こんにちわ!フクロウラボの若杉です。
最近はRAG(Retrieval-Augmented Generation)アプリケーションを考えることが普段の仕事において割合が増えてきています。
RAGアプリケーションを構築する上で、精度の高いセマンティック検索の基盤をどのように作るかが重要なポイントです。そこで以前から気になっていた知識グラフベースのRAGアプローチについて調べたので、GraphRAGについて書いていきます。
GraphRAGとは…
GraphRAG(Graph Retrieval-Augmented Generation)は、情報検索(Retrieval)と生成(Generation)を統合した高度な手法です。特にグラフ構造を活用して情報の関連性を強化する点に特徴があります。RAG自体は、ユーザーのクエリに対して関連情報を検索し、その情報を元に自然言語生成を行うモデルですが、GraphRAGは、さらにナレッジのグラフ情報を組み合わせることで、より高度な情報処理と精度の高い回答生成を目指すものです。

引用:https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/
なぜ注目されているのか
単純なベクトル検索では、関連性の高い情報を正確に見つけ出すのが難しい場合があります。また、LLMでの文章の文脈の理解に限界があり、質問者が望む回答とはずれだ回答、もしくは無関係な情報を生成してしまうことがあります。
これらの課題に対してGraphRAGは、主に以下のアプローチを強化することで、回答精度を上げることができます。
関連性の高い情報の検索:
グラフ構造を利用することで、データ間の関係性を明確にし、クエリに対してより関連性の高い情報を効率的に検索できます。グラフはノード(情報の単位)とエッジ(情報間の関係)から構成されており、複雑なクエリでも関連する情報を見つけやすくなります。
文脈を理解した情報生成:
検索フェーズで得られたグラフ構造に基づき、生成フェーズでの出力がより文脈に沿ったものになります。これにより、単純なテキスト生成モデルよりも意味の通った、連続性のある情報を生成できます。
データの多様な利用:
グラフ構造は異なるタイプのデータを一つのフレームワークで統合できるため、異種データを扱う場合にも有効です。例えば、ニュース記事と科学論文、ソーシャルメディアの投稿などを同時に扱い、それぞれのデータ間の関係性を活用できます。
今までのRAGとの比較
今までのRAGと比較してどのような違いがあるのか、ざっくり表にまとめると下記の様になると思います。
| 項目 | RAG(キーワード検索/ベクトル検索) | GraphRAG |
|---|---|---|
| データ構造 | テキストデータベース、文書群 | グラフデータベース |
| 情報の検索 | テキスト検索エンジンを使用 | グラフクエリを使用 |
| データの関係性 | 主にキーワードの一致に基づく | ノード間のリンクやエッジに基づく |
| 生成結果の精度 | 検索結果に依存 | ノード間の関係性を考慮し高精度 |
| クエリの柔軟性 | 一般的なテキストクエリ | 構造化クエリ、複雑な関係の把握が可能 |
| 適用範囲 | テキストベースのタスク全般 | 関係性が重要なタスク、例えば知識グラフ |
GraphRAGの前提知識
GraphRAGについて説明するにあたり、前提知識として説明しておいた方が良い内容について説明します。
グラフ理論の基本概念
そもそもグラフについて簡単におさらいしたいと思います。
グラフ理論は、データ間の関係性を表現するための数学的枠組みであり、ノード(頂点)とエッジ(辺)から構成されます。グラフはさまざまな分野で使用されており、特にデータ間の複雑な関係を視覚化し、解析するのに有効です。
グラフの要素
-
ノード(Node):
- グラフの各点を表し、データの個々の単位を意味します。例えば、ソーシャルネットワークでは各ユーザーがノードとして表されます。
-
エッジ(Edge):
- ノード間の関係性を示す線であり、データ間のリンクや関連性を表します。ソーシャルネットワークでは、ユーザー間の友達関係やフォロー関係がエッジとして表現されます。

- ノード間の関係性を示す線であり、データ間のリンクや関連性を表します。ソーシャルネットワークでは、ユーザー間の友達関係やフォロー関係がエッジとして表現されます。
グラフの種類
-
有向グラフ(Directed Graph):
