はじめに
こんにちは!ナウキャストのデータエンジニアのけびんです。昨年に引き続き今年も Snowflake Summit 2025 に参加しております。
3日目に "How Pfizer Saved 30% by Consolidating Snowflake Warehouses" というセッションに参加しました。ファイザーでは元々は部署ごとにウェアハウスを分けていたようなのですが、ウェアハウスを共有するように変更したそうです。これにより計算リソースの利用率が向上し、余分なウェハウスの稼働がなくなるためコスト削減に成功したという話で、非常に勉強になりました。
本ブログではこのセッションの内容に添いつつ、この原理を理解できるように解説していこうと思います。
セッション概要
- title
- "How Pfizer Saved 30% by Consolidating Snowflake Warehouses"
- summary
- As compute warehouses become more commonly used, they become more cost efficient. At Pfizer, business domains at first had their own compute warehouses, and distinct functions (such as ETL, reporting, etc.) within each domain had their own dedicated warehouses. Pfizer has since switched to one set of common warehouses, one of each size and a larger value for MAX_CLUSTERS so that the warehouse handles many concurrent queries. Learn how Pfizer has seen cost savings of 30% without any performance degradation by using this approach.
コスト最適化のポイント
ここはセッションにはなかった話なのですが、コスト最適化の全体感をまず整理したいと思います。 Snowflake でコストを最適化する方向性として大きく2つあります。
