この記事は、Finatextグループ Advent Calendar 2024の4日目の記事です。
はじめに
こんにちは!ナウキャストのデータエンジニアのけびんです。
Snowflake は様々な便利な機能がありますが、その一つにゼロコピークローンがあります。 Snowflake のような DWH ではデータ量が大きいテーブルが多いと思いますが、こういったテーブルをコピーするのはコストが高いオペレーションになります。これを解決するのがゼロコピークローンです。
本ブログではゼロコピークローンに関する概要を説明し、利用時の注意点や具体的なユースケースを紹介していきます。
ゼロコピークローンとは?
概要
ゼロコピークローンとはテーブルやスキーマ、データベースといったSnowflakeの各種オブジェクトの「コピー」を作成する機能です。以下のように通常のオブジェクトのCREATE文に CLONE <source_object_name> を追加するだけでこの機能が利用できます。
CREATE TABLE company_metadata_dev CLONE company_metadata;
詳細は以下の CREATE <object> … CLONE 文のドキュメントをご覧ください。
仕組み
Snowflake ではデータの実体(マイクロパーティション)とメタデータは分離して管理されており、マイクロパーティションはS3などのオブジェクトストレージで永続化され、メタデータは Foundation DB という Key-Value Store で永続化されています。またこのマイクロパーティションはイミュータブルに管理されています。
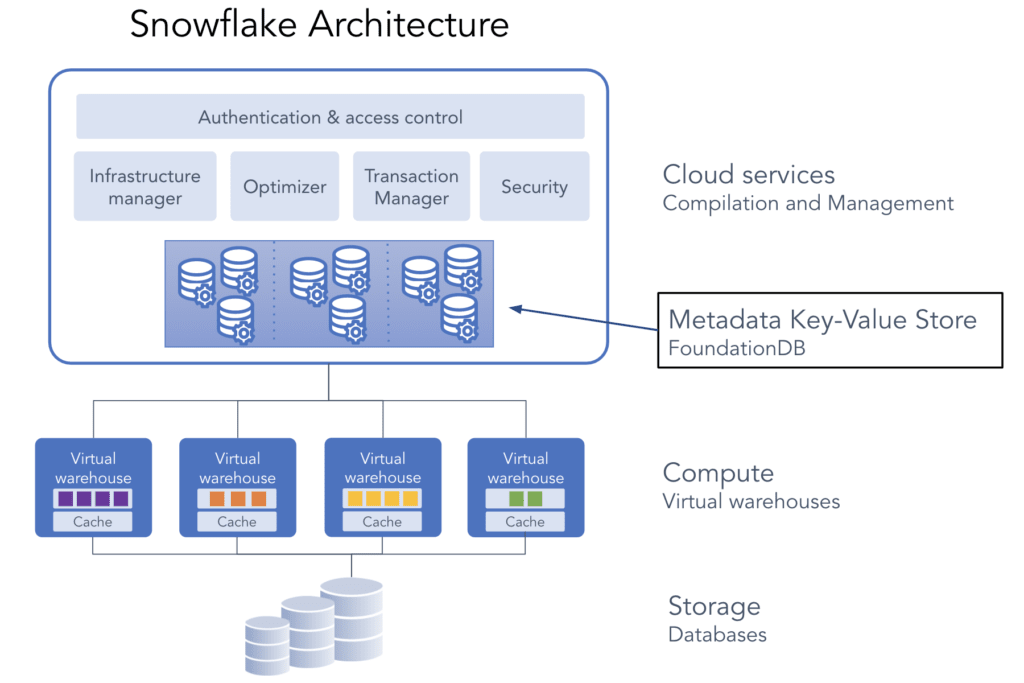
https://www.snowflake.com/en/blog/how-foundationdb-powers-snowflake-metadata-forward/ より
あるテーブルをコピーしようとしてマイクロパーティションもメタデータも両方をコピーしようとすると時間がかかります。特にマイクロパーティションはデータの実体であり、サイズが大きいからです。
そこでマイクロパーティションはコピーせず、それを参照するメタデータだけコピーして新しく用意することであたかもテーブル全体をコピーしたかのように取り扱うことを可能にした仕組みがゼロコピークローンです。
具体的に書くと、
- クローン直後は、元テーブルもクローン先のテーブルもメタデータだけが別で、マイクロパーティションは同じものを参照した状態
- クローン元で変更があった場合、元のマイクロパーティションは変更されず、新しくマイクロパーティションは作られ、メタデータもこれを参照するようにクローン元のテーブルでのみ独立に変更される
- クローン先のテーブルであっても同様