- エッジに方向性があるグラフです。例えば、X(ツイッター)のフォロワー関係は有向グラフで表現されます。

- エッジに方向性があるグラフです。例えば、X(ツイッター)のフォロワー関係は有向グラフで表現されます。
-
無向グラフ(Undirected Graph):
- エッジに方向性がないグラフです。例えば、Facebookの友達関係は無向グラフで表現されます。

- エッジに方向性がないグラフです。例えば、Facebookの友達関係は無向グラフで表現されます。
GraphRAGにおけるグラフ理論の役割
GraphRAGでは、情報検索フェーズで得られたデータをグラフ構造で表現し、その関係性を利用して生成フェーズを強化します。これにより、ノード間の関係性を考慮した、より精度の高いテキスト生成が可能になります。例えば、特定のトピックに関する関連文献をグラフとして構築し、その構造を元に回答を生成することで、深い文脈理解と高い関連性を持つ情報提供が実現します。
グラフデータベースについて
上記のグラフの情報を格納するために、グラフデータベースを使用します。
グラフデータベースは、データ間の関係性を重視して設計されたデータベースシステムです。
※クラグデータベースについては、割と奥が深いので、別記事で改めて説明しようと考えています。
基本構造
グラフデータベースは主に3つの要素のデータを格納していきます。
- ノード(Node):データの実体を表す。例えば、人物や商品など。
- エッジ(Edge):ノード間の関係を表す。例えば、友人関係や購買関係など。
-
プロパティ(Property):ノードとエッジに付随する属性情報。例えば、ノードが表す人物の生年月日(
birthdate: '1990-01-01')やエッジが表す関係が始まった日付(startDate: '2022-01-01')など。
※そのグラフデータをどの様に活用したいかによって、プロパティにどのような情報を格納するが重要なポイントになりそうです。
クエリ言語
リレーショナルデータベースではSQLという標準化された言語によって操作が可能でしたが、グラフデータベースにおいては、SQLとは別のクエリ言語が使用されます。また、そのクエリ言語は複数あり、使用するグラフデータベース毎で対応状況が異なっています。
グラフデータベースのクエリ言語について、主要なものをいくつか説明します。
1. Cypher:
- Neo4jが開発した宣言型クエリ言語
- SQLに似た構文を持ち、直感的で学習しやすい
- パターンマッチングを使ってグラフ構造を視覚的に表現できる
- 例:
MATCH (p:Person)-[:KNOWS]->(f:Person) WHERE p.name = "John" RETURN f.name
2. Gremlin:
- Apache TinkerPopプロジェクトの一部として開発されたグラフ走査言語
- 関数型言語で、トラバーサルステップを連鎖させてクエリを構築する
- 多くのグラフデータベースでサポートされている
- 例:
g.V().has('name','John').out('knows').values('name')
3. SPARQL:
- RDF(Resource Description Framework)データ向けの標準クエリ言語
- W3Cによって標準化されている
- セマンティックWebやリンクトデータで広く使用されている
- 例:
SELECT ?name WHERE { ?person foaf:name "John" . ?person foaf:knows ?friend . ?friend foaf:name ?name }
これらのクエリ言語は、それぞれ特徴や強みが異なります。Cypherは直感的で学習しやすく、Gremlinは柔軟性が高く多くのシステムでサポートされています。SPARQLはセマンティックWebの標準として広く使われています。グラフデータベースを選択する際には、サポートされているクエリ言語も重要な検討事項の1つとなります。
グラフデータベースの種類
上記のクエリ言語と同様にグラフデータベースもいくつか存在します。以下、代表的なグラフデータベースであるNeo4j AuraDB、Amazon Neptune、JanusGraphの特徴をそれぞれまとめたものです。
-
Neo4j AuraDB
- タイプ: ネイティブグラフデータベース
- クエリ言語: Cypher
- 特徴: Neo4jは市場リーダーであり、豊富な機能と使いやすさが特徴です。オンプレミスおよびクラウドでのデプロイが可能で、垂直および水平スケーリングに対応しています。主にソーシャルネットワークや推薦エンジンに利用されます。
