※本記事は、2022年12月6日に公開済みの記事を移行して再掲載したものです。
はじめに
フェズでエンジニアをしている321です
2021年7月に1人目のSREとしてフェズに入社して、早1年5ヶ月になります
完全にゼロの状態からスタートするのは楽しくもあったのですが、課題は多く何に手をつけようかそれなりに悩みながらやってきました
ちょうどこの記事を書いてるのが12月で年の瀬という事もあり、どんな事をやってきたかピックアップして振り返りつつ記事にしてみようと思います
私と同じように、新天地で同じようなミッションを担う人とって少しでも参考になれば嬉しいです
データ基盤チームに配属
入社当時、まだSREという組織はなかったのでデータ基盤チームに所属しつつSRE的な観点で改善をしていく。という建て付けでした
初日は「ってもベンチャーのデータ基盤なんて結構レガシーなんだろうなぁ、ガッツリ作り直しちゃうぞー」
とか思ってたのですが、中を覗いてみたら「あれ、わりといい感じの設計だな・・・」と。
こちらの記事にもあるように、私が入社時点でCloud Composer導入の検討も既にあり、あまり私が積極的に口出しする必要が無い状態でした
ということで、運用業務を中心にキャッチアップして課題を探し、それに優先度付けをして潰していく事にしました
Google Cloud のアカウント整備
課題
DWHには当時から変わらずBigQueryを利用しており、開発者以外にも分析等の用途で多くのメンバーがGoogle CloudのGUIからクエリを実行していました
ただ、メンバーへの権限やアカウント追加のルール等が当時は存在せず、以下のような課題がありました
- 🙅♂️ 権限が妥当であるか、有識者や責任者の承認が得られていない 🙅♂️
- 🙅♂️ 権限付与/削除等の履歴が残っていない 🙅♂️
- 🙅♂️ データ基盤管理者が、誰にどんな権限を付与しているのか把握できない 🙅♂️
改善1: 申請と承認のフローを作って依頼をチケットで管理する
まずは 申請と承認のフローを作って依頼をチケットで管理 する事で1と2の課題に対応しました
方法としては、Slack Workflow + Lambda(+API Gateway) + Github Issue を使いました
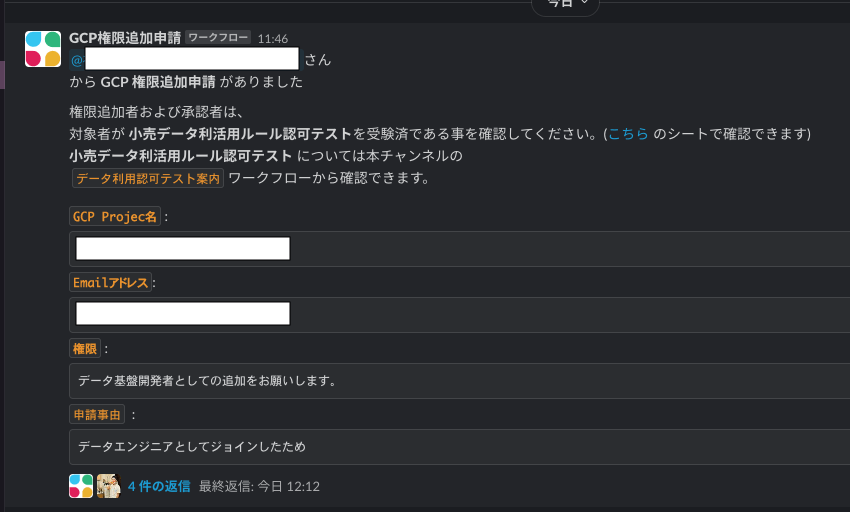
- 申請者はSlack Workflowを起動し、必要な情報を記入して申請します(下記 1枚目の画像参照 )
