こんにちは、初めましての方は初めまして。株式会社 Fusic の瓦です。人生で五回目の痛風を発症したので、そろそろお酒を控えるべきかちょっと真剣に悩んでいます。
この記事では、Stack More Layers Differently: High-Rank Training Through Low-Rank Updates(以降 ReLoRA として参照)の解説を行います。この論文は、以前解説した LoRA[1] のアイデアを、ファインチューニングではなく事前学習時に適用したものになります。「ファインチューニングで LoRA 使えば効率的に学習できますよね。じゃあ事前学習にも同じ考えを適用して効率的に学習できるのでは?」みたいな感じです。実装は Github にて公開されています。
概要
LoRA で提案されていた行列分解によるパラメータ削減の方法を、学習時に適用した手法です。ステップ数が増えるにつれて学習するパラメータを段階的に追加していくことで、全体でよりよくパラメータの学習が行えると主張しています。

Fig. 1 より引用
250M 全体を学習させたモデルと比較すると、途中から 99M だけを学習するようにしたモデルでは同じくらいの損失になっています。また、99M 全体を学習させたモデルと比較すると、途中から 99M だけを学習するようにしたモデルの方が損失が低くなっています。このように ReLoRA を用いることで、少ないパラメータ数でより効率的に学習を行うことが出来ます。
提案手法
LoRA での学習を軽く振り返ります。LoRA ではファインチューニング用のパラメータ
ReLoRA ではこの考えを学習時に適用します。学習ステップをいくつかに分割し、それぞれの区間ごとで新しく差分
このようにいくつかの行列に分割することで、行列のランクが増えてよくなるよねという考え方らしいです。ただし途中で新たにパラメータを追加すると、Adam のようにそれまでの勾配を考慮するような手法ではうまく学習できなくなります。そのため、ReLoRA ではスケジューラーとして jagged-cosine という手法を取り入れています。
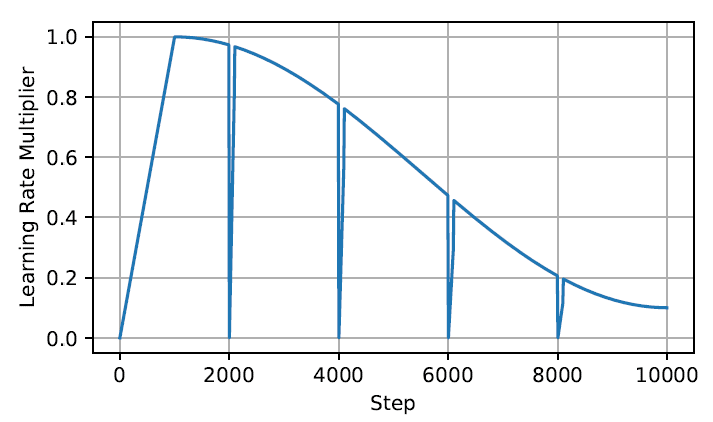
Fig. 2 より引用
図で見ると分かるように、全体的には cosine スケジューラーを取り入れつつ、各ステップの初めに warmup するような手法になっています。これによりうまく学習が行えるようになります。
実験
実験で使用したモデルは以下の四つになります。

Tab. 1 より引用
そして結果がこちら。
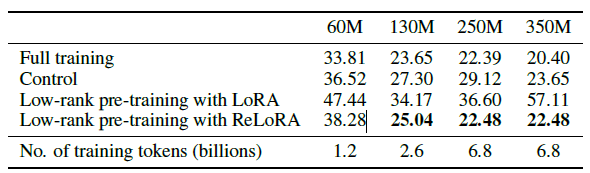
Tab. 2 より引用(パープレキシティによる評価)
Control という先行研究と比較すると、60M より大きいモデルでは Control よりもよい結果になっています。また、全てのパラメータを学習した場合のパープレキシティにもどんどん近づいていることが分かります(350M は WIP らしいので、ちゃんとした結果が出てからに期待)
冒頭に載せた Fig. 1 の引用を見ると、250M 全体を学習させた場合と 99M だけ学習させた場合で同じような損失曲線を辿っています。また、99M 全体を学習させた時よりも損失が低く、少ないパラメータでより効率的に学習出来ていることが分かります。
また 1.3B のモデルで少しだけ学習してみたところ、メモリ消費量が 30% 減少し訓練は 52% ほど速くなったとのことです。これで同じくらいの精度が出るのであれば、大規模言語モデルの訓練の敷居が少し下がりそうで期待できます。
まとめ
この記事では、LoRA での考えを学習時にも適用した ReLoRA という手法を紹介しました。学習を軽いモデルで行える部分は嬉しいポイントです。ただし正直なところ、ランクを大きくすることが本当にいいのかは分からないと感じています。1.3B での精度や、それよりも大きなモデルでどのような傾向になるのかを実験した結果も見てみたいところではあります。
最後に宣伝になりますが、機械学習でビジネスの成長を加速するために、Fusicの機械学習チームがお手伝いたします。機械学習のPoCから運用まで、すべての場面でサポートした実績があります。もし、困っている方がいましたら、ぜひFusicにご相談ください。お問い合わせからでも気軽にご連絡いただけます。またTwitterのDMからでも大歓迎です!

Discussion