はじめに
こんにちは、株式会社ナウキャストの松村です。Snowflake Summit 2025で開催されたハンズオン「Build and Deploy Visual Language Models for Unstructured Data Processing」に参加しました!
このハンズオンでは画像・動画・音声といった非構造化データの解析と、解析データに対して自然言語で分析クエリを生成するチャットボットの作成を体験しました。サミット2日目のPlatform Keynoteで発表されたCortex AISQLに加えて、Snowpark Container Services (以下SPCS) やCortex Analyst・Streamlitと、Snowflakeの複数の機能を体験できるハンズオンでした。
セッション基本情報
- セッション名:Build and Deploy Visual Language Models for Unstructured Data Processing
- 登壇者:
- Yavor Georgiev (Product Manager, Snowflake)
- Seth Mason (Sr. Product Manager, Snowflake)
- 実施日時:Thursday, Jun 5 | 10:00 AM - 11:30 AM PDT
ハンズオン概要
このハンズオンでは、シミュレーション会議データセットAMI Corpusを使用して、以下のステップで非構造化データ処理を実施しました。
実施内容
Step 1. 会議動画の意味解析
VLM(Visual Language Model)をSPCSを使ってSnowflake 上でコンテナとして実行し、動画内容をテキスト化
Step 2. スライド画像のOCR(光学文字認識)
Cortex AISQLの PARSE_DOCUMENT関数を使用してスライド画像をテキスト化
Step 3. 会議音声のASR(音声認識)
Cortex AISQLの AI_TRANSCRIBE関数を使用して会議音声を文字起こし
Step 4. チャットボット構築
Cortex AnalystとStreamlitを使用して、Step1~3の解析データをもとに自然言語で分析ができるUIを作成

Cortex AISQLとは
SQLコマンドでテキストや画像などの多様なデータ(マルチモーダルデータ)の処理ができる機能です。弊社メンバーによる詳細な解説記事もあるのでぜひご覧ください。
Snowpark Container Services (SPCS)とは
Snowflakeが提供するフルマネージドコンテナランタイムサービスです。従来のSnowflakeではSQL中心の処理が主流でしたが、SPCSによりPythonやその他の言語で書かれた複雑なAI/MLワークロードをSnowflake内で直接実行できるようになりました。
各Stepの詳細な手順は下記のQuickStartsで確認できます。 セッション参加時はハンズオン用のSnowflakeアカウントが配布されており、コンテナが初期デプロイ済だったため、手順に記載されているコンテナデプロイはスキップしました。
ハンズオンで使用したGitHubリポジトリも公開されています。
project-root/
├── run.sql # ハンズオン時に実行するSQLスクリプト
├── videos/
│ └── amicorpus/IS1004/ # 会議データ一式
│ ├── audio/ # ASR対象の音声ファイル (*.mp3)
│ ├── slides/ # OCR対象のスライド画像 (*.jpg)
│ └── video/ # VLM分析対象の動画ファイル (*.mp4)
├── chatbot/
│ ├── meeting_analysis.yaml # Cortex Analystのセマンティックモデル設定ファイル
│ └── streamlit_app.py # チャットボットアプリ
└── video_analysis/ # VLM分析用のコンテナ
├── Dockerfile
├── entrypoint.sh
└── run.py # VLM分析のメイン処理
ハンズオン内容詳細
事前準備
-
Hugging FaceでRead権限のアクセストークンを発行

-
Worksheets上で、run.sqlの「COMMON SETUP」部分を実行し、必要なリソースを作成
- ロール:
hol_user_role - データベース:
hol_db - ウェアハウス:
hol_warehouse - コンピュートプール:
hol_compute_pool(GPU_NV_M インスタンス) - 外部アクセス統合:
dependencies_access_integration
- ロール:
-
ローカルファイルをSnowflakeステージにアップロード
- 会議データ:
@videos/amicorpus/IS1004/ - セマンティックモデル:
@model/meeting_analysis.yaml

