こんにちは!Fusic 機械学習チームの鷲崎です。最近、音声や言語処理に興味がありますが、機械学習モデルの開発からMLOpsまでなんでもしています。もし、機械学習で困っていることがあれば、気軽にDMください。
本記事では、Flow Matching (FM)と、その発展版であるOptimal Transport Conditional Flow Matching (OT-CFM)を解説します。最近の生成AIでは、拡散モデルがよく使用されていますが、Flow Matchingは、拡散モデルに取って代わる可能性がある生成技術と考えています。
おもに、Improving and Generalizing Flow-Based Generative Models with Minibatch
Optimal Transportという論文を参考に解説していきたいと思います。また、本記事の図は、論文から参照いたしました。
Flow Matachingは、音声合成においては、Metaが発表した音声合成手法であるVoiceboxや、より高速で高性能な音声合成手法であるMatcha-TTSに使用されてきています。
Matcha-TTSに関しては、弊社のToshikiが、記事を書いているので、ぜひ、読んでみてください。
【音声合成】Matcha-TTS🍵で日本語音声を生成してみる
個人的に、Flow Matchingは、拡散モデルが発展した手法と考えて論文を読み始めたのですが、それだとかなり勘違いしてしまっていました。皆さん、Normalize Flowという手法を聞いたことがありますでしょうか?現在、拡散モデルがバズワード化しすぎて、あまり耳にしないかもしれませんが、分布を変換する関数を学習するとてもおもしろいモデルです。そのNormalize Flowの発展版がFlow Matchingと考えるとスムーズに納得できた気がします。
そこで、本記事では、拡散モデルとNormalize Flowの関係性からFlow Matchingまでの過程とその発展を解説していきたいと思います。
理解が及ばなかった部分が多々あるため、ご指摘をたくさんいただけると嬉しいです。よろしくお願いいたします。
基礎
Flow Matchingを理解するために、まず、拡散モデルの拡散過程を連続時間化した、確率微分方程式(SDE)を説明します。そして、それを常微分方程式(ODE)に変換した確率フローODEを説明します。
その後、確率フローODEが、Normalize Flow (NF)を連続化したContinuous Normalize Flow (CNF)と、どのように関連するか説明します。
SDEとODEの詳細に関しては、拡散モデル データ生成技術の数理という本がとても参考になります!ぜひ読んでみてください。
拡散モデルの確率微分方程式(SDE)
拡散モデルでは、拡散・逆拡散過程のステップ数を増やせば増やすほど、離散化誤差が小さくなり生成性能が向上します。そこで、ステップ数を無限大に増やして連続化した場合の拡散モデルを考え、このモデルは確率微分方程式(SDE)とみなすことができます。
拡散過程に相当する拡散SDEは、以下の式で与えられます。
一方で、逆拡散過程は、以下のSDEで与えられます。
時刻
Denoising Diffusion Probabilistic Model (DDPM)の場合
元のDDPMの式は、以下です。
この式を、SDEに変換した場合、以下のようになります。
ここでの、
確率フロー常微分方程式 (ODE)
任意のSDEは、同じ周辺分布
確率的な要素が除外され、拡散過程では
Normalizing Flow
Normalizing Flow (NF)は、複雑な分布を、より単純な分布へ変数変換(Normalize)する関数です。
例えば、シンプルな確率密度関数
NFでは、この変数変換を行う関数
また、NFでは、この性質をもつ関数
ざっくりしたイメージですが、
Continuous Normalizing Flow
Neural Ordinary Differential Equations (Neural ODE) という論文で、連続時間化したNormalizing Flow を Continuous Normalizing Flow (CNF)と呼んでいました。
Neural ODEでは、Residual Networkのように、残差を計算の結果を元の値に付加することで値を更新する方法に着目し、以下のように常微分方程式の式に似た概念を導入しています。
この表現を用いる利点は、時刻も入力としたことで、変化量の微分を表す単一のネットワークを使用すればよく、メモリの使用量を削減できます。加えて、逆変換の計算が可能で、RNNなど離散的な時間を扱うモデルとはことなり、連続時間を扱うことができます。※これの特殊系が確率フローODEになります。
このNeural ODEの考えを用いて、時間連続性をもつNFであるContinuous Normalizing Flow (CNF)は、以下のように表されます。
この式は、確率変数
また、この変換の逆変換も、以下のように書くことができます。
上記のことから、拡散モデルの拡散過程と逆拡散過程に類似した表現をすると、拡散過程にあたるCNFでは、
となり、逆拡散過程にあたるCNFでは、
のように表現できます。
なぜ、拡散モデルがよいとされているのか?
拡散モデルのDDPMの損失は、以下になります。
この式の意味は説明しませんが、拡散モデルでは各時刻
一方で、CNFの損失は、以下になります。
見ての通り、全時刻に渡って積分した値を使用しており、計算グラフのすべてを使って学習が必要となる欠点があります。このようなアプローチは、Simulation based trainingと呼ばれます。これが原因で、学習効率が悪く、拡散モデルほど使用されていませんでした。
そこで、CNFの学習を改善したFlow Matchingが開発されました!
Flow Matching
CNFを安定して学習可能なFlow Matchingについて解説します。上記のように、時間全体の学習が必要である点が、CNFの欠点と言えます。そこで、CNFを時刻ごとに、学習可能にするために、Flow Matchingが、開発されました。
まず、微小時変ベクトル場
また、密度
このとき、時変密度
かなり説明を省いていますので、詳細は論文を読んでいただきたいのですが、個人的に確率経路
Flow Matchingは、ニューラルネットワーク
Flow Matching for Generative Modeling では、正規分布によるガウス確率経路
Flow Matchingにより、このベクトル場を回帰するように
Conditional Flow Matching
Flow matchingは、ガウス確率経路を仮定していました。そこで、ガウス分布の仮定を緩和し、2つの分布間の条件付き確率経路(ODE Bridge)の学習を可能にした、Conditional Flow Mataching (CFM)が提案されました。
潜在条件変数
ベクトル場
とします。周辺ベクトル場
このとき、条件付き確率経路
そこで、CFMの損失を
としたとき、特定の条件下で、
であることが論文で示されました。
つまり、条件付きベクトル場
これをConditional Flow Matching(CFM)とし、以下のアルゴリズム(論文中 Algorithm 1)で計算されます。

