はじめに
こんにちは!ナウキャストのデータエンジニアのけびんです。
Data Cloud Summit 2024 にて Iceberg Table が GA となること、また Polaris Catalog が発表されました。大々的に発表されたので気になっているものの、詳細を知らない方も多いのではないでしょうか?
自分もその一人だったので、本記事では改めて Apache Iceberg とは何かというところからまとめていきます。もし誤りなどあれば教えていただけますと幸いです。
Table Format とは
Apache Iceberg とは大規模な分析データ向けの Open Table Format で、 Snowflake の Iceberg Table はこれを使用したテーブルということになります。Iceberg を深掘る前にそもそも Table Format とは何でしょうか?
Table Format とはファイルを管理・編成そして追跡し、テーブルを構成する方法のことです。関連する用語と並べて見ることで分かりやすくなると思います。
| Data Lakehouse の関連要素 | 具体例 |
|---|---|
| Compute Engine | Spark / Presto / Hive / Snowflake など |
| Table Format | Iceberg / Delta Table / Hive format など |
| File Format | CSV / Avro / Parquet / ORC など |
| Object Storage | AWS S3 / GCS / Azure Storage など |
Data Lakehouse としてなんらかの Object Storage に適当な File Format でデータを配置するだけではテーブルとしては機能しません。物理的な個々のファイルをどのように利用することでテーブルとして理解できるか、ここの方法が大事であり、これが Table Format です。物理的なデータの File Format と実際の構造化されたテーブルとの間に存在する抽象的なレイヤと考えることができます。
Iceberg は新しい Table Format の一つというわけです。
Hive Format の構造
Table Format の具体例として Hive Format を見てみましょう。 Amazon Athena などで利用したことがある人も多いのではないでしょうか?以下のサンプルのように Hive Format ではデータをディレクトリ構造で整理し、それぞれのパーティションに基づいて必要なファイルのみ読み込むように Pruning ができるようになっているのがポイントです。S3などのストレージにデータを綺麗に配置することである種のインデックスを作成することができるわけです。
/hive/warehouse/sample_table
├── date=2024-01-01/
│ ├── category=CatA/
│ │ ├── file1
│ │ └── file2
│ └── category=CatB/
│ └── file3
├── date=2024-01-02/
│ ├── category=CatA/
│ │ └── file4
│ └── category=CatB/
│ ├── file5
│ └── file6
...
Hive Format の場合、一度テーブルを作る(ファイルを配置してしまう)とパーティションは変更できなかったり、ディレクトリ内のすべてのテーブルをリストする必要がありパフォーマンスに優れない、などといった問題がありました。
Iceberg の構造
