Stable Diffusionからの概念消去⑧:LocoEdit (論文)



On Mechanistic Knowledge Localization in Text-to-Image Generative Models (ICML2024)
以前, DiffQuickFixの記事を書きました.
この論文と同じ著者による新作の論文が今回紹介するLocoGenです. DiffQuickFixの後続研究にあたるため, DiffQuickFixの知識は前提とします. 図は論文からの引用です.
書籍情報
Samyadeep Basu, Keivan Rezaei, Priyatham Kattakinda, Vlad I Morariu, Nanxuan Zhao, Ryan A. Rossi, Varun Manjunatha, and Soheil Feizi. On mechanistic knowledge localization in text-to-image generative models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 3224–3265. PMLR, 21–27 Jul 2024.
関連リンク
GitHubのリンクはありますが, リポジトリは空です.
-
GitHubのリンクが論文にはありますが, 5/26現在では未公開のようです.
Causal Tracing
DiffQuickFixの論文 (以後「前回」とします)ではCausal Mediation Analysisを用いて知識のありそうな場所を特定していました. それはROMEなどのLLMに対する分析手法とは異なっています. 今回の論文ではROMEなどでも行われているCausal Tracingを行います.
今回の分析手法と前回の分析手法との違いを表したのが下の図になります.
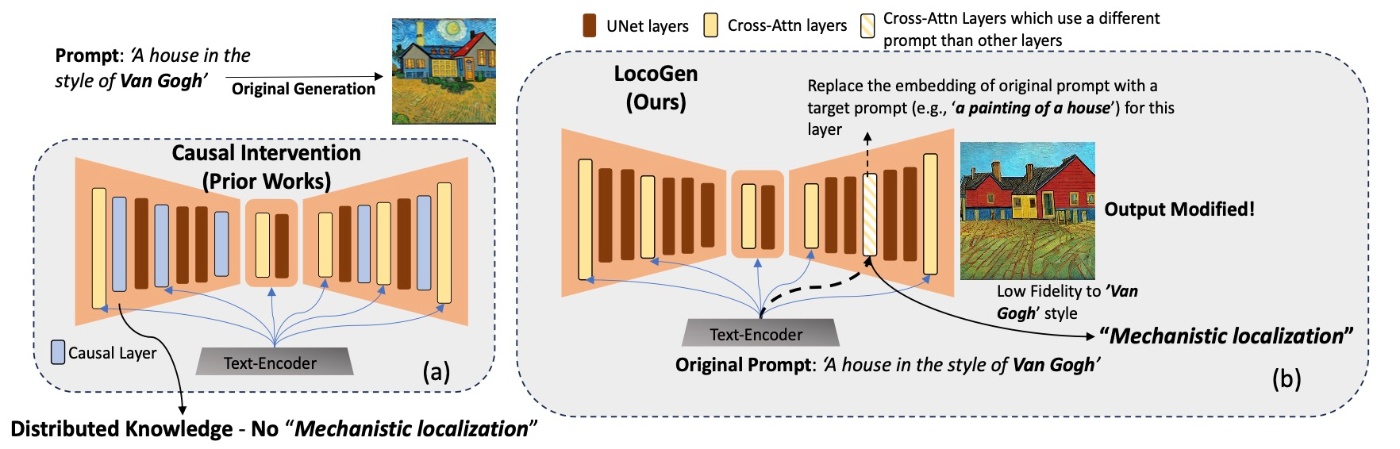
流れとしては, U-Netのcross-attentionの部分集合を見つけ, そのkeyとvalueの行列が変更されたときに, スタイルといった視覚的属性がどのように変化するかを確認します. 中間層に関与することで, より直接的な介入の効果を測定することができます.
まずは, 前回と同様の手法を用いて結果を観察します. 簡単に前回の分析手法を述べるとレイヤー単位で壊したり復元したりします.
U-Net
さっそく結果を見てみます.