というような形です。
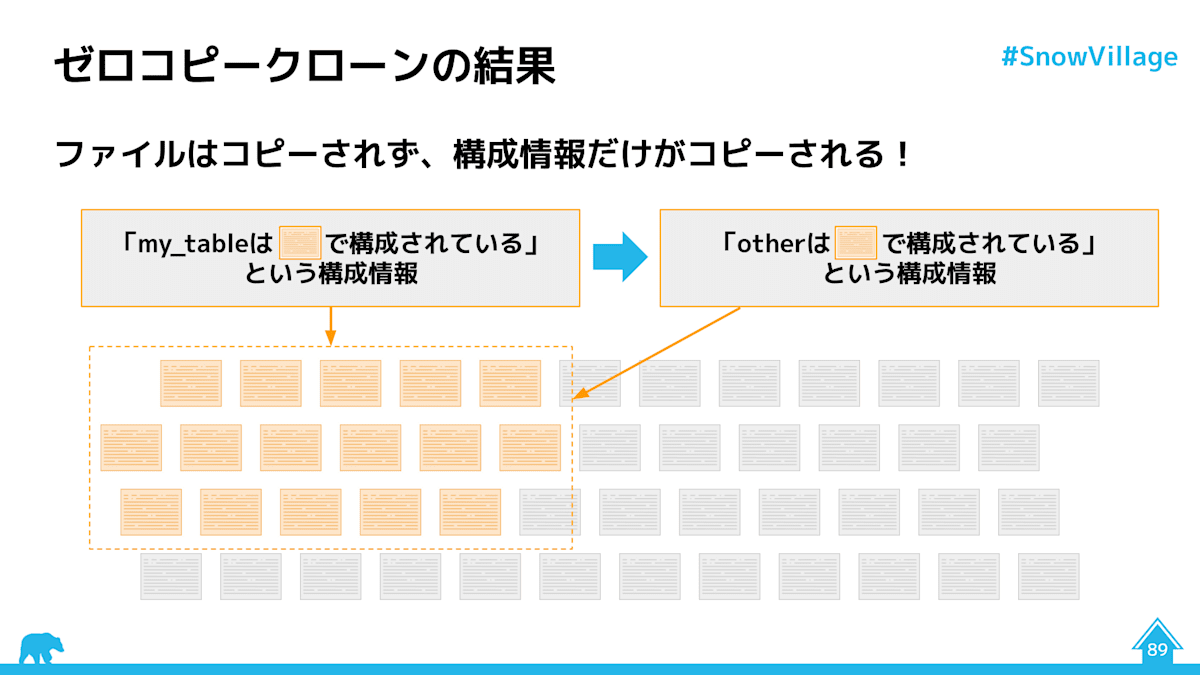
https://docs.google.com/presentation/d/1PabfRSyOzNaQ2Anr2Zimaio2KrYiqZidhRpsxcWfk4A/edit#slide=id.p より
マイクロパーティションやその周辺、そしてゼロコピークローンについては Data Superhero である酒徳さんが上記の資料で様々な図とともに非常にわかりやすく解説してくださっています。こちらも併せて是非ご覧ください。
Iceberg との類似性
Iceberg はデータファイルとメタデータファイルを分離して管理し、メタデータファイルに適切な階層を用意しておくことで様々な便利な機能を実現可能にした OTF です。Iceberg 自体の詳細は以下などをご覧ください。
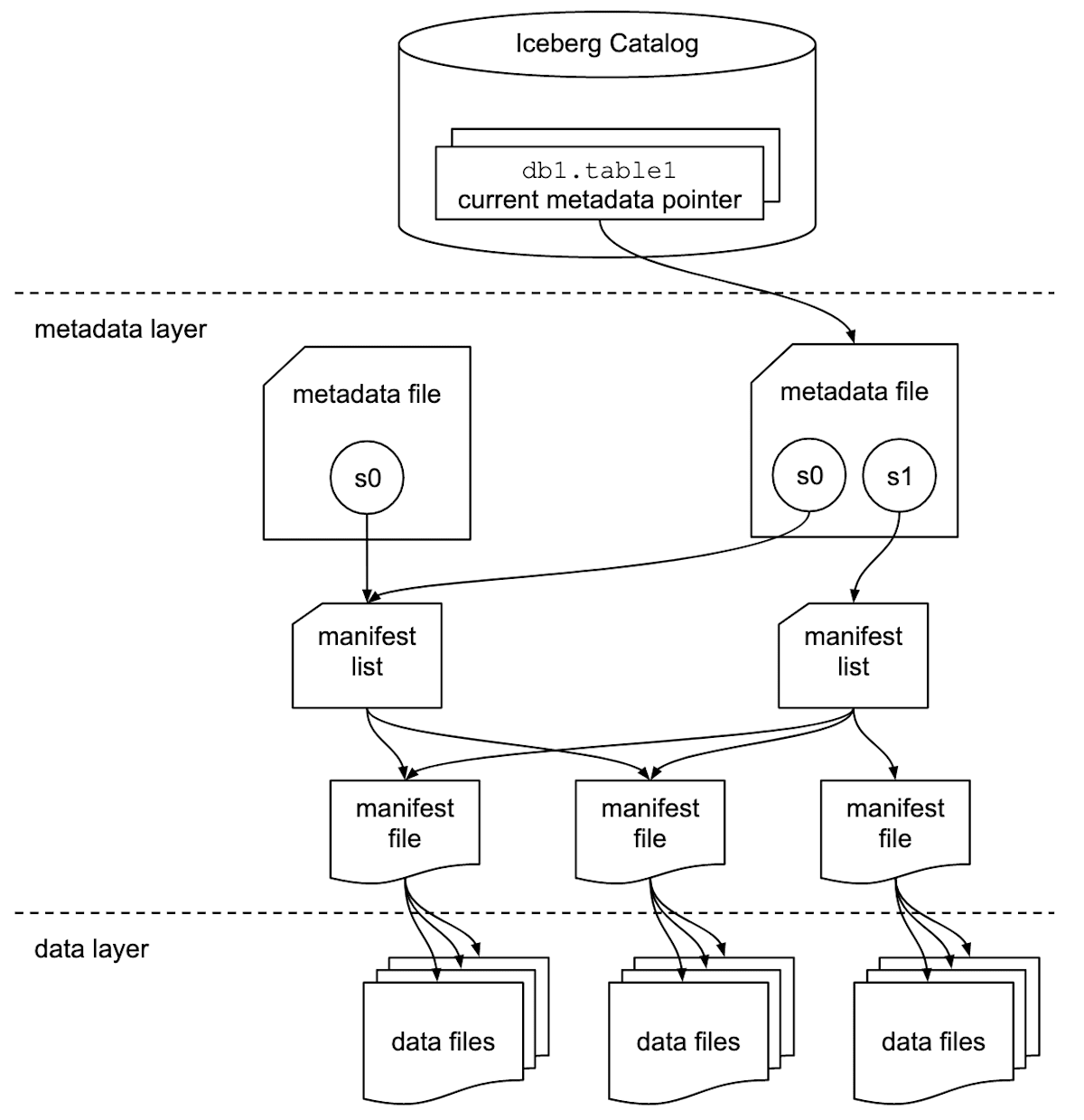
https://iceberg.apache.org/spec/#overview より
このようなアーキテクチャにより、 ACID Transaction や Time travel そして Branching や Rollback といった特性・機能が実現されています。Snowflake のテーブルもこれらの特性・機能は実現されています。データの構造的にも、以下の通り類似性があります。
- Iceberg も Snowflake もデータとメタデータは分離されている
- データの管理方法
- Iceberg では Parquet などのデータファイルが S3 などで永続化されており、データファイルはイミュータブルに管理される
- Snowflake ではマイクロパーティションが S3 などで永続化されており、マイクロパーティションはイミュータブルに管理される
- メタデータの管理方法
- Iceberg では階層を持ったメタデータファイルが S3 などで永続化されている
- Snowflake では Foundation DB で永続化されている
このように類似点が多いため、Icebergのアーキテクチャや仕組みを踏まえつつ、Snowflakeの裏側を想像するとしっくりくることが多いなと思っています。今回題材にしているゼロコピークローンはデータファイル(マイクロパーティション)はコピーせず、それを参照するメタデータだけ新たに作成していると考えることできます。
もちろん実際には Snowflake のゼロコピークローンはテーブル以外の様々なオブジェクトのクローンにも対応しており、 Iceberg との類似性だけで全てを理解できるわけではないです。しかしメインのユースケースと考えられるテーブルのクローンに関しては Iceberg の知識は良い示唆を与えてくれるのではないかと考えています。
