この論文、思ったより難しいですね。 すごく難しい言葉をたくさん使って理解するのに、頭が痛かったです
PointNetの問題点
PointNet++はPointNetの短所を補完する方向で研究が進められました。 PointNetの説明を見たいなら、前に私が記事を参考にしてください。 https://zenn.dev/fusic/articles/de5379fca388c6

上の図は、PointNetネットワークの構造です。 PointNetは、3D Point CloudデータのGlobal FeatureをFully Connected LayerとMax Pooling Layerを使用して抽出します。 (これからFully Connectedを略してFCと呼びます。)上の図の赤いボックスで表示した部分が一つのFully Connected Layerですが、下の図のように動作します。 nx3 サイズの入力行列があるとき、各行が一度に 1 回ずつFC Layer を経由します。 そうしながら次元は3から64に増えます。 この時、出力結果である64次元のFeatureは各点に対する活性化程度を意味します。
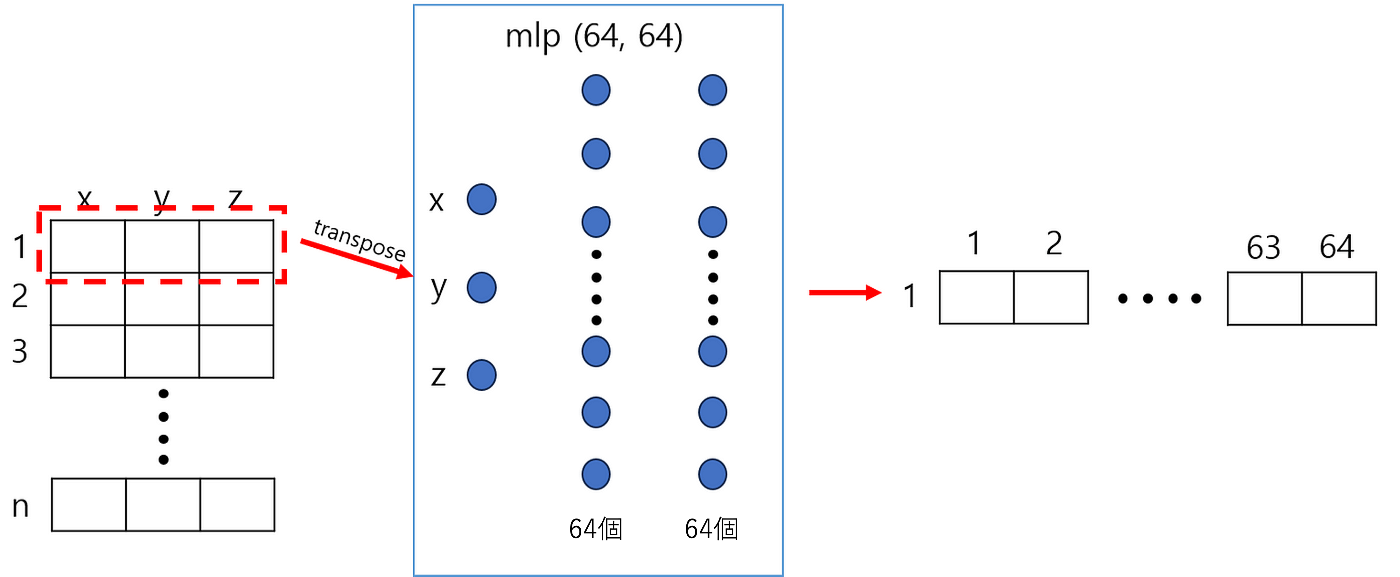
上記のFC Layerを経てnx64サイズの行列に変換され、もう一度FC Layerを経てnx1024サイズの行列が出力されます。 そしてnx1024サイズの行列は、10単位でMax Poolingを経て、1024次元ベクトルに変換されます。 そして、1024次元ベクトルはFC Layerをもう一度経ながらClassification結果が出力されます。
これまで言葉で説明した内容を以下の式のように作成することができます。 h、 γはFC Layerを意味し、MaxはMax Pooling Layerを意味します。
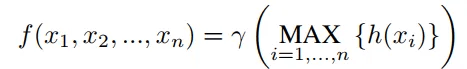
しかし、PointNetには問題点があります。 それぞれのPointがhというFC Layerに独立して適用されるため、Point CloudデータのLocal Structureを効果的に抽出できないという短所があります。
Local Structureを抽出することは思ったより重要です。 CNNを例に挙げます。 CNNは階層的な構造を通じてLocal+Global Featureをすべて含む出力物を生成します。 Global情報だけでなく、Local情報も持っていれば、初めて見るイメージについても予測がよりよくできるようになります。 論文では、このような特性をGeneralizabilityといいますが、翻訳すると「一般化の可能性」くらいになります。
PointNet++ ご紹介
Point CloudデータのLocal Featureを抽出するために、階層的構造を持つ人工神経網であるPointNet++を紹介します。