-
Amazon Neptune
- タイプ: フルマネージドグラフデータベース
- クエリ言語: openCypher, SPARQL, Gremlin
- 特徴: Amazon NeptuneはAWSによってフルマネージドされており、高可用性と自動スケーリングが特徴です。AWSクラウド上でデプロイされ、自動水平スケーリングに対応しています。クラウドネイティブアプリケーションやIoTに適しています。
-
JanusGraph (The Linux Foundation)
- タイプ: オープンソースグラフデータベース
- クエリ言語: Gremlin
- 特徴: JanusGraphは分散処理が可能で、柔軟なバックエンド選択が特徴です。オンプレミスおよびクラウドでのデプロイが可能で、水平スケーリングに対応しています。大規模分散グラフ処理に適しています。The Linux Foundationの傘下にあることで、中立性と継続性が担保されている点も特徴と言えます。
| データベース | タイプ | クエリ言語 | 特徴 | デプロイメント | スケーラビリティ |
|---|---|---|---|---|---|
| Neo4j AuraDB | ネイティブグラフDB | Cypher | 市場リーダー、豊富な機能、使いやすい | オンプレミス / クラウド | 垂直 / 水平 |
| Amazon Neptune | フルマネージドグラフDB | openCypher / SPARQL / Gremlin | AWSサービス統合、高可用性、自動スケーリング | AWSクラウド | 自動水平スケーリング |
| JanusGraph (The Linux Foundation) | オープンソースグラフDB | Gremlin | 分散処理、柔軟なバックエンド選択 | オンプレミス / クラウド | 水平スケーリング |
GraphRAGはベクトル検索と組み合わせで利用する
GraphRAGの情報のみを参照して回答を生成するのではなく、基本的には、既存のベクトル検索での検索結果にGraphRAGの情報も追加し、それらを両方を参照して回答を生成するアプローチが一般的だと思います。
GraphRAGは知識グラフを用いて構造化されたデータ間の関係性を捉えます。一方でベクトル検索は非構造化テキストデータの意味的類似性を扱います。この両方のデータタイプを効果的に活用できるため、組み合わせで利用することが多いです。

引用:https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/
※ただし、意味的類似性よりも明確に定義された関係性に基づく検索の方が適切な場合などでは、GraphRAGの構造化データのみ利用するケースもあります。
実装例
ここからは実際の実装について解説していきたいと思います。
参考文献の紹介
基本的には、下記のLangChainのブログ記事を参考にしています。 コードも下記で公開されており、Google Colab上でほぼそのまま稼働させても問題なく動作検証することはできると思います。
構成
上記のLangChainのブログ記事に記載されていますが、ざっくり構成について説明します。
主に、LangChainのGraphsを利用し、グラフデータベースはNeo4jのAuraDBを使用しデータを保存します。
LangChainのGraphs
LangChainのGraphsは、グラフデータベースやグラフ構造を活用して言語モデルの能力を拡張するためのモジュールです。
GraphRAGを構築するためのもので、知識グラフの構築や活用、グラフベースのQ&Aシステムの開発に使用され、構造化されたデータの管理と検索ができます。
また、Neo4j、Amazon Neptune、TigerGraph、MemGraphなど、様々なグラフデータベースと連携できます。と同時に、(先程、クエリ言語について触れましたが)Cypher、SPARQL、Gremlinなど、複数のグラフクエリ言語のサポートもしています。
※注意:"LangChainのGraphs"について検索していると、"LangGraph"というのもが出てきますが、"LangGraph"は、"LangChainのGraphs"とは別物です。"LangGraph"は、複雑なAIエージェントを作成するためのフレームワークですので、混同しないように注意してください。