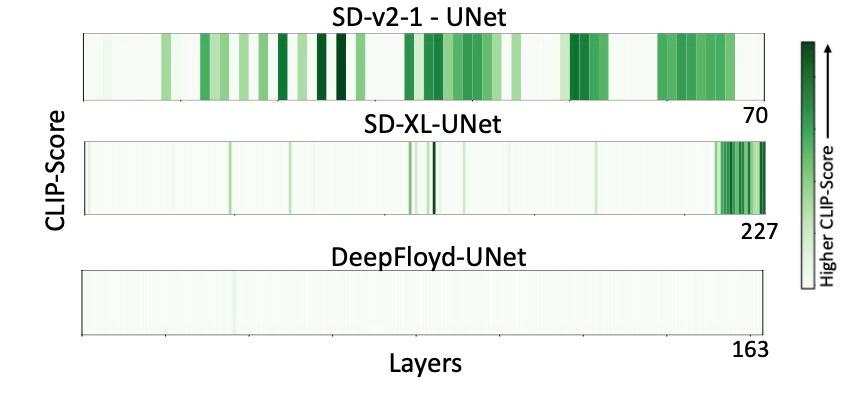
いわゆるLatent Diffusion Models (LDMs)では幅広く分布していることがわかります. Stable Diffusion 1.5でも同じだったことを思い出すと, 前回と同様の結果と言えます. しかしながら, モデルによってそれは異なっていて, SD-XLでは後ろの層に集中しています. また, ImagenベースのOSSであるDeepFloydでは1箇所だけやや緑が見えますが全体として知識は分布していないことがわかります.
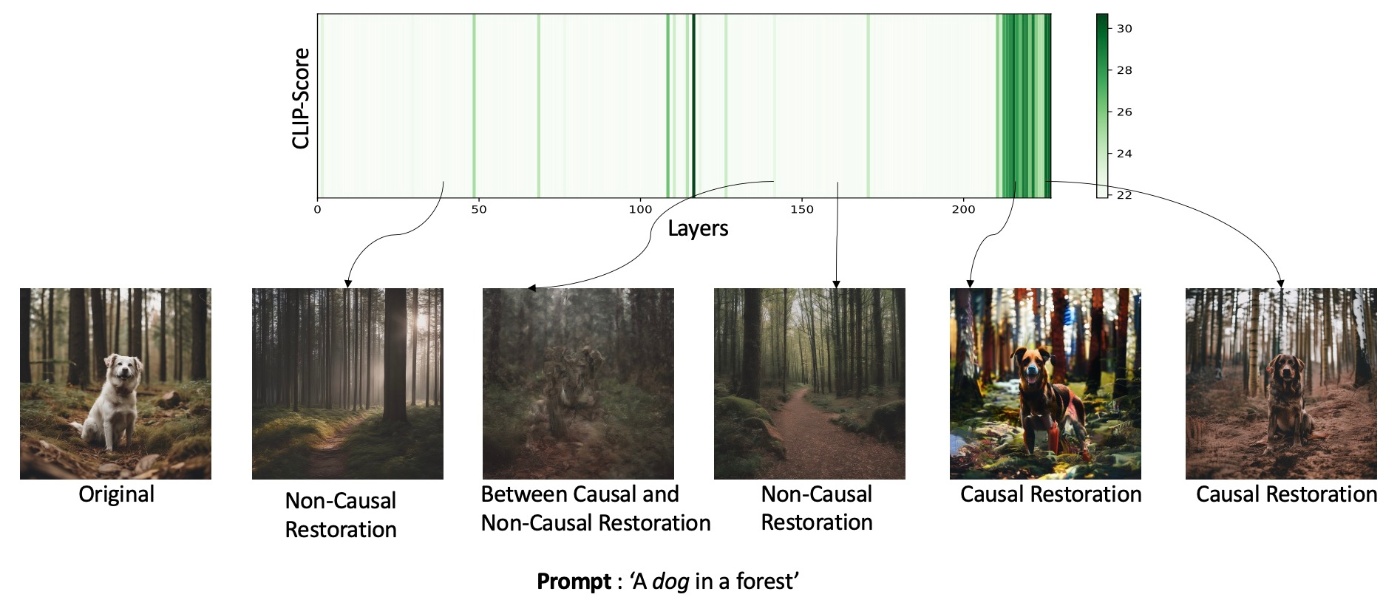
これは実際に生成してみるとわかります. まず, Stable Diffusion 2.1の結果です. オブジェクトという属性は, 様々な層に分布していて, モデル編集では関連するすべての層を編集する必要があります. また, レイヤーの構成要素に非線形性が存在するために閉形式では更新できません.

続いて, SD-XLの結果をみます. これもSD-2.1と同様に様々な部分に分散していますが, それほど密に分布しているわけではありません.