アイデアは簡単です。 重なる集合でPointを分割します。 (論文ではNested Partitioningを使うと出てきます。)理解を助けるために下の図を見てみましょう。 左側にPoint Cloudがあるとき、右側の図のように丸い集合でPointを分割するというアイデアです。
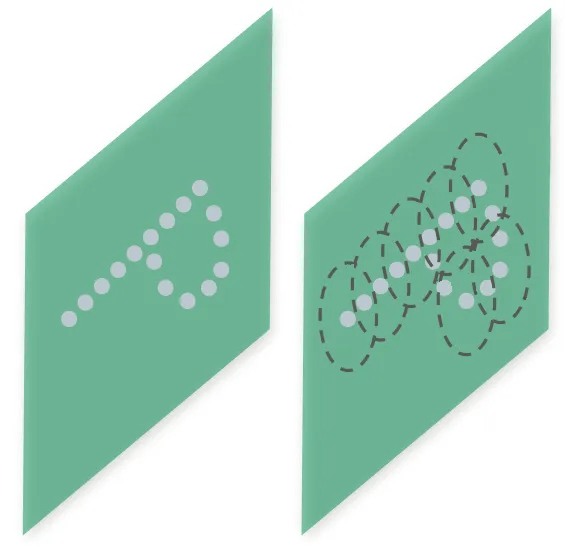
丸領域に分割してから、各領域からLocal Featureが抽出されます。 このように領域を分割するレイヤが階層的構造でいくつか積まれています。 そしてPointNet++の階層的構造に従い、Local Featureはより大きな領域のLocal Featureを盛り込むことになります。 このようなプロセスは、1つの領域が(丸)すべてのPoint Cloudを入れるまで繰り返されます。 もっと詳しい内容は後で説明します。
Point Cloudを分割した場合は、各領域から共通の構造を学習する必要があります。 ここで言う共通の構造とは、私の考えでは四角、三角、丸、線などの3D Point Cloud構造でよく見られる特徴のことだと思います。 このような共通の構造を学習するために、PointNetの構造が使用されます。 PointNetは、順序のないPoint Cloudポイントを学習するのに非常に有用なネットワークです。 学習がどのように行われるのかについては、後で詳しくご紹介します。
ところで、Point Cloudを分割するためには、一つの句(Partition)の中心点と(Centroid)句の大きさを(Scale)決定する必要があります。 中心点を求めるためには、Farthest Point Sampling (FPS) アルゴリズムが使用されます。 FPSを使用すると、下図の左のような結果が得られます。 右側にあるRandom Point Sampleアルゴリズムに比べて、FPSアルゴリズムを使った結果の密度がより均等であることが確認できます。 FPSアルゴリズムを使用すると、希望する数のPoint CloudでDown-samplingが可能になります。 Down-samplingとは、信号処理分野におけるデータの数を減らす過程を意味します。

分割したい領域のCentroidはFPSで求めます。 それでは、領域の大きさを求めることが残っています? これはCNNでKernel Sizeと似た概念です。 VGGネットワークでは、Kerel Sizeを3と非常に小さくし、非常に良い性能のObject Classificationの結果を得ることができました。 しかし、Point Cloudはデータのデータは希少なので、領域の大きさを常に小さくしてはいけません。 つまり、PointNet++で領域の大きさを決定することは一つのHyperparameterになります。 この内容に関しては後からもっと詳しくご紹介しましょう。
そして、PointNet++ではFeatureを学習するために、様々な階層の領域のデータを加えて使用します。 この時、どの階層から取得したデータにどれだけの重みを与えるかは学習されます。 詳しい内容も後で説明します。
PointNet++の構造