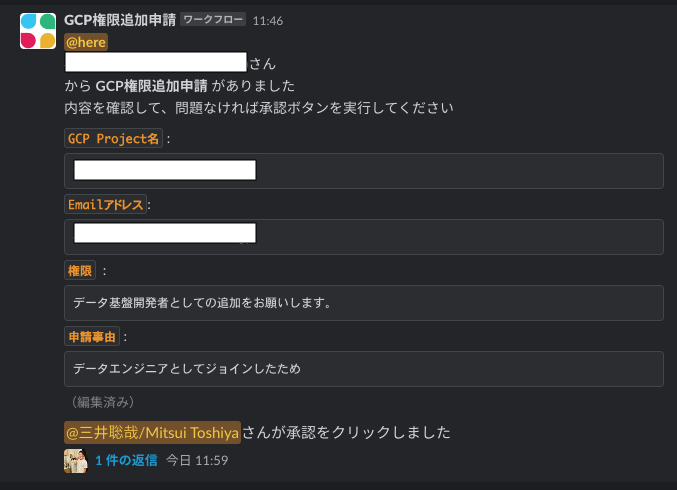
- 申請は承認者に届き、承認者は内容を確認してSlack上で承認ボタンを押下します (下記 2枚目の画像参照 )
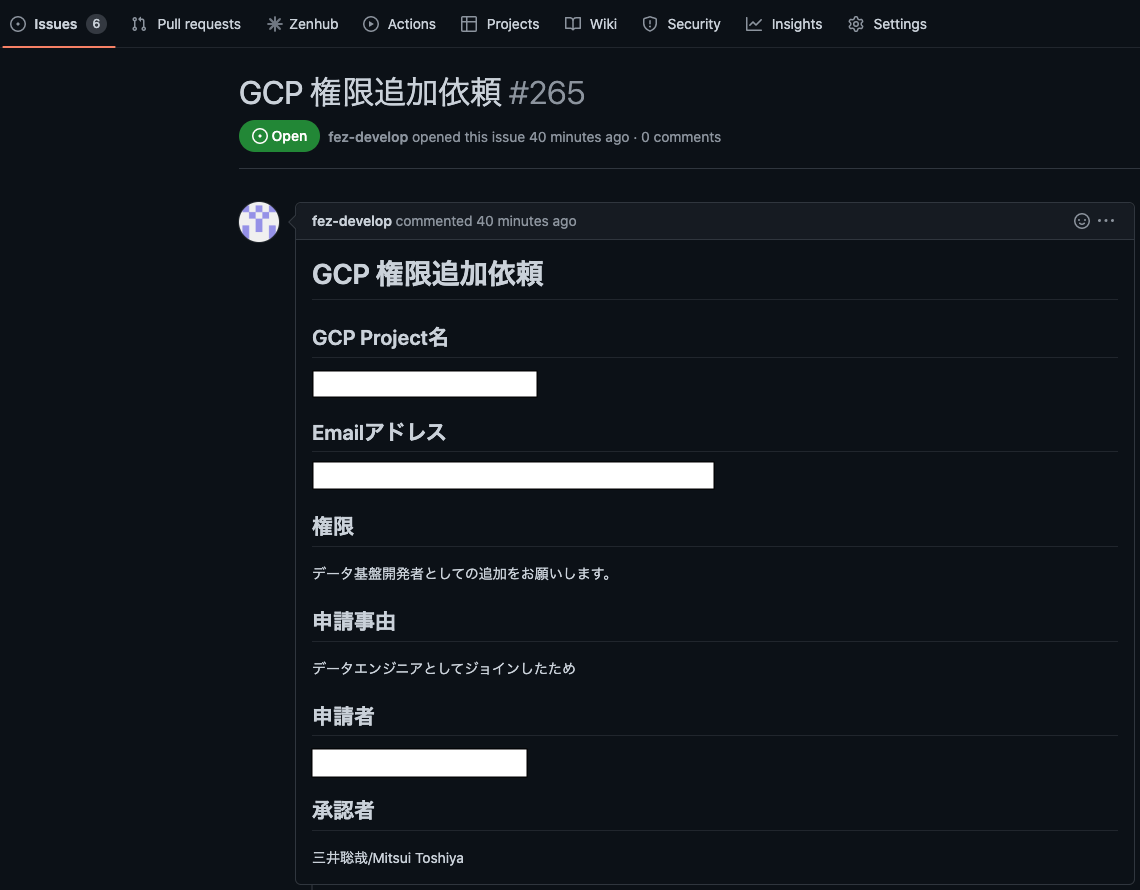
- 承認者がボタンを押下すると、Slack AppによりLambdaが起動しGithub Issue を作成します (下記 3枚目の画像参照)
- 権限追加者はIssueを確認して、追加/削除の作業を実施する (下記 4枚目の画像参照)
という流れです

改善:2 アカウントをグループ化してコード管理する
3の課題については グルーピングとコード化 で対応しました
方法としては、Google Group + Terraform を使いました
当時、権限は個人アカウントに対して付与していたため、IAMが大量に存在してそこそこカオスになってました
幸いなことに当時から既にGoogle Workspaceを契約していたため、ロールごとにGoogle Groupを作成しGroupに対して権限を付与する事にしました
数十個あるProjectの全てのIAMをスプレッドシートに書き出してグルーピングしていく作業はなかなかにツラいものでしたが(w)、
不要だったり権限が強すぎるアカウントの棚卸しが同時にできたのは良かったです
Google Groupの作成と、Google Cloud Project(Folder)へのアサインは全てTerraformでコード化しました
前職まではインフラ構築目的でTerraformを使う事がほとんどだったので、アカウント管理目的でも利用できるのは自分にとって良い発見でした
※ 実際に使ったのは以下のようなresourceです。具体的にどんなコードを書いているかは、いずれ別の記事で書こうと思います
Terraform Registry: google_cloud_identity_group
Terraform Registry: google_project_iam
Terraform Registry: google_folder_iam
Service Account の整備 (以下、SAと表記)
先の項目でフェズの社員アカウントは一通り整備できましたが、SAも整備する必要がありました
具体的には以下のような問題がありました
- 🙅♂️ 複数の処理のために同じSAが使い回されている 🙅♂️
- 単一の処理が廃止されてもSAを削除していいのか判断に困る
