動画生成AI: 比較×5、低VRAM: 11GB、ローカル: I2V編
はじめに
前回の text to video: T2V 編に続く image to video: I2V 編です。
Hunyuan-Video の I2V
Hunyuan-Video の Tencent は、まだ正式な I2V を公開していません(2025.02.24現在)。しかしながら、前回の T2V 編から一か月の間に、 Leapfusion や Skyreels などのサードパーティが、Hunyuan-Video で I2V を実現できるモデルを提案しています。Leapfusion は I2V 機能を LORA として、Hunyuan-Video の基本モデルに追加します。一方、SkyReels は新しい I2V モデルとして、Hunyuan-Video のファインチューニングモデルを提供します。
動画生成AI の I2V は、ComfyUI、Geforce RTX 2080Ti_11GB のローカル環境でどこまで遊べるでしょうか? 以下、 workflow の seed 項目は、fixed を外して下さい。動画作成に長い時間かかった挙句、同じ動画を見ることになってしまいます。
PCスペック
OS: Windows 11 Pro
CPU: Intel i9-9900K 3.6GHz
RAM: 64GB
VRAM: Geforce RTX 2080Ti 12GB
CUDA: 12.1
python: 3.11.8
pytorch: torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0
方法と検証
a. input 画像
写真ACさんのフリー素材で、やまガールさんに”手を振ってヤホーと叫んで”もらいました。
- input 画像

b. プロンプト
以下の共通プトンプトで動画生成しました。プトンプトはローカル環境で Ollama の llava-phi3 モデルを使用し、画像を読み込み生成しています。
1. PyramidFlow
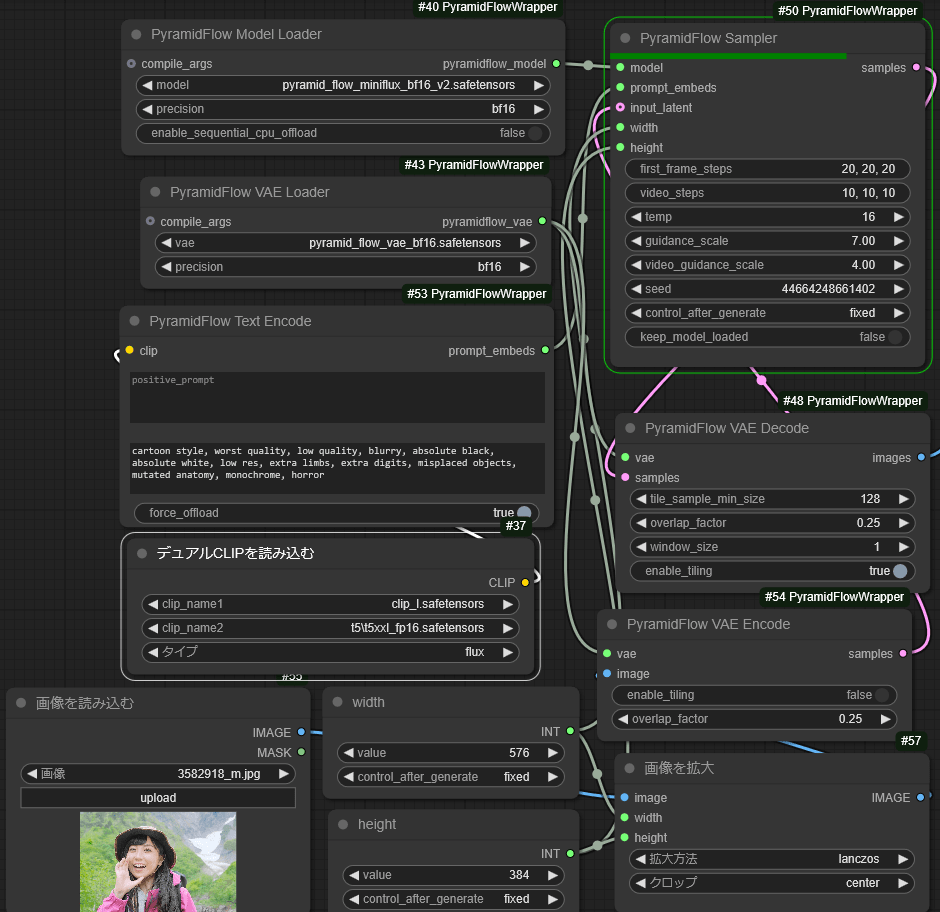
PyramidFlow では、以下の a. b. 二種類のモデルで I2V を行い、5秒の動画を生成しました。5秒動画の生成時間は約 18分です。

Workflow は”ComfyUI\custom_nodes\ComfyUI-PyramidFlowWrapper\examples” にある I2V worlflow を用いました。PyramidFlow ではプロンプトが 126 トークンを超えるとエラーになるため、前述のプロンプトをさらに 126 トークンまで圧縮して使用しました。プロンプトなしでも動画は生成されます。また生成する動画の、幅、高さは 8の倍数である必要があります。
縮小プロンプト
Best quality, 4k, HDR. Young Japanese woman outdoors in nature. Long black hair, bright pink raincoat (open, gray lining visible), brown bucket hat, lightweight backpack. Smiling, shouting "yoo-hoo" with left hand to mouth. Mountain slope background, valley with snow-covered stream visible. She seems at home in nature. After shouting, she waves to us.
a. pyramid_flow_miniflux_768_bf16.safetensors
このモデルでは、まったく動画生成できませんでした。

| プロンプトなし | プロンプトあり |
|---|---|
 |
 |
b. pyramid_flow_miniflux_bf16_v2.safetensors
このモデルでは、背景など比較的保持できていますが、人物は一貫性が破綻しています。PyramidFlow I2V をプロンプトで制御するのはきわめて困難だと思います。
| プロンプトなし | プロンプトあり |
|---|---|
 |
 |
2. LTX-Video
LTX で生成した 4秒動画です。 4秒動画の生成時間は約 2分です。