Hive Format などで知られていた問題に対処したり、クラウド全盛の時代に大規模なデータ分析に対処するために Iceberg は改めて設計されました。そんな Iceberg は具体的にどのようにデータを編成するのかを見てみましょう。
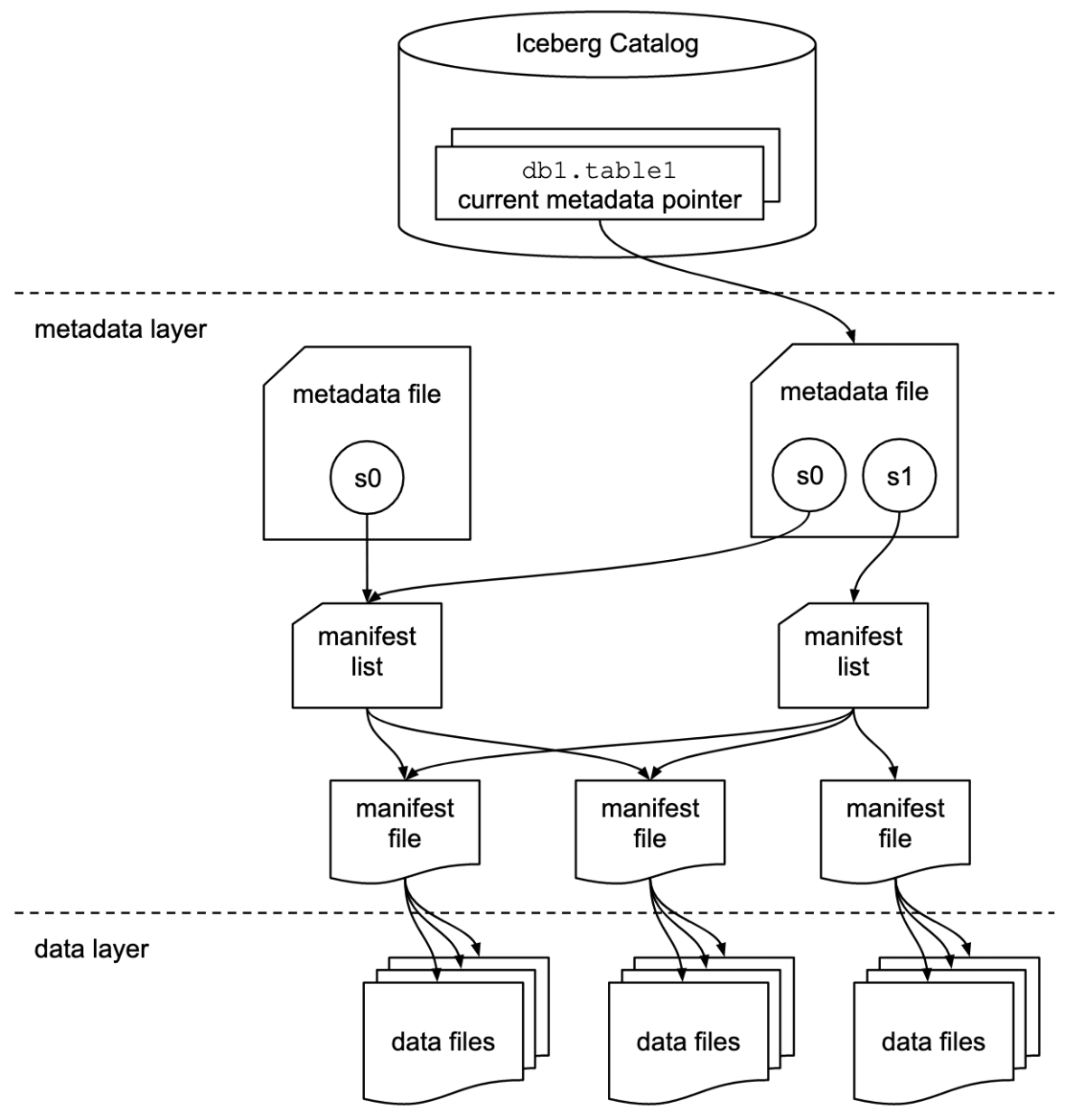
https://iceberg.apache.org/spec/#overview より
3つのレイヤーから構成され、いくつかの種類のファイルが存在します。
- first layer
-
Iceberg Catalog
- テーブルの生成・削除・リネームといった情報を管理する
- テーブルの対応する metadata file がどれかを追跡するのが一番重要な責務
-
Iceberg Catalog
- metadata layer
- metadata file
- テーブルの状態を表し、スキーマやパーティションの情報を持つ
- スナップショットのような形でテーブルの設定・データに変更があると新しく作成される
- manifest のパスの情報も持つ
- manifest list / manifest file
- 紐づいている data file のパーティションデータやその様々なメトリック・統計情報など
- data file のパスの情報も持つ
- immutable な avro 形式のファイル
- metadata file
- data layer
- data files
- 物理的なデータファイルで、Parquet/ORC/Avro のどれか
- immutable に管理される
- data files
それぞれ見ていきましょう。まず大事なポイントは、データファイルの整理の仕方です。 Hive Format では適切にディレクトリ構造を作っていましたが、 Iceberg では個々のデータファイルをメタデータを記録したファイルたちを適宜利用して追跡します。