具体例
クローンされたオブジェクトは書き込みが可能で、クローン元のオブジェクトとはマイクロパーティションは共有しているものの独立しています。そのため、クローン先のオブジェクトになんらかの変更を加えてもそれはクローン元のオブジェクトには何ら影響はなく、その逆も同様です。これを具体的に確認してみましょう。
Clone の実行
まず元のテーブルを作っておきます。
create or replace table original_table (id int, code varchar, name varchar) as
select seq8(), 'code-' || seq4()%2, randstr(10, random())
from table(generator(rowcount => 1000000));
original_table の code 列は code-0 か code-1 のどちらかの値をとります。
まずは original_table をクローンし cloned_table を作成しましょう。これは1秒程で完了するはずです。
create or replace table cloned_table clone original_table;
また、 Query Profile を確認すると "CREATE TABLE" のみで、 Warehouse も使わずに実行されていることがわかります。
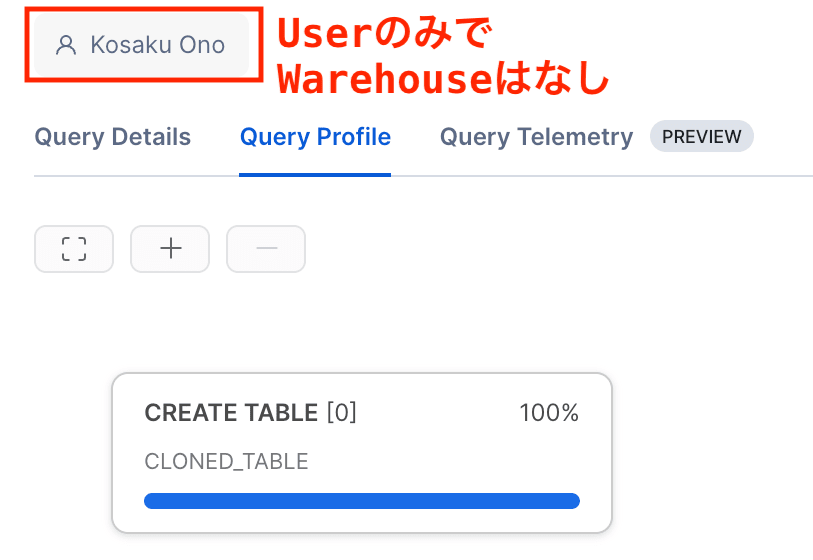
Query Profile には warehouse の名前が表示されていない
比較として直接 original_table を CTAS でコピーしてみましょう。こちらは Small の Warehouse で数秒程度はかかりました。
create or replace table copied_table as (
select * from original_table
);
クローン元とクローン先の独立性
クローン先の cloned_table に insert してみてそれがクローン元の original_table に影響がないことを確かめてみましょう。
insert into cloned_table(id, code, name)
select seq8(), 'code-2', randstr(10, random())
from table(generator(rowcount => 100000));
select code, count(*) as count from original_table
group by code order by code;
-- code は `code-0` / `code-1` の2つのまま
