Stable Diffusionからの概念消去⑤:DiffQuickFix (論文)
Localizing and Editing Knowledge In Text-to-Image Generative Models (ICLR2024)
今回はtext-to-imageの概念消去に戻ってDiffQuickFixという手法をみます. 論文は60ページ以上あり, 非常に多くの結果が提供されていますが主にmain paperの部分を見ていきます.
図や表はことわりのない限り論文からの引用です.
書籍情報
Samyadeep Basu and Nanxuan Zhao and Vlad I Morariu and Soheil Feizi and Varun Manjunatha. Localizing and Editing Knowledge In Text-to-Image Generative Models. The Twelfth International Conference on Learning Representations, 2024
関連リンク
公式実装はなさそうです. 公式実装がAdobe Researchの方から公開されました (2024/10/24追記).
TL;DR
この論文では, 「画像生成には, オブジェクトの構造, スタイル, 視点などの属性に関するきめ細かな知識が必要であるが, このような情報はtext-to-image generative modelsのどこに存在するのだろうか?」という問いを扱います.
著者らの貢献は以下のようにまとめられます (論文の抜粋です).
- 媒介分析 (Causal Mediation Analysis)を用いて知識がU-Netとtext encoderのどこにあるのかを追跡する.
- その結果から, Diff-QuickFixという手法を提案. 既存手法の1000倍以上高速で, 1秒以内の知識編集が可能
前提知識
提案手法に移る前に前提知識をいくつか確認します.
Transformerの知識の蓄積
知識編集で最もホットな分野といえばLLMだと思います. LLMでは特にGPTに焦点を当てて研究が行われています. いくつか研究がありますが, 最も有名な研究はROMEという研究です.
この論文ではcausal traceを用いてGPTの真ん中あたりのMLP (feed-forward)に知識が蓄積しているとしています. イメージとしては発火したニューロンがあればそこに知識がありそうという感じです.
しかし, この手法は論文のタイトルにあるようにGPT (decoder only model)でのみで検証された話です. たとえばencoder only modelであるBERTでは別の論文があり,
ここでは後ろの方のlayerにあるとされています. さて, text-to-imageを行うモデルではどうでしょう? text-to-imageではプロンプトをエンコードするtext encoderと画像を生成するgenerative moduleに分かれていて, generative moduleは条件なしでも生成ができます. なので両方に知識が蓄積されていそうです. この疑問を扱うのがこの論文の内容になります.
Causal Mediation Analysis
先ほどのROMEでは因果追跡 (causal trace)を用いました. それに対してこの論文では媒介分析 (Causal Mediation Analysis)を用います. 媒介分析とはなんでしょうか?私もそこまで詳しいわけではないので以下のサイトを参考にまとめてみます.
- https://www.krsk-phs.com/entry/mediation1
- https://www.asahikawa-med.ac.jp/dept/mc/healthy/HP2/21_Mediation.pdf
1つ目のサイトにはこのように書かれています.
「媒介分析」とは文字通り「注目している因果関係がある因子によってどの程度媒介されるか」を検討する手法です。
これを信じて今回の話に適用すると以下のようになります.
text-to-imageにおいて, textからimageを生成する因果関係がある因子 (ここではtext encoderとU-Netのパラメータ)によってどの程度媒介されるか
これだけでも十分わかるような気がしますが, 2つ目の資料には以下のように書かれています.
媒介分析は、原因要因がアウトカムに影響を与えるメカニズム、経路(pathways)、および中間要因(intermediates)を理解するのに役立つ。
介入方法を再確認する。介入の効果を増加させるために、介入方法をさらに改良したい。
すなわち, どの媒介変数 (ここではパラメータ)がどの程度text-to-imageのパイプラインにおいて寄与しているのかを調べて, その寄与度が大きいパラメータを変更すれば知識編集ができそうということだと私は解釈しています.
この論文では, 4つの視覚的属性に限定して分析を行います.
- objects
- style
- color
- action
なお, 図にすると以下のようになります.
