こんにちは!株式会社フクロウラボの若杉と申します。
最近は、もっぱらRAGの精度向上に試行錯誤しています。Difyには、RAGの機能が最初から備わっていますが、通常のRAGだけでは、良い回答が得られないことも多いです。そこでGraphRAGに注目するようになったのですが、最速でDify上でGraphRAGを使用できるようにする実装方法を調べてみました!
はじめに
GraphRAGとは…
GraphRAGは、文章内の重要な情報(ノード)とその関連性(エッジ)をグラフ構造として捉えることで、単なるキーワード検索を超えた文脈理解を可能にする手法です。具体的には、情報間の「つながり」を明確にすることで、質問に対してより正確な回答が生成されます。詳しい解説は、前回の記事に書きましたので、下記を参考にしてもらえればと思います。
GraphRAGの主な特徴:
- ナレッジグラフの利用:文書から抽出した情報をノードとエッジで構造化
- 高度な検索能力:単語の類似度だけでなく、文脈上の関連性も考慮
- 複雑な関係性の理解:エンティティ間の直接的および間接的な関係を考慮した推論が可能
ちなみに、Microsoft Researchが2024年2月に発表した下記の記事が、GraphRAGの概念の原点のようです。
Difyとは…
Difyは、プログラミングの知識がなくてもLLM(大規模言語モデル)を用いたワークフローを簡単に設計・自動化できるツールです。文章生成、画像解析、データ処理など多様な機能が初期状態で利用でき、ドラッグ&ドロップによる直感的な操作で、複雑なタスクも視覚的に構築できます

文章生成や画像解析、データ処理の機能をつなげていくことで、複雑なタスクを自動で実行できる仕組みを構築できます。処理の流れを視覚的に設計できるため、比較的カジュアルにAIアプリケーションを作成できるのが特徴です。
詳細は、下記を公式ドキュメントを参考にしてください。
DifyとGraphRAGを組み合わせるメリット
今回、Dify上で、GraphRAGしたエージェントやワークフローを気軽に構築できるような環境を作ってみようと考えたのですが、主に下記の理由からです。
- DifyのRAGエンジンとGraphRAGのナレッジグラフ技術をハイブリッド統合することで、より精度の高い回答生成ができるか検証したい。
