダッシュボードで確認する方が、ログを見るよりも直感的。
- 長時間実行しないと再現できない問題の把握に役立ちそう。
- Python 側のコードはほぼいじらずに、開発と運用の両方で利用できそう。運用のためにメトリクスを足したとしても、元の Python コードがそこまで汚くならない。
- (補足) 開発時は Weight & Bias などでメトリクスをとることができるが、運用時にこの手法は適さないと思われる。その点、OTel で収集したメトリクスは運用時にもそのまま使用可能と思われる。
逆にデメリットとしては、以下の点が挙げられます。
- Pytorch Profiler や Nsight Sytems ほどの詳細な情報は得られないので、モデルの最適化などには向いていない。
- Grafana のダッシュボードを誰が作るか?メトリクスが頻繁に追加削除される場合、ダッシュボードの運用が大変。
まとめ
長期的な視点で観測しておきたい主要なメトリクスを収集するには、OTel は実装も簡単で、単一サーバの ML Pipeline でも十分に有用だと感じました。
開発のワークフローにも組み込みやすいような使い方ができるのであれば、さらに便利なのかなと思います。具体的には、Triton Inference Server でモデルをホストするとするときに、別プロセスで実行されているモデルのログやメトリクスを一箇所に集めて、Artifact として保存できたりすると、開発効率が上がるのではないかと思いました。
オブザーバビリティの勉強をしつつ、上手な使い方を模索していきたいと思います。
参考文献
-
"OpenTelemetry - Documentation"
- "Glossary," Docs
- "Span Metrics Connector," GitHub
- "Prometheus Exporter," GitHub
- "Python プロジェクトに OpenTelemetry を導入する," CADDi Tech Blog, March 2, 2022.
- "OpenTelemetry と Grafana で Logs と Metrics と Traces を接続する," Qiita, Dec 20, 2022.
- "OpenTelemetry に触れてみた," Zenn, Apr 2, 2023.
- "OpenTelemetry Collector の Span Metrics Connector を使ってメトリクスを生成してみる,", Zenn, Dec 22, 2023.
- "OpenTelemetry と Prometheus," Qiita, Dec 24, 2023.
- "OpenTelemetry でメトリックを計装するときによく出現する Reader や Aggregation など色々な用語をまとめて紹介します," ブログ mackerelio, Dec 31, 2023.
- "OpenTelemetry 超入門," Qiita, Mar 14, 2024.
- "テレメトリーを関連付けて Grafana で Metrics から Trace にジャンプする," Zenn, Apr 11, 2024.
- "OpenTelemetry による計装と OpenTelemetry Collector について調べてみた," Streae ブログ, May 7, 2024.
補足: 顔の匿名化について
私は今回のアプローチをブラックリスト方式と呼んでいます。このアプローチでは、置くルージョンが激しい場合に検出が落ちることが多く、匿名化に失敗することが多い印象です。
以前は、画面全体に対してセマンティックセグメンテーションを行い、骨格推定で得た顔以外の部分のマスクを外す方法で実装を行いました。私はこれをホワイトリスト方式と呼んでいます。ホワイトリスト方式の方が、オクルージョンなどマスクが外れる事態を防ぎやすいので、現在公開されているデータは安全側に寄せてホワイトリスト方式で作成しました。
そのほかにも世の中には、商用の API 含め様々な方法があるので、また時間があるときに調べたいと思います。
-
データ収集の際に被験者と交わした同意書に記載された、動画公開のための条件です。 ↩︎
Discussion