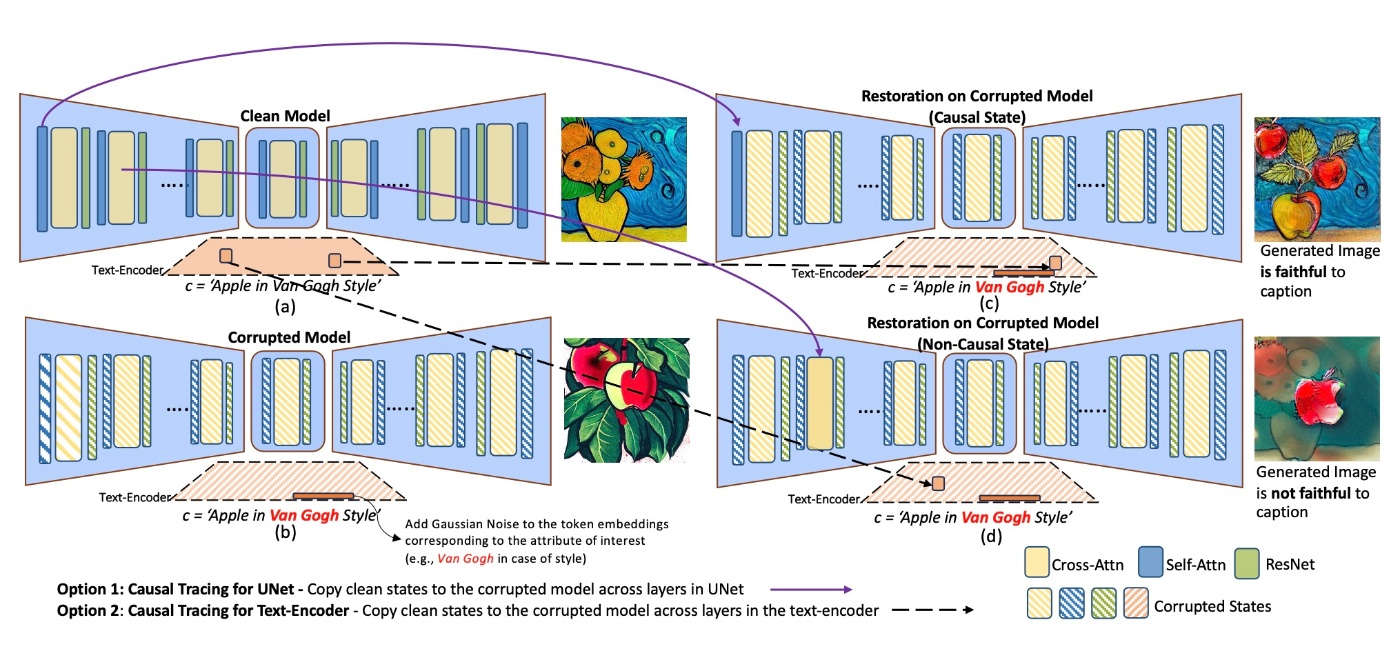
U-Netの追跡手法
実際に, U-Netの分析を行います. ある程度の手法 (DDPM, classifier-free guidanceなど)は前提とします. 分析の仕方はROMEに倣い, 3つの設定を考えます.
- cleam model
\varepsilon_{\theta} - corrupted model
\varepsilon_{\theta}^{corr} c - restored model
\varepsilon_{\theta}^{restored} \varepsilon_{\theta}^{corr}
少しわかりにくいので定式化してみます. まず,
続いて, corrupted modelのレイヤー
最終的な
Text Encoderの追跡手法
text encoderもU-Netと同様に調べます. CLIP-ViT-L/336pxを用いるようです. notationが変わるだけなので詳細は省略します.
Extracing Causal States Using CLIP Score
分析結果
実際に, 分析の結果を見てみます. まずはU-Netです.