- 会議データ:
Step1: 会議動画の意味解析
VLM(Visual Language Model)をSPCSを使ってSnowflake上でコンテナとして実行し、動画ファイル(.mp4)の内容をテキスト化します。
SPCSの実行環境:
- Hugging FaceのVision Language Modelの1つであるQwen2.5-VL-7B-Instructを使用
- Snowflakeステージを直接コンテナ内で利用 (
volumeMountsで設定) - 4つのGPUを使用した並列処理(
nvidia.com/gpu: 4)
実行SQL:
EXECUTE JOB SERVICE
IN COMPUTE POOL hol_compute_pool
ASYNC=TRUE
NAME = process_video
EXTERNAL_ACCESS_INTEGRATIONS=(dependencies_access_integration)
FROM SPECIFICATION_TEMPLATE $$ ... $$
USING(id=> $meeting_id, part=> $meeting_part);
実行前に以下の設定が必要です:
-
image: <image>:<version>- イメージレポジトリから取得 -
HF_TOKEN: <your_hf_token>- 事前準備で取得したHugging Faceアクセストークン
下記のSQLを実行することでイメージレポジトリが確認できます。
SHOW IMAGE REPOSITORIES IN SCHEMA spcs_db.public
SHOW IMAGES IN IMAGE REPOSITORY spcs_db.public.model_repo;
JOBの実行には10分弱かかり、結果はvideo_analysisテーブルに格納されます。処理中はSnowsightでジョブの実行状況をリアルタイムで監視できます。

実行結果:
動画ファイル IS1004c.C.mp4を対象に分析
video_analysis テーブル
| MEETING_ID | MEETING_PART | START_TIME | END_TIME | DESCRIPTION |
|---|---|---|---|---|
| IS1004 | IS1004c | 0:00:00 | 0:00:21 | The video opens with a group of four individuals entering a room equipped with a large screen displaying a presentation titled "Conceptual Design Meeting." |
| IS1004 | IS1004c | 0:00:21 | 0:01:45 | The group continues their discussion, focusing on the content displayed on the screen. The screen shows a slide titled "Method" with bullet points about user preferences and constraints. |
| IS1004 | IS1004c | 0:01:45 | 0:03:09 | The screen transitions to a slide titled "Findings," listing various aspects such as user preferences, device requirements, and design constraints. |
| IS1004 | IS1004c | 0:03:09 | 0:04:58 | The screen changes to a slide titled "Interface Concept," which includes a diagram and text discussing the design model and technology. |
| IS1004 | IS1004c | 0:04:58 | 0:06:57 | The screen displays a slide titled "Method" again, listing steps for the next phase of the project. The group continues their discussion. |
テーブル1行目のDESCRIPTIONの内容は4人の人物が「Conceptual Design Meeting」と題されたプレゼンテーションが表示された大型スクリーンのある部屋に入る場面から始まるとなっており、動画ファイルの内容と一致していることが確認できます。

IS1004c.C.mp4 0:00:17
Step2: スライド画像のOCR(光学文字認識)
Cortex AISQLのPARSE_DOCUMENT() 関数を使用し、スライド画像ファイル(.jpg)から文字情報を抽出します。
実行SQL:
INSERT INTO slides_analysis
SELECT
$meeting_id as meeting_id,
$meeting_part as meeting_part,
relative_path AS image_path,
CAST(SNOWFLAKE.CORTEX.PARSE_DOCUMENT(
@videos,
relative_path,
{'mode': 'LAYOUT'}
):content AS STRING) AS text_content
FROM DIRECTORY(@videos)
WHERE relative_path LIKE CONCAT('amicorpus/', $meeting_id, '/slides/%.jpg');
PARSE_DOCUMENT() 関数のデフォルトのモードはOCRでレイアウト情報が無視されたプレーンテキスト形式の出力になります。LAYOUTモードにすることでレイアウト保持型の文書解析になり、Markdown形式で構造化されたテキストが出力されるため、表やリストが多く含まれるスライド画像の処理に向いています。
実行結果:
スライド画像ファイル(.jpg)を対象に分析した際のslides_analysisテーブル(一部抜粋)