Neo4j AuraDB
Neo4j AuraDBは、Neo4jが提供する完全マネージド型のクラウドグラフデータベースサービスです。AuraDBは、グラフデータベースの管理の複雑さを軽減し、開発者がアプリケーションの構築に集中できるようにすることを目的としています。各プランは異なるニーズと規模に対応し、ユーザーは自身のプロジェクトに最適なオプションを選択できます。
-
主な特徴:
- ゼロ管理: 自動アップグレード、パッチ適用、メンテナンスを提供
- 高可用性: 自己修復機能を備えた信頼性の高いインフラストラクチャ
- スケーラビリティ: 需要に応じて簡単にスケールアップ/ダウン可能
- セキュリティ: データ保護と法令遵守のための高度なセキュリティ制御
- 開発者ツール: 組み込みの開発者ツール、データ可視化、統合機能を提供
-
提供プラン:
- AuraDB Free: 小規模な開発プロジェクト、学習、実験、プロトタイピング向け
- AuraDB Professional: 高度な開発環境、中規模アプリケーションの本番環境向け
- AuraDB Enterprise: 高度なセキュリティと24時間365日のサポートを必要とする大規模アプリケーション向け
コードの説明
グラフデータの生成
import os
from langchain_community.graphs import Neo4jGraph
from langchain.document_loaders import TextLoader
from langchain.text_splitter import TokenTextSplitter
from langchain_openai import ChatOpenAI
from langchain_experimental.graph_transformers import LLMGraphTransformer
from neo4j import GraphDatabase
from yfiles_jupyter_graphs import GraphWidget
一旦、グラフデータの生成とNeo4j AuraDBへ保存するために必要なモジュールです。
os.environ["OPENAI_API_KEY"] = ''
os.environ["NEO4J_USERNAME"] = ''
os.environ["NEO4J_URI"] = ''
os.environ["NEO4J_PASSWORD"] = ''
OpenAIのAPIキーとNeo4jの情報を入力します。
raw_documents = TextLoader('./knowledge.txt').load()
text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)
documents = text_splitter.split_documents(raw_documents)
今回は予めナレッジとして使用するテキストデータ(knowledge.txt)を用意してTextLoaderで読み込ませています。また、TokenTextSplitter は、テキストをトークン単位で分割するためのクラスです。
chunk_size=512: 各チャンクの最大トークン数を512に設定しています。
chunk_overlap=24: 各チャンク間で24トークンの重複を持たせるように設定しています。
これはテキストをベクトル化する際の設定ですが、この後のconvert_to_graph_documentsメソッドは、ドキュメントからグラフデータを生成するだけでなく、ベクトル化も行うため、ここで設定しておきます。
llm = ChatOpenAI(temperature=0, model_name="gpt-4o-mini")
llm_transformer = LLMGraphTransformer(llm=llm)
graph = Neo4jGraph()
graph_documents = llm_transformer.convert_to_graph_documents(documents)
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)
LLMGraphTransformerクラスのconvert_to_graph_documentsメソッドは、入力されたドキュメントを解析し、グラフのノードとエッジを生成します。convert_to_graph_documentsメソッドがドキュメントをグラフデータに変換し、その際にベクトル化も行っているようで、データベースにはグラフデータだけでなく、ベクトル検索ようのチャンクデータ(テキストデータとベクトルデータ)の両方が含まれているようです。