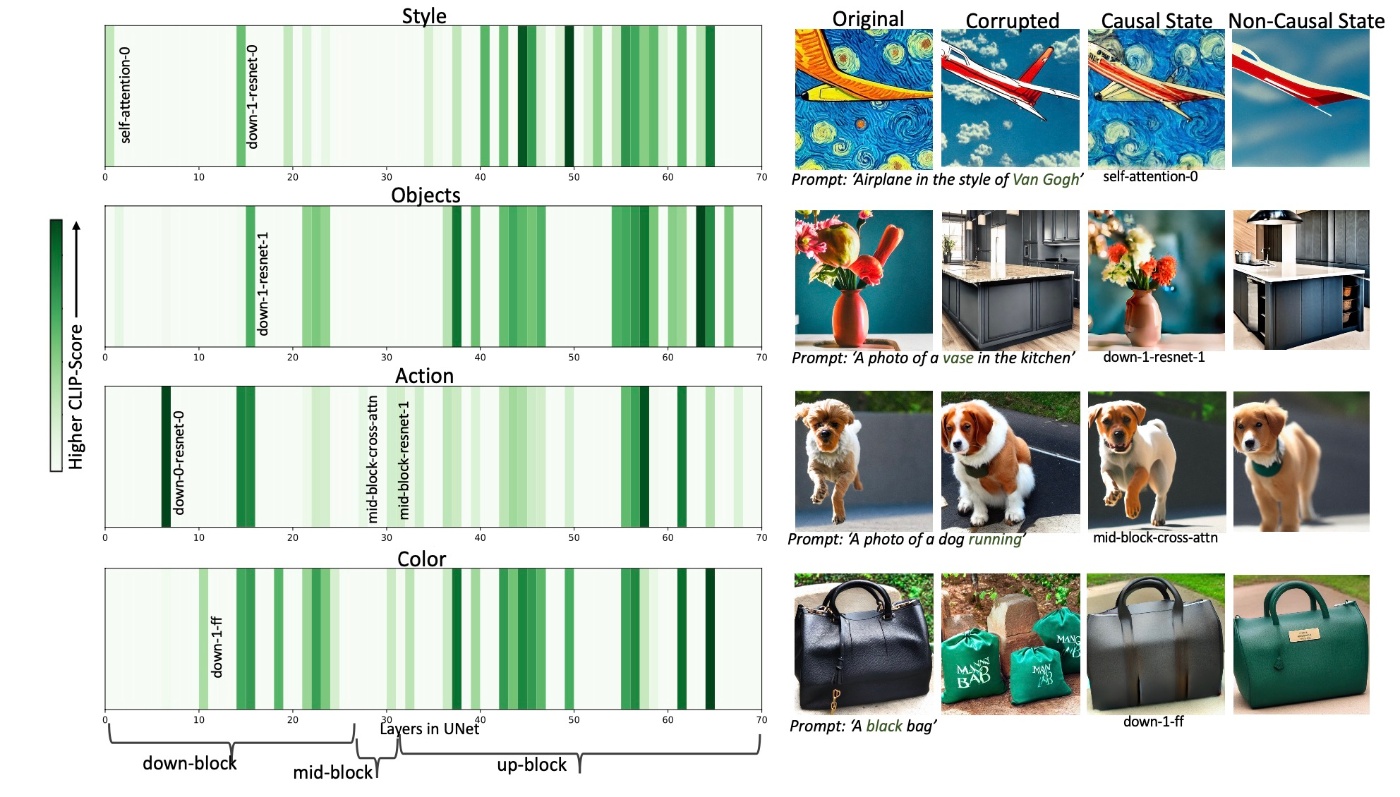
左図から, U-Netの様々なレイヤーに因果関係の状態が広がっていることがわかります. 特に, up-blockが相対的にCLIP Scoreが高いことがわかります. しかし, up-blockの中でも視覚的属性の種類によって違いがります. 例えばstyleで濃い緑になっている部分はobjectでは真っ白なことがあります.
次に右図をみます. これは, 因果関係のあるレイヤーと非因果関係のレイヤーの両方を復元して生成された画像が示されています. 左図のレイヤーの名前が書かれている部分です. この結果から, cross attentionを超えた領域に様々な視覚的属性が分布していることがわかります. Appendix Bに広範な結果がありますが, 量が多すぎるのでここでは載せられません.
ここで, 重要な点があります. ROMEの研究では知識は属性関連の知識が近接した数層にあるとされています. しかし, 今回の分析結果はそうではありません.
続いて, Text Encoderでの結果を確認します.
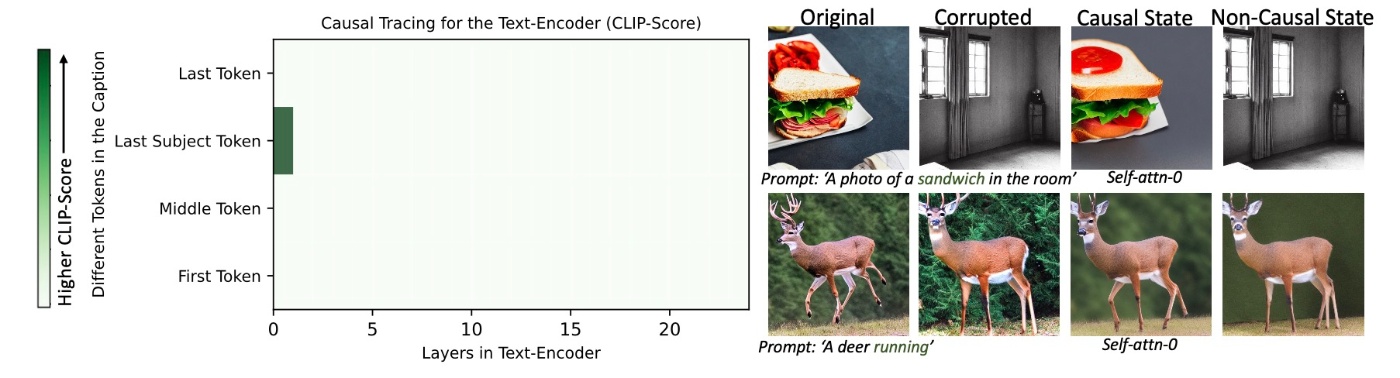
先ほどのU-Netの結果とは対照的です. Text Encoderでは, 因果関係の状態がすべての視覚的属性にわたってLast Subject Tokenに対応する最初のself-attention layerに局所化されていることがわかります. 実際, 最初のself-attention layer以外を復元してもプロンプトとは一致しない結果が得られます. これもAppendix Cに結果がありますが, この結果は見てみます.
first self-attention layerを復元した場合, 以下のようにプロンプトと一致した画像になります.
しかし, それ以外の例として6番目のself-attention layerを復元してみると, 以下のように, プロンプトとはまったく関係のない画像になります.

この観察結果はもやはりROMEでの研究とは異なります.
これまでの分析から, U-NetよりはText Encoderの方が知識操作が容易であることが想像できます. そこで, DiffQuickFixという閉形式で記述できる編集手法を提案しています.
DiffQuickFix
さっそく提案手法を確認します. 先ほどの分析結果から, Text Encoderのfirst self-attention layerのみを更新すればよさそうであることがわかります. この手法は1秒以内にできるのでESDなどと比較しても高速に動作します.
self attentionには重みが4つあります. その中でもattention operationのあとの出力を射映する重みを更新します. 一般には
非常にTIMEの式と似ていますが, そこの言及はありませんでした.
TIMEと似ているので当然同様の最適化が行われます. 具体的には
です.
実験
実際に, Stable Diffusionに提案手法を適用して有効性を確認します. まず, CLIP Scoreを用いてfirt self-attentionを更新する正当性を示しています.
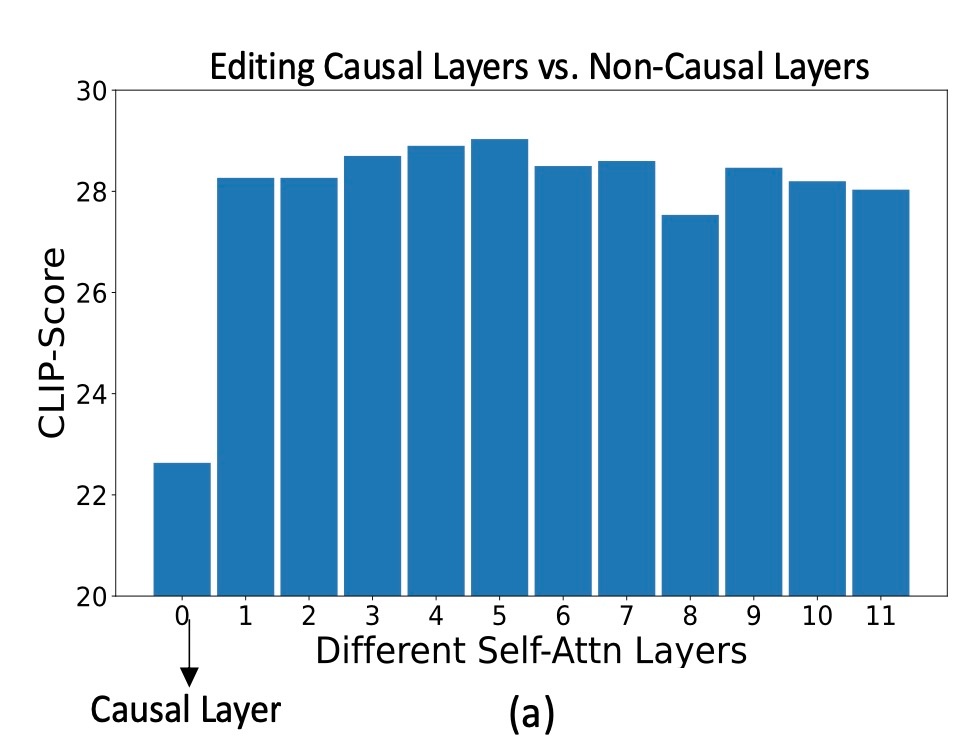
確かに, 最初のself-attention以外を更新したときはCLIP Scoreが同じくらいですが, 最初のself-attentionの場合は大幅に下がっています. ただし, 縦軸が20を一番下にしている点はミスリードっぽく見えるので注意が必要です.
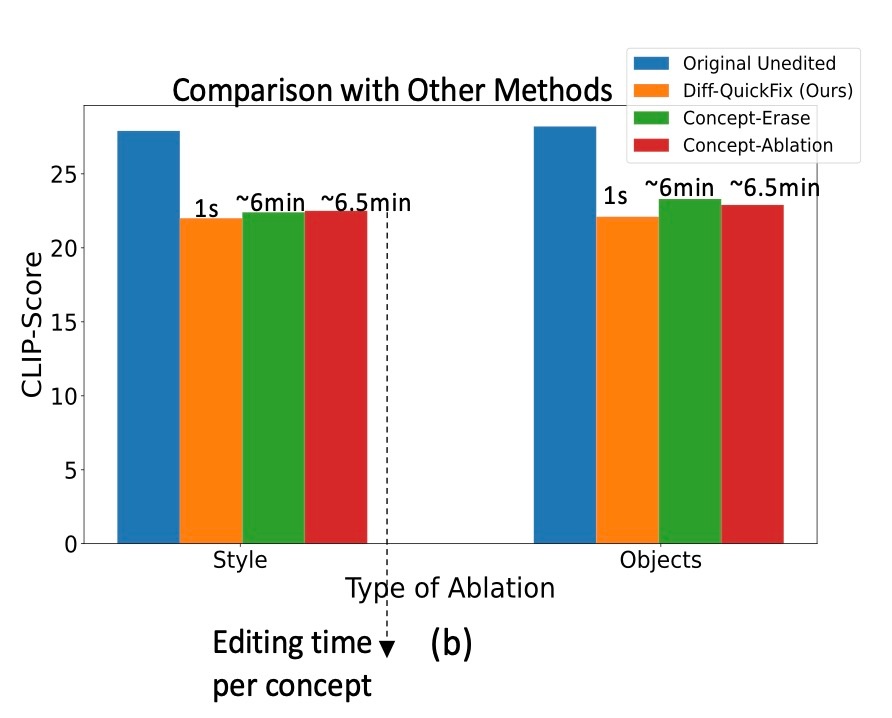
続いて, 他の手法との定量比較を行います. 他の手法と比較しても同等のCLIP Scoreになっています. このタスクにおいてCLIP Scoreは低ければいい指標になるので, 一応比較手法よりは性能が良いことになりますがそこまでではありません. しかし, それを1秒でできるというのは非常に優位な手法であると言えます.
実際に, 概念を消去したり更新させた例を見てみます. ここでは概念消去が非常にうまくいっていることがわかります. それに加え, 例えばトランプ大統領をバイデン大統領にしたりといったこともできています.

