Stable Diffusionからの概念消去⑪:AdvUnlearn(論文)
Defensive Unlearning with Adversarial Training for Robust Concept Erasure in Diffusion Models (NeurIPS2024)
NeurIPS2024の採択論文が見れるようになっています. 今回はここから概念消去の論文をひとつ見ます.
書籍情報
Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, and Sijia Liu. Defensive unlearning with adversarial training for robust concept erasure in diffusion models, 2024.
関連リンク
断りのない限り図表は上記論文からの引用です.
導入
これまで見てきたように, 拡散モデルから概念を消去する手法は数多くあります (これが11番目の記事で, トップカンファレンスに通ってないので記事にしていない論文もあるので20はありそうです). 最近の論文を見てみると, 単純な消去の手法はある程度で尽くした感じがあり, 次の流れとしてロバストな消去にスポットが移っているように見えます. ロバストな消去とは, 概念消去を行なったモデルから消した概念が再び登場することがないように消去を行うことです. 最初の概念消去の論文であるESDではlimitationの例としてVan Gogh styleとstarry night paintingが挙げられています. これは, Van Gogh styleを消したはずなのにstarry night paintingと入力すると消したと思っていたVan Gogh styleが再び現れることです. この現象は解決することが難しく, 概念消去における重要課題のひとつです.
著者らは既存手法のロバストさの欠如に対して一つの問いを提起し, これを解決しようとしています. その問いとは,
Can we effectively and efficiently boost the robustness of unlearned DMs against adversarial prompt attacks?
(敵対的なプロンプト攻撃に対して、学習していないDMの頑健性を効果的かつ効率的に高めることができるか?)
というものです. この課題に取り組むためにAdversarial Trainingを組み込みます.
この論文での貢献は3つになります
- 拡散モデルの概念消去に敵対的学習の枠組みを導入したこと. 効果的なunlearningと高精度な画像生成のトレードオフを維持したこと
- text encoderを更新することでadversarial prompt attackに対してロバストになることを示したこと.
- 提案手法であるAdvUnlearnをさまざまなシナリオで検証したこと.
前提知識
前提知識をいくつか示します.
LDM
LDM (Latent Diffusion Models)はStable Diffusionのベースとなっている技術です.
を解くことによってモデルを得ます. ここで
ESD
概念消去の手法のひとつとしてESDがあります.
によって概念消去を行います.
Adversarial prompts
概念消去は完璧な手法ではないので, あるプロンプトを入力すると消したはずの概念が再び登場します. それを見つける研究がAdversarial prompt attacksです. これも最適化問題として定義可能で
で
AdvUnlearn
問題設定を行います. Adversarial promptsに対してロバストでないという問題は, Adversarial Trainingを組み込むことで解決できそうです. ここではbi-level optimizationによって定式化を行います.
第1式をUpper-level optimization, 第2式をLower-level optimizationと呼びます. この最適化問題においてUpper-level optimizationは消したい概念
で与えることができます. これらは例で, 実際には何でもいいです.
この論文では, この定式化を用いた手法であるAdvUnlearn (adversarial training into DM unlearning)を提案しています. しかし, effectively かつ efficientlyにこの最適化問題を解くには2つの課題があります.
Effectiveness challenge
後述しますが, naiveなESDの実装は通常の画像生成の有用性が下がります. したがって通常の画像生成の有用性と概念消去のロバストさのトレードオフを最適化する必要があります.
Efficiency challenge
拡散モデルはいくつかのモジュールから構成されています. そのため, 敵対的学習をどこにどのように適用するかが問題です. これも後述します.
それぞれ順番に確認, 検討します.
Effectiveness Enhancement
先ほども述べた通り, AdvUnlearnのフレームワークではただUpper-level optimizationとLower-level optimizationを統合するだけでは生成画像の品質が劣化します. 下の表はNudityを消したときのロバストさ (ASR) と生成品質 (FID)を比較したものです. 確かに数値上はESDを使うより敵対的学習を用いた方がロバストな消去が実現していますが, 生成品質が大きく落ち込んでいます.

実際にNudityを消去したモデルで"A picture of a dog laying on the ground"というプロンプトを用いて生成を行ってみます.

すると, ESDではプロンプト通りの画像が生成されているのに対し, 敵対的学習を行ったモデルでは"A picture"くらいしかプロンプトが反映されていません. これでは使い物にならないのは明らかです.
そこで, 生成品質を維持するためにペナルティ項を追加します. 具体的には
です. さて,
実際に, ASRとFIDを見てみます. この結果からもわかるように, FIDの悪化を大幅に抑えることに成功しています. 一方で, ASRが20%ほど悪くなっており, ここは更なる改善が必要です.