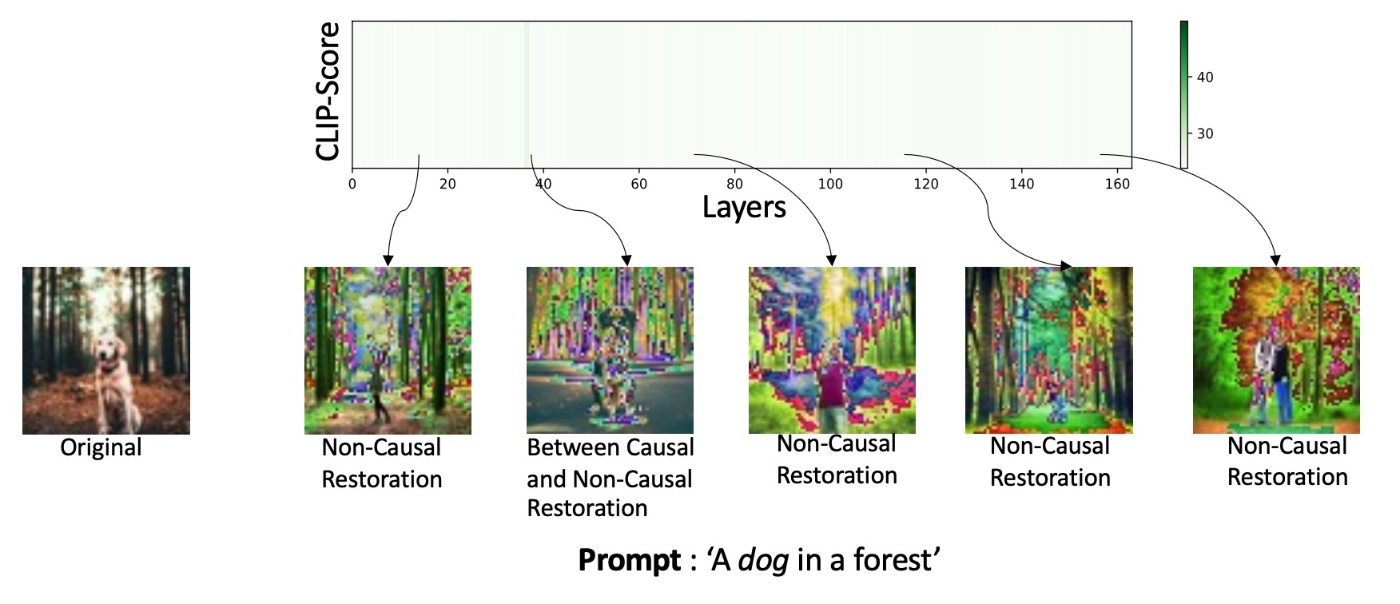
最後に, DeepFloydを確認します. まったくモデル復元ができず, 因果関係がありません. これではU-Netでモデルを編集することができません.
Text Encoder
前回はStable Diffusion 1.xと2.xは同じ結果でした. では, 今回はどうでしょう.
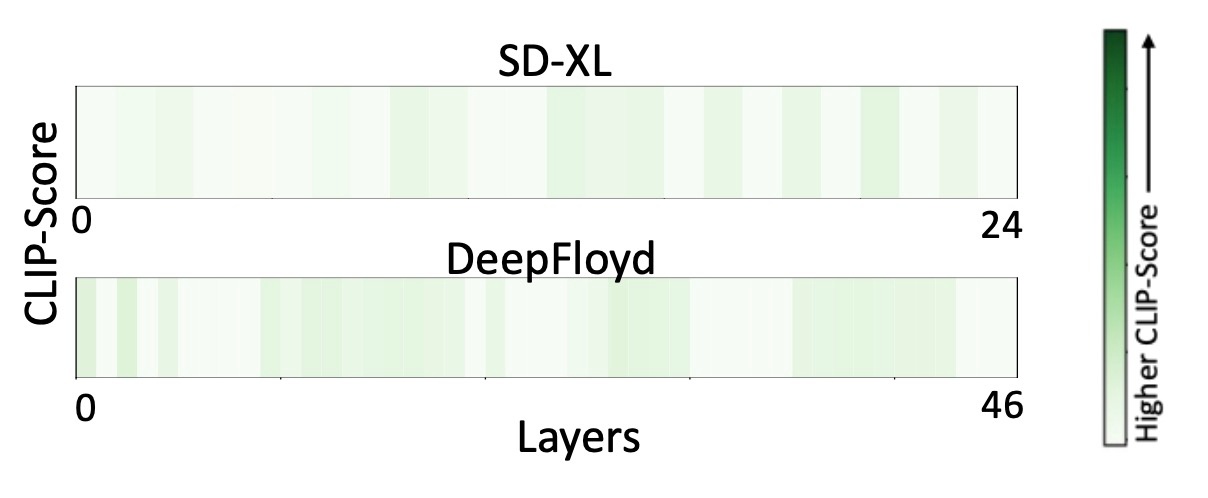
この結果からは, DeepFloydとSD-XLのText Encoderにはこれまであった固有の因果関係が存在しないことがわかります. そこで, Text Encoderの比較を行うと, 以下の表になります. ここから推測できるのは, 単独のCLIP Text Encoderが用いられたときのみにユニークな因果状態が生じるということです.