またメタデータのファイルたちはツリー構造で永続化されており、効率よくテーブルのスナップショットを管理できるようになっています。これにより後述の様々な特徴を実現しています。
Iceberg Catalog について
Iceberg Catalog の一番重要な責務は、テーブルの対応する metadata file がどれかを追跡する( metadata へのポインタを保持する)ことです。これによりコンピュートエンジンはテーブルの管理とロードが可能になります。また現在指しているポインタを atomic に切り替えることで様々な利点を保証します。
Iceberg Catalog の詳細については以下をご覧ください。
Iceberg の特徴
先ほど見た Iceberg の構造により、様々なメリットが存在します。
in-place table evolution
まずは in-place table evolution です。単に Schema Evolution や Partition Evolution などということもあります。
Hive Format によるテーブルの時にはテーブルのスキーマやパーティションなどを変更するためには、新しいテーブルとしてデータを配置しなおしたりする必要がありましたが、 Iceberg を利用したテーブルの場合直接変更を加えることができます。
テーブルの設定に何らかの変更を加えると、新しい metadata file が作られ、適宜 manifest も編成されます。つまり直接 data file に変更を加えるわけではないのでパフォーマンスも良いはずです。
またたとえば複数の metadata や manifest をおいておくことも可能なため、後から partition を追加したり、データを絞り込む時に複数の種類の partition を利用することも可能です。