- それぞれの処理が本来担っている責務が権限設計から読み取れず、ブラックボックス化する
- 🙅♂️ CI/CDなどにSAのKeyが利用されていて、各開発者のPCにもkeyが保存されている 🙅♂️
※ SA のベストプラクティスは 公式ドキュメント でも言及されているのでこちらをご参照ください
改善1: 処理ごとにSAを新規作成して 入れ替える
1の課題についてのアプローチはシンプルで、それぞれの処理ごとにSAを新規に作成して入れ替えていきました
幸い、データ基盤開発者がそれぞれの処理についてはしっかり把握していたので、権限設計と置き換えはスムーズでした
長い時間が経過して担当者が入れ替わったりしていると、調査に時間がかかってしまう傾向はあると思うので、そういう意味では早めに手がつけられて幸運でした
SAの作成と権限付与についても例によって、Terraformでコード管理しています
初期構築は私が実施しましたが、今ではこのあたりのコードはデータ基盤チームに引き継いで運用してもらってます
改善2: SAのKeyを利用しない状況を作る
2の課題については、基本的にkeyを発行する必要がない状態を作る必要があります
当時はリリースのワークフローが完全に自動化されておらず、作業者のローカルPCから gcloud コマンドを実行する
というような運用が一部残っており、その流れでkeyが利用されていました
まずは開発者のローカルPCに残っているkeyを削除してもらい、APIを実行する必要がある場合は自身の個人アカウントで認証するようにしてもらいました
(これは、keyを使わないという目的に加えて、監査ログから実行者を特定可能な状態にしておくという意図もあります)
そして、リリースフローに関してはGithub Actionsで定型化して、Googleへの認証には Workload Identity を利用する事で不要なkeyの発行を制限しました
※ Workload Identityの詳しい説明は省略しますが、要するにGoogle Cloudの外部からkeyを必要としない認証が実現できます
Workload Identityの構築については 公式ドキュメント に設定手順が記載されており
Github Actionsから利用するのも 公式Action が用意されているので
あまり設定は難しくなく、以下のような数行のコードをgithub actionsに記述するだけで任意のProjectに対してgcloudコマンドが実行できます
