はじめに
こんにちは!ナウキャストのデータエンジニアのけびんです。昨年に引き続き今年も Snowflake Summit 2025 に参加しております。Platform Keynote でも触れられていた、データウェアハウスとしての新機能である "Adaptive Compute" について紹介するセッションに参加してきました!本ブログではその内容を紹介しようと思います。
セッション概要
- title
- "What's New: Faster Insights with Snowflake Standard Warehouse - Gen2 and Adaptive Compute"
- summary
- Learn how to efficiently scale and manage data engineering pipelines with Snowflake's latest native capabilities for transformations and orchestration with SQL, Python, and dbt Projects on Snowflake. Join us for new product and feature overviews, best practices, and live demos.
Even Faster Warehouses
まずはじめに、より早いウェアハウスを模索してきた Snowflake の歴史と現状が紹介されました。
Performance Improvements
Snowflake は日々パフォーマンス向上のアップデートをしてくれており、SPIで計測されていることは有名かと思いますが、今回のセッションでも過去12ヶ月でリリースされたアップデートが紹介されていました。
また、 Snowflake の歴史の中でどのように Warehouse が進化したかも振り返られており、
- 2012 年に Standard Warehouse
- 2023 年に Snowpark Optimized Warehouse
- 2025 年に Gen2 Warehouse
と継続的な改善、そしてどれもダウンタイムなしにリリースされてきています。
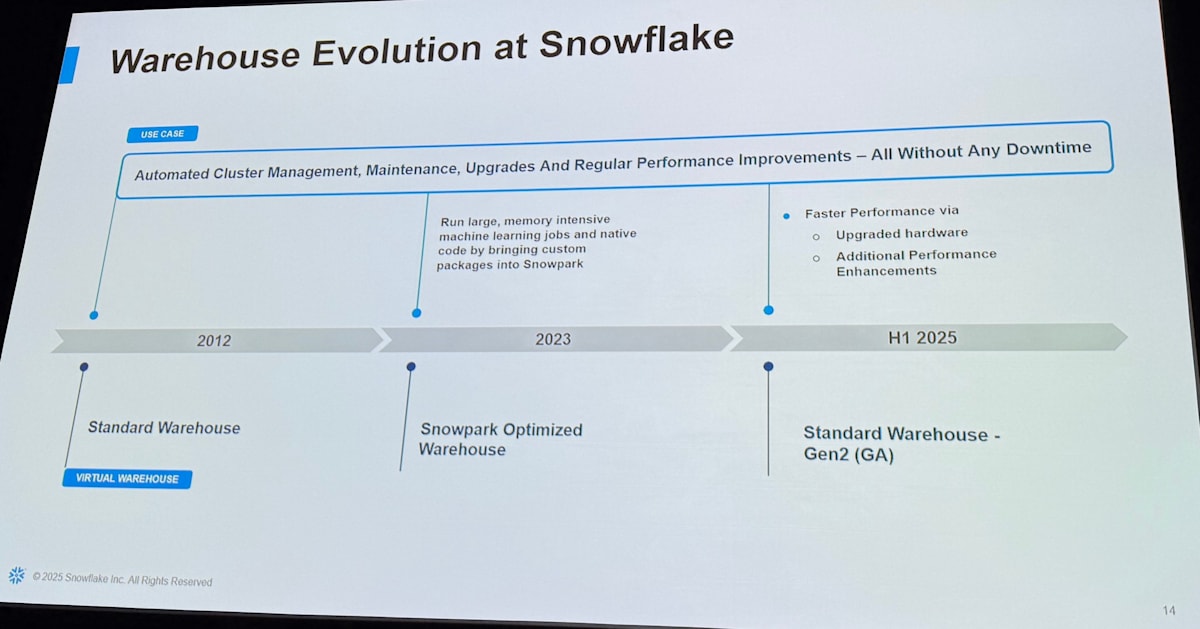
Gen2 Warehouse
大きなパフォーマンス改善の事例として、第2世代標準ウェアハウス(以下 Gen2)が紹介されました。以下のスライドの通り、特に従来の Standard Warehouse と比較して Gen2 は
- スループットが 2.3 倍
- Delete/Merge/Update といった処理に関しては 4.4 倍高速
とパフォーマンスが大幅に改善されています。それ以外にも多くのケース(Icebergテーブルなど)でパフォーマンスの向上がなされています。また既存の warehouse からの切り替えも alter 文を実行するだけで可能であり、非常に容易です。
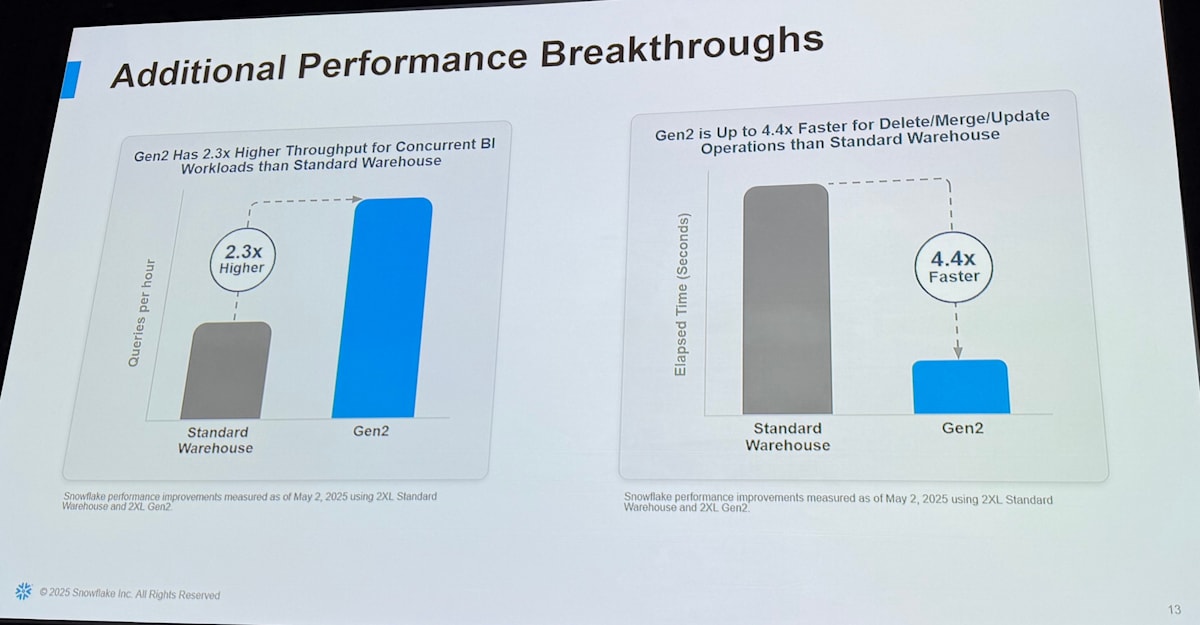

Gen2 はすでに GA となっていますが、2025/6/3現在 AWS と Azure の一部の地域で使えません。今回の発表を見て改めて Gen2 が日本リージョンでも使えるようになるのが楽しみになりました!
The Future of Snowflake Compute
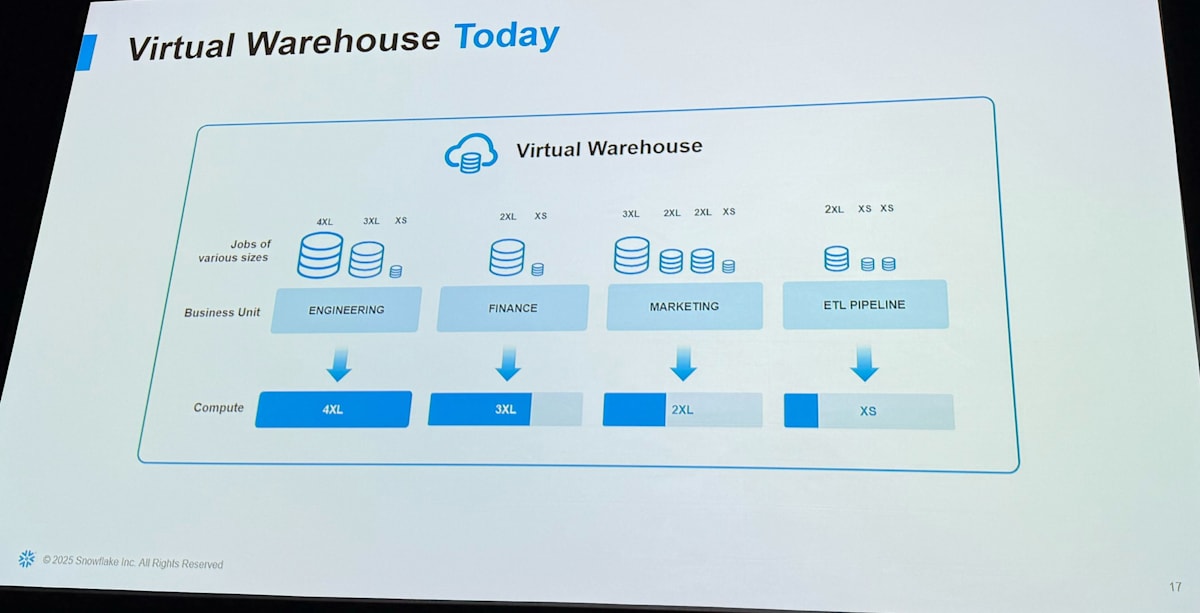
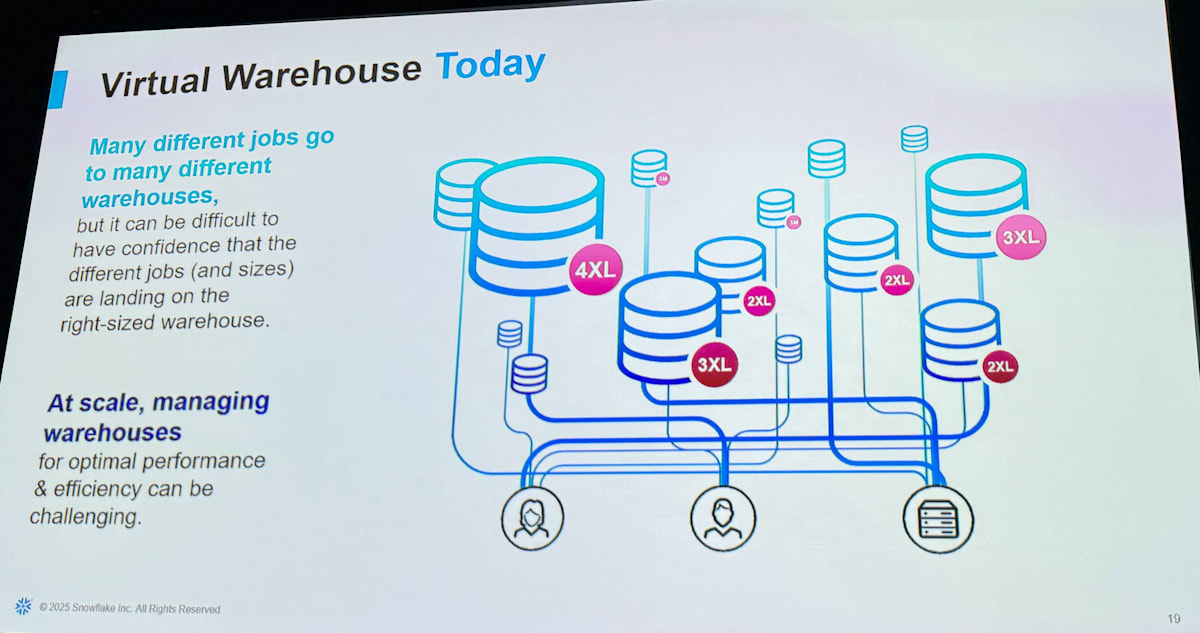
Virtual Warehouse Today
現在の Warehouse ではワークロードごとに最適な設定を決める必要があります。 Snowflake はシンプルとはいえ