select code, count(*) as count from cloned_table
group by code order by code;
-- code は `code-0` / `code-1` / `code-2` の3つ
次にクローン元の original_table から code-0 のレコードを削除して、それがクローン先の cloned_table に影響がないことも確かめてみましょう。
delete from original_table
where code = 'code-0';
select code, count(*) as count from original_table
group by code order by code;
-- code は `code-1` のみ
select code, count(*) as count from cloned_table
group by code order by code;
-- code は `code-0` / `code-1` / `code-2` の3つのまま
最後に元のテーブル original_table 自体を削除してしまっても、それがクローン先の cloned_table に影響がないことも確かめてみましょう。
drop table original_table;
select code, count(*) as count from cloned_table
group by code order by code;
-- code は `code-0` / `code-1` / `code-2` の3つのまま
考慮事項
ここまで見てきたようにゼロコピークローンは便利な機能なのですが、様々な考慮事項がありいくつか紹介しようと思います。
詳細は以下のドキュメントをご覧ください。
権限について
データベースやスキーマをクローンした場合、その中のオブジェクトは再帰的にすべてクローンされます。その際に子オブジェクトに関しては、クローン元の権限は継承したままクローンされます。
例えばあるスキーマをクローンすると、その中のテーブルも合わせてクローンされますが、このテーブルの Ownership はクローン元のテーブルの設定がそのまま引き継がれるわけです。
このあたり含めて事前に権限設定もしておくか、クローン後に Ownership を移譲するといった作業が必要になるので注意しましょう。
対象オブジェクトについて
データベースやスキーマをクローンした場合、その中のオブジェクトは再帰的にすべてクローンされますが、内部ステージは対象外なので注意してください。
ユースケース
複数環境作成
Prod 運用しているテーブルに何か変更を加えたい時に、まず Dev 環境を作りそこで作業したいというユースケースはよくあると思います。この際に Prod のテーブルをゼロコピークローンすることで Dev のテーブルをすぐに用意できます。