※この具体的な処理や格納形式については、詳細を調べて別記事で書きたいと思います。
ここの処理には時間がかかりますが、LLMGraphTransformerクラスは便利で、一応、これだけでグラフデータを作成することができます。
default_cypher = "MATCH (s)-[r:!MENTIONS]->(t) RETURN s,r,t LIMIT 1000"
def showGraph(cypher: str = default_cypher):
driver = GraphDatabase.driver(
uri = os.environ["NEO4J_URI"],
auth = (
os.environ["NEO4J_USERNAME"],
os.environ["NEO4J_PASSWORD"]
)
)
session = driver.session()
widget = GraphWidget(graph = session.run(cypher).graph())
widget.node_label_mapping = 'id'
return widget
showGraph()
Neo4j AuraDBに格納されているデータを確認します。
ここではyFilesというグラフやダイアグラムを視覚化、編集、分析するためのソフトウェアライブラリを使用しています。
Neo4jのコンソールでもクエリを実行し、グラフやテーブルを確認することができるので、いろいろ試したい場合は、Neo4jのコンソールを利用すると良いと思います。
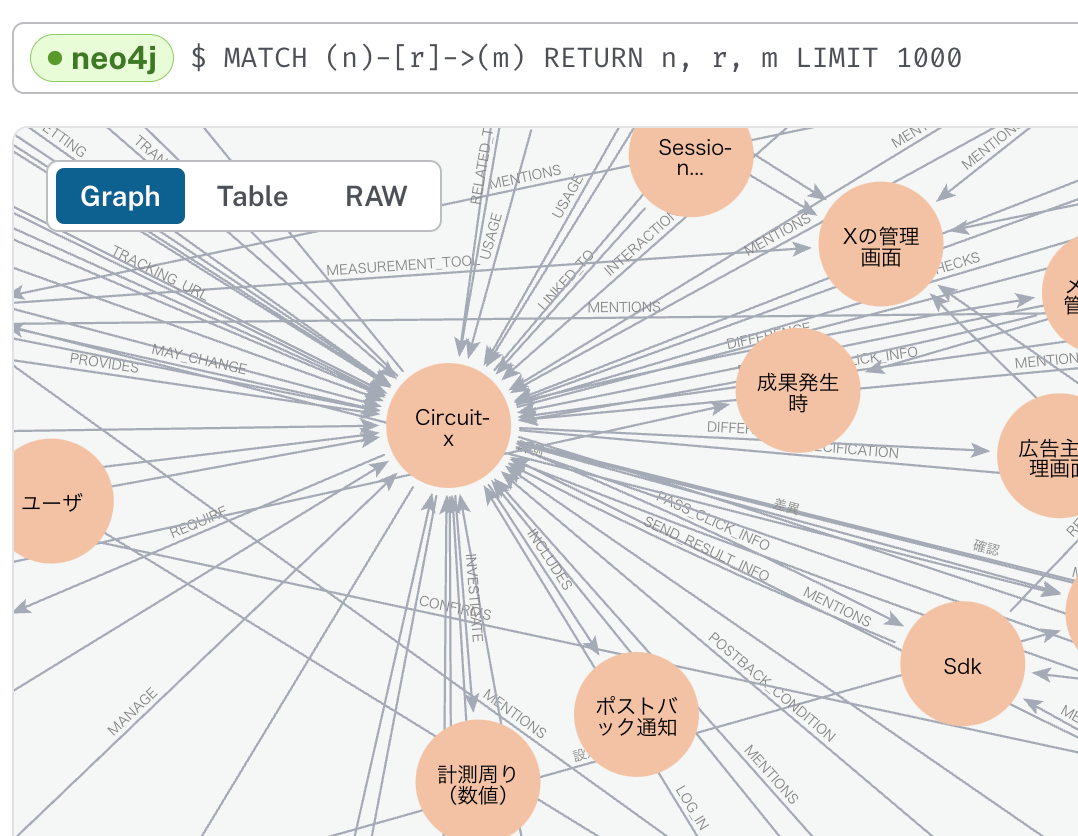
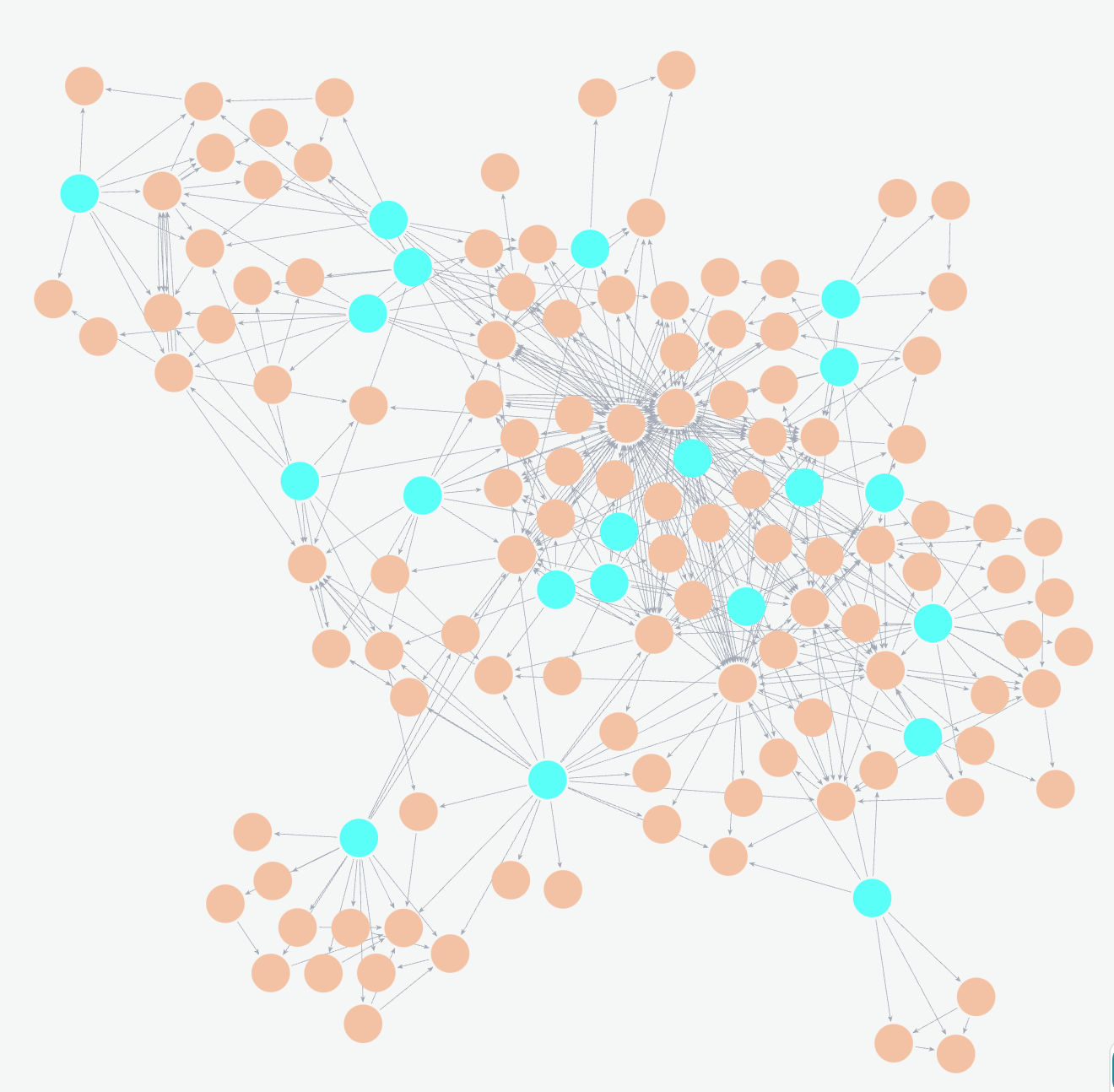
上記は、弊社の自社プロダクトCircuit Xのナレッジ読み込ませた際のグラフの一部になります。
グラフデータを参照して回答生成
import os
from typing import Tuple, List
from langchain_core.runnables import (
RunnableBranch,
RunnableLambda,
RunnableParallel,
RunnablePassthrough,
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.prompt import PromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_community.graphs import Neo4jGraph
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores import Neo4jVector
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores.neo4j_vector import remove_lucene_chars
上記が回答生成側で必要なモジュールです。
os.environ["OPENAI_API_KEY"] = ''
os.environ["NEO4J_USERNAME"] = ''
os.environ["NEO4J_URI"] = ''
os.environ["NEO4J_PASSWORD"] = ''
グラフデータ生成時と同様に、OpenAIのAPIキーとNeo4jの情報を入力しておいてください。
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question,
in its original language.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template)
def _format_chat_history(chat_history: List[Tuple[str, str]]) -> List:
buffer = []
for human, ai in chat_history:
buffer.append(HumanMessage(content=human))
buffer.append(AIMessage(content=ai))