これより下の項目では、
Flow Matching from a Gauusian
Flow Matching for Generative Modeling で説明されたFlow MatchingをCFMの特殊なケースとして解釈した場合について説明します。
この論文では、
となります。
となります。実は、このベクトル場は、確率経路の平均と分散を上記FMの章に記載したベクトル場の式
に当てはめると計算できます!
下図は、論文中のFigure 1で、Flow Matchingのイメージです。ガウス分布がデータサンプルへ分散を小さくしながら遷移している確率経路が見えますね。

Independet CFM
CFMの基本形として、初期点
何を言いたいかというと、
そして、この確率経路の平均と分散をベクトル場の定式(flow matchingの項に記載)にあてはめると、ベクトル場は、
となります。かなりシンプルな形式になっていますが、これにより
下図は、論文中のFigure 1で、I-CFMのイメージです。固定の分散の分布が移動している事がわかります。
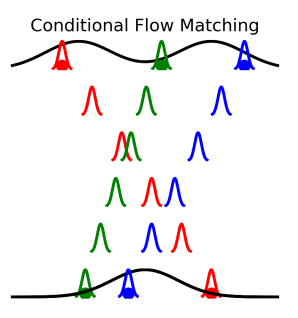
I-CFMのアルゴリズムは、以下になります。これだけ見ると、かなりシンプルですね。

Optimal Transport CFM
まず、2-Wasserstein距離による最適輸送(OT)に関して説明します。そして、OTを用いてCFMに関して説明します。
2-Wasserstein距離
最適輸送問題は、ある測度から別の測度へのマッピングを、コストが最小化するように求めるものである。論文では、2-Wasserstein距離を用いており、分布
そして、2-Wassrstein距離の動的形式は、ある測度を他の測度に変換するベクトル場
L2正則化を持つCNFが動的最適輸送に近似可能なことは証明されていますが、この式の計算には、多くの積分とバックプロパゲーションが必要なため数値的にも、効率的にも問題がありました。そこで、CFMとして、直接ベクトル場を回帰することで、これらの問題を回避することが提案されました。
OT-CFM
上記の2-Wasserstein距離をCFMに当てはめるため、2-Wasserstein最適輸送写像
これにより、
I-CFMに対して、この修正を行ったものが、OT-CFMになります。
論文では、
OT-CFMは、
と q(x_0) の間の静的OT写像と中間時間ステップで条件付きフローの回帰のみを用いて、シミュレーションフリー(時間ごとに学習可能)な動的OT問題を解いた最初の手法である。 q(x_1)
とのことです。
下図は、論文中のFigure 1で、OT-CFMのイメージです。I-CFMと異なり、時刻
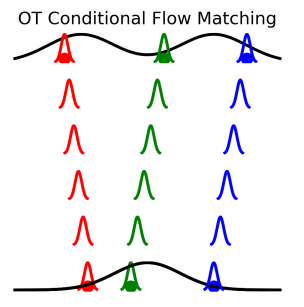
実際、下図のようにmoonから9つのガウス分布の生成を行っていますが、左側のI-CFMより、右側のOT-CFMが明らかにシンプルな遷移を行っています。