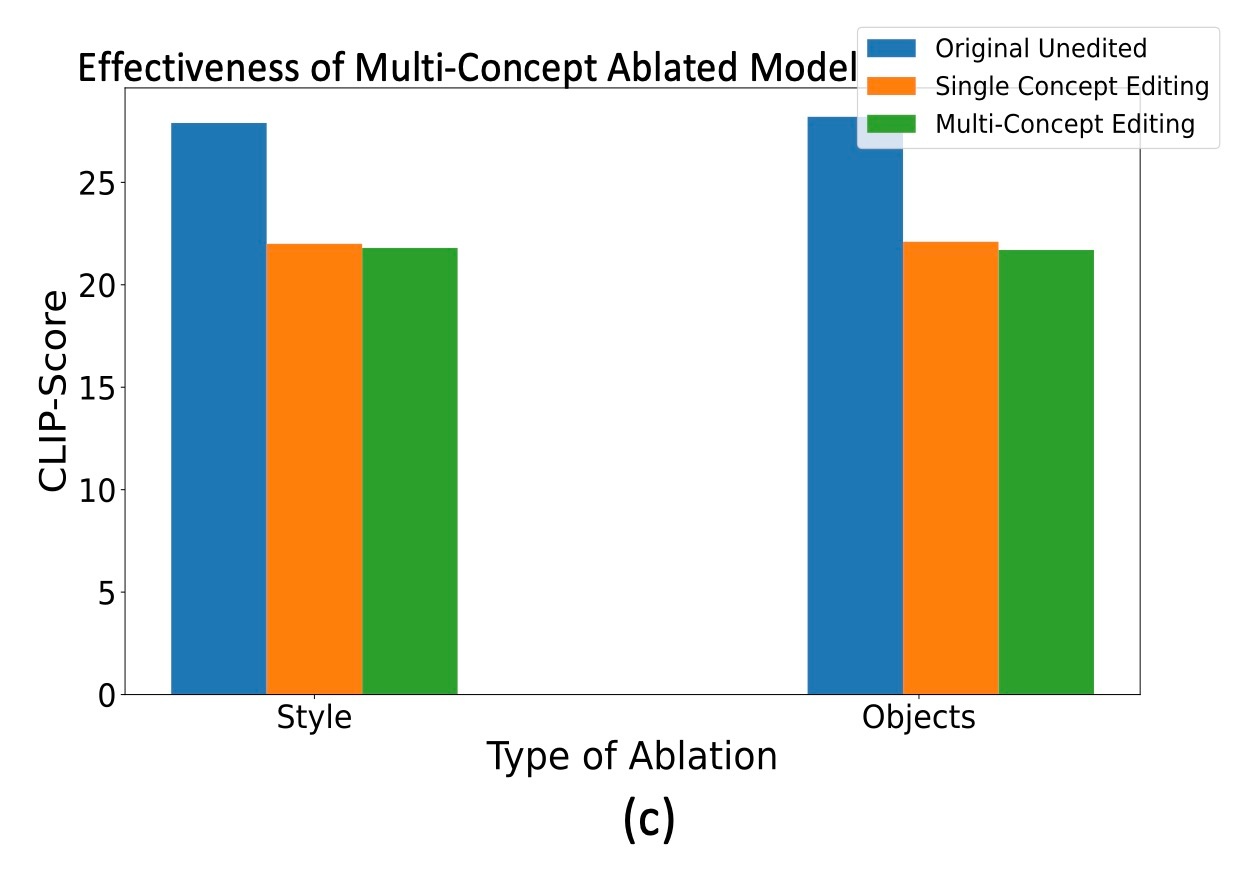
続いて, 複数概念の消去の結果を確認します. 一度に最大10個のstyleやobjectを消去できると述べられています. 複数概念を同時に消去しても性能に変化はありません.
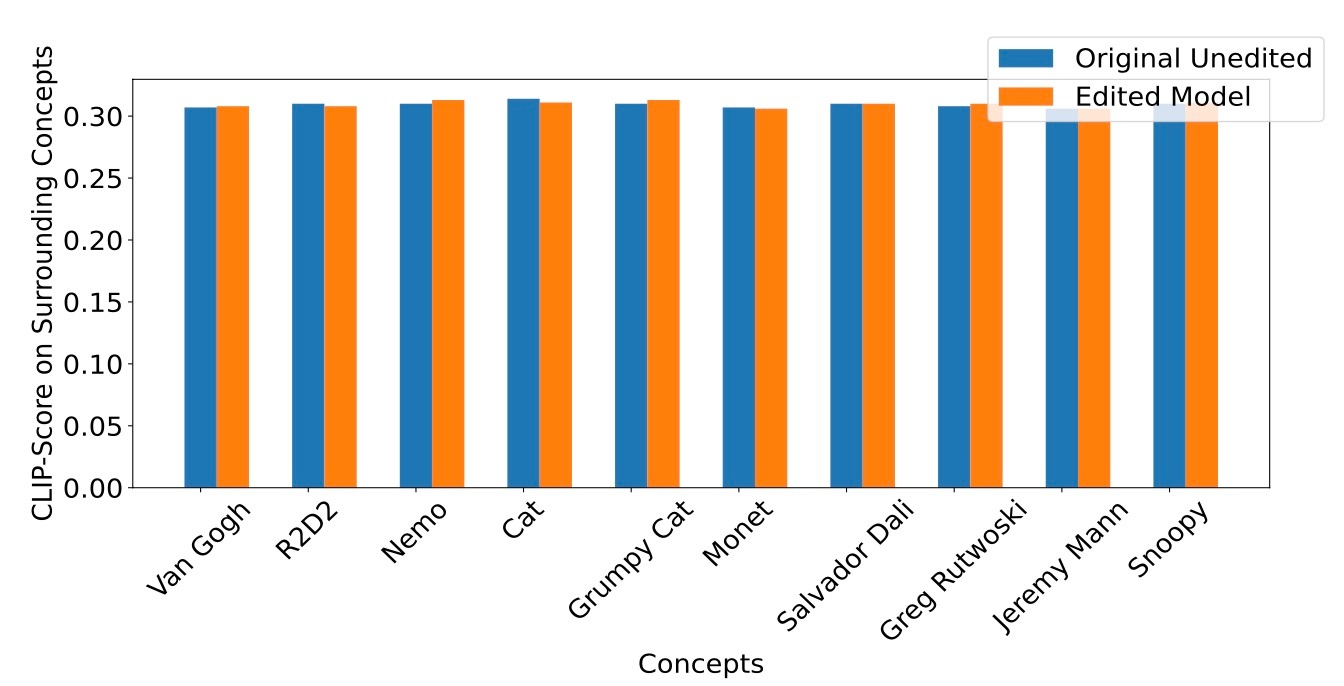
これでmain paperの実験は終わりなのですが, やや味気ないので少しだけAppendixも確認します. まず, 他の概念への影響を確認します. CLIP Scoreで結果を確認すると, Original SDと同程度になっていることが確認できます.
実際に, Van Gogh styleを消したモデルでの生成例を確認します. 確かに他の概念への影響は少なそうです.

ここまではStable Diffusion1.4での話でした. では, Stable Diffusion2.1 ではどうなのでしょうか. Stable Diffusionは1.xのモデルと2.xのモデルで用いているText Encoderが異なります. 実際に, Stable Diffusion2.1で分析を行ってみても, 同様にfirst self-attntion layerを編集すれば良さそうということがわかります. それに従って実際に概念消去を行った結果が以下のようになります.

確かに概念が消えていることがわかります.
まとめ
- Causal Mediation Analysisを用いて視覚的属性に関する情報がU-Netは幅広く分布しており, Text Encoderはfirst self-attention layerにのみ分布していることを明らかにした
- それに従って Text Encoderのfirst self-attention layerの重み
W_{out} - 既存手法より高速に, 同程度の概念消去が可能
思ったこと
- 分析がしっかりしている論文だと感じました. 分析結果も十分に示されています.
- UCEのときもそうでしたが, 閉形式で記述できるのは計算自体が高速に終了する可能性があり, とても良いと思います.
- 一方で既存手法との比較が少ないように感じます. Appendixの最後の方に少しだけ定性評価が示されていますがstyleだけです.
- 途中でも触れましたが, TIMEとの違いについても言及が欲しいです. Related WorksではTIMEの論文が引用されているので著者らはもちろん知っています.