- Difyでは並行処理もカジュアルに実装できるので、様々なプロトタイプを作成し検証したい。
Difyの直感的なインターフェースを通じて、GraphRAGの高度な機能を容易に実装できるメリットはいろいろありそうということで、Dify上でGraphRAGを扱える環境の構築をしてみました。
実装の全体像
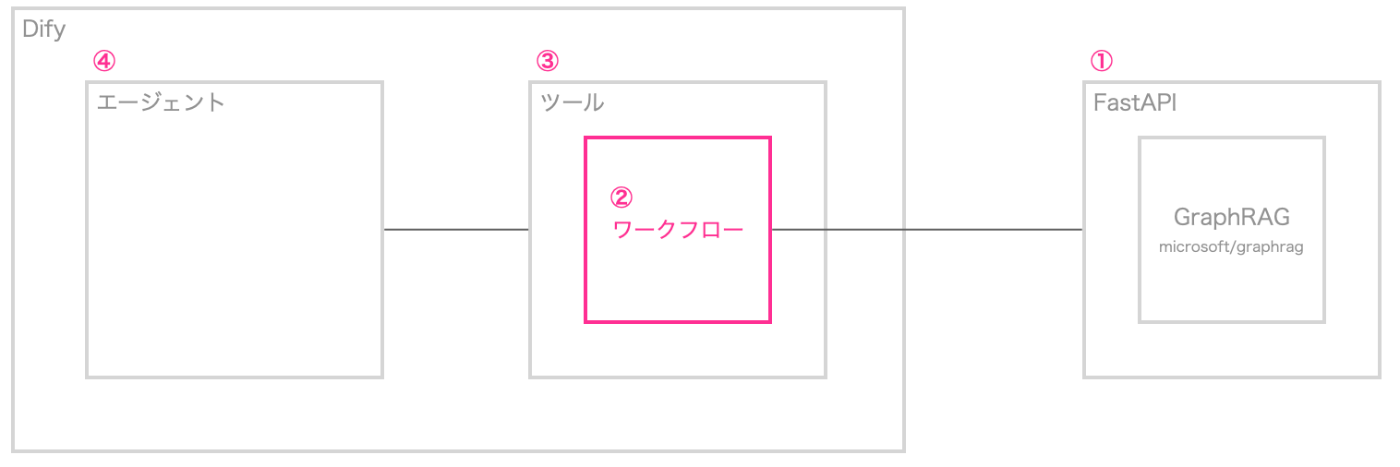
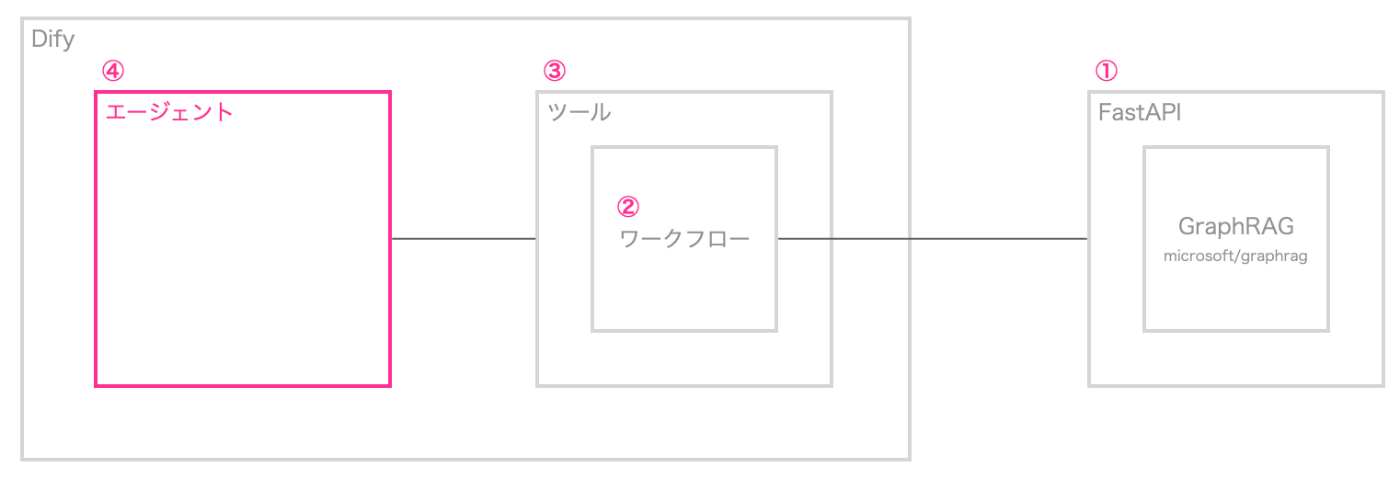
今回のDifyにGraphRAGを取り込む全体像としては下記です。組み合わせたAIチャットボット構築の全体像は以下のようになります。

図1
図1の例では、最終的にエージェントがツールとして、GraphRAGを利用するケースを想定しています。
①:前回の記事では、Langchain+Neo4jでGraphRAGを実装していましたが、今回はマイクロソフトが公開しているGraphRAGのリポジトリを利用します。
リクエストとして、クエリをGraphRAGへ投げ、GraphRAGでの検索結果をレスポンスとして返すAPIをFastAPIで実装します。
ちょっと調べてみると、Dify向けのFastAPIを使ったGraphRAGのAPIの実装を公開してくれているリポジトリを見つけたので、一旦、下記のリポジトリのコードを使ってみることにしました。
②:ここからはDifyの実装になりますが、①のAPIに対してHTTPリクエストするだけのワークフローを作成します。
③:②のワークフローをツール化します。ツール化することで、エージェントやワークフローで(共通化された)ツールとして利用することができるようになります。
④:例えば、エージェントが利用できるツールに追加することで、GraphRAGへクエリを投げ、その結果を参照してエージェントが回答を生成できるようになります。
構築手順
ここからは、具体的な構築手順を記載してい光と思います。ローカル(Mac上)で環境を構築することを想定しています。ベースにmicrosoft/graphragを使うので、基本的には、下記のページを参考に進めます。
図1:①の部分