return buffer
_search_query = RunnableBranch(
(
RunnableLambda(lambda x: bool(x.get("chat_history"))).with_config(
run_name = "HasChatHistoryCheck"
),
RunnablePassthrough.assign(
chat_history=lambda x: _format_chat_history(x["chat_history"])
)
| CONDENSE_QUESTION_PROMPT
| ChatOpenAI(temperature=0)
| StrOutputParser(),
),
RunnableLambda(lambda x : x["question"]),
)
上記はチャットでの会話を成り立たせるために、ユーザーのオリジナルの質問とは別に、会話履歴も加味して改めて独立した質問文を作成する処理です。後ほど、コンテキストとして使用します。
graph = Neo4jGraph()
graph.query(
"CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]"
)
class Entities(BaseModel):
names: List[str] = Field(
...,
description="All the person, organization, or business entities that "
"appear in the text",
)
def generate_full_text_query(input: str) -> str:
full_text_query = ""
words = [el for el in remove_lucene_chars(input).split() if el]
for word in words[:-1]:
full_text_query += f" {word} AND"
full_text_query += f" {words[-1]}"
return full_text_query.strip()
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting organization and person entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
llm = ChatOpenAI(temperature=0, model_name="gpt-4o-mini")
entity_chain = prompt | llm.with_structured_output(Entities)
def structured_retriever(question: str) -> str:
result = ""
entities = entity_chain.invoke({"question": question})
for entity in entities.names:
response = graph.query(
"""CALL db.index.fulltext.queryNodes('entity', $query, {limit:2})
YIELD node,score
CALL {
WITH node
MATCH (node)-[r:!MENTIONS]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION ALL
WITH node
MATCH (node)<-[r:!MENTIONS]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 50
""",
{"query": generate_full_text_query(entity)},
)
result += "\n".join([el['output'] for el in response])
return result
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
search_type="hybrid",
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding"
)
def retriever(question: str):