| Model | Text Encoder |
|---|---|
| SD-1.5 | CLIP-ViT-L-p14 |
| SD-2.1 | OpenCLIP-ViT-H |
| SD-XL | OpenCLIP-ViT-G & CLIP-ViT-L |
| DeepFloyd | T5-XXL |
LocoGen: Towards Mechanistic Knowledge Localization
これまで確認した知識局在化の汎化性の欠如を考慮したより汎用的な手法としてLocoGenを提案しています.
Knowledge Control in Cross-Attention Layers
推論過程ではclassifier-free guidanceを用いて条件なし・ありのスコアを取り込みます. 式にすると
です. DDIMで
テキストによる条件は,
イメージとしての話は以上ですが, しっかり数式にしておきます. cross-attention layerの部分集合
例えば, 特定のartistに対応するstyleの知識が格納されている層を見つけることを考えます. すると,
アルゴリズム
目標は異なる視覚属性に対する制御層
その次に,
特定の属性にLogoGenを適用するには, 特定の属性を含む入力プロンプトの集合
その後, styleとobjectに関しては,

特定結果
実際にOSSモデルを用いた結果をみます. 定量結果をみます. ここから, SD-v1-5とSD-v2-1においてはstyleは
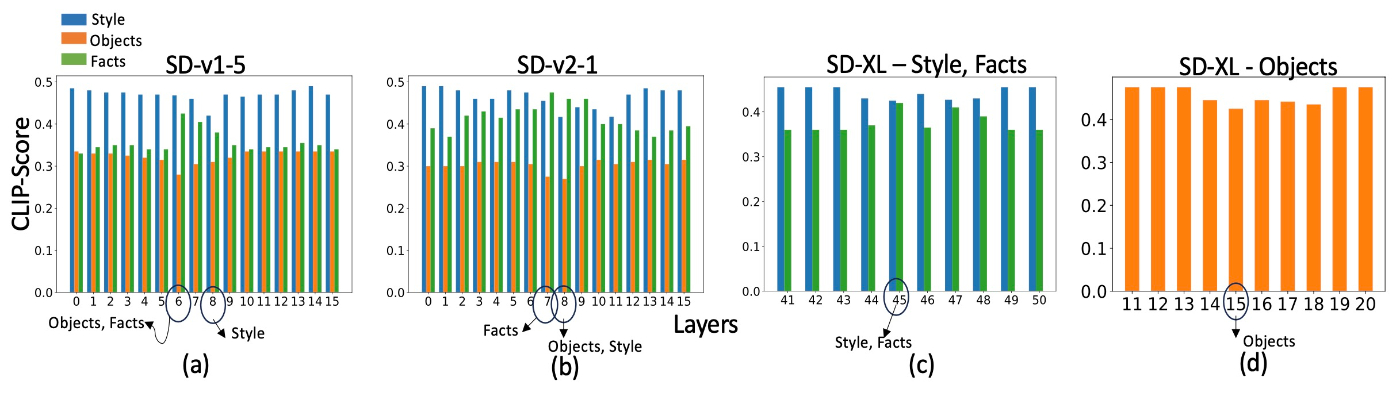
また, この結果にはないですが, Open-Journeyは概ねSD-v1-5と同じ結果です. Open-JourneyはSD-v1-5をfine-tuningする形で学習されており, Mid-Journeyの生成画像をもとに学習していることを踏まえると, 訓練設定やデータセットの違いではなく, (text encoderやU-Netなどの) モデルアーキテクチャと密接に関連していることが伺えます.
SD-XLの結果にいく前に定性的な結果も見ます.