microsoft/graphragをgit cloneする
git clone git@github.com:microsoft/graphrag.git
microsoft/graphragを展開するための適当なディレクトリ作成します。今回は、デフォルトのまま(graphrag)とします。
v0.9.0を利用する
brightwang/graphrag-difyによると、"v0.9.0バージョンをサポートしている"ということなので、v0.9.0へチェックアウトします。
cd graphrag
git checkout v0.9.0
pyproject.tomlへの追記
さらに、brightwang/graphrag-difyによると、"下記のライブラリを追記して"ということなので、pyproject.tomlの[tool.poetry.dependencies]のところに、下記を追加します。
fastapi = "^0.115.0"
uvicorn = "^0.31.0"
asyncio = "^3.4.3"
utils = "^1.0.2"
上記、追記後に
poetry install
を実行して仮想環境へライブラリをインストールします。
brightwang/graphrag-difyのファイルをコピー
一旦、ここで、brightwang/graphrag-difyを適当なディレクトリにダウンロードします。
cd ../
git clone git@github.com:brightwang/graphrag-dify.git
main.pyを先程のgrpahragプロジェクト直下にコピーします。
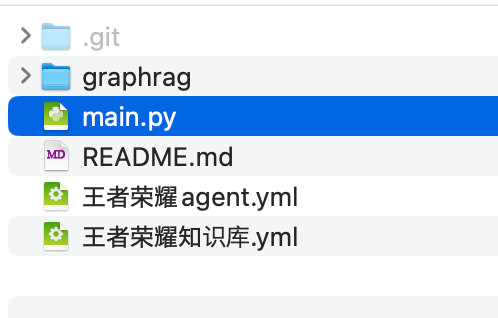
microsoft/graphrag側は、下記のようになります。
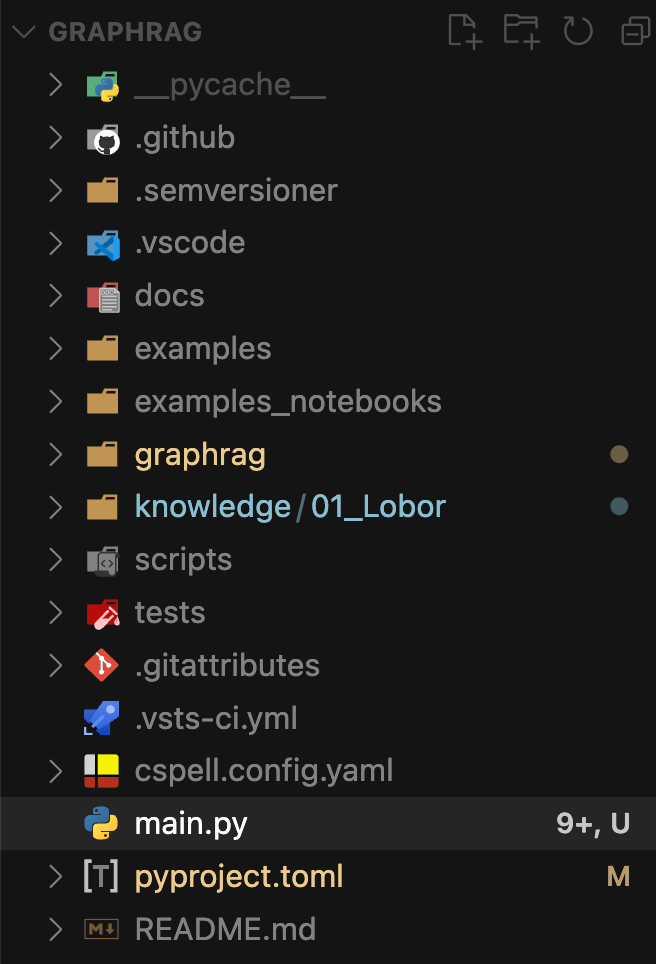
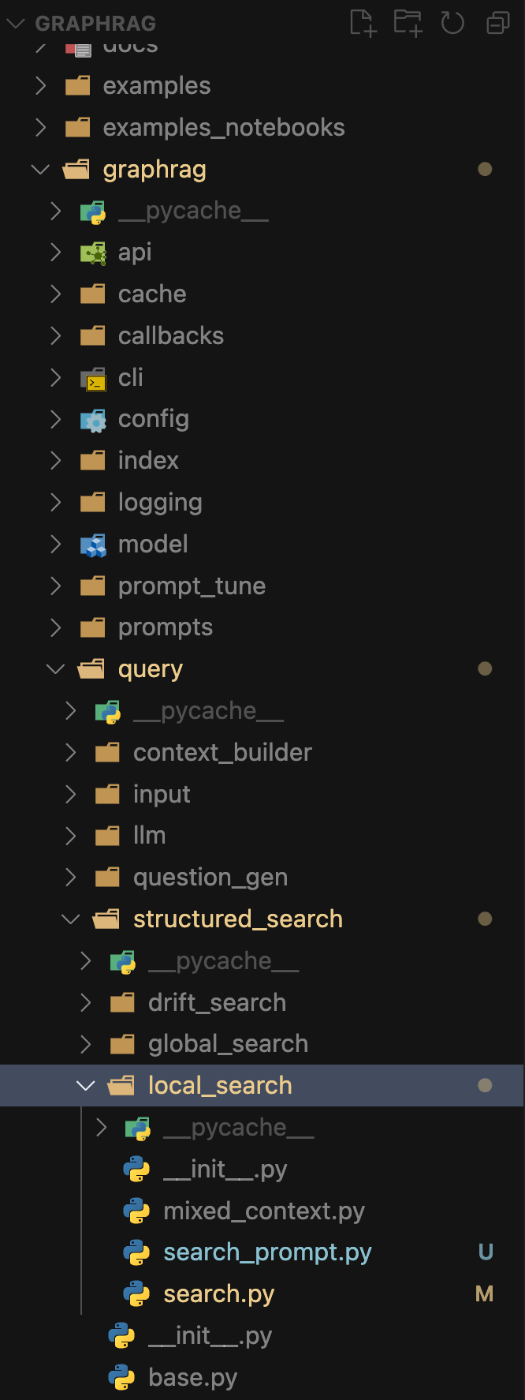
graphragディレクトリ配下にあるsearch.pyとsearch_prompt.pyのファイルをgraphragリポジトリ内のディレクトリの場所に応じてファイルをコピー上書きします。