print(f"Search query: {question}")
structured_data = structured_retriever(question)
unstructured_data = [el.page_content for el in vector_index.similarity_search(question)]
final_data = f"""Structured data:
{structured_data}
Unstructured data:
{"#Document ". join(unstructured_data)}
"""
print(f"{final_data}")
return final_data
template = """Answer the question based only on the following context:
{context}
Question: {question}
Use natural language and be concise.
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
RunnableParallel(
{
"context": _search_query | retriever,
"question": RunnablePassthrough(),
}
)
| prompt
| llm
| StrOutputParser()
)
こちらのコードで、グラフデータ(構造化データ)とベクトルデータ(非構造化データ)を組み合わせて、質問に対する回答を生成するためのRetrieverを定義しています。
structured_retrieverメソッドでグラフデータ(構造化データ)を取得します。処理の流れとしては、質問文からノードとなりうるキーワードをLLMで抽出し、そのキーワード(ノード)から出発するリレーションシップとノードに向かうリレーションシップをすべて取得しています。
retrieverメソッドにて、structured_retrieverメソッドで取得したグラフ情報とユーザーの質問文とのベクトル検索から取得したテキストデータの両方をマージしてコンテキストとして利用できるようにしています。
これで準備は整いましたので、chain.invokeメソッドで質問をして動作を確認することができます。
出力例
chain.invoke({"question": "Circuit Xからポストバックする際、ポストバックサーバーのIPアドレス一覧を教えてください。"})
上記のように社内のナレッジをベクトルデータとグラフデータを構築しておくことで、社内からのお問い合せなどを円滑に対応できるようになると思います。
実際に動かしてみて感じた課題感
ナレッジ構築のコスト
基本的には非構造データのベクトル化とグラフデータ(構造データ)の構築を両方行うケースが多いため、従来のRAGよりもコストは高くなります。また、構築する際のコストだけでなく、検索時の参照コストも増加します。
データの一貫性維持の難しさ
知識グラフの構造が不正確であると、検索結果の精度に大きな影響を与えます。まず、よくあるのが、ノードの表記揺れの問題。同じノードに対して異なった表現が存在していまうと正しいグラフ構造を構築できません。統一の表現になるように置換をすれば良いのですが、ノードの数が多くなってくると一筋縄ではいかなく、それなりの対応を考えなければなりません。
また、新たなデータを追加する際に、既存のデータと矛盾するようなグラフデータのケースも考えられます。その場合、矛盾検出や矛盾解決の戦略を考え、グラフの一貫性を保つように、適切に追加、更新、削除することが求められます。プロパティに時系列情報を付与して一貫性を保つようにするアプローチも可能ですが、設計段階で予め加味しておく必要があることと、先のコストも問題も絡んできます。
まとめ
やはり、従来のRAGに比べて圧倒的に高精度で効率的な情報検索を提供できます。特に抽象的な質問や曖昧なクエリに対しても、GraphRAGにカバーできる様になるのは重要です。あらゆる質問に対しての確実にエンゲージメントがあがると感じています。個人的には、GraphRAGにおいて最適化をする余地が多分にあり、またその対策を行うことでのさらに精度を上げられそうで、GraphRAGにはまだまだ可能性を感じます。
今後もしばらくGraphRAGに関連する記事を発信して行こうと思いますので、引き続きよろしくお願いします!

Discussion