下図は、OT-CFMのアルゴリズムを示しています。
アルゴリズム中にOTのミニバッチ近似が出てきます。大きなデータセットにおいて、OTにおける輸送計画
実際アルゴリズムを見ると、変わったところは、OTの部分くらいかと思います。

Schrödinge Bridge CFM
論文中には、シュレディンガーBridge(SB)によるCFMもでてきます。勝手なイメージですが、I-CFMとOT-CFMの中間に当たると思っていますが、理論が複雑で説明が、かなり長くなりそうなので省きます。ぱっとみ、SB-CFMより、OT-CFMのほうが精度が良さそうでした。ただ、Schrodinger Bridges Beat Diffusion Models on Text-to-Speech Synthesisという論文もでていたので、次回の記事を書く際にしっかり理解したいと思います。(誰か書いてください!!)
ちなみにですが、Schrödinge Bridgeに関しては、以下の記事がとても参考になりました。すごく良い記事です!
比較
最後に比較結果です。
下図は、分布の適合度(一致度?)を示した2-Wasserstein
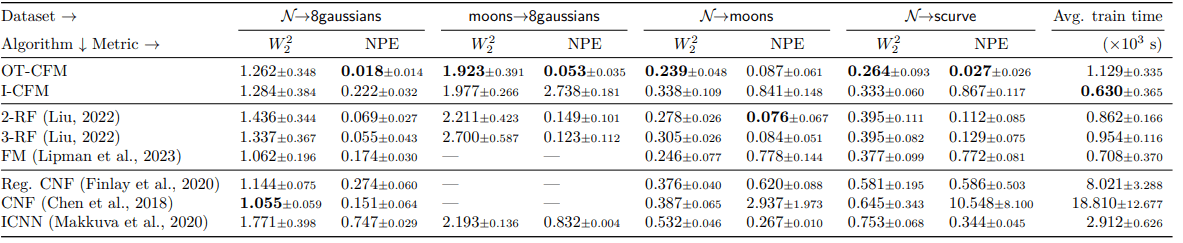
また、下図の左より、学習時の検証セットに対する誤差の収束も早いことがわかります。