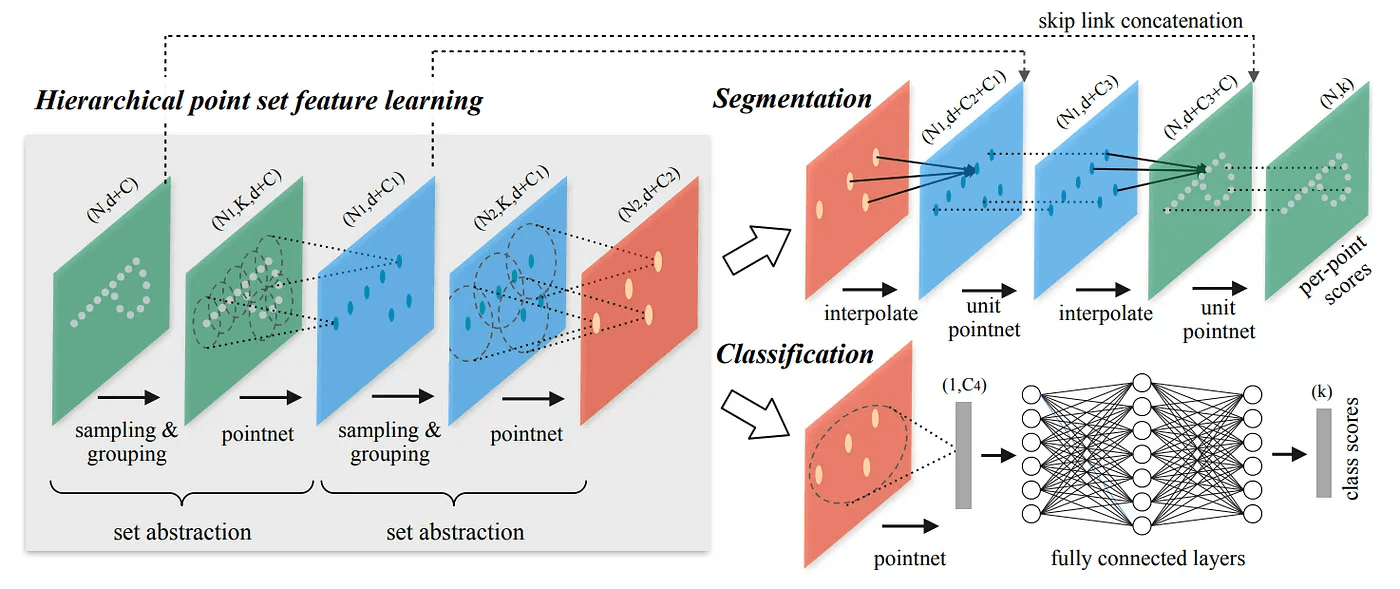
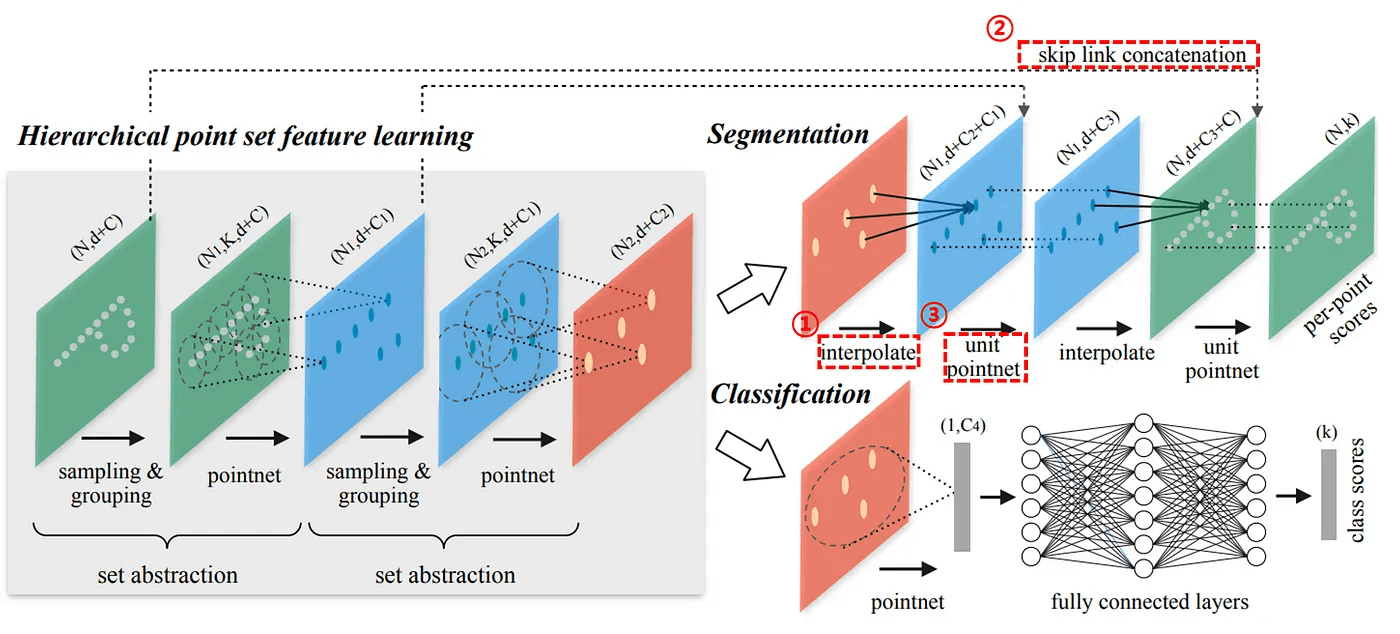
上の図はPointNet++の構造です。 Local Feature情報をよりよく抽出するために、PointNetとはかなり異なる構造を持っています。 PointNetは、1つのMax Pooling Layerを使用して、すべてのPoint Cloudの情報を総合しました。 PointNet++の構造は、漸進的により大きな領域のLocal Feature情報を抽出できる階層的構造を持っています。
PointNet++の構造はSet Abstract Layerで構成されます。 各Layerを経て、より少ない数の点が出力されます。 Set Abstract Layer の入力には、N x (d + C) 行列が入ります。 この時、Nは点の数、dは3次元空間の座標、Cはフィーチャー情報を意味します。 Set Abstract Layerは計3つの小さなLayerに分けられますが、詳しく説明します。
Sampling Layer
Sampling Layerでは、FPSアルゴリズムを使ってn個の入力された点の中からn'個の点をサンプリングします。
{x1, x2, …. , xn} -> {x1, x2, …. , xn’}
Grouping Layer
Grouping Layerで入力されるデータは二つです。
- N x (d + C)
- N’ x d
そして出力はN' x K x (d + C) 行列です。 KはCentroidが属する領域に含まれる点の数を意味します。 下の図で、赤色の円は一つの領域を意味し、水色の点はCentroid、黄色の点は領域の中に属する異なる点を意味します。 下記の場合、Kは7です。

この時、あの領域の大きさを決める2つの方式が存在します。
最初の方式はBall Query方式です。 半径の大きさを決めて、Centroid基準半径に属する点を一つの集合とみなす方式です。 下図のようになります。 radiusを10にしたのは例です。

二番目の方式はkNNです。 kNearest Neighborアルゴリズムを使用した方式であり、図は以下の通りです。 kを5に設定したのは例示です。
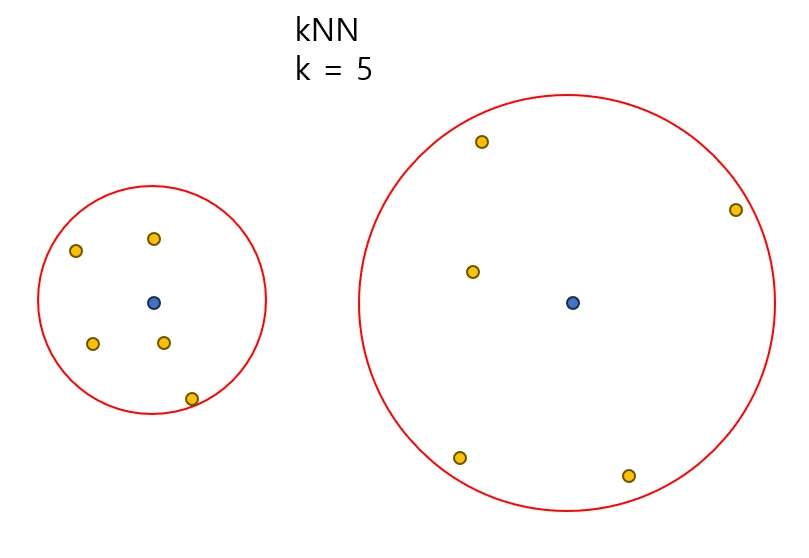
固定されたサイズの領域を使用する場合、Point CloudのLocal Structure情報を抽出しやすくなります。 それで、二つの方式の中でBall Query方式が使われました。
PointNet Layer
PointNet Layerの入力値はN' x K x (d + C)です。 一つの領域の中に属するK個の点の座標をxi、そしてCentroidの座標をkjとします。 すると、xi=xi-xjになり、xiはxj基準相対座標に変換されます。 例えば、x1 = (21, 20, 22)、xj = (1, 1, 1) のとき、以下の過程を経ます。
(20, 19, 21) = x1 - xj
