Apollo Client を基礎から理解する(キャッシュの仕組み編)
現在のプロジェクトで Apollo Client を触り始めて約半年。いまだに「Apollo Client完全理解した!」 と言えるレベルに至っていないのですが、Apollo Client の最難関「キャッシュ」をはじめとした基本的な使い方についてまとめてみました!
間違っている内容やさらに良い方法等あれば、コメント欄にて(優しく)ご指摘いただけるととても嬉しいです。
- Apollo Client を基礎から理解する(キャッシュの仕組み編) 👈
- Apollo Client を基礎から理解する(QueryとMutationのhooksの使い方編)
- Apollo Client を基礎から理解する(ローカルでの状態管理方法編)
Apollo Clientとは
Apollo Clientは、GraphQLを使用してローカルデータとリモートデータの両方を管理することができる、JavaScript用の包括的な状態管理ライブラリです。そのため、キャッシュを利用しながらデータを取得・更新はもちろんのこと、ReduxやRecoillのようなローカルでの状態管理も Apollo Client 一つで出来てしまいます。
Apollo Client を扱う上で、一番肝となるのが 「キャッシュの仕組み」 をしっかり理解することです。丁寧に説明していきたいと思うので、一緒に理解していきましょう!!
キャッシュがある場合は、即座にデータを取得できる
Apollo Client は余計なネットワーク通信を減らすために、便利なキャッシュ機構を備えています。
GraphQLで取得したデータは「正規化」され、インメモリのキャッシュに保存します。これにより、同じリクエストに対しては、サーバーに取り行くことなく、メモリ上にキャッシュしたデータを返すことで即座に応答することができます。
キャッシュされたデータが存在しない場合

キャッシュされたデータが存在する場合
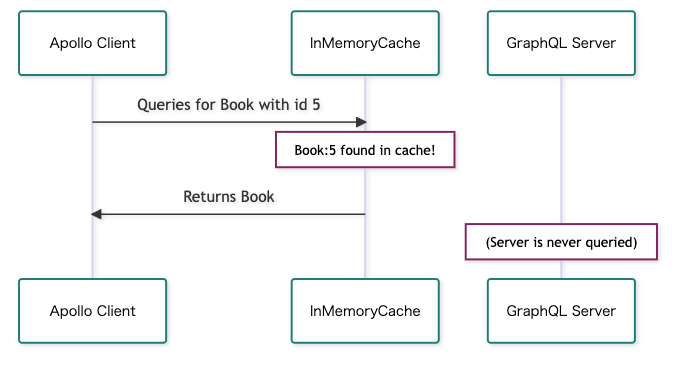
ただデータによっては、キャッシュを利用したいものとそうでないものがあるかと思います。
その場合は、FetchPolicies の設定によってキャッシュの利用有無を決めることができます。
FetchPoliciesの設定方法
-
cache-first(デフォルトの設定)
キャッシュがある場合はキャッシュを返す。 -
cache-and-network
キャッシュを返した後、サーバーからデータを取得し、キャッシュを更新する。更新されたデータを返す。 -
network-only
必ずサーバーからデータを取得し、キャッシュを更新する。更新されたデータを返す。 -
no-cache
必ずサーバーから取得したデータを返す。キャッシュは更新しない。 -
cache-only
キャッシュからしかデータを取得しない。
詳しくは、公式ブログが分かりやすいのでそちらをご確認ください。
データの正規化の仕組み
Apollo Clientでは、「正規化」というものをすることで即座にデータにアクセスする仕組みを持っています。データの正規化は、以下の手順で行われます。