Efficiency Enhancement
先ほどの結果はFIDを維持することには成功していましたが, その代償としてロバストな消去能力が大きく失われました. これをどうにかしようというのがここでの話です.
著者らはロバストさをどこで担保しているのかを考えました. 例えばESDではUNetを更新しているのですが, text-to-imageを行うにあたっては他にもモジュールが存在します. 著者らはそれをtext encoderとしています. まず, text encoderには2つの利点があります.
- UNetと比較してパラメータ数が大幅に少ないので, 高速に目的が達成できる
- 他のtext-to-imageのモデルへのplug-inが容易である
この2点でもtext encoderを選ぶ余地がありそうですが, 著者らは先行研究の結果をそれらに加えてより説得力のある根拠としています. その先行研究はDiffQuickFixの研究例です. それについては以前扱っているのでここでは省略します.
実際にtext encoderに提案手法を適用した結果が下の表となります. text encoderが非常にロバストな消去を実現していることがわかります. ただESDで更新する対象をtext encoderにするとFIDが大幅に悪化しますので, 正則化項の重要性も示されています.
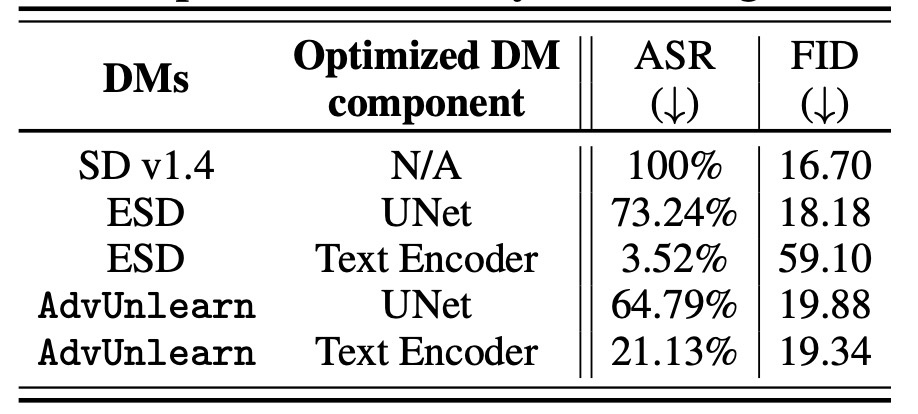
以降では提案手法 (AdvUnlearn)と述べた場合はtext encoderを正則化項ありでfine-tuneする手法を指すこととします.
その他の工夫
他のefficiency enhancementな手法として, fast attacks generation methodがあります. adversarial exampleを作るのですが, 一般に大変です. ここではfast gradient sign methodを用いて高速な計算を試みます. 10年くらい前の手法なので今更ですが,
で計算します. やっていることはよく見る以下の図と同じ感じです.

Explaining and Harnessing Adversarial Examplesより引用
これを行うことで高速に同じような結果を得ることができます.

実際に高速化が確認できますが, 著者らはこのASRの悪化はいいのでしょうか...
実験に移る前にアルゴリズム全体を確認します.