特定の層に介入することで概念の影響を小さくできています. 例えば, SD-v1-5やOpen-JourneyではLayer 8に介入することでVan Gogh特有の夜空の描き方 (starry night)の要素が消えていることがわかります.
続いてSD-XLです. 先ほどのCLIP Scoreのグラフの (c)と, 下の生成例をみます.

styleとfactは
しかし, DeepFloydではそれは異なります. 例えばfactという属性を鑑みても, “The British Monarch”は

LocoEdit: Editing to Ablate Concepts
これまでの観察の結果を踏まえて, 概念消去の手法が提案されています. このような解析をこれまでしたのは閉形式で更新するためなので, 当然閉形式で更新を行います.
まず, LocoGenのアルゴリズムの結果として特定の属性に関与するレイヤーの集合が得られます. それを
入力プロンプト
です.
結果
まず, 定性的な結果を確認します.

この結果から, styleであったりobjectといったものが消えていることがわかります. これはCLIP Scoreの結果からも裏付けられます.
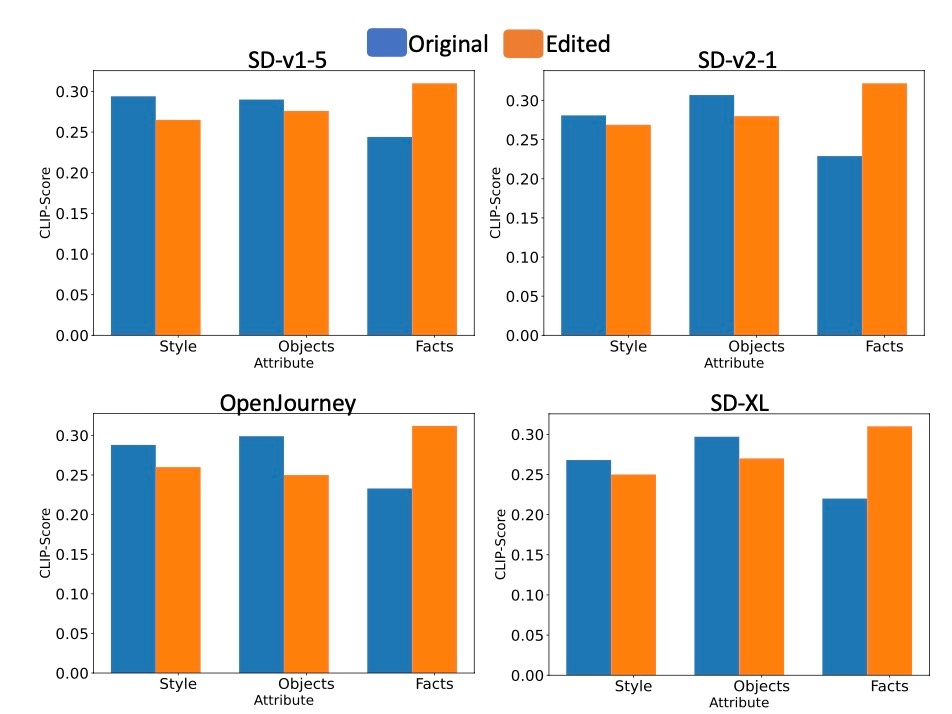
編集後のモデルは編集前のモデルと比較してstyleとobjectに関するCLIP Scoreが減少し (すなわち要素が消え), factsに関してはCLIP Scoreが上昇している (正しく知識更新された)ことがわかります. しかし, 手法がどれほど有効かはモデルによって異なっていて, 例えばstyleを例にとると, SD-v1-5とOpen-JourneyのグループとSD-v2-1とSD-XLのグループでは減少幅が異なっています. 定性的にはどちらのグループも消せていますが, 定量的には差が出るというのが現状です.
しかし, Deep-Floydでは課題が残ります.

Deep-FloydではT5-XXLが用いられますが, これは双方向のattentionを持ったencoderです. これはCLIP Text Encoderとは異なります. 閉形式での更新手法はlast subject tokenを埋め込むことに依存していているので, last subject token以降のトークンが重要な情報を持つ場合には不適当です.
On Neuron-Level Model Editing
これまではlayerの重み行列を更新していました. ここからはニューロンレベルで編集を行う可能性の探求をします. LocoGenで特定した層に対して, keyとvalueの埋め込みの活性化層でニューロンの選択的dropがstyle要素を効果的に除去できるかどうかを検証することが目的です.