graphrag > query > structured_search > local_search

こちらもmicrosoft/graphrag側は、下記のようになります。
ナレッジファイルの設置
ここでは、ナレッジファイル設置します。基本、ディレクトリ名は何でも良いのですが、下記のように作成します。

今回は、社内の労務関連のFAQやドキュメントをナレッジとしてGraphRAG化してみたいと思いますので、下記のディレクトリ構成にしたいと思います。
knowledge/
└── 01_Lobor/
└── input/
上記のようにディレクトリを作成し、inputディレクトリ直下に、ナレッジファイル群を置きます。上記ので、一つのファイルしか置いていないですが、複数のファイルを設定して置いて問題ないです。
下記の3つの拡張子のファイルが対応しているようです。
- .txt
- .csv
- .json
詳細は、こちらを参考にしてください。
ただ今回は、.txtファイルのプレーンテキストファイルのみを設置します。
main.pyの変更
knowledge > 01_Loborというディレクトリ構成で、knowledgeディレクトリ配下に、各カテゴリのナレッジを追加していく構成を考えています。そのためには、main.pyの71行目のroot_dirの指定の部分だけ、変更したいと思います。
# 変更前
root_dir = f"./indexs/{search_query.active_docs}"
# 変更後
root_dir = f"./{search_query.active_docs}"
初期化
下記のコマンドで初期化します。
poetry run poe init --root ./knowledge/01_Lobor
すると、
knowledge > 01_Lobor直下に
.envファイルとsettings.ymlファイルが、生成されます。
.envファイルには、OpenAIのAPIキーを記載します。
settings.ymlファイルはそのままでも良いのですが、下記のモデルだけ、"gpt-4o-mini"に変えて置こうと思います。

インデックスの作成
下記のコマンドを実行してインデックスを作成します。