ComfyUI_examples の workflow I2V を用いました。背景は雪渓の谷沢など良く保持されています。以前の T2V と同様、時間とともに一貫性が破綻します。特に手指の形状を維持するのは難しいようです。ガチャ要素が強く、case 2 で軽く手を振った?程度のプロンプト追従です。また 4秒を超えたり、サイズが 768x512 px を超えると動きがなくなります。VRAM 容量が影響していると思います。
| Case 1 | Case 2 |
|---|---|
 |
 |
3. Hunyuan-Video Leapfusion
Leapfusion は、ComfyUI で I2V を行うため、LORA 拡張モデルを読み込む必要があります。Workflow は kijai さんが提供する a. と、 Comfyonline が提供する b. を用いました。a. も b. も手指の一貫性は、LTX より改善されていると思います。しかしながら、input 画像のキャラクター再現性や画質に関しては、LTX より良好とは言い難い結果でした。両者とも、動画サイズが 480x320 px であれば、OOM なく 4秒の動画が作成できました。早回し感があり fps 調整が必要と思われます。
I2V 用 LORA モデル:leapfusion_img2vid544p_comfy.safetensors
a. leapfusion_hunyuuanvideo_i2v_native_testing.json
4秒動画の作成時間は、約 17分でした。


| Case 1 | Case 2 |
|---|---|
 |
 |
b. hunyuan Leapfusion image to video share.json
4秒動画の作成時間は、約 24分でした。


| Case 1 | Case 2 |
|---|---|
 |
 |
4. Hunyuan-Video Skyreels
Skyreels は、ComfyUI で I2V を行うため、Hunyuan-Video をファインチューニングした新しいモデルを使用します。新しいモデルでは、プロンプトを FPS-24 で始めるように code されているので、この点に注意します。Workflow は kijai さんが提供する a. と、 Comfyonline が提供する b. を用いました。a. は動画サイズが 480x320 px であれば、OOM なく 4秒の動画が作成できました。ところが、 b. は様々に条件を変え、multiGPU ノードで読み込みを分散しても、ローカル環境では OOM を回避できませんでした。b. は Comfyonline で作成した動画を参考に挙げます。Comfyonline の RTX 4090 24GB の環境でも 2秒動画以上は OOM になります。
さすが、Skyreels は Hunyuan-Video をファインチューニングした甲斐あって、プロンプトへの追従が良く、やまガールはみなさん手を振ってくれました。また、input 画像キャラクターの保持性も最も良かったと思います。
a. skyreels_hunyuan_I2V_native_example_01.json
4秒動画の作成時間は、約 35分でした。


| Case 1 | Case 2 |
|---|---|
 |
 |
b. hunyuan SkyReels image to video share.json
Comfyonline で動画サイズ 960x640 px 2秒動画の作成時間は、約 13分でした。


| Case 1 | Case 2 |
|---|---|
 |
 |
5. Cosmos
Workflow は、 Comfyonline が提供する workflow を用いました。良好な結果が得られる workflow の条件として、幅、高さが 704 px 以上、長さ 121 フレーム以上がありますが、低VRAM で条件を満たすのは困難です。画像サイズを落とすと、低VRAM でもかろうじて走りますが、得られる画像は blackscreen になります。
Comfyonline で作成した動画を参考に挙げます。input 画像キャラクターの一貫性は保持できていると思いますが、手指の形状保持は難しいようです。また、動き自体はオーバーアクション気味で、カメラワークに酔いそうです。
cosmos image to video.json
Comfyonline で動画サイズ 960x640 px 5秒動画の作成時間は、約 8分でした。


| Case 1 | Case 2 |
|---|---|
 |
 |
まとめ
AI が見ている仮想空間が、モデルによってかくも違うのかと実感しました。指示したプロンプトは同じでも、やまガールさんの挙動は千差万別です。
ローカル完結、低VRAM で最も良好な結果が得られる I2V は、個人的には Hunyuan-Video Skyreels だと思います。Hunyuan-Video のプロンプトに反応が良い特徴を継承しつつ、入力画像の一貫性も保持できています。
次の機会は、ローカル環境でマルチモーダルに使える LLM や tagger による イメージプロンプト作成について実験したいと思います。今回も長ったらしいジジイの記事にお付き合いいただき有難うございました。
あとがき
Load Image node の Filter list (cache list) が delete (clear) できない。
ComfyUi で 新しいアプリを試すときは、それ用の ComfyUI を git clone から作成し workflow を試します。うまく動かなければ、ComfyUI ごと削除します。このほうが他の ComfyUI アプリに影響が出ません。ところがこの方法では、至る所に output フォルダが出来ていちいち探しに行くのが面倒。そこで昨日起動オプションで、 python main.py --output-directory D:/<my_new>/output --temp-directory D:/<my_new>/temp --input-directory D:/<my_new>/input に設定しました。output のついでに、input や temp にもオプション付けたのをスッカリ忘れてました。Load Image の Filter list が溜まってクリアしたいのに、やり方がわからない。Claude さんからも Google からも、input フォルダの内容を削除せよと言われるが、ComfyUi 配下の input には何もない(そりゃ自分でそういう設定に昨日したから)。Venv や AppData の cache を削除しても Filter list が削除できない。なにこれ config.ini か、どこかの json か、ウギャーの長期戦に。自分で蒔いた種なのに、健忘症とは恐ろしいものです。
Discussion