- warehouse size
- warehouse type (Snowpark Optimized など)
- multi cluster 関係の設定
- query acceleration 関係の設定
などの設定値が存在します。これらの具体的な設定値の組み合わせの数は多く、ワークロードごとにパフォーマンスと効率を最適化するのはなかなか大変な作業でした。
Adaptive Compute
そこで新しく発表されたのが "Adaptive Compute" です。Snowflake が自動で warehouse のサイズの最適化と共有を行うことにより効率を最大化し、リソース管理の負担を軽減しつつ、コストの上昇なくパフォーマンス向上につながるという機能です。

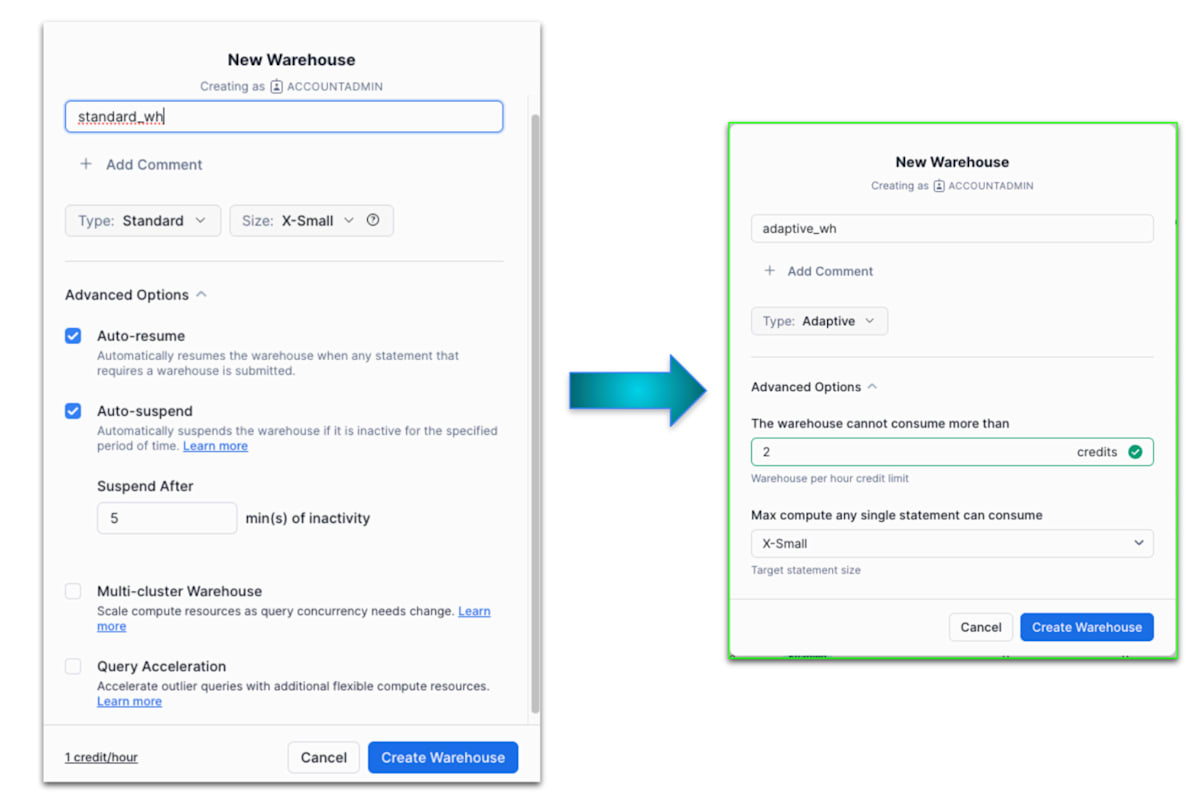
いかに設定項目が減ったかがよくわかります
作り方もシンプルで、 CREATE ADAPTER WAREHOUSE や ALTER WAREHOUSE をするだけです。
CREATE ADAPTIVE WAREHOUSE my_adaptive_wh;
ALTER WAREHOUSE my_wh SET WAREHOUSE_TYPE = 'ADAPTIVE';
Adaptive Compute のアーキテクチャは以下の通りです。 Adaptive Compute に渡されたすクエリははまず共有クラスターのプールに送られます。クエリの内容やクラスターの空き状況などに基づき、そのクエリをどのリソースで実行すべきかを判定し、最適なリソースへとルーティングします。このようにクエリごとに必要十分な計算リソースが割り当てられるため、コストを抑えつつ全体としてパフォーマンスの向上が見込めるようになるようです。