poetry run poe index --root ./knowledge/01_Lobor
このコマンドを実行するとインデックス用のパイプラインが走り、GraphRAGに必要なデータを作成していきます。
最終的には、下記のようにディレクトリとデータが作成されます。
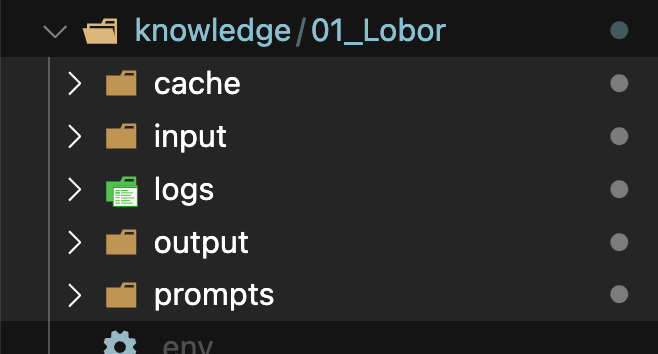
テストとしてGraphRAGへのクエリを実行
ここで、例えば下記のようにコマンドを実行して、クエリに対して、きちんと回答が返ってくるかを確認しておきます。
poetry run poe query --config ./knowledge/01_Lobor/settings.yaml --root ./knowledge/01_Lobor --method local --query "確定申告を行いたいのですが、去年の源泉徴収票のどのように取得できますか?"
最終的に"SUCCESS: Local Search Response:"とその後に回答が返ってきていることが確認できれば問題ないです。
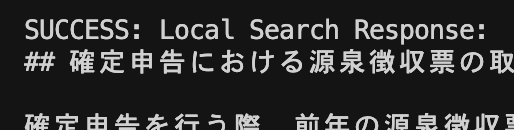
アプリケーションサーバーを起動
前のテストが問題なければ、main.pyをuvicornで起動し、アプリケーションサーバーを立ち上げます。例えば、8000ポートで起動させる場合は、下記のようになります。
poetry run uvicorn main:app --reload --host 0.0.0.0 --port 8000
これで、HTTPリクエスト経由で、GraphRAGに対してクエリを実行できるAPIサービスができました。
テストとして、エンドポイントに対してリクエストを投げてみる。
念のため、APIエンドポイントへリクエストを送信して、レスポンスが返ってくるか確認します。
curl -X POST "http://localhost:8000/v1/search" -H "Content-Type: application/json" -d '{"active_docs": "knowledge/01_Lobor", "query": "確定申告を行いたいのですが、去年の源泉徴収票のどのように取得できますか?"}'