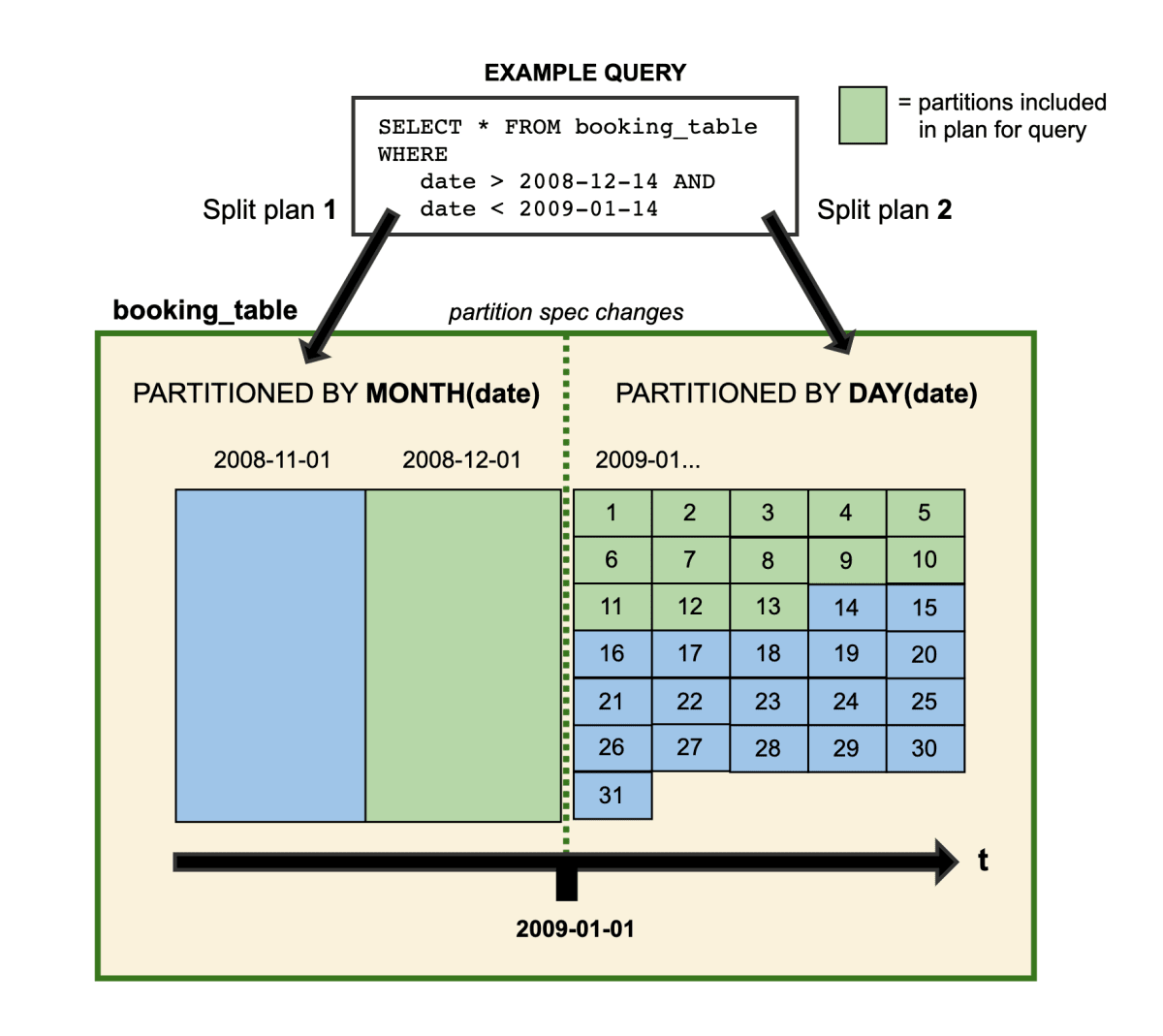
https://iceberg.apache.org/docs/latest/evolution/#partition-evolution より
具体的にどのような進化がサポートされているかはこちらをご覧ください。
ACID 特性をサポート
テーブルに変更が加えられるとスナップショットを撮るような形で新しく metadata file が作られます。この新しい metadata file が古いものと atomic に交換されるようになっていたり、ファイルの読み書きの分離性を保証する形で実装されています。こういった工夫により Iceberg を利用したテーブルは ACID 特性を持つことが可能になっています。より細かい部分については以下のブログを参照ください。
Time Travel
ACID特定の部分と同様、スナップショット方式でかつ data files や manifest files は immutable に管理されており、必要に応じて過去時点のデータを復元したりクエリすることも可能になっています。
これら以外にも様々な利点があるようです。最新のフォーマットなのでよく考えられていますね。
Snowflake Iceberg Table について
Snowflake Iceberg Table には Snowflake を Catalog に使うかどうかで大きく分けて以下の2種類に分かれます。
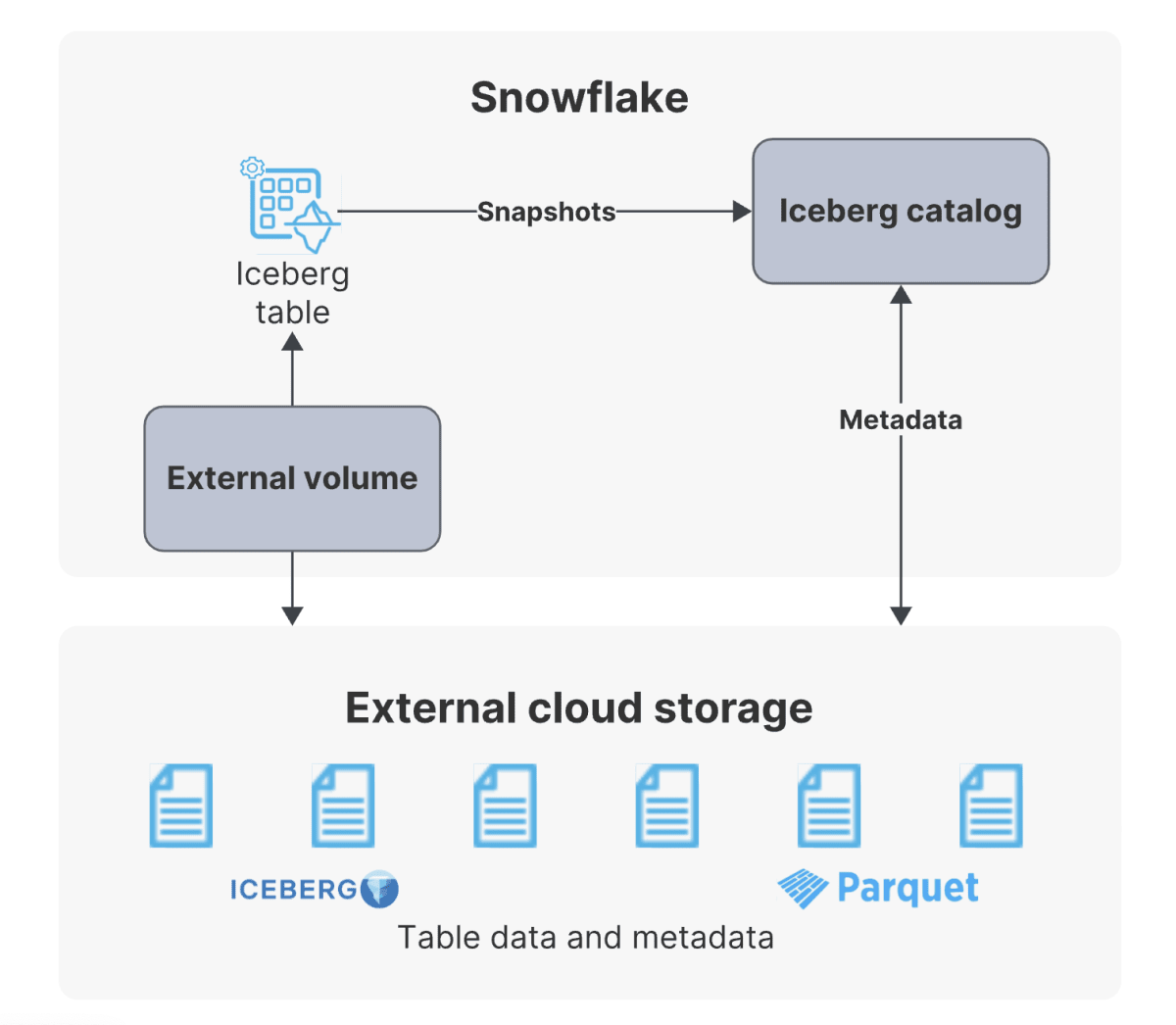
https://docs.snowflake.com/ja/user-guide/tables-iceberg#use-snowflake-as-the-iceberg-catalog より