プログラム上でどう記載するのか?
理論ばかり書いても、まぁわからないので、いくつか実装例を見てみましょう。
まずは、CFMを使用している音声合成モデルであるMatcha-TTSです。ここでは、
実装を見ると、概ねアルゴリズム通りですが、ランダムなsigma_minが入っています。ただ、この値は、かなり小さい(
また、確率経路から、データ
def compute_loss(self, x1, mask, mu, spks=None, cond=None):
"""Computes diffusion loss
Args:
x1 (torch.Tensor): Target
shape: (batch_size, n_feats, mel_timesteps)
mask (torch.Tensor): target mask
shape: (batch_size, 1, mel_timesteps)
mu (torch.Tensor): output of encoder
shape: (batch_size, n_feats, mel_timesteps)
spks (torch.Tensor, optional): speaker embedding. Defaults to None.
shape: (batch_size, spk_emb_dim)
Returns:
loss: conditional flow matching loss
y: conditional flow
shape: (batch_size, n_feats, mel_timesteps)
"""
b, _, t = mu.shape
# random timestep
t = torch.rand([b, 1, 1], device=mu.device, dtype=mu.dtype)
# sample noise p(x_0)
x0 = torch.randn_like(x1)
# 確率経路の平均計算
y = (1 - (1 - self.sigma_min) * t) * x0 + t * x1
# ベクトル場の計算
u = x1 - (1 - self.sigma_min) * x0
loss = F.mse_loss(self.estimator(y, mask, mu, t.squeeze(), spks), u, reduction="sum") / (
torch.sum(mask) * u.shape[1]
)
return loss, y
これを、OT-CFMに改造してみましょう。実際動作させていないですが、おそらく以下のようになると思います。最適輸送には、POT: Python Optimal Transportというライブラリを使用します。
from functools import partial
import ot as pot
class OTCFM()
def __init__(self, ot_method):
if ot_method == "exact":
self.ot_fn = pot.emd
elif ot_method == "sinkhorn":
self.ot_fn = partial(pot.sinkhorn, reg=reg)
elif ot_method == "unbalanced":
self.ot_fn = partial(pot.unbalanced.sinkhorn_knopp_unbalanced, reg=reg, reg_m=reg_m)
elif ot_method == "partial":
self.ot_fn = partial(pot.partial.entropic_partial_wasserstein, reg=reg)
def get_map(self, x0, x1):
"""Compute the OT plan (wrt squared Euclidean cost) between a source and a target
minibatch.
Parameters
----------
x0 : Tensor, shape (bs, *dim)
represents the source minibatch
x1 : Tensor, shape (bs, *dim)
represents the source minibatch
Returns
-------
p : numpy array, shape (bs, bs)
represents the OT plan between minibatches
"""
a, b = pot.unif(x0.shape[0]), pot.unif(x1.shape[0])
if x0.dim() > 2:
x0 = x0.reshape(x0.shape[0], -1)
if x1.dim() > 2:
x1 = x1.reshape(x1.shape[0], -1)
x1 = x1.reshape(x1.shape[0], -1)
M = torch.cdist(x0, x1) ** 2
if self.normalize_cost:
M = M / M.max() # should not be normalized when using minibatches
p = self.ot_fn(a, b, M.detach().cpu().numpy())
return p
def sample_map(self, pi, batch_size):
r"""Draw source and target samples from pi $(x,z) \sim \pi$
Parameters
----------
pi : numpy array, shape (bs, bs)
represents the source minibatch
batch_size : int
represents the OT plan between minibatches
Returns
-------
(i_s, i_j) : tuple of numpy arrays, shape (bs, bs)
represents the indices of source and target data samples from $\pi$
"""
p = pi.flatten()
p = p / p.sum()
choices = np.random.choice(pi.shape[0] * pi.shape[1], p=p, size=batch_size)
return np.divmod(choices, pi.shape[1])
def compute_loss(self, x1, mask, mu, spks=None, cond=None):
"""Computes diffusion loss
Args:
x1 (torch.Tensor): Target
shape: (batch_size, n_feats, mel_timesteps)
mask (torch.Tensor): target mask
shape: (batch_size, 1, mel_timesteps)
mu (torch.Tensor): output of encoder
shape: (batch_size, n_feats, mel_timesteps)
spks (torch.Tensor, optional): speaker embedding. Defaults to None.
shape: (batch_size, spk_emb_dim)
Returns:
loss: conditional flow matching loss
y: conditional flow
shape: (batch_size, n_feats, mel_timesteps)
"""
b, _, t = mu.shape
# random timestep
t = torch.rand([b, 1, 1], device=mu.device, dtype=mu.dtype)
# sample noise p(x_0)
x0 = torch.randn_like(x1)
# OTを用いて、x0, x1をサンプル
pi = self.get_map(x0, x1)
i_arr, j_arr = self.sample_map(pi, x0.shape[0])
x0, x1 = x0[i_arr], x1[j_arr]
y = (1 - (1 - self.sigma_min) * t) * x0 + t * x1
u = x1 - (1 - self.sigma_min) * x0
loss = F.mse_loss(self.estimator(y, mask, mu, t.squeeze(), spks), u, reduction="sum") / (
torch.sum(mask) * u.shape[1]
)
return loss, y
最後に
今回は、Flow Matchingをより効率的にした、OT-CFMについて解説しました。個人的に、数式が多く難しいな~と思いながらも、今後使える技術だと思い、記事にしてみました。この記事で、Flow Matchingの理解の手助けになればと思います。
今後は、シュレディンガーBridgeに関する記事か、実際にOT-CFMを使用した音声合成などの記事を作成できればと思っています。
最後に宣伝になりますが、機械学習でビジネスの成長を加速するために、Fusicの機械学習チームがお手伝いしています。機械学習のPoCから運用まで、すべての場面でサポートした実績があります。もし、困っている方がいましたら、ぜひFusicにご相談ください。お問い合わせから気軽にご連絡いただけますが、TwitterのDMからでも大歓迎です!
参考文献

Discussion