ngrokでURLの発行
Difyもローカルのlocalhostで稼働させていると後々うまくいかなくなるので、ngrokを使って、パブリックなURLを発行しておきます。
ngrok http 8000
※ngrokについての説明はここでは省きます。詳細は、下記にて確認してください。
ここでは、ローカル環境のエンドポイントを一時的にパブリックなURLでアクセスできるようにしてくれるものと認識してもらえれば、一旦、問題ないです。
そうすると、例えば、先程のcurlコマンドでリクエスト先がlocalhostではなく、下記のようなURLでリクエストを通すことができます。
curl -X POST "https://00a3-159-28-182-163.ngrok-free.app/v1/search" -H "Content-Type: application/json" -d '{"active_docs": "knowledge/01_Lobor", "query": "確定申告を行いたいのですが、去年の源泉徴収票のどのように取得できますか?"}'
※00a3-159-28-182-163.ngrok-free.appはすでに使用できません。
ここまでがGraphRAGをマイクロサービス化するところまでの手順です。
図1:②の部分
ここからはDifyの操作になります。
一応、ローカルの環境でDifyを立ち上げているという想定です。
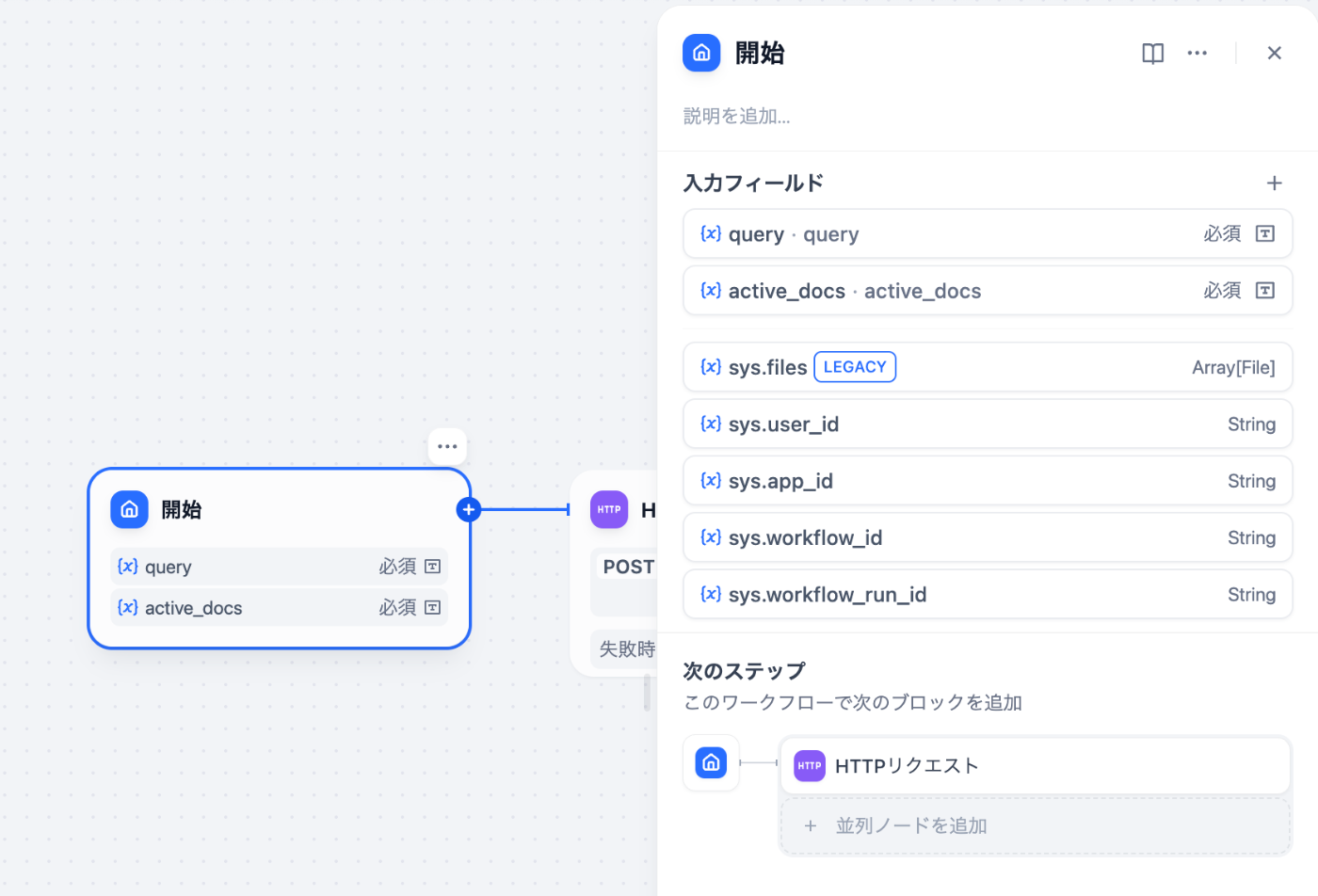
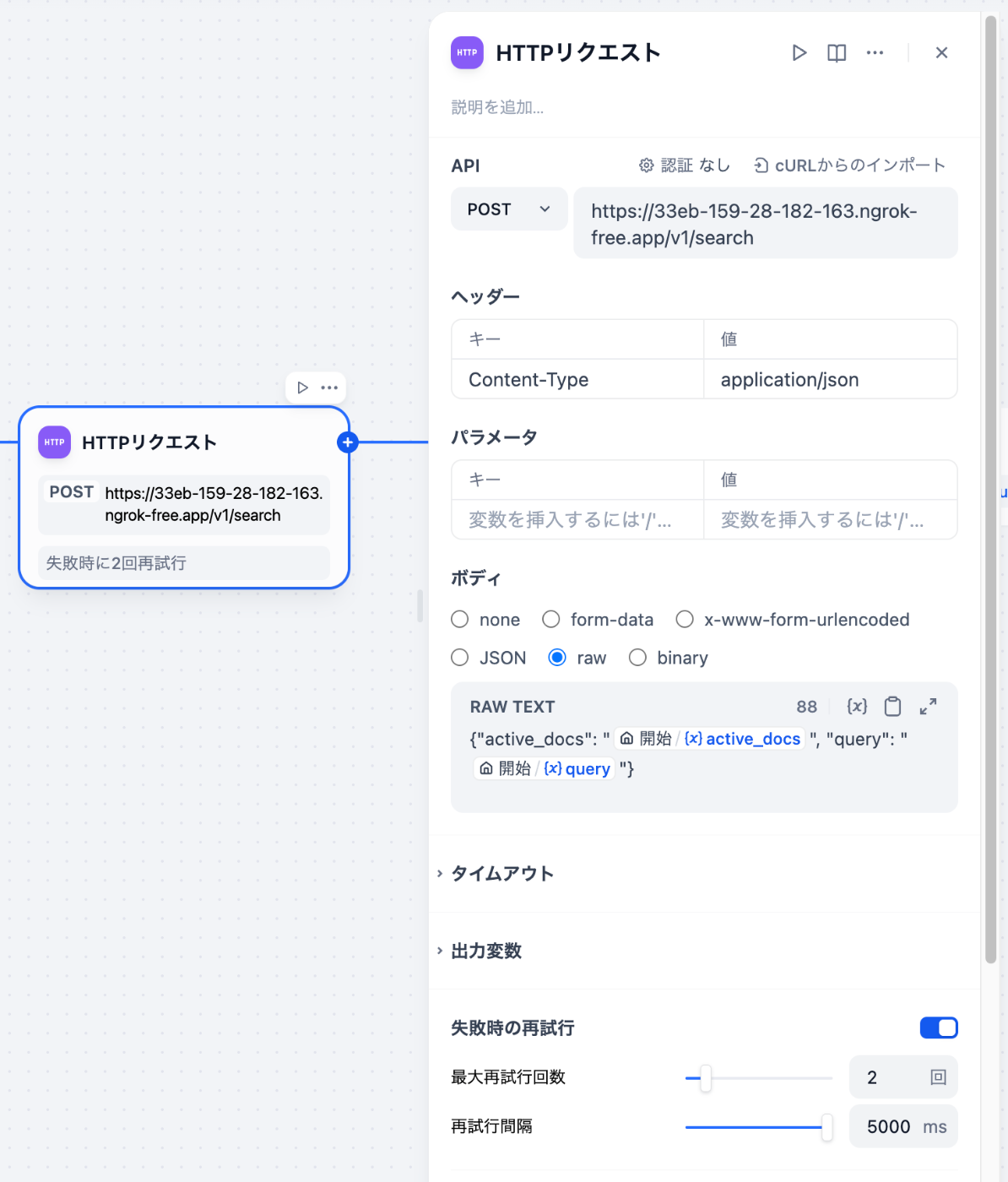
ワークフローを作成
ワークフローは、brightwang/graphrag-difyにサンプルのDSLがありますので、それを参考に作成すれば問題ないと思います。
おおよそ下記のようになります。



念のため、実行して、動作確認しておきましょう。


図1:③の部分

上記のワークフローをツール化します。
作成したワークフローをツール化する
右上の"公開する"ボタンから、一度、"Publish Update"を行い、"ツールとしてのワークフロー"をクリックします。