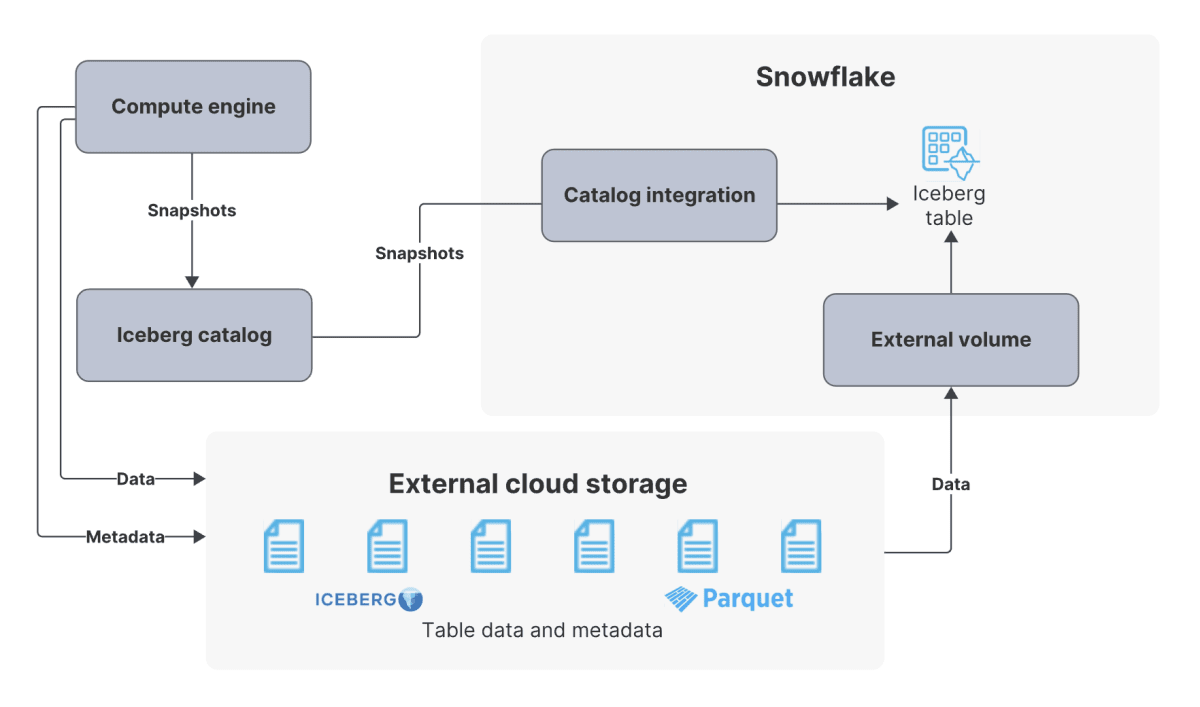
https://docs.snowflake.com/ja/user-guide/tables-iceberg#use-a-catalog-integration より
外部カタログとしては AWS Glue などが設定可能です。
これらを比較すると以下のような違いがあります。
| ポイント | Snowflake catalog | iceberg catalog |
|---|---|---|
| Storage | Cloud Storage | Cloud Storage |
| Read access | ⭕️ | ⭕️ |
| Write access | ⭕️ | ❌ |
| Full Snowflake platform support | ⭕️ | ❌ |
どちらもファイルはS3などの自前のクラウドストレージに置くことになりますが、WriteはSnowflakeをカタログに使わないとできません。またSnowflakeをカタログにした方がSnowflake platformの力をフルに使うことができるのでパフォーマンスも良いようです。
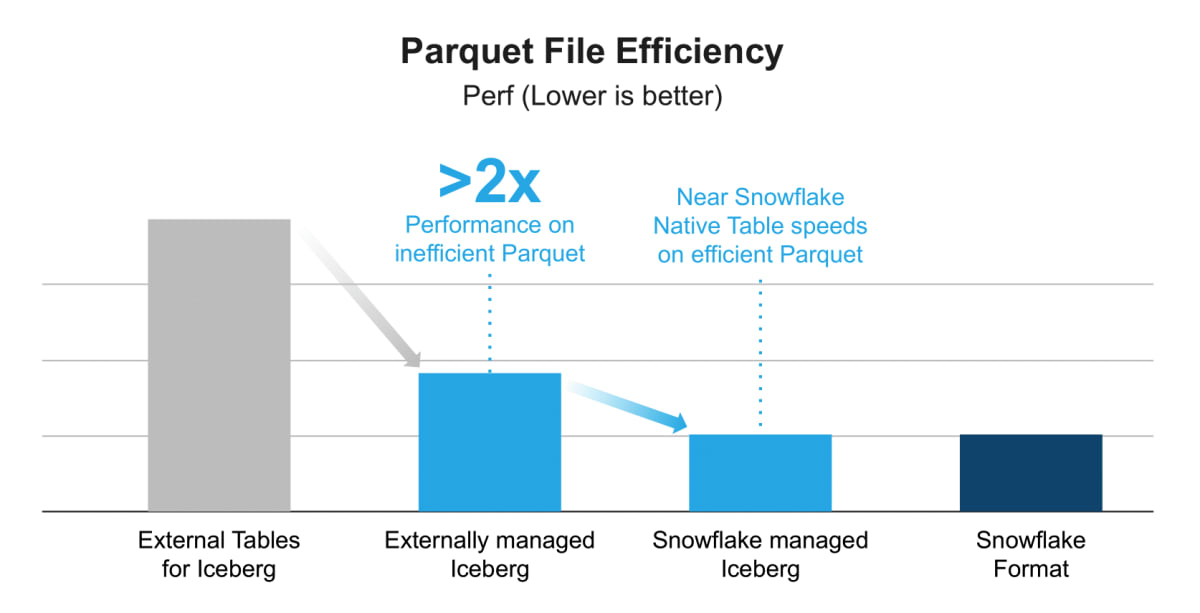
https://www.snowflake.com/blog/unifying-iceberg-tables/ より
Catalog の問題点と Polaris Catalog
Iceberg はオープンな Table Format で、 Compute Engine と組み合わせて Data Lakehouse として機能するわけですが、オープンであるにもかかわらず、 Iceberg Catalog と Compute Engine との間で相互依存する多くの制約があるというのが現実になっていたようです。