また CI でデータを利用したテストをしたいような場合にもゼロコピークローンは有用です。CI専用のデータベースやスキーマを本番環境のデータからゼロコピークローンして作成することで、短時間でCI専用の環境を用意することができます。
これらのように、複数環境を作成し安全にデータパイプラインの開発を進めたいケースにおいて、新しい環境を作る際にゼロコピークローンは最適です。短時間でストレージコストも抑えながら複数の環境を用意が可能になります。
WAP パターン
Write-Audit-Publish パターンと呼ばれるデータパイプラインの設計手法があります。
端的にいうと Git ライクにデータを取り扱い、
- prod から dev ブランチを作る
- 新しいデータは dev ブランチに書き込む
- 新しいデータを含む dev ブランチのテーブルに対し品質チェックのテストを行う
- テストが通れば dev ブランチを prod ブランチに fast-forward マージする
というような手順を追うことで prod ブランチの品質を担保するというものです。
以下の通り、 Iceberg の文脈などでよく取り上げられます。
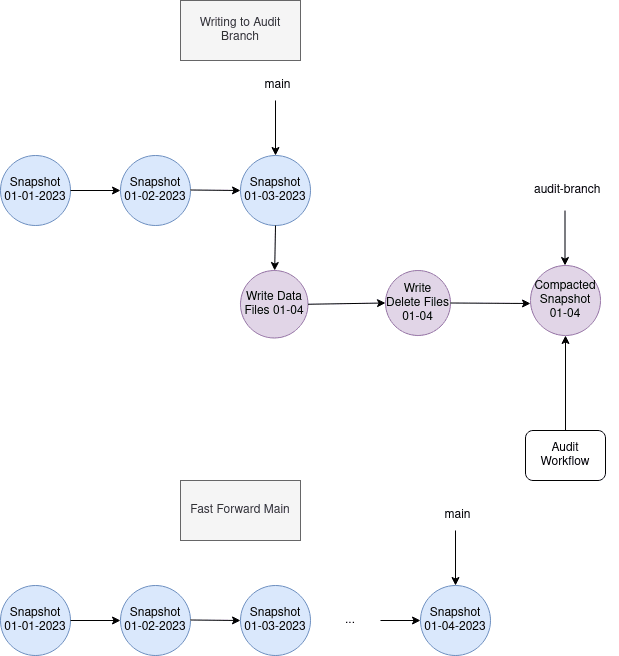
https://iceberg.apache.org/docs/latest/branching/#audit-branch より
Snowflake のゼロコピークローンはまさに Git のブランチのようにデータを取り扱うことが可能になるため、このようなパターンの実装を低コストで行うことができます。
- prod テーブルから dev テーブルをゼロコピークローンで作成する
- dev テーブルに対しデータを書き込む
- 新しいデータを含む dev テーブルに対し品質チェックのテストを行う
- テストが通れば dev テーブルから prod テーブルをゼロコピークローンで上書きする
ナウキャストでもこれと同様にゼロコピークローンを取り扱うことで、コスパよくデータ品質を担保したデータパイプラインの作成を行っています。
スナップショット
ゼロコピークローンをスナップショット的に使うことも可能です。過去データに対して変更が起きないようなテーブルであればゼロコピークローンでスナップショットとしてテーブルを作っておくと、ストレージを無駄に重複させずに過去の断面を保持することができるようになります。
終わりに
Snowflake のゼロコピークローンについて確認してきました。実際に使う際には細かい注意点もありますが、うまく利用できると非常に強力な機能です。是非皆さんもゼロコピークローンが使えるユースケースがないか探してみてください!

Discussion