それだけでなく、ウェアハウスの余剰リソースを余すことなく使うことでコスト効率を上げ、パフォーマンス向上に役立てているようです。詳細は以下もご覧ください。


Adaptive Compute では設定値は以下の2つだけになります。
-
warehouse_credit_limit- ウェアハウスの1時間あたりのクレジット上限です
- この上限に達している場合にはそのクエリはキューイングされます
-
target_statement_size- システムに渡せるヒントの役割をするパラメーターです
- これが使うサイズの目安になります
- システムはこれを基準にクエリのサイズに基づいて使う計算リソースをスケールアップしたりスケールダウンしたりします
Adaptiveウェアハウスは既存のウェアハウスと同様に利用することができ、稼働時間に基づくクレジット課金です。既存のウェアハウスは簡単にAdaptiveに変換可能で、既存設定に基づき自動的にプロパティが設定されます。デモでは、Adaptive Compute により得られるパフォーマンス改善される様子が紹介され、特に大規模で複数のワークロードを実行する場合にその効果が顕著であるとのことでした。
インフラの設定コストを下げベストプラクティスに従っておきたい場合には Adaptive Compute を、細かいチューニングなども含め自分でやりたい場合には Gen2 を使う、というのが一つの判断基準となります。

まとめ
Keynote では Simple / Easy というキーワードが強調されていましたが、 adaptive compute はそれを体現したようなサービスだと感じました。
設定はシンプルで直感的ですし、多くのユースケースでまず使ってみてみると良い気がしました。もしリソースがあれば Gen2 を使ってしっかりクエリ最適化をしていくと良さそうです。Pubic Preview が待ち遠しいですね!
References

Discussion