※本記事は、2022年1月18日に公開済みの記事を移行して再掲載したものです。
はじめに
フェズでは購買データの分析等にGoogle BigQueryを利用しています
Google BigQuery とは
ビッグデータを素早く活用したい場合に選択肢にあがるフルマネージド型のデータウェアハウスです
標準SQLを利用して、実行したクエリが利用したデータ量に応じて課金されます
フェズのデータ基盤は、主に分析用途で複数のチームから利用されているため以下のような課題がありました
- 誰がどんな用途でBigQueryを利用しているのか可視化できていない
- 組織毎にコストを按分したいけど実行者や利用用途が判別できない
- BigQueryが複数存在して集計に手間がかかる
今回は上記のような課題を解消するために試みた事例をご紹介しようと思います
背景
この記事を書いてる日からは少し前の事になりますが
データ基盤チームでGoogle Cloud の請求アカウントのレポートを眺めていると
8月のBigQueryのコストがほぼ倍増している事に気づきました

データ基盤チームで原因を調査しましたが、
誰がいつどんなクエリを実行していくらコストが発生したのか
を把握するためにそれなりに時間がかかってしまいました
そこで、これらをすぐに把握できる仕組みを構築する事にしました
どんな構成
BigQueryには INFORMATION_SCHEMA というビューが存在します。
そのなかでも JOBS_BY_PROJECT を利用すればジョブの実行履歴が取得できます。
フェズのデータ基盤では、複数ProjectにBigQueryのデータセットが存在します。
また、INFORMATION_SCHEMAの有効期限は180日でそれ以前の履歴は閲覧できません。
そのデータセットに各Projectのジョブの実行履歴を日次で蓄積する仕組みを考えました。
簡単ですが絵にするとこんな感じです。
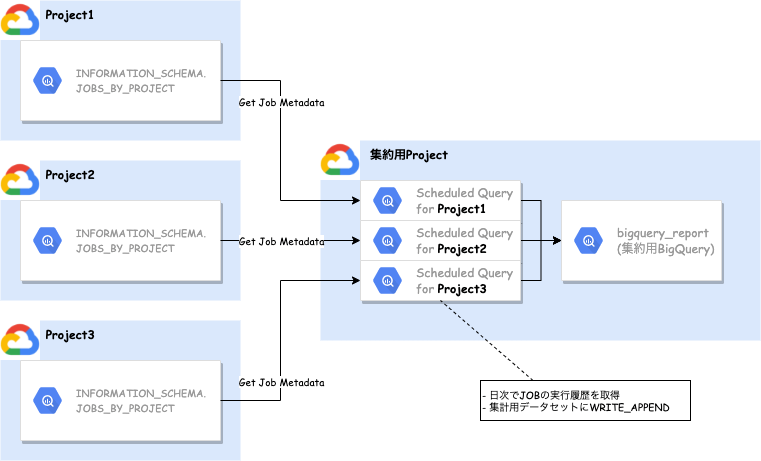
JOBメタデータの集約
JOBメタデータ
JOBS_BY_* ビューのスキーマ定義は公式ドキュメントに書いています。
その中でも、今回欲しいカラムはこのあたりです。
| カラム | データ型 | 値 |
|---|---|---|
| user_email | STRING | ジョブを実行したユーザーのメールアドレスまたはサービス アカウント |
| project_id | STRING | プロジェクトの ID |
| query | STRING | SQL クエリテキスト 注: query 列が表示されるのは JOBS_BY_PROJECT ビューのみです。 |
| total_bytes_billed | INTEGER | ジョブに対して課金された合計バイト数 |
| total_slot_ms | INTEGER | ジョブの全期間のスロット(ミリ秒) |
| start_time | TIMESTAMP | このジョブの開始時間 |
集約用BigQueryデータセット
集約用のBigQueryは以下のようなスキーマ構成にしています
- Dataset:
bigquery_report - Table:
query_history
| カラム | データ型 | モード | 説明 |
|---|---|---|---|
| user | STRING | NULLABLE | User who executed the query |
| project_id | STRING | NULLABLE | Google Cloud Project ID |
| query | STRING | NULLABLE | Executed Query |
| total_bytes_billed | INTEGER | NULLABLE | Capacity used by executing Query (Byte) |
| total_slot_ms | INTEGER | NULLABLE | Slot by executing Query (ms) |
| charges_doller | FLOAT | NULLABLE | Cost used by executing Query (Doller) |
| slot_usage | FLOAT | NULLABLE | Slot used by executing Query |
| start_time | TIMESTAMP | NULLABLE | Time when the query was executed (JST) |
Scheduled Query
メタデータを取得するために Scheduled Query で実行されるクエリは以下のようになります
これを対象のProjectの数だけ設定して、日次で定期実行されるように設定します
※ クエリ実行するユーザもしくはサービスアカウントに bigquery.jobs.list の権限が必要です
- [project] と [region] はProjectごとに適宜書き換え
-
charges_dollerは こちら を参考に$に換算 - 対象期間は実行日の前日
SELECT
user_email AS user,
project_id AS project_id,
query AS query,
total_bytes_billed AS total_bytes_billed,
total_slot_ms AS total_slot_ms,
ROUND(total_bytes_billed / POW(1024, 4) * 6.0, 4) AS charges_doller,
ROUND(total_slot_ms / TIMESTAMP_DIFF(end_time, creation_time, MILLISECOND), 4) AS slot_usage,
TIMESTAMP(FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', start_time, 'Asia/Tokyo')) AS start_time,
FROM
`[project]`.`[region]`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
(total_bytes_billed IS NOT NULL AND total_bytes_billed != 0)
AND start_time BETWEEN
TIMESTAMP(DATE_TRUNC(DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY), DAY))
AND TIMESTAMP(DATE_TRUNC(CURRENT_DATE('Asia/Tokyo'), DAY))
Looker Studioによる可視化
ここまでで、集約用BigQueryに各Projectのジョブ履歴が蓄積されるようになりました
ここから、Looker Studioから集約用BigQueryにつないで可視化してみます
Looker Studioを作成するアカウントには集約用BigQueryへの権限が必要になります
参考: Looker Studio でデータを分析する
Looker StudioからBigQueryに接続する
Looker Studioから集計用BigQueryに接続します
- データのレポートへの追加で
BigQueryを選択
- 集約用BigQueryデータセットを選択して、右下の 追加 ボタン