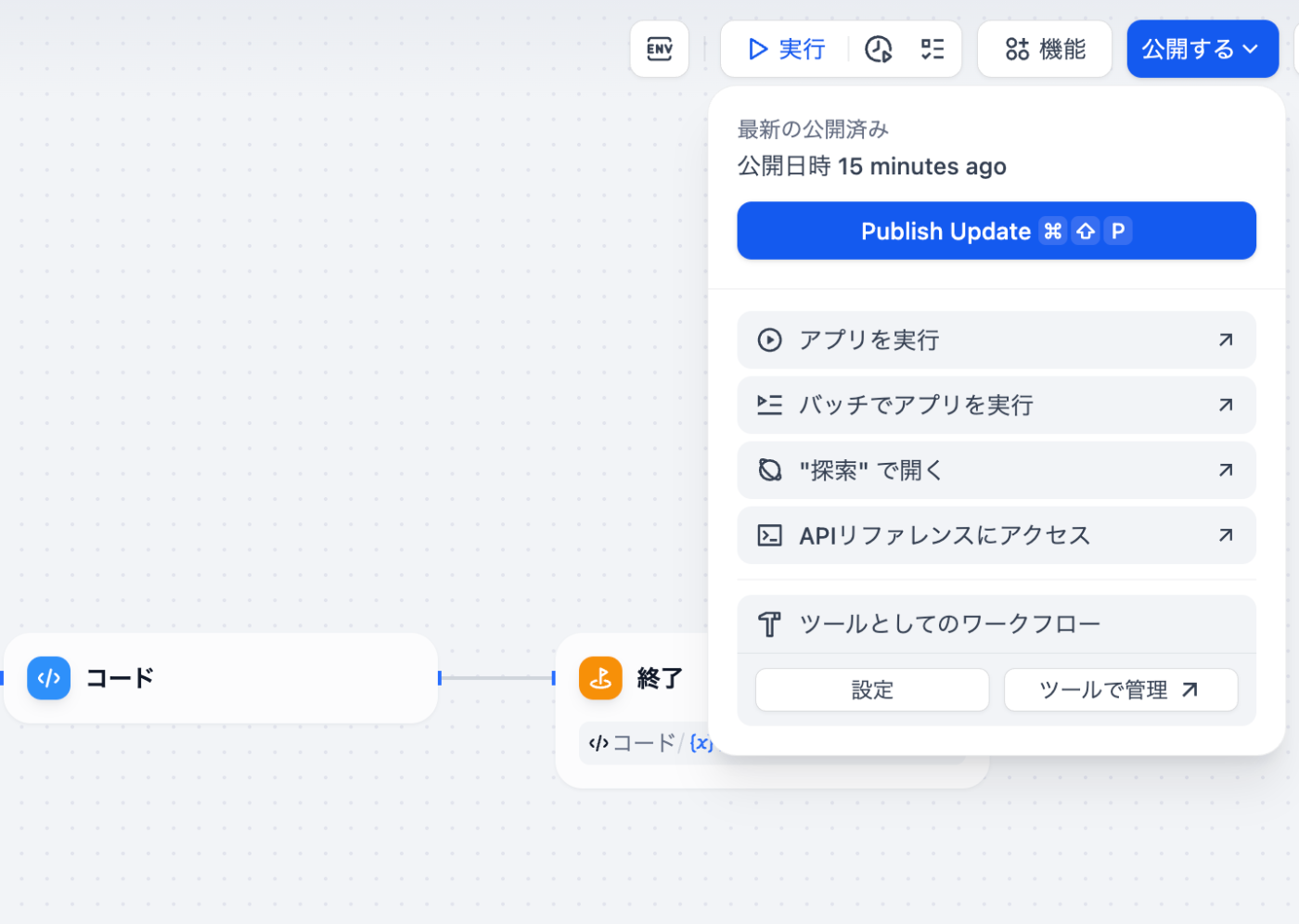
すると、下記のような入力フォームが表示されるので、適宜入力します。

保存し、次のエージェントで正しく利用できるか確認しましょう。
図1:④の部分
最後に、エージェントを作成します。
エージェントを作成
エージェントは、下記のように作成します。
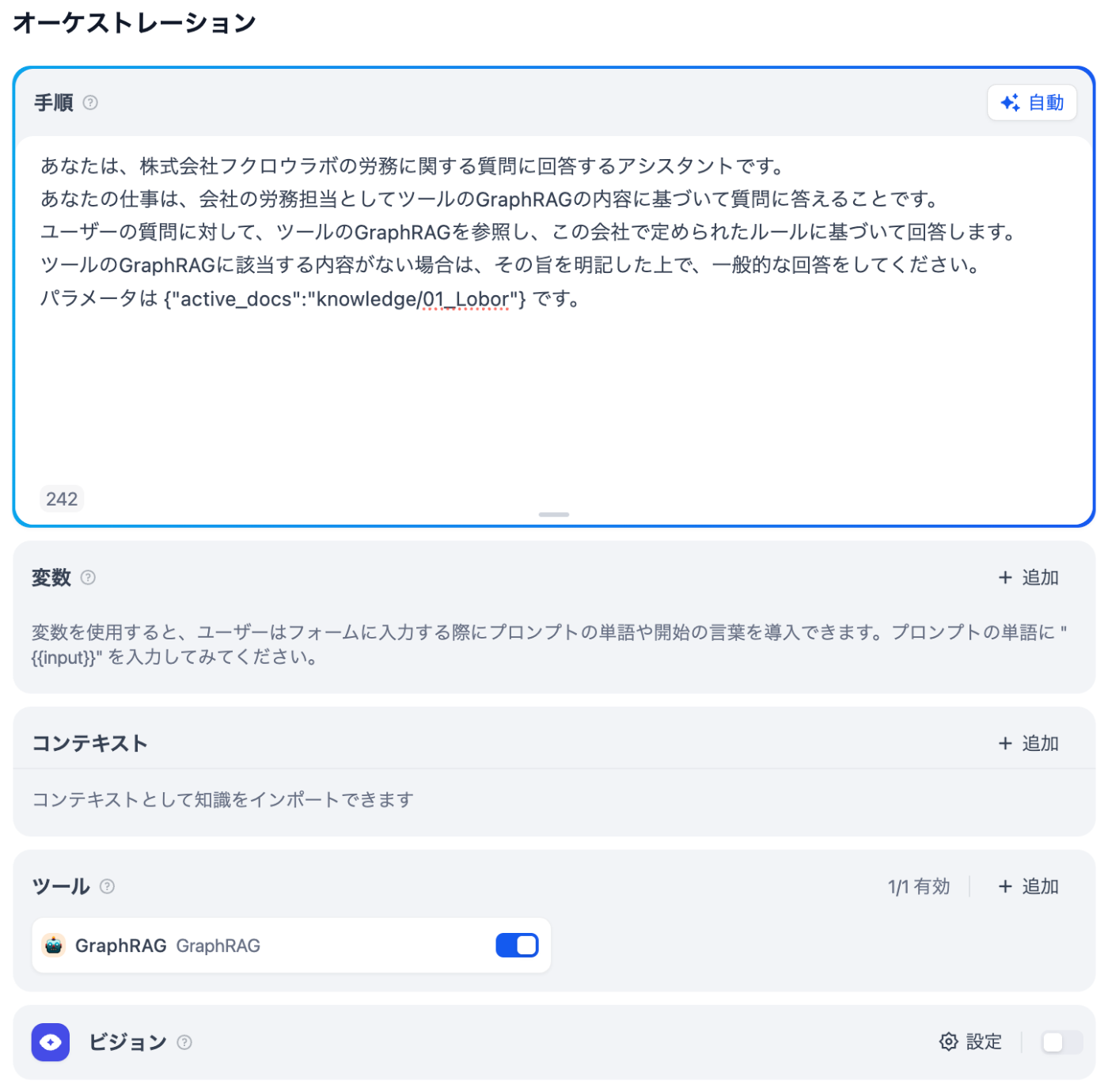
ツールにて、"+追加"ボタンをクリックし、"ワークフロー"タブを選択肢、先程作成したツールを選択します。

"パラメータは {"active_docs":"knowledge/01_Lobor"} です。"というプロンプトによって、ツールに対する必須パラメータ"active_docs"を"knowledge/01_Lobor"という固定値でリクエストするように狙っています。労務以外のエージェントを作成する場合は、ここを変えることで他のカテゴリのナレッジもGraphRAGを使用できるようになっています。※その場合は、GraphRAG側で予めナレッジのインデックスを作成しておく必要があります。
デバックとプレビューで、動作確認をして問題なければ、完了です。

上記のエージェントに与えるプロンプトは、簡易的な内容です。ユーザーに対してどのように回答してほしいかをもっと厳密に定義して作り込んだ方が良いと思います。今回は、DifyからGraphRAGを使用するというところにフォーカスしているので、プロンプトについても詳細は省きます。
プロンプトについては、下記などを参考に適宜作成してください。
まとめ
通常のRAGでもチューニングできるポイントはそこそこあるのですが、そこでがんばるよりも、GraphRAGをラフに導入した方が回答精度は劇的に向上すると感じています。ただ、計算コストや大規模データセット対応、運用管理の手間などのデメリットを考慮すると、RAGをすべてのGraphRAGに置き換えれば良いというわけには行きません。まだ利用できるケースは限定されるかもしれませんが、利用できるケースにおいては積極的に利用していきたいところです。
実装の振り返り