- ある単一のクエリの最適化をする
- 単一のクエリの効率が上がればウェアハウスの稼働時間も短くなり安くなる
- 具体例
- partition pruning の効率を見直す
- search optimization などを使う
- キャッシュを使えるように工夫する
- ウェアハウスの利用率を高める
- ウェアハウスでは複数のクエリが並列実行可能なため、単一ウェアハウスでなるべく多くのクエリを捌くことで、コスト効率が上がる
- 具体例
- ウェアハウスの共通化
- adaptive warehouse の利用
今回のファイザーのセッションで取り扱われていたのは後者の方向性でのコスト最適化でした。
Warehouse おさらい
まずは Snowflake の Warehouse の性質のおさらいをしましょう。
- Billing period
- ウェアハウスがアクティブでクエリを処理している間に課金される
- Auto Suspend でシャットダウンされるまでの間課金され続ける
- 1分以上、秒単位で課金される
- Query Processing
- 基本的にクエリは 8 並列できる
-
MAX_CONCURRENCY_LEVELで同時に並列実行できるクエリの数が制御できる - これのデフォルト値は8
-
- クエリに割り当てられる計算リソースはクエリの複雑性や上記のパラメーターに基づき決定される
- 並列実行のリミットに達すると、設定により追加のウェアハウスが起動されたり、クエリがキューに入ったりする
- 1つのウェアハウスで幾つの並列実行をしていても、そのクエリのコストは変わらない
- 基本的にクエリは 8 並列できる
ドメイン別WHから共有WHへ
ファイザーでは、商業・製造・人事など、部門ごとに別々のウェアハウスを用意する構成でした。ある部門専用のETLのウェアハウス、ある部門専用のレポートのウェアハウスといった形です。
例えば部門が3つあったとして、それぞれ Large のウェアハウスを使っているとします。3部門全てで何らかのクエリが実行されているとすると、以下のように1分あたりには $0.65 * 3 = $1.95 のコストがかかることになります。これは各ドメインのウェアハウスの計算リソースには余裕が残っている状態でもったいないです。
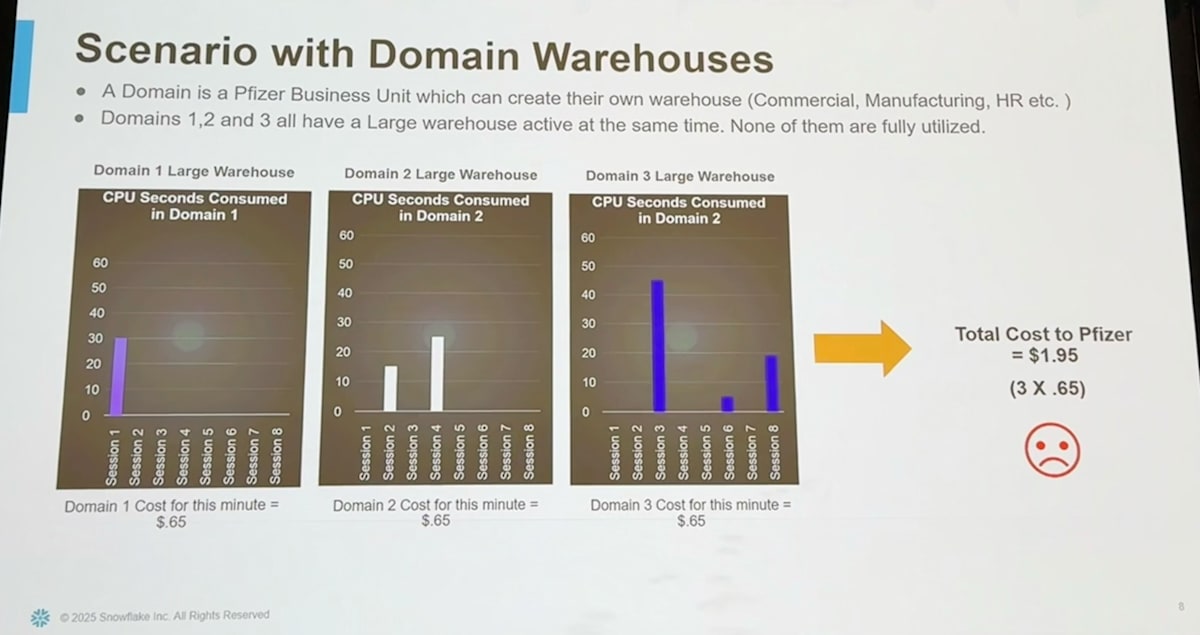