解析結果はMarkdown形式で出力されており、実際のスライド内容だけでなくPowerPointのUI要素や背景アプリケーション情報も含まれています。
テーブル1行目の IS1004c.1.34__72.51.jpg のTEXT_CONTENTには、スライド画像に記載されている、Real Reaction We put fashion in electronicsなどのテキストが含まれていることが確認できます。
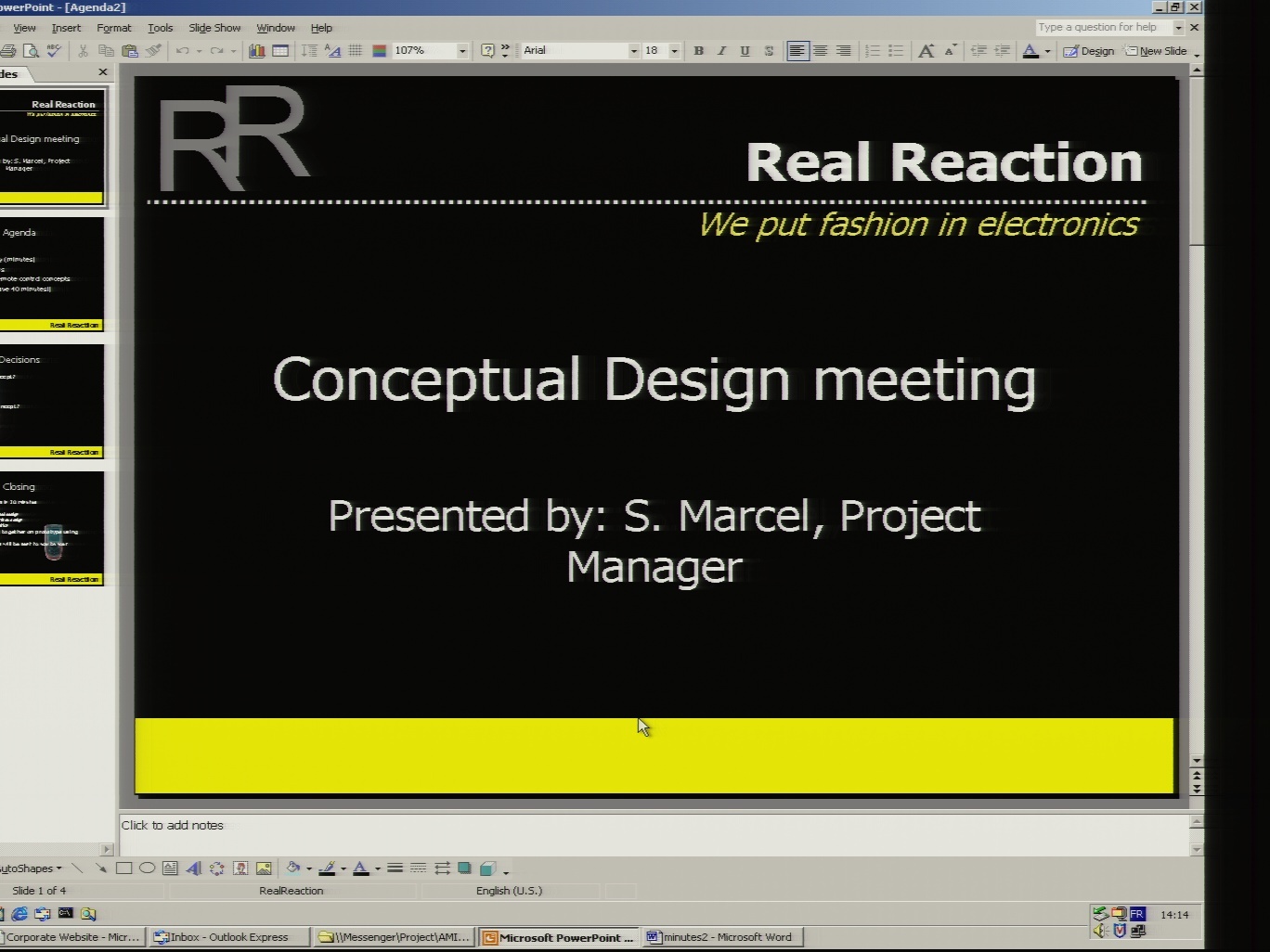
IS1004c.1.34__72.51.jpg
Step3: 会議音声のASR(音声認識)
Cortex AISQLの AI_TRANSCRIBE関数を使用し、音声ファイル(.mp3)を文字起こしします。
実行SQL:
INSERT INTO speech_analysis
SELECT
$meeting_id as meeting_id,
$meeting_part as meeting_part,
$audio_path AS audio_path,
CAST(SNOWFLAKE.CORTEX.AI_TRANSCRIBE(TO_FILE($audio_path)):text AS STRING) AS text_content
実行結果:
speech_analysisテーブル
| MEETING_ID | MEETING_PART | AUDIO_PATH | TEXT_CONTENT |
|---|---|---|---|
| IS1004 | IS1004c | @videos/amicorpus/IS1004/ audio/IS1004c.Mix-Lapel.mp3 |
Okay, good afternoon. Hope you have good lunch. Yeah, we had falafel. Oh, nice. And you? Uh, yes, I had something similar, but non-vegetarian. Okay, so today is our third meeting. It will be about the conceptual design. Uh... If I