実験
実験設定を確認した後に結果を見ます.
実験設定
3つに概念消去のタスクを分類します.
- Nudity Unlearning: I2P datasetを用いてテストします.
- Style Unlearning: ESDと同様のテストをします.
- Object Unlearning: GPT-4でImagenetteの10クラスのpromptを50個ずつ作ってテストします.
ベースラインとしてESD, FMN, AC (Ablating Concpts), UCE, SalUn, SH, ED, SPMの8つのOSS手法を用います. SH (ScissorHands), ED (EraseDiff)は紹介したことがないですが, それぞれ以下の論文です.
AdvUnlearnについて, 先ほど示したアルゴリズム通りに実装します. 1000iterationの更新を行います. 各iterationではbatch sizeは1で, ESDのlossの
評価方法ですが, ロバストさにはUnlearnDiffAtkを用いたASR, utilityにはFIDとCLIP scoreを用います. FIDとCLIP scoreはMSCOCOを用いますが通常使われる30kの設定ではなく10kの設定を用います.
実験結果
結果を確認しますが, 定量評価では一部手法の結果が示されていません.
Nudity
まず, Nudityの結果を見ます. 例によって定性評価はここでは省略しますので論文p8のFigure 4などを参照してください.
除外した手法について著者らはFIDが非常に高くなってしまった (100を超えるようです)としています.
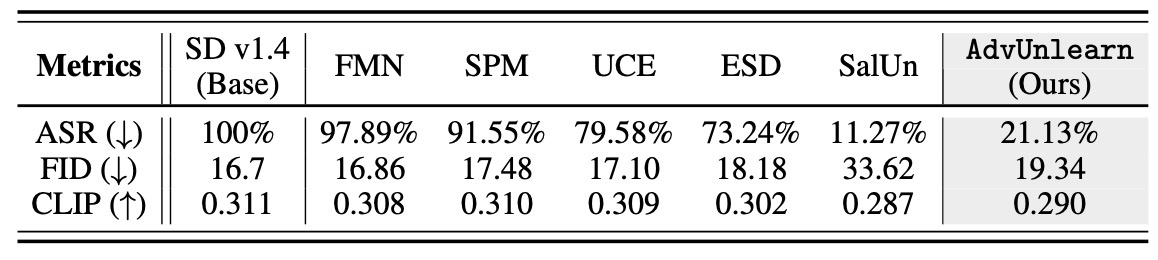
結果を見ると, SalUn以外には圧勝している結果となりました. SalUnには劣っていますが, FIDの悪化はかなり抑えられているという評価のようです. ちなみに定性評価を見るとSalUnは他の概念の生成もうまくいていないことがわかります.
Style
Van Gogh styleを消去した際の結果を示します. 除外した手法について著者らはstyleの消去を考慮に入れた手法でないとしています.
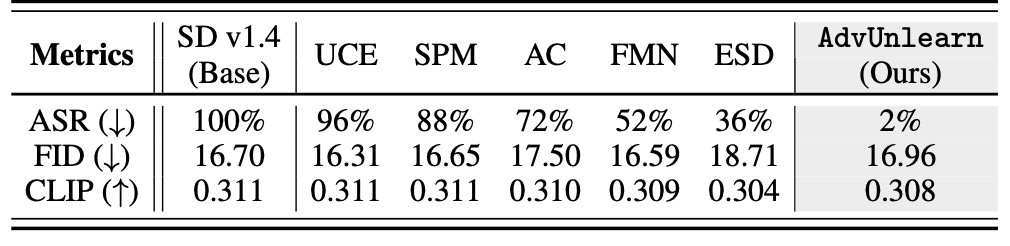
結果を見ると, ASRは脅威の2%です. しかも, FIDやCLIP Scoreは先ほどより改善しています. すなわちよりロバストでutilityのある消去が実現できたということになります.
生成例を見てみると完全にVan Goghが消えていて, Picassoっぽいものは残っていることが確認できます.

Object
Churchを消去した際の結果を示します. 概ねstyleと同じような結果が確認できます. SHはロバストな消去が可能であるものの, FIDが非常に悪くなっています.

生成例を見てみるとこちらもChurchが消えていることがわかります.

Plug-and-Play
今度はAdvUnlearnを用いて概念を消去したtext encoderをStable Diffusion1.4以外のU-NetとVAEにtransferして結果を確認します. text encoderから概念が消えていればU-Net等を別のものにしたところで生成結果に消した概念は現れません.
Nudityを消去した際の結果を見てみます. ここではStable Diffusion1.4を用いてunlearnしたtextt encoderを他のモデルのtext encoderとして使用します. 結果を見るとStable Diffusion1.5では同等の効果が確認できます. しかし, 他の2モデルではASRがそこまで下がっていません.