相互運用性を高めベンダーロックインに伴う潜在的なリスクを軽減するためにも Snowflake は Polaris Catalog という名の Iceberg Catalog を発表しこれを近々オープンソースとすることも述べています。このようなオープンソースのカタログにより具体的には以下のようなメリットが生まれます。
- 複数の Compute Engine やカタログのためにデータを移動・コピーしておく必要はなくなります。どこかのクラウドストレージ1箇所にデータを配置しておき、 Polaris Catalog をホストしておけば、どんな Compute Engine もこのカタログとストレージを参照して相互運用することが可能
- Polaris Catalog は Snowflake managed なインフラでホストしたものを利用することも可能ですし、自分たちのインフラでセルフホストすることも可能
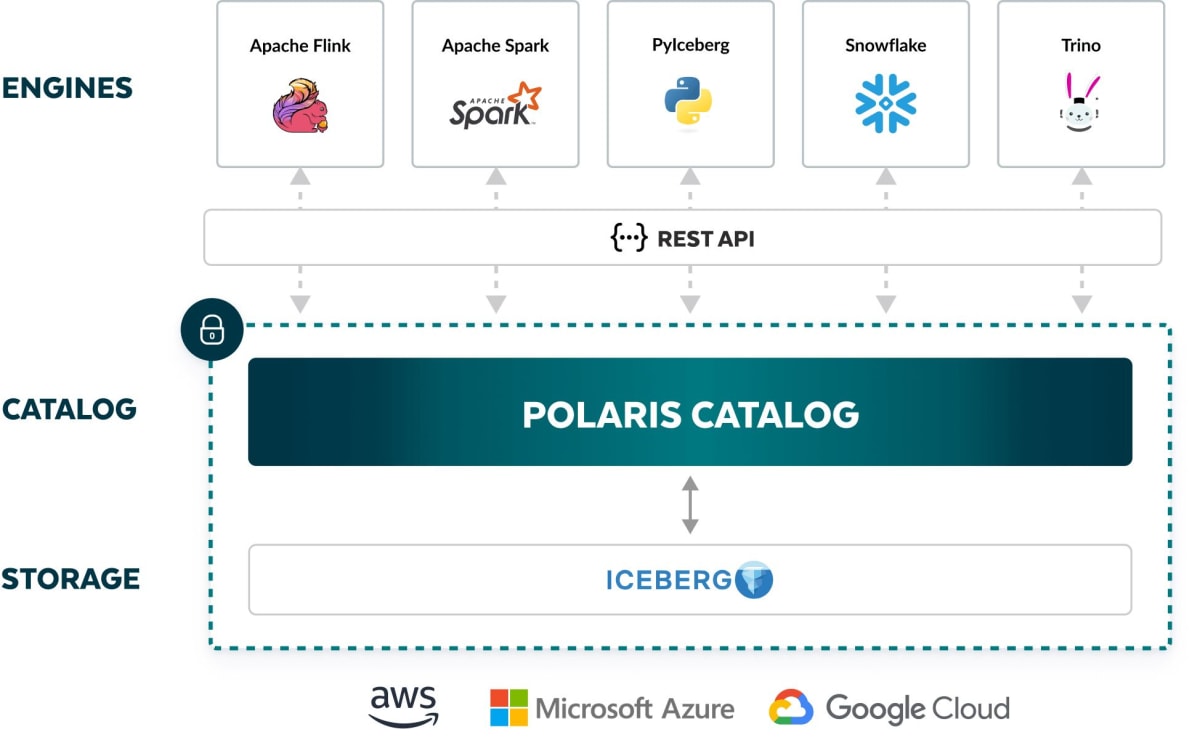
https://www.snowflake.com/blog/introducing-polaris-catalog/?lang=ja より
まとめ
本ブログでは Table Format とは何か、 Iceberg はどのような仕組みでどのようなメリットがあるのか、そして Polaris Catalog についてみてきました。サミットでも様々なセッションがあったので、今後もっと盛り上がっていきそうな予感です!
一部の機能はまだPreviewだったりこれからPreviewなものもあるので動向を見守っていきましょう!
References
Snowflake blog
その他

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion