はじめに
こんにちは/こんばんは、Fairy Devices株式会社(以降、当社)でプロダクト開発部の部長をしている吉川(@emergent)と申します。
当社には音声処理技術のサービスやソリューションを提供するmimi® 事業があり、その中でWeb APIを提供するサービスをmimi® クラウドAI[1]と呼んでいます。
すでに当社の音声処理技術の研究開発に関する記事を複数公開[2][3][4][5]しておりますが、本記事では音声処理をWeb APIで提供するクラウドAIで運用中のサーバーアーキテクチャを紹介します。
mimi® クラウドAIサービスの全体像
当社のWebサイトからmimi® で提供しているサービスの全体像の絵を引用します。以下の画像内の「クラウドAI」のサーバーアーキテクチャが本記事のスコープです。