そこで以下のように3部門で共有された一つのウェアハウスだけがあるようにしてみましょう。すると3部門の8クエリを同時に処理できることになりますが、稼働しているウェアハウスは Large 1つのみとなるため、1分あたりのコストは $0.65 で済むことになります。
このようにウェアハウスを共有すると、単一のウェアハウスの計算資源を有効活用することができ余分なウェアハウスの起動を防げるため、コスト削減につながるというわけです。
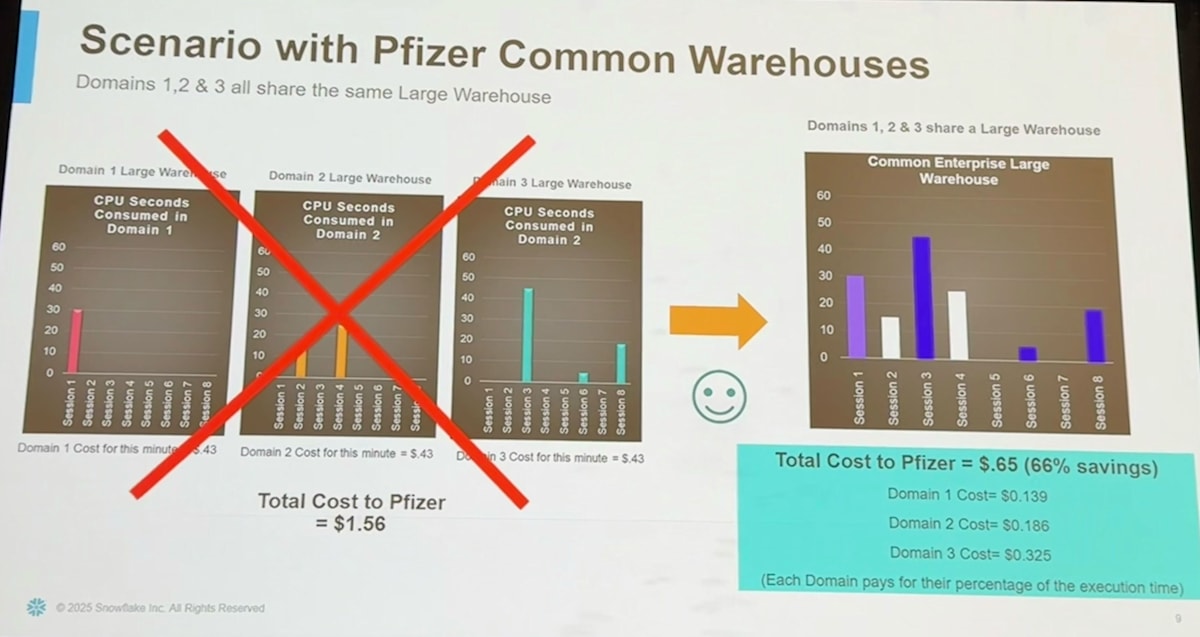
共有WHの整理
これまでを踏まえ、改めて共有ウェアハウスのポイントについて整理してみます。
- 1つのウェアハウスで1クエリしか実行していなくても、8クエリ並列実行していても、起動時間が同じであれば払う金額は一緒
- なるべく計算リソースの利用率を高めるために複数クエリ実行できるように、ウェアハウスを共有しておくのがお得という話
- 言い換えるとクエリを実行する時に、新しいウェアハウスを立てるよりも、既存のウェアハウスで実行してもらえた方がこの観点でお得
- あるクエリのパフォーマンスは、そのウェアハウスで他のクエリが実行されていても影響を受けず、また他のクエリの数が増えても基本的にはパフォーマンスが変わらないとスピーカーは言っていました
- multi cluster warehouse で scaling policy を standard とすると、新しいクエリがきた時にキューに入れずに新しい warehouse を立ち上げて並列実行可能数を動的に増減できこの観点で便利
共有ウェアハウスの唯一の欠点は、コスト管理が面倒になることです。
部門ごとにウェアハウスを分けていれば、それぞれのウェアハウスのコストを見るだけで各部門のコストが当然分かります。しかし共有ウェアハウスではそうはいきません。
まずロールやユーザーを部門ごとに分けたり、クエリタグを設定するなどして、あるクエリがどの部門によるものかを判別できるようにする必要があります。その上で、 WAREHOUSE_METERING_HISTORY と QUERY_HISTORY を組み合わせ、共有ウェアハウスの起動時間のうち何割がある部門の利用分に相当するかを計算する必要があるわけです。
ただし、それ以外大きなデメリットはないとされていました。
計測指標と測定結果