ここでは特定のstyleの生成に関与するニューロンを特定します. 具体的には特定のstyleを含むプロンプトと, 含まないプロンプトを比較する際に, 顕著に変動するニューロンを特定します.
まず, 特定のstyle (例:ゴッホ)を特徴とする
さらに, これらの
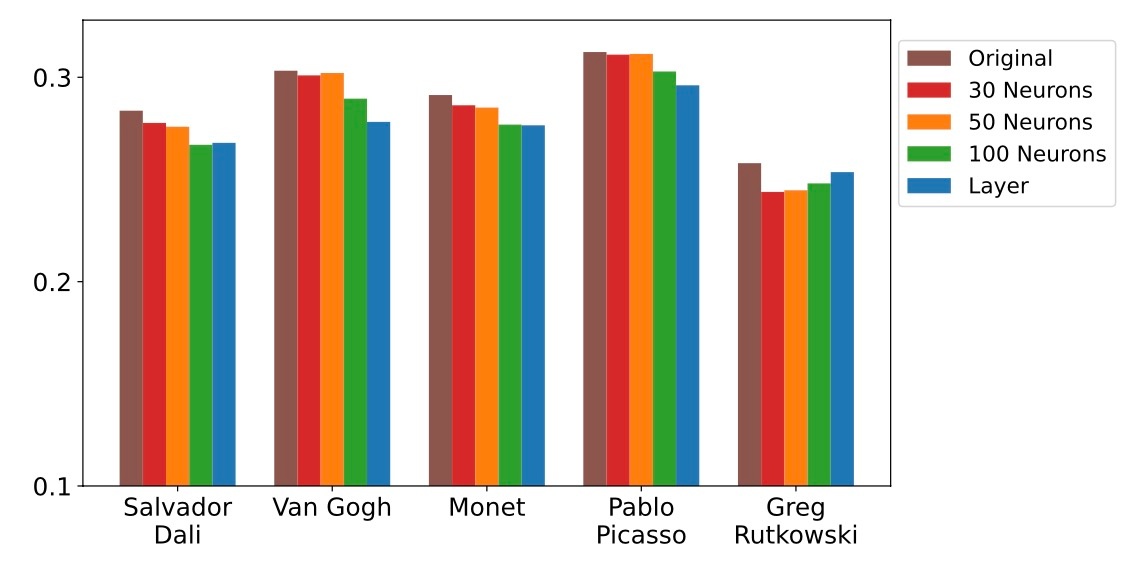
結果をみてみます.

ニューロンレベルでの編集は効果的であることがわかります. これは, 特定のstyleに関する知識が少数のニューロンにさらに局在化されていることを示唆しています. 特に, 編集するニューロンの数が増えるとより強く概念除去に反映されていることがわかります. CLIP Scoreを測定してみると効果的な除去が確認できます.
まとめ
- 詳細な分析によってtext-to-image diffusion modelsにおけるU-Net内部の知識の分布を調査
- それに基づく閉形式編集手法LogoEditの提案
- U-Net内部の知識の分布はtext-to-imageのアーキテクチャによって様々である
- Stable Diffusion系ではモデルごとに差はあれど, ある視覚属性について一部のレイヤーの隣接数個に集まる
思ったこと
- 今回も40ページを超える論文で, すごい量だと思いました.
- DiffQuickFixの際に思ったことがここで検証されていて, 個人的には安心しました.
- やはりタイトルでGeerative ModelsといいつつDiffusion Modelsしか検証していないのはあまりいいものではないように思えます.
- DeepFloydでもできるようになるといいなと思います.
- 論文の時期的にできていないだけだと思いますがStable Diffusion3のようなCLIPとT5を混合したアーキテクチャでの実験結果が気になります.
- アーキテクチャによって知識分布が変わるのはLLMではあまりみられない傾向だと思います (自分が知らないだけかもしれませんが). 複数モジュールが関わり合っているからと考えられますがMultimodalな言語モデルでの研究もヒントになりそうです.
参考文献
- Samyadeep Basu, Keivan Rezaei, Priyatham Kattakinda, Vlad I Morariu, Nanxuan Zhao, Ryan A. Rossi, Varun Manjunatha, and Soheil Feizi. On mechanistic knowledge localization in text-to-image generative models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 3224–3265. PMLR, 21–27 Jul 2024.
Changelog
- PMLR公開によるリンクの更新とそれに伴う文章の削除, 参考文献および書籍情報の更新 (2024/08/26)
Discussion