すべての座標がCentroid基準、相対座標に変換され、Local Feature情報を得るためにPointNetネットワークを経由します。 この時、それぞれの点はFully Connected Layerを独立的に経ることになります。 そして出力されたLocal Featureは、Max Pooling、Average Pooling、またはConcatenationを経て、N'x(d + C')サイズの行列で出力されます。 この時、CentroidのLocal Feature情報がCからC'に増えたことが確認できます。
Robust Feature Learning under Non-Uniform Sampling Density
敢えて翻訳すると、「密度が均一でない状況での強健なFeature学習」程度に翻訳されます。 Point Cloudデータの密度は一様ではありません。 密度の高いPoint Cloudを学習したネットワークは、密度の低いPoint Cloudを推論するのに困難をきたすことがあります。
これらの点を克服するために、論文ではDensity Adaptive Layerを紹介します。 訳すと「密度適応層」です。 密度適応層は、複数のスケールの領域でフィーチャーを合わせるレイヤです。 この時、該当領域の密度によって様々なスケールのフィーチャーに加重値が異なります。
論文で2種類のDensity Adaptive Layerを紹介します。 何なのか詳しくご紹介します。
Multi-Scale Grouping (MSG)

上の図はMSGを作動方式を描いた内容です。 様々なスケールのフィーチャーが接続され、Multi-Scale Featureを構成する方式です。 モデルを学習段階で各スケールのフィーチャーにどれだけの重みを与えてMulti-Scale Featureを作るかを学習します。 そのためにRandom Input Dropoutの概念を使用します。 θというドロップアウト比率を決めます。 この時、θは以下の不等式を満足しなければなりません。
0 ≤ θ ≤ 0.95
θの最大値を0.95に設定するのは、1にするとPoint Cloudのすべての点がDropoutされる危険があるからです。 Random Input Dropoutを使用することにより、PointNet++ネットワークが希少性比率が(Various Sparsity)多様なデータセットを学習できるようにします。 また、密度の多様な(Various Uniformity)データセットを学習することもできます。 これを図で説明します。

Original SetでDropout比率を変えて、Various SparsityとVarious Uniformityを持つ部分集合を作ることができます。 これらのさまざまなデータセットで、学習したネットワークが堅牢になる可能性があります。 まるでData Augmentationと似ていると感じました。 そして、あまりにも当たり前の話ですが、推論する時はDropoutを使いません!