Looker Studioでグラフや表を作成
あとはお好みでグラフや表を作成していきます
画面でポチポチするだけなので、作成方法は割愛します
参考までにフェズで作成したLooker Studioのキャプチャと簡単な説明を書いておきます
- ①Filter : 日付、Project、Userでフィルターをできます
- ②Cost : コストに関するサマリ
- ③Queries : クエリに関するサマリ
- ④Ranking By User : User毎の課金額ランキング
- ⑤Ranking By Query : Query毎の課金額ランキング

通知
あとはこのLooker Studioを定期的にチェックしつつ問題があるクエリや運用を改善。。。
できればいいのですが、人間なので能動的な運用ではついつい忘れてしまう事があります
ということで、利用状況を定期的にSlack通知しています
こちらは今回のメインテーマではないため詳しい説明は割愛しますが、以下のような仕組みになっています
- Google Apps Script を利用して、集計用BigQueryからスプレッドシートに集計結果を保存
- Slack ワークフローでスプレッドシートからデータを取得してチャンネルにメッセージ送信

まとめ
上記のような仕組みを導入することで
BigQueryコストの内訳が簡単に把握できるようになりました
また
想定していないようなクエリ実行を発見し運用を改善する動きも取れるようになりました
当初予定していた課題は達成できましたが、運用を続けると以下のような課題が出てきました
- 個人がBigQueryのUIから実行したクエリと、データポータル等のツール類から実行されたクエリと区別がつかない (実行ユーザはINFORMATION_SCHEMA的には同一になる)
- ツール類からの実行を区別できるように実行アカウントを整備したい
- 想定外の利用が発生していても、そのタイミングで気づくことができない
- 即座に通知する仕組みを整備したい
データ基盤チームでは上記のような課題も少しずつ解決できるよう、日々改善を続けていきます
- 即座に通知する仕組みを整備したい
Appendix
今回ご紹介した環境はConsoleやgcloudコマンドで構築可能ですが、せっかくなのでTerraformによりIaC対応しています
参考にコードを載せておきます
ファイル構成
┣ bigquery.tf
┣ service_account.tf
┣ locals.tf
┗ templates/
┣ query_history.sql
┗ query_history_schema.json
bigquery.tf
- BigQuery および Scheduled Query の設定
resource "google_bigquery_dataset" "bigquery_report" {
dataset_id = local.bigquery.dataset.bigquery_report.dataset_id
description = local.bigquery.dataset.bigquery_report.description
location = local.bigquery.dataset.bigquery_report.location
}
resource "google_bigquery_table" "query_history" {
dataset_id = google_bigquery_dataset.bigquery_report.dataset_id
deletion_protection = false
schema = file("./templates/query_history_schema.json")
table_id = local.bigquery.table.query_history.table_id
time_partitioning {
field = "start_time"
expiration_ms = "15552000000" // 180 days
type = "DAY"
}
}
resource "google_bigquery_data_transfer_config" "query_history" {
for_each = { for idx, target in local.bigquery.data_transfer_config.query_history.targets : target => idx }
data_source_id = "scheduled_query"
destination_dataset_id = google_bigquery_dataset.bigquery_report.dataset_id
display_name = "QueryHistory (${each.key})"
location = "asia-northeast1"
schedule = format("every day 17:%02d", each.value)
service_account_name = google_service_account.bigquery_report.email
params = {
destination_table_name_template = google_bigquery_table.query_history.table_id
write_disposition = "WRITE_APPEND"
query = templatefile("templates/query_history.sql", {
project = element(split(".", each.key), 0)
region = element(split(".", each.key), 1)
})
}
schedule_options {
// 初回実行時の 翌2:00 から開始
start_time = formatdate("YYYY-MM-DD'T'17:00:00Z", timestamp())
}
lifecycle {
ignore_changes = [schedule_options]
}
}
service_account.tf
- Service Account を作成して
BigQuery 管理者を付与する
resource "google_service_account" "bigquery_report" {
account_id = local.service_account.bigquery_report.account_id
description = local.service_account.bigquery_report.description