- 個々のオブジェクトに分割する
- 分割したオブジェクトに一意の識別子を割り当てる
- フラット化されたデータ構造でオブジェクトを保存する
- 実行したクエリ(またはミューテーション)、引数、結果を保存する
本記事では、「商品一覧を取得する」というクエリを用いながら一つずつ説明していきます。
1.個々のオブジェクトに分割する
まずはじめに、サーバーから取得した商品一覧の配列データを個々のオブジェクトに分割します。
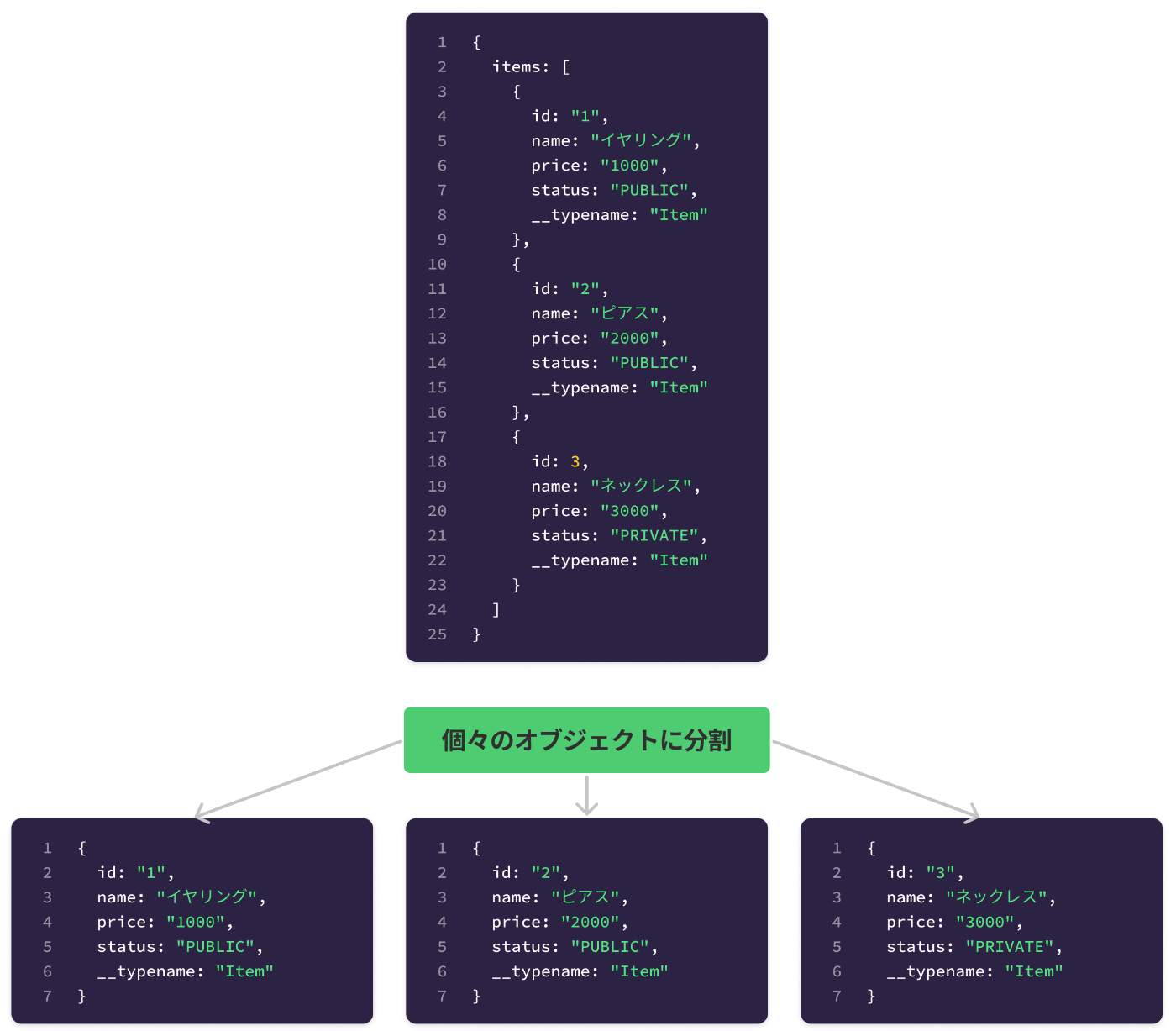
2. 分割したオブジェクトに一意の識別子を割り当てる
分割した各オブジェクトに、一意の識別子(キャッシュID)を割り当てます。
デフォルトでは、識別子はオブジェクトが持つ__typenameとidまたは_idをコロン(:)で繋げて作成します。
例:Item:1
id以外を用いて識別子を作ることも可能です。(こちらで説明してます)

3. フラット化されたデータ構造でオブジェクトを保存する
正規化された各オブジェクトをフラットな構造に格納することで、一意の識別子を介してデータにアクセスできるようになります。探しているオブジェクトの識別子さえわかっていれば、非常に高速に検索することが可能となります。
{
"Item:1": {
id: 1,
name: 'イヤリング',
price: 1000,
status: "PUBLIC",
__typename: "Item"
},
"Item:2": {
id: 2,
name: 'ピアス',
price: 2000,
status: "PUBLIC",
__typename: "Item"
},
"Item:3": {
id: 3,
name: 'ネックレス',
price: 3000,
status: "PRIVATE",
__typename: "Item"
}
}
ただこれだけでは、商品一覧の並びを維持させることができません。
実行したクエリや引数、その結果も全てキャッシュに保存する必要があります。
4. 実行したクエリや引数、結果を保存する
実行したクエリとその結果はROOT_QUERYにのオブジェクトに保存されます。
ミューテーションの場合は、ROOT_MUTATIONに保存されます。
itemsという商品一覧クエリには、実データを格納しているのではなく、正規化した識別子を格納しています。識別子を使ってデータを参照することができるので、キャッシュのサイズを可能な限り小さくすることができます。
{
"ROOT_QUERY": {
__typename: "Query",
items: [
{ "__ref": "Item:1" },
{ "__ref": "Item:2" },
{ "__ref": "Item:3" }
]
},
"Item:1": {
__typename: "Item",
id: 1,
name: 'イヤリング',
price: 1000,
status: "PUBLIC",
},
"Item:2": {
__typename: "Item",
id: 2,