runs:
steps:
- id: auth_google_cloud
name: 'Authenticate to Google Cloud'
uses: google-github-actions/auth@v1
with:
service_account: 'my-service-account@my-project.iam.gserviceaccount.com' # 実際に利用するService Accountに置換
workload_identity_provider: 'projects/123456789/locations/global/workloadIdentityPools/my-pool/providers/my-provider' # 実際に作成したproviderに置換
- id: setup_gcloud
name: 'Setup Gcloud'
uses: google-github-actions/setup-gcloud@v1
with:
project_id: 'my-project' # 実際に認証するGoogle Cloud Project IDに置換
- id: exec_gcloud
name: 'Gcloud Auth List'
run: gcloud auth list
モニタリングの整備
Google Cloudのアカウント整備が一通り終わったので、次はモニタリングに手を付けました
モニタリングはSRE的にはいわゆる サービス信頼性の階層(Service Reliability Hierarchy) の最下層にあたります
単純に インシデントの発生を検知する 仕組みが存在するか?
に加えて、 信頼性を計測するうえで指標を可視化する 仕組みがあるか?
という側面もあるかと思いますが、このタイミングでは前者の対応になります
(データ基盤の信頼性の計測 については、まずは指標や定義をどうするか決める必要があり、今後のデータ基盤とSREの共通課題として取り組んでいくテーマとしています)
ETL処理のエラー検知する構成を修正
元々、私がジョインする前から各ETL処理のエラーを検知する仕組みは存在しました
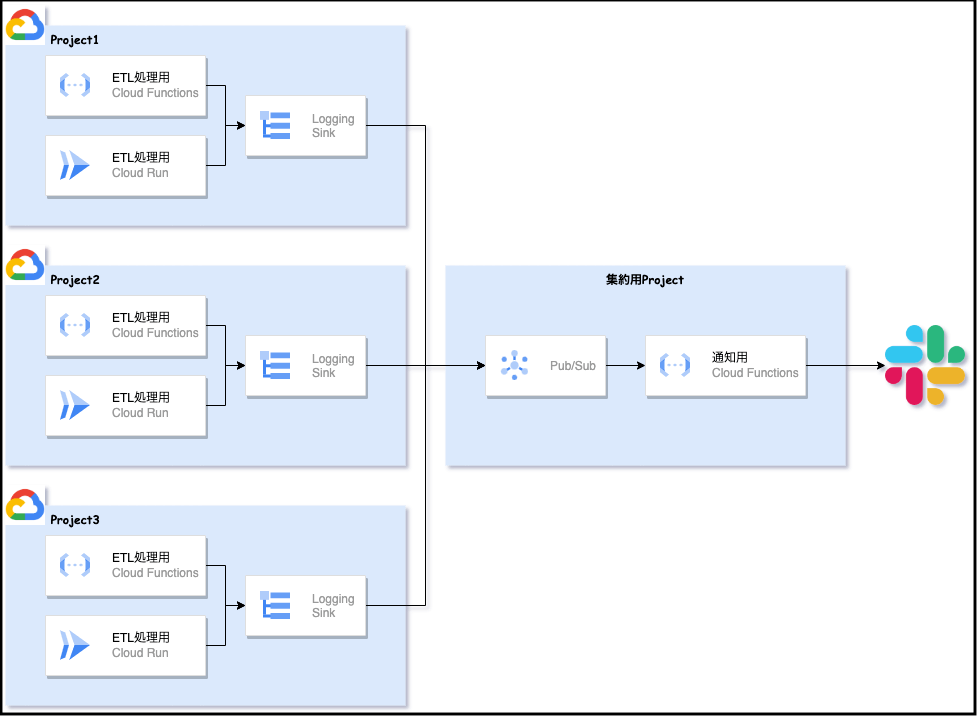
下記の Before 画像のように、Logging Sinkのフィルタでエラーの発生を検知し、Pub/Sub経由で通知用のCloud Functionsを起動してSlackに通知していました