display_name = local.service_account.bigquery_report.display_name
}
// 複数Project横断して実行が必要なので、OrganizationレベルでBigQuery管理者 権限をSAに付与する
resource "google_organization_iam_binding" "bigquery_admin" {
org_id = "XXXXX" // OrganizationのID
role = "roles/bigquery.admin"
members = ["serviceAccount:${google_service_account.bigquery_report.email}"]
}
locals.tf
- 変数を定義
- Projectを追加したい場合は、
bigquery.data_transfer_config.query_history.targetsのリストに追加すればOK
locals {
bigquery = {
data_transfer_config = {
query_history = {
targets = [
// "[project_id].[region]"
// ここに必要なProjectとRegionを列挙する
"project1.region-asia-northeast1", // Project1
"project2.region-asia-northeast1", // Project2
"project3.region-asia-northeast1", // Project2
]
}
}
dataset = {
bigquery_report = {
dataset_id = "bigquery_report"
description = "BigQuery Report"
location = "asia-northeast1"
}
}
table = {
query_history = {
table_id = "query_history"
}
}
}
service_account = {
bigquery_report = {
account_id = "bigquery-report"
description = "BigQuery Reportを作成するために利用されるサービスアカウント"
display_name = "BigQuery Report"
}
}
}
templates/query_history.sql
- Scheduled Query で実行されるSQLのテンプレートファイル
SELECT
user_email AS user,
project_id AS project_id,
query AS query,
total_bytes_billed AS total_bytes_billed,
total_slot_ms AS total_slot_ms,
ROUND(total_bytes_billed / POW(1024, 4) * 6.0, 4) AS charges_doller,
ROUND(total_slot_ms / TIMESTAMP_DIFF(end_time, creation_time, MILLISECOND), 4) AS slot_usage,
TIMESTAMP(FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', start_time, 'Asia/Tokyo')) AS start_time,
FROM
`${project}`.`${region}`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
(total_bytes_billed IS NOT NULL AND total_bytes_billed != 0)
AND start_time BETWEEN
TIMESTAMP(DATE_TRUNC(DATE_SUB(CURRENT_DATE('Asia/Tokyo'), INTERVAL 1 DAY), DAY))
AND TIMESTAMP(DATE_TRUNC(CURRENT_DATE('Asia/Tokyo'), DAY))
templates/query_history_schema.json
[
{
"name": "user",
"type": "STRING",
"mode": "NULLABLE",
"description": "User who executed the query"
},
{
"name": "project_id",
"type": "STRING",
"mode": "NULLABLE",
"description": "GCP Project ID"
},
{
"name": "query",
"type": "STRING",
"mode": "NULLABLE",
"description": "Executed Query"
},
{
"name": "total_bytes_billed",
"type": "INTEGER",
"mode": "NULLABLE",
"description": "Capacity used by executing Query (Byte)"
},
{
"name": "total_slot_ms",
"type": "INTEGER",
"mode": "NULLABLE",
"description": "Slot by executing Query (ms)"
},
{
"name": "charges_doller",
"type": "FLOAT",
"mode": "NULLABLE",
"description": "Cost used by executing Query (Doller)"
},
{
"name": "slot_usage",
"type": "FLOAT",
"mode": "NULLABLE",
"description": "Slot used by executing Query"
},
{
"name": "start_time",
"type": "TIMESTAMP",
"mode": "NULLABLE",
"description": "Time when the query was executed (JST)"
}
]

フェズは、「情報と商品と売場を科学し、リテール産業の新たな常識をつくる。」をミッションに掲げ、リテールメディア事業・リテールDX事業を展開しています。 fez-inc.jp/recruit
Discussion