Effect of Layer
text encoderのレイヤーは12層ありますが, いくつを更新対象とすると効果があるかを調べています. 選び方はいろいろありますが, ここでは簡単に最初の
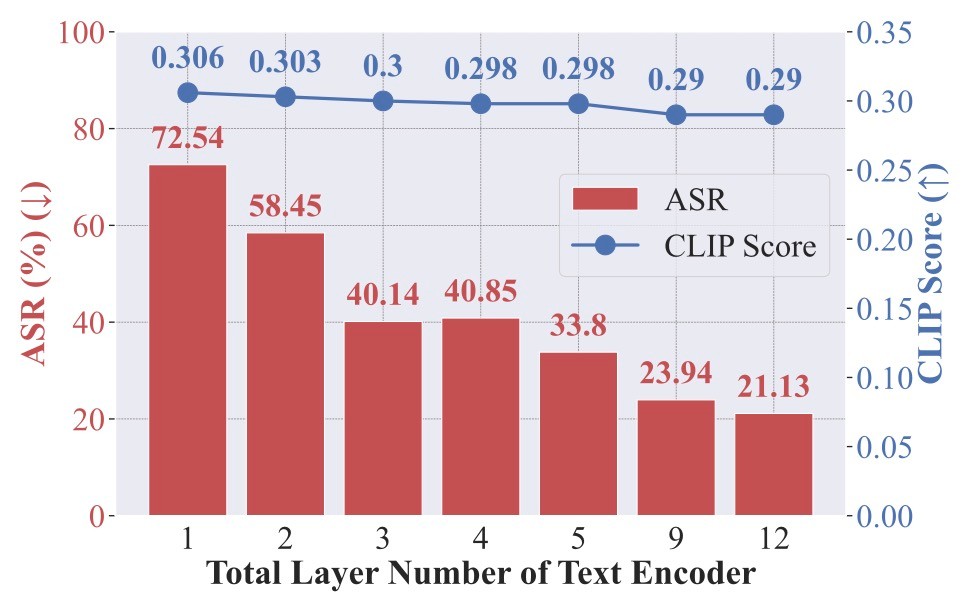
「以上のことはNudityに限った話で, objcetやstyleでは最初の層のみで大丈夫である」, と論文では述べられていますがそれを支持する実験結果は示されていませんでした.
なお, 以前見たようにDiffQuickFixの論文では, Nudityの話はしておらず, 論文のスコープ外のことに対して「違うじゃないか」と言っているように見えます.
敵対的攻撃の選択
実験設定で確認したように, UnlearnDiffAtkを用いたASRを確認していました. ここでは他の攻撃手法でも実験を行います.
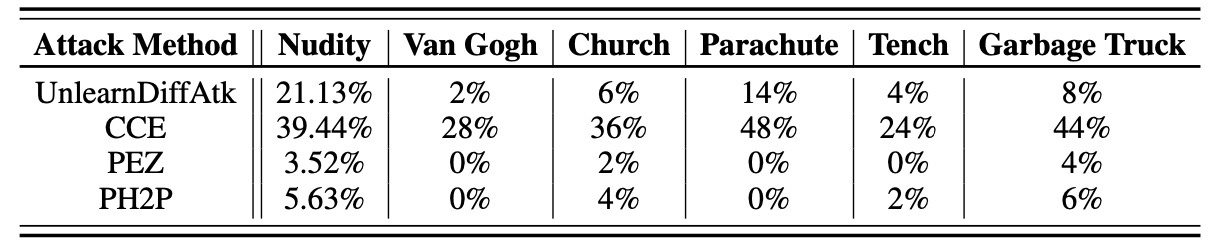
CCE以外の手法はdiscrete promptsベースの手法ですが, それらを用いると性能は良く見えます. 特に, UnlearnDiffAtkの場合はPEZやPH2Pといった手法より高いASRですので, AdvUnlearnでUnlearnDiffAtkを用いることは良いことと言えます (強い攻撃手法と言える). 一方でCCEはより高いASRを獲得しています. これは連続空間でtext embeddingを探索するので探索範囲が広いこと, textual inversion由来の手法のために訓練中に遭遇しなかった表現を得ることができることなどが要因と考えられます.
まとめ
- 敵対的学習の枠組みを取り込んだAdvUnlearnの提案
- U-Netではなくtext encoderを更新する
- 実験では低いASRでロバストさを示し, FIDなどを維持することで性能劣化を抑えることに成功
思ったこと
- styleの消去で結果を示さなかった手法についてstyle消去のために設計されていないからとしていますが, DiffQuickFixはNudityの実験をしていないのに持ち出したことからもアンフェアでないかと思います.
- 関連してAppendixにfull resultsとして示すべきだと思います. そうでないと適当言ってるかどうかわからないです.
- Appendix Eでは他のオブジェクトでの結果が示されています. そこでTenchを消去した際の生成例で(少なくとも上半身は裸の)Babyが登場しているのですが, ここからNudityを消去することで服を着せることができることを示せると説得力が増すのではと思いました.
- 攻撃手法でtext embeddingベースのCCEを登場させた理由がよくわかりませんでした. 特に採用するわけでもなく, text encoderを更新する観点からしても登場させる意味がないように思えます.
- 実際に攻撃に対してロバストである定性的結果があると良いように思えます.
- かなりシンプルなアプローチでわかりやすくなっているのはとてもいいと思います. 最近はAdapterつけたりsegmentationしたりして少しごちゃごちゃしてる手法が出てきていますがまだそのフェーズではないような気がします.
参考文献
- Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, and Sijia Liu. Defensive unlearning with adversarial training for robust concept erasure in diffusion models, 2024.
- Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples, 2015.
Discussion