come back to the minutes of the last meetings, we decided not to go for speech recognition technologies because of some reasons and we were not decided about the use of LCD screen on the remote control because of costs. So maybe we could be able to clarify (以下省略) |
Step4: 自然言語で分析クエリを生成するチャットボットの作成
Cortex AnalystとStreamlitを使用して、Step1~3の解析データをもとに自然言語で分析ができるUIを作成します。
セマンティックモデル設定
meeting_analysis.yaml はCortex Analystのセマンティックモデル設定ファイルで、自然言語クエリをSQLクエリに変換するための詳細な定義が含まれています。
Step1~3での解析結果を持つ3つのテーブルについて、主要カラムやサンプルデータ、同義語が定義されています。
-
VIDEO_ANALYSIS: step1の会議動画解析結果 -
SLIDES_ANALYSIS: step2のスライド画像のOCR結果 -
SPEECH_ANALYSIS: step3の会議音声のASR結果
チャットボットの仕組み
streamlit_app.py がCortex Analyst を使用したStreamlitアプリケーションとして動作します。
- ユーザーの質問を受信
- Cortex Analystの
/api/v2/cortex/analyst/messageエンドポイントに送信 - セマンティックモデルに基づいてSQLクエリを生成
- SQLクエリを実行してデータを取得
- Claude-3.5-Sonnetで自然言語回答を生成
詳細手順
Projects > Streamlitから新規のStreamlit Appを作成します。
App locationでHOL_DBを選択するためには、事前にロールをHOL_USER_ROLEに変更しておく必要があります。