Multi-Resolution Grouping (MRG)
以前に説明したMSG方式は計算的に費用がかかります。 特に、最初のSet Abstraction Layerでは点数が最も多いので、MSGを実行するのに時間が長くかかります。 そこで著者は計算的に費用が少なくなるMRG方式を提案します。 図は下記の通りです。
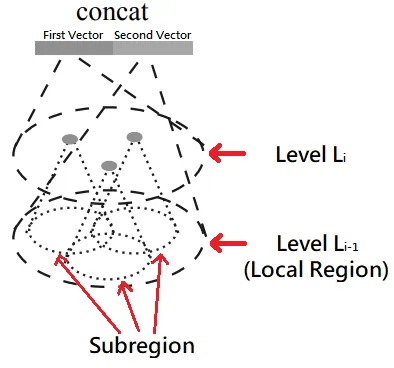
MRGはレベルLiで二つのベクトルが連結される方式です。 最初のベクトルは、レベルLi-1のSubregionから抽出された複数のFeatureを「総合」した結果です。 私が総合という表現を使いましたが、論文では「Summarize」という単語を使います。 二番目のベクトルは、レベルLi-1に属するすべての点からフィーチャーを抽出したベクトルです。
もし、Local Regionにある点の密度が低かったら、2番目のベクトルに加重値をもっと与えなければなりません。 なぜですか? 密度が低いということは、情報が不足しているということです。 Local Regionに属するSubregionから抽出したFeatureは使い勝手が良くないでしょう? 逆に、Local Regionに点の密度が高い場合は、最初のベクトルにより多くの重みを与える必要があります。 なぜなら、Subregionから抽出されたFeatureの情報はLocal Regionの微細な情報を含んでいるからです。
Point Feature Propagation for Set Segmentation
上記の小見出しの意味は「Set Segmentationのための点のFeature伝播」です。 PointNet++では、Point CloudデータがSet Abstraction Layerを通して減ることになります。 ところで、Segmentation作業の結果は、入力されたすべての点に対して特定のクラスに対するラベルを付ける必要があります。 つまり、Set Abstraction Layerを通じてなくなった点を復旧する方法が必要です。
単純な方法では、Set Abstraction Layerですべての点をCentroidに指定する方法です。 しかし、この方法は計算量が多すぎます。 そこで著者は、部分サンプルしたFeatureで元の点を復元する方法を提案します。
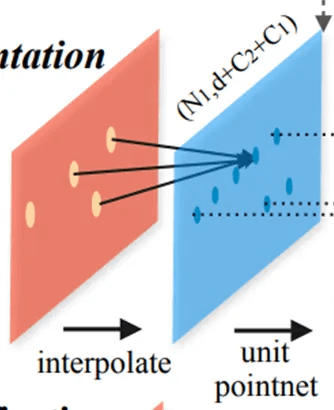
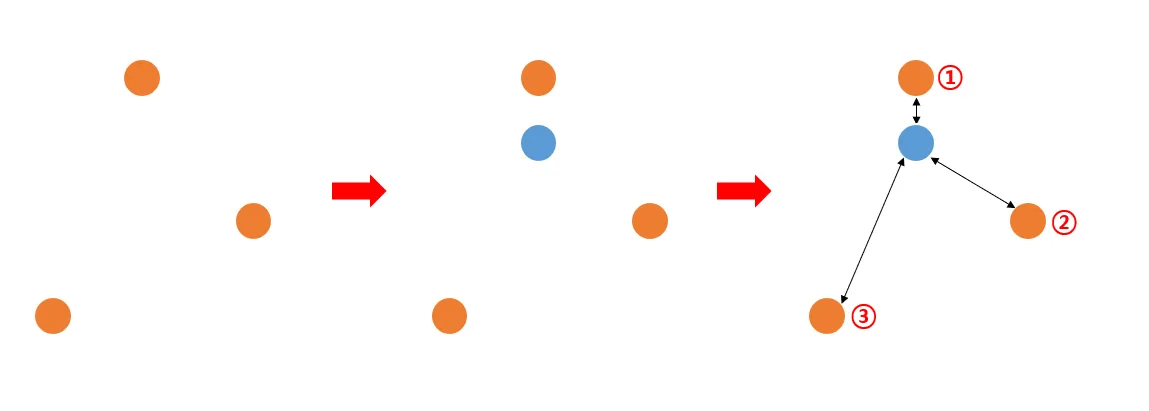
下記の図をご参考お願いします。 アイデアは単純です。 3つの点のFeatureを使って、青色の位置にあった点を復元するということです。

下図に示すように、復旧過程は計3つの段階に分けられます。 各段階についての説明を詳しくしてみることにしましょう。
Distance Based Interpolation
最初のステップです。 PointNet++の階層的構造で(上図の左部分)Nl-1の点の数がSet Abstraction Layerを経てNl個に減りました。 つまり、以下の不等式を満足しています。
Nl < Nl-1
これからはNl個の点を使ってNl-1個の点を逆に復旧する過程を図で説明します! 下の図は、PointNet++の階層的構造のSet Abstraction Layerのいずれかです。 N1個の点が入力され、最終的にN2個の点が出力されます。 (N1 > N2)

これからは逆にN2個の点でN1個の点を復旧しようと思います。 復旧した結果が下の図です。
この時、復旧しようとする点を基準に最も近い3つの点を使用します。 下の図を見てみましょう。 3つの点があります。 そして青い点を復旧しようと思います。 この時、青色の点と黄色の点との距離を求めます。 全部で3つの距離が計算されます。 計算した距離に逆数をとったものをwi(x)といいます。 たとえば、w1(x)は、最初の点と青い点の間の距離の逆数です。
それでは、以下の式を見てみましょう。 以下の式は、Inverse Distance Weighting Interpolationアルゴリズムを数式にまとめた内容です。 以下の式でpは2で2点間の距離を求める時に使われ、kは3で3つの点を意味します。 今まで下記式の右側の結果であるwi(x)を求める方法について話しましたか? これから下式の左側を求めればいいです。 ここで、fiはi 番目の点のFeature ベクトルを意味します。
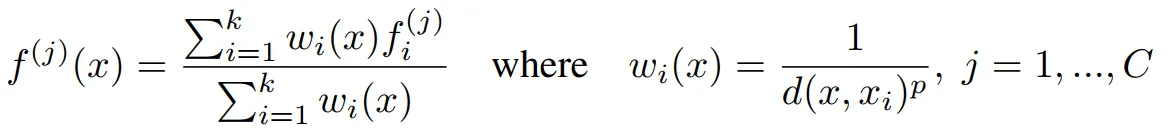
それで、Inverse Distance Weighting Interpolationアルゴリズムで求めたのは次のとおりです。 求めたい点と違う点の距離に反比例して加重値を与えた後に求めたい点のフィーチャーを復旧したものです。
Skip Link Concatenation with Features from Set Abstraction Layer

名前が長くて複雑に見えますが、実はResNetのSkip Connectionと似ています。
上の図を見てみましょう。 赤い点線ボックスで表示したSet Abstraction Layerに入力される点の数がN1個です。 そして各点は(d + C1)次元のFeatureを持っています。 これをSkip Linkを使って、右の赤い点線ボックスで表示された(d+C2)次元のFeatureに繋げます。 つまり、以下の式のようになるのです。
N₁ x (d + C₂) + N₁ x (d + C₁) = N₁ x (d + C₁ + C₂)
Pass Through Unit Pointnet
上の小見出しを翻訳すると、「Unit PointNetを経る」です。 さっきまでN₁ x (d + C₁ + C₂)を求めたでしょう? これをN₁ x (d + C₃) に変換する作業です。 簡単に言うと、各点のFeatureの次元数を(d+C₁+C₂)から(d+C₃)に減らす過程だと言えます。 Unit PointNetはFully Connected Layerで構成されており、Batch NormalizationとReLU活性化関数が適用されます。 詳しい構造については、論文の裏側にあるSupplementary Section B.1を参考にしましょう。
説明がついに終わりました。 元のPoint Cloudの数であるNがすべて復旧するまで、上記の3つのプロセスが繰り返されます。
実験の結果
MNIST Digit Classification

面白い実験です。 2DデータであるMNISTをPointNet++に分類しました。 MNISTで計512個のPoint Cloudを抽出して実験したそうです。 Error Rateを見ると、PointNet++が0.51で表では2位を記録しました。
ModelNet40 Shape Classification

ModelNet40という3D Meshデータセットで実験した内容です。 Meshデータの表面から計1024個のPoint Cloudを抽出し、PointNet++を学習しました。 性能が最もよく出たのは、PointNet++と法線ベクトルを活用したモデルです。
Robustness to Sampling Density Variation
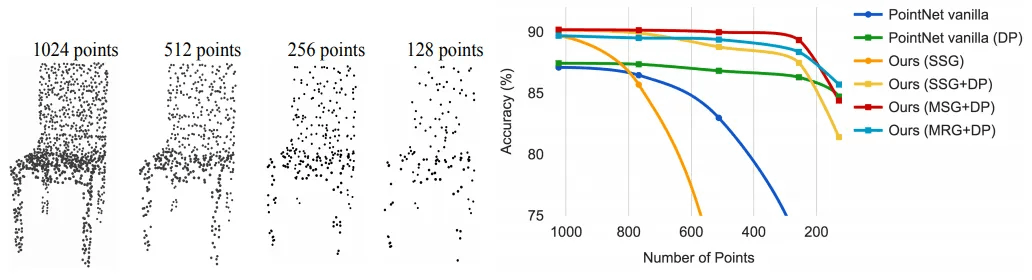
SSG(Single Scale Grouping)、MSG(Multi-Scale Grouping)、MRG(Multi-Resolution Grouping)、DP(Dropout)に対するAblation実験だと言えます。 上の図で左側の写真は任意で点を除去していく時の椅子の姿の変化です。 上の図で右のグラフは任意にPointを除去したときの性能に変化を示しています。 SSGだけを使った時は性能がよくありません。 しかし、DPで様々な密度のPoint Cloud部分集合で学習した時は、良い結果を示しています。 PointNet+DP、MSG+DP、MRG+DPは、点が1024個から128個に減った時も85%に近い性能を見せてくれます。 つまり、DPはいいです.