name: 'ピアス',
price: 2000,
status: "PUBLIC",
},
"Item:3": {
__typename: "Item",
id: 3,
name: 'ネックレス',
price: 3000,
status: "PRIVATE",
}
}
引数がある場合は以下のように保存されます。
例)最新順で商品一覧を取得する
"ROOT_QUERY": {
__typename: "Query",
items({"orderBy":{"createdAt":"desc"}): [
{ "__ref": "Item:3" },
{ "__ref": "Item:2" },
{ "__ref": "Item:1" }
],
}
// 〜省略〜
}
id以外のフィールドを識別子にする
デフォルトでは、識別子はオブジェクトが持つ__typename とidまたは_idで生成されますが、typePoliciesで別のフィールドを使用することもできます。
cache の typePolicies で変更可能です。
const cache = new InMemoryCache({
typePolicies: {
Product: {
// upc を識別子として使用する場合
keyFields: ["upc"],
},
Person: {
// name と email の複合を識別子として使用する場合
keyFields: ["name", "email"],
},
Book: {
// title と author オブジェクトの name の複合を識別子として使用する場合
keyFields: ["title", "author", ["name"]],
},
AllProducts: {
// キャッシュに含まれる AllProducts オブジェクトが1つだけで、そのオブジェクトに識別フィールドがない場合は、 keyFields に空の配列を指定できます。
keyFields: [],
},
},
});
参考:Apollo Client Docs - customizing-cache-ids
キャッシュされたデータの確認方法
キャッシュされたデータを確認するために、基本的にはchrome の拡張機能「Apollo Client Devtools」を使って確認できます。
しかし、度々chromeの拡張機能が表示されない時があります。。。
(バグとしてissueにもあがっていました)
もし表示されない時は、やや見づらいですが Chrome DevTools Console で__APOLLO_CLIENT__.cache.data.dataを叩いて確認することもできます。
__APOLLO_CLIENT__.cache.data.data
{
// 〜省略〜
items: [
{ "__ref": "Item:1" },
{ "__ref": "Item:2" },
{ "__ref": "Item:3" }
]
}
まとめ
以上、キャッシュの仕組みについてまとめてみました。
この記事が何かお役立ていただけましたら幸いです。
Discussion