実際に共有ウェアハウスがうまくいっていることを測定する方法を考えると、以下の2つの指標が考えられます。
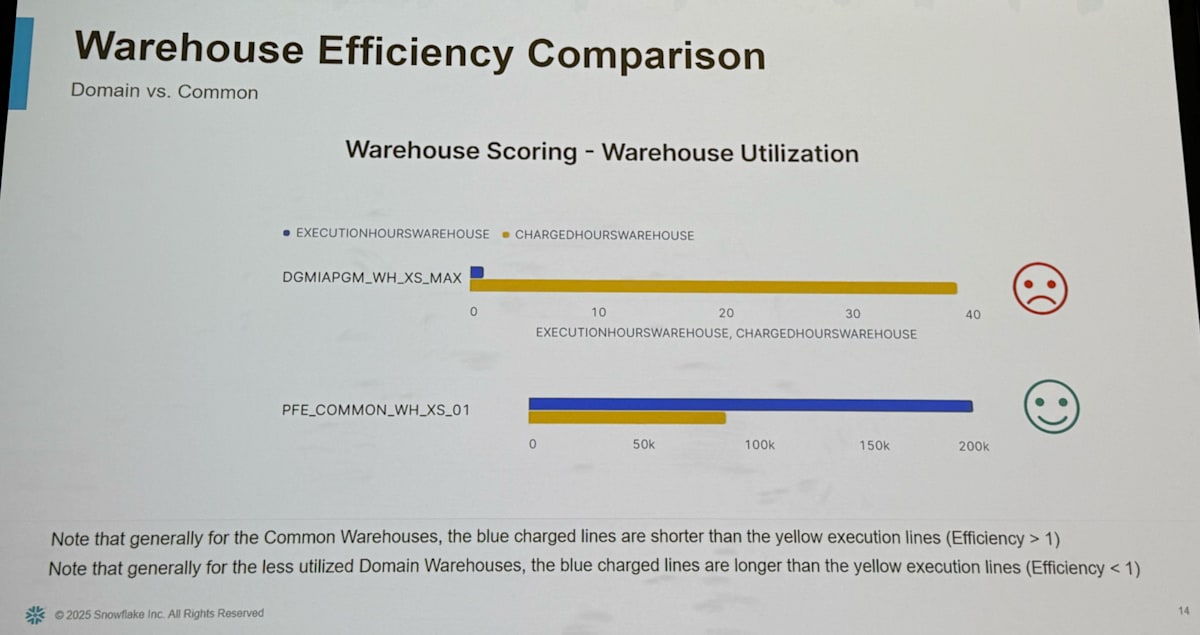
- Warehouse Efficiency
- (各クエリの実行時間の合計) / (ウェアハウスが実際に課金される稼働時間)
- この数値は大きいほどウェアハウスの計算資源の利用率が高いということになる
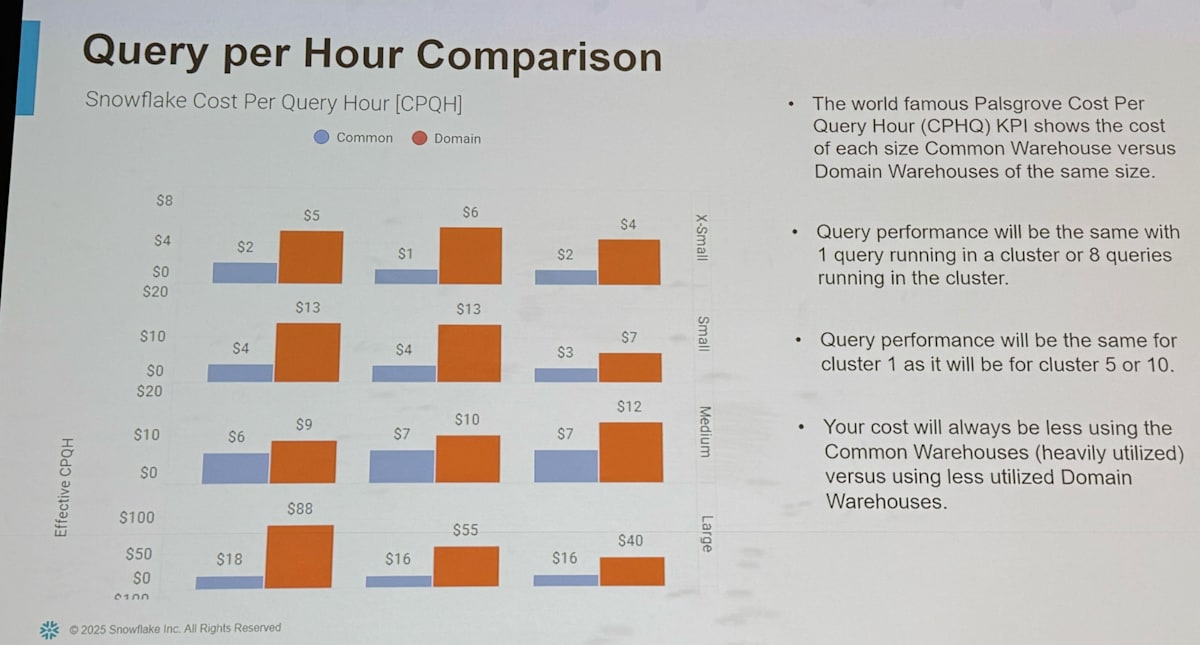
- Cost per Hour Query (CPHQ)
- 1時間かかる単一のクエリを実行するのにかかるコスト
- 例えば Medium の Warehouse で1時間かかるクエリを同時に2つ実行した場合を考える
- Medium の単価は4クレジットで$16なので、CPHQとしては$8
- これは安ければ安いほど嬉しい
ファイザーでは実際にドメイン別ウェアハウス時代と共通ウェアハウス時代とで Efficiency と CPHQ を比較し、以下の通りパフォーマンスが改善されたことを定量的に確認していました。
まとめと感想
多くの企業でユースケースやワークロードごとにウェアハウスは分割していることが多いと思いますが、ウェアハウスの利用率を上げるためにウェアハウスを共有することでコスト削減が可能であることがファイザーの事例を通して紹介されました。
このコスト最適化はおそらく adaptive compute でも使われており、その裏側が理解できて非常に勉強になるセッションでした。 adaptive warehouse の詳細は以下の記事もご覧ください。
これらを踏まえると、今後のウェアハウスの運用のプラクティスは
- 基本的には adaptive warehouse を使い、リソースが共有されるためコスト効率が高い環境を実現する
- 安全のため求められる分離レベルが高いワークロードには専用の standard warehouse を用意する
- 例えば dev 環境は adaptive warehouse を使うが、 stg/prod 環境では安全性重視で standard warehouse を使うとかはありだと思います
という形になっていくのかなと感じました。
今後ナウキャストでもウェアハウスの共有の検証は実際にやってみて、プラクティスを模索していきたいと思います!

Discussion