Point Set Segmentation for Semantic Scene Labeling

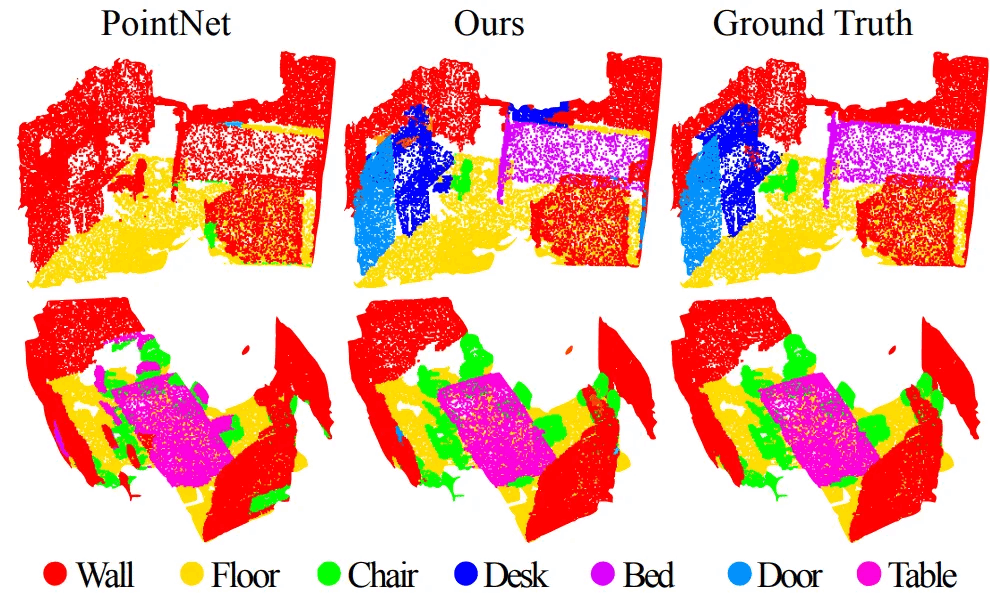
Semantic Segmentationの結果です。 青色の棒はScanNetデータを使った実験結果です。 そして黄色の棒は密度が均一でないScanNetデータセットを持って行った実験結果です。 実際にLiDARセンサーを使って3Dスキャンをすると、Point Cloudデータの密度が不均一になります。 だから、このような実験は本当に良い実験だと思います。 PointNet++(MSG+DP)を使用する場合、最も良い性能が得られます。 下の図はPointNet、PointNet++の推論結果とGround TruthをVisualizationした図です。
コード
Farthest point sampling (FPS) algorithm
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, 3]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(npoint):
centroids[:, i] = farthest
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
dist = torch.sum((xyz - centroid) ** 2, -1)
mask = dist < distance
distance[mask] = dist[mask]
farthest = torch.max(distance, -1)[1]
return centroids
Sample layer/Grounping layer/Pointnet
class PointNetSetAbstraction(nn.Module):
def __init__(self, npoint, radius, nsample, in_channel, mlp, group_all):
super(PointNetSetAbstraction, self).__init__()
self.npoint = npoint
self.radius = radius
self.nsample = nsample
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv2d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm2d(out_channel))
last_channel = out_channel
self.group_all = group_all
def forward(self, xyz, points):
"""
Input:
xyz: input points position data, [B, C, N]
points: input points data, [B, D, N]
Return:
new_xyz: sampled points position data, [B, C, S]
new_points_concat: sample points feature data, [B, D', S]
"""
xyz = xyz.permute(0, 2, 1)
if points is not None:
points = points.permute(0, 2, 1)
if self.group_all:
new_xyz, new_points = sample_and_group_all(xyz, points)
else:
new_xyz, new_points = sample_and_group(self.npoint, self.radius, self.nsample, xyz, points)
# new_xyz: sampled points position data, [B, npoint, C]
# new_points: sampled points data, [B, npoint, nsample, C+D]
new_points = new_points.permute(0, 3, 2, 1) # [B, C+D, nsample,npoint]
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
new_points = torch.max(new_points, 2)[0]
new_xyz = new_xyz.permute(0, 2, 1)
return new_xyz, new_points
Segmentation Network
class get_model(nn.Module):
def __init__(self, num_classes, normal_channel=False):
super(get_model, self).__init__()
if normal_channel:
additional_channel = 3
else:
additional_channel = 0
self.normal_channel = normal_channel
self.sa1 = PointNetSetAbstractionMsg(512, [0.1, 0.2, 0.4], [32, 64, 128], 3+additional_channel, [[32, 32, 64], [64, 64, 128], [64, 96, 128]])
self.sa2 = PointNetSetAbstractionMsg(128, [0.4,0.8], [64, 128], 128+128+64, [[128, 128, 256], [128, 196, 256]])
self.sa3 = PointNetSetAbstraction(npoint=None, radius=None, nsample=None, in_channel=512 + 3, mlp=[256, 512, 1024], group_all=True)
self.fp3 = PointNetFeaturePropagation(in_channel=1536, mlp=[256, 256])
self.fp2 = PointNetFeaturePropagation(in_channel=576, mlp=[256, 128])
self.fp1 = PointNetFeaturePropagation(in_channel=150+additional_channel, mlp=[128, 128])
self.conv1 = nn.Conv1d(128, 128, 1)