Packageメニューで、必要なパッケージのリストにsnowflake-ml-pythonを追加し、デフォルトで作成されるstreamlit_app.pyの内容をGithubリポジトリの内容に置き換えます。
Streamlit アプリを起動し、自然言語を投げると分析クエリが生成される様子が確認できました。

また、抽象的な質問を行うなどチャットボットが質問に答えられない場合は、より詳細な質問をするように促されます。

おまけ:日本語データで試してみた
日本語のデータも解析できるかが気になったので、日本語の動画・スライド画像・録音データを入れて検証してみました。
チャットボットの作成に関しては省略しています。
サンプルデータ
株式会社ナウキャスト主催のDataOps Night #7から3分程度(00:08:30 ~ 00:11:37)抜粋しました。
- 動画(.mp4):ハンズオンで使用したデータでは、会議室にいる参加者も映っていましたが、今回はスライド画像がメインで一部登壇者のカメラ画像が入っています。
- スライド画像(.png):日本語のスライド画像ですが、一部の英語の単語や固有名詞が含まれています。
- 音声(.mp3):全て日本語で発言しているデータになります。
実行結果
SQLで指定している、対象データのパスを一部変更して実施しました。
動画解析
解析処理をSnowflakeの機能で行っているわけではなく、VLMを呼び出して処理しているため、プロンプトを実行時に指定できます。
今回はプロンプトを下記のように変更しました。
Please provide detailed description of this meeting video in Japanese, dividing it into sections with one sentence description, and capture the most important text displayed on screen in Japanese. Identify the start and end of each section with timestamp in 'hh:mm:ss' format. Return the results as JSON.
この会議動画の詳細な説明を日本語で提供してください。各セクションに分けて一文で説明し、画面に表示される重要なテキストも日本語で記録してください。各セクションの開始時刻と終了時刻を'hh:mm:ss'形式のタイムスタンプで特定してください。結果はJSON形式で返してください。Please provide detailed description of this meeting video in Japanese, dividing it into sections with one sentence description, and capture the most important text displayed on screen in Japanese. Identify the start and end of each section with timestamp in 'hh:mm:ss' format. Return the results as JSON.
実行結果:
問題なく日本語でDESCRIPTIONが出力されました。動画内のスライドとも内容はあっていました。
| MEETING_ID | MEETING _PART |
VIDEO_PATH | START_TIME | END_TIME | DESCRIPTION |
|---|---|---|---|---|---|
| IS1004 | IS1004b | /videos/amicorpus/IS1004/ video/IS1004b.C.mp4 |
00:00.0 | 00:25.0 | 福井理弘氏が自身の経歴と趣味について紹介しています。 |
| IS1004 | IS1004b | /videos/amicorpus/IS1004/ video/IS1004b.C.mp4 |
00:25.0 | 00:40.0 | ナウキャスト会社の紹介と現状について説明します。 |
| IS1004 | IS1004b | /videos/amicorpus/IS1004/ video/IS1004b.C.mp4 |
00:40.0 | 01:00.0 | ナウキャストの組織構造を示しています。 |
| IS1004 | IS1004b | /videos/amicorpus/IS1004/ video/IS1004b.C.mp4 |
01:00.0 | 01:20.0 | データウェアハウスの機能と関連する企業を紹介しています。 |
| IS1004 | IS1004b | /videos/amicorpus/IS1004/ video/IS1004b.C.mp4 |
01:20.0 | 01:40.0 | ナウキャストの事業の拡張期について説明しています。 |
| IS1004 | IS1004b | /videos/amicorpus/IS1004/ video/IS1004b.C.mp4 |
01:40.0 | 02:00.0 | 複数データソースを名寄せシステムで管理する方法について説明しています。 |
OCR
PARSE_DOCUMENT() 関数には言語設定のオプションがないため、同じSQLを実行しました。
実行結果(一部抜粋):

スライド画像と比較すると、数字やアルファベット部分は検出できていますが、日本語は難しそうです。。

該当のスライド画像
ASR
OCRと同様に、AI_TRANSCRIBE() 関数には言語設定のオプションがないため、同じSQLを実行しました。
実行結果:
音声データはすべて日本語ですが、一部英訳された状態で出力されました。内容自体はおおむねあっているので、日本語と認識できているが、出力言語に明確な指定がないので英語と日本語が混じっていそうです。
| MEETING _ID |
MEETING _PART |
AUDIO_PATH | TEXT_CONTENT |
|---|---|---|---|
| IS1004 | IS1004b | @videos/amicorpus/ IS1004/audio/IS1004b.mp3 |
Let's get started. I have a few things to say before I start. I will introduce myself again. I am Fukui, a data engineer at Nowcast. I will explain a little later. (省略) I actually wanted to talk about something that came to my mind, but I couldn't because I had to go to the conference, so I hope I can talk about it again next time. So, this is my talk today. まずですね、Narcastの会社の紹介と現状というところについてご紹介させていただいて、次にちょっと本日メインの内容として増え続けるデータとどうNarcastが向き合っているかみたいなテーマですねここを名寄せっていうテーマにフォーカスして話していきます最後に締めとして最近直面しているチャレンジについて話していきたいなと思いますまずは会社の紹介ですねNarcastの事業構造としては大きく2つ事業がございます 左の箱のようにデータのプロダクトを提供するというデータサービスの事業と右のように顧客支援に特化するソリューション事業(以下省略) |
まとめ・感想
今回のハンズオンでは、Snowflakeの複数の機能を組み合わせることで、非構造化データを処理する一連のワークフローを体験することができました。
自分自身、Snowflakeを使い始めて日が浅く、Cortex AISQL・SPCS・Cortex Analyst・Streamlitに触れたことがなかったので、このハンズオンで各機能の使い方を学べたのはとても良い経験になりました。
また、Platform Keynoteで発表されたCortex AISQLについては、SQLのみで非構造化データを処理できるというSimpleさが印象的でした。一方で、言語設定や出力のカスタマイズにはまだ制限があり、実用レベルで使うには前後の処理を工夫する必要があると感じました。
今後もCortex AISQLをはじめとした非構造化データ処理に関する機能はどんどんアップデートされていくと思うので、注目していきたいです!
長くなりましたが、最後までご覧いただきありがとうございました!

Discussion