- ImagenやeDiff-IではT5も使われています (eDiff-IはCLIP Text Encoderとのアンサンブルです). この2つの研究は本論文でも当然引用されているのですが, その場合でも使えるのかという議論は見当たらなかったと思います.
- また, この論文はICLR2024ですが, ICML2023にはStyleGAN-TというText-to-Imageを行うGANが提案されています. この論文のタイトルは''Generative Models''なわけですから, 当然このようなモデルに対する議論があって然るべきです. あくまで提案手法はU-Netと比較してText Encoderの方が編集が容易だという話であって, StyleGAN-Tでは異なる結果の可能性があります.
参考文献
- Samyadeep Basu and Nanxuan Zhao and Vlad I Morariu and Soheil Feizi and Varun Manjunatha. Localizing and Editing Knowledge In Text-to-Image Generative Models. The Twelfth International Conference on Learning Representations, 2024
- Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in gpt. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 17359–17372. Curran Associates, Inc., 2022.
- Hadas Orgad, Bahjat Kawar, and Yonatan Belinkov. Editing implicit assumptions in text-to-image diffusion models. In Proceedings of the 2023 IEEE International Conference on Computer Vision, 2023.
- https://www.krsk-phs.com/entry/mediation1
- https://www.asahikawa-med.ac.jp/dept/mc/healthy/HP2/21_Mediation.pdf
Discussion