self.bn1 = nn.BatchNorm1d(128)
self.drop1 = nn.Dropout(0.5)
self.conv2 = nn.Conv1d(128, num_classes, 1)
def forward(self, xyz, cls_label):
# Set Abstraction layers
B,C,N = xyz.shape
if self.normal_channel:
l0_points = xyz
l0_xyz = xyz[:,:3,:]
else:
l0_points = xyz
l0_xyz = xyz
l1_xyz, l1_points = self.sa1(l0_xyz, l0_points)
l2_xyz, l2_points = self.sa2(l1_xyz, l1_points)
l3_xyz, l3_points = self.sa3(l2_xyz, l2_points)
# Feature Propagation layers
l2_points = self.fp3(l2_xyz, l3_xyz, l2_points, l3_points)
l1_points = self.fp2(l1_xyz, l2_xyz, l1_points, l2_points)
cls_label_one_hot = cls_label.view(B,16,1).repeat(1,1,N)
l0_points = self.fp1(l0_xyz, l1_xyz, torch.cat([cls_label_one_hot,l0_xyz,l0_points],1), l1_points)
# FC layers
feat = F.relu(self.bn1(self.conv1(l0_points)))
x = self.drop1(feat)
x = self.conv2(x)
x = F.log_softmax(x, dim=1)
x = x.permute(0, 2, 1)
return x, l3_points
その中のFeaturePropagationの定義は
class PointNetFeaturePropagation(nn.Module):
def __init__(self, in_channel, mlp):
super(PointNetFeaturePropagation, self).__init__()
self.mlp_convs = nn.ModuleList()
self.mlp_bns = nn.ModuleList()
last_channel = in_channel
for out_channel in mlp:
self.mlp_convs.append(nn.Conv1d(last_channel, out_channel, 1))
self.mlp_bns.append(nn.BatchNorm1d(out_channel))
last_channel = out_channel
def forward(self, xyz1, xyz2, points1, points2):
"""
Input:
xyz1: input points position data, [B, C, N]
xyz2: sampled input points position data, [B, C, S]
points1: input points data, [B, D, N]
points2: input points data, [B, D, S]
Return:
new_points: upsampled points data, [B, D', N]
"""
xyz1 = xyz1.permute(0, 2, 1)
xyz2 = xyz2.permute(0, 2, 1)
points2 = points2.permute(0, 2, 1)
B, N, C = xyz1.shape
_, S, _ = xyz2.shape
if S == 1:
interpolated_points = points2.repeat(1, N, 1)
else:
dists = square_distance(xyz1, xyz2)
dists, idx = dists.sort(dim=-1)
dists, idx = dists[:, :, :3], idx[:, :, :3] # [B, N, 3]
dist_recip = 1.0 / (dists + 1e-8)
norm = torch.sum(dist_recip, dim=2, keepdim=True)
weight = dist_recip / norm
interpolated_points = torch.sum(index_points(points2, idx) * weight.view(B, N, 3, 1), dim=2)
if points1 is not None:
points1 = points1.permute(0, 2, 1)
new_points = torch.cat([points1, interpolated_points], dim=-1)
else:
new_points = interpolated_points
new_points = new_points.permute(0, 2, 1)
for i, conv in enumerate(self.mlp_convs):
bn = self.mlp_bns[i]
new_points = F.relu(bn(conv(new_points)))
return new_points
結論及び感想
結論
- PointNet++は、Point Cloudデータを処理できる強力なNeural Networkです。
- 様々な3DベンチマークデータセットでState-of-the-artの性能を見せました。
- 将来的には、スピードを上げる方向で研究を進めるだろうと著者は述べています。
感想
- 論文を読むのがとても難しかったです。 簡単に説明していただければいいのですが、すべての言葉を本当に難しく説明しました。
- Ablation実験をする時、もう少し多様な実験結果を見せたらよかったと思います。 これを聞いて、Section 6.3でMSGとMRGだけを学習して見せた実験結果があればよかったと思います。
- やはりスピードがカギでしょう。
出典
- PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space, Charles R. Qi et al., 2017–06–07
- Furthest Point Sampling, Mini-batch AI, 2021–08–07

Discussion