しかし、開発環境等も含めると数十個あるProjectそれぞれに通知の仕組みが存在しメンテナンス性に問題があったので
下記 After 画像のような構成に変更しました
少なくともこの構成にしたことでProjectが増える度に通知処理のFunctionsとPub/SubをDeployする必要がなくなり、構成がシンプルになりました
さらに 集約シンク を使えば、組織やフォルダレベルでシンクを作成してよりシンプルに集約する構成が可能です
Before
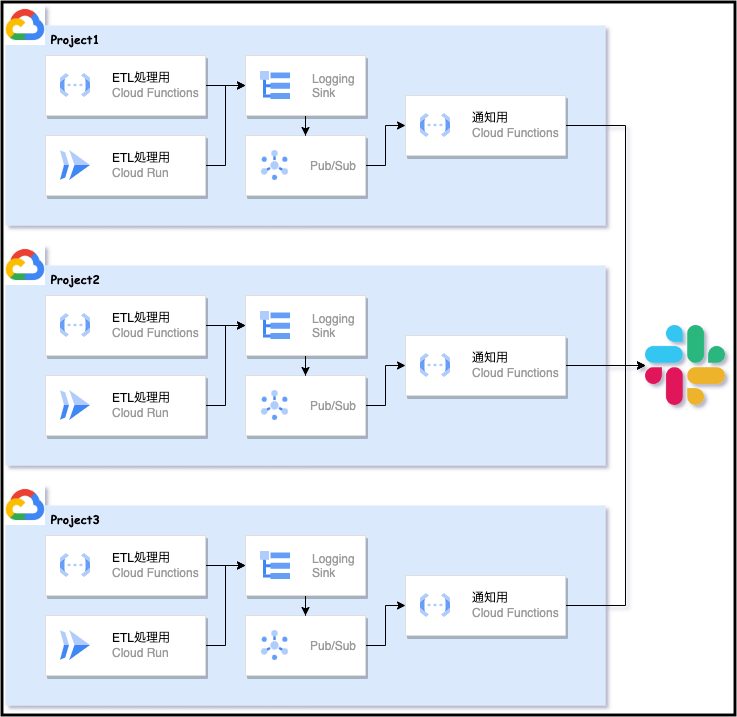
After
Metricsによるアラートを追加
また、この時期にちょうどCloud Composerが導入されるタイミングだったので、
Cloud MonitoringによるMetrics Alertも設定して、 意図せずETL処理が実行されない状態 を検知できるようにしました
Composerの指標については 公式ドキュメント に記載がありますので、
こちらを参考に、環境やデータベースのヘルス等の重要な指標についてはモニタリングを設定しました
データ基盤編、一旦終了
ここに書いた以外にも細々した改善を、入社後半年くらい掛けて実施してきました
※ 以前 こちら の開発ブログでもご紹介したのですが、BigQuery等のコスト可視化なども実施しました
勿論、まだまだ改善の余地はたくさん残されていましたが、必要最低限の状況は実現できたかなという所でした
このあたりのタイミングで、Urumo Shopper などプロダクトが少しずつ形になり、データ基盤以外にも手を伸ばしていく時期になります
そのあたりの話もここに書くと長くなってしまうので、続きは後編という形で書こうと思います
まとめ
入社してからこれまでの事を振り返ろうと思って書き始めたのですが、
思ったよりボリューミーになってしまいそうだったので、続きは後編という形でご紹介させていただこうと思います
データ基盤編と題してみましたが、改めて振り返るとデータ基盤以外でも発生しうる課題に向き合っていたなという感想です
クラウドを利用するならどの組織でも同じような課題は発生しうると思うので、この記事が誰かの参考になれば幸いです

フェズは、「情報と商品と売場を科学し、リテール産業の新たな常識をつくる。」をミッションに掲げ、リテールメディア事業・リテールDX事業を展開しています。 fez-inc.jp/recruit
Discussion