今回は、Microsoft ResearchのGraphRAGをDifyに統合することで、ナレッジグラフを活用した高度な回答生成の気軽に構築できる仕組み目指してみました。ただ、その種明かしとしては、microsoft/graphragをFastAPIを利用してAPI化して、それをDifyから利用するというものなので、GraphRAGをDifyに統合というのはちょっと大袈裟な表現かもしれません。しかも、brightwang/graphrag-difyのコードをほぼ利用させていただいているので、microsoft/graphragのv0.9.0までにしか対応できていないというのもあります。今回、実装してみておおよそ理解できたので、microsoft/graphragのDify向けのAPI化のコードは自前で作成してみようとも思っています。
主な利用用途としては…
今回のDify × GraphRAGの利用用途としては、個人的には検証用として色々試していきたいと考えています。Difyでは、ワークフローで並行処理をカジュアルに実装できるので、同じクエリを通常のRAGとGraphRAGへ送って、レスポンス内容の精度や回答時間、消費トークン数など簡単に比較できるので、便利かなと思っています。GraphRAGでも、Config設定やindexing、プロンプトのチューニングなどでも精度は変わると思うので、同じナレッジで複数のインデックスデータを生成して比較するなど検証用で非常に役立ってくれそうなイメージがあります。
2025年は、AIエージェントの進化が一層加速すると予測されていますが、個人的には、自社データなど独自のコンテキストをどのようにAIに提供するかが、精度向上の鍵だと考えています。今後も、さまざまなRAG手法やエージェントアルゴリズムの検証を進め、試行錯誤しながらAIと向き合ってきたいと思っておりますので、引き続きよろしくお願いいたします。
【執筆者について】
株式会社フクロウラボ
取締役CTO 若杉 竜一郎
長年にわたりSSPやASPの開発などのアドテク系のエンジニアリングに従事。 フリーランス時代にはcakesやnoteの立ち上げ期に業務委託として開発。フクロウラボに1人目のエンジニアとして参画。CTOとして技術全般を見ています。最近はAWSや生成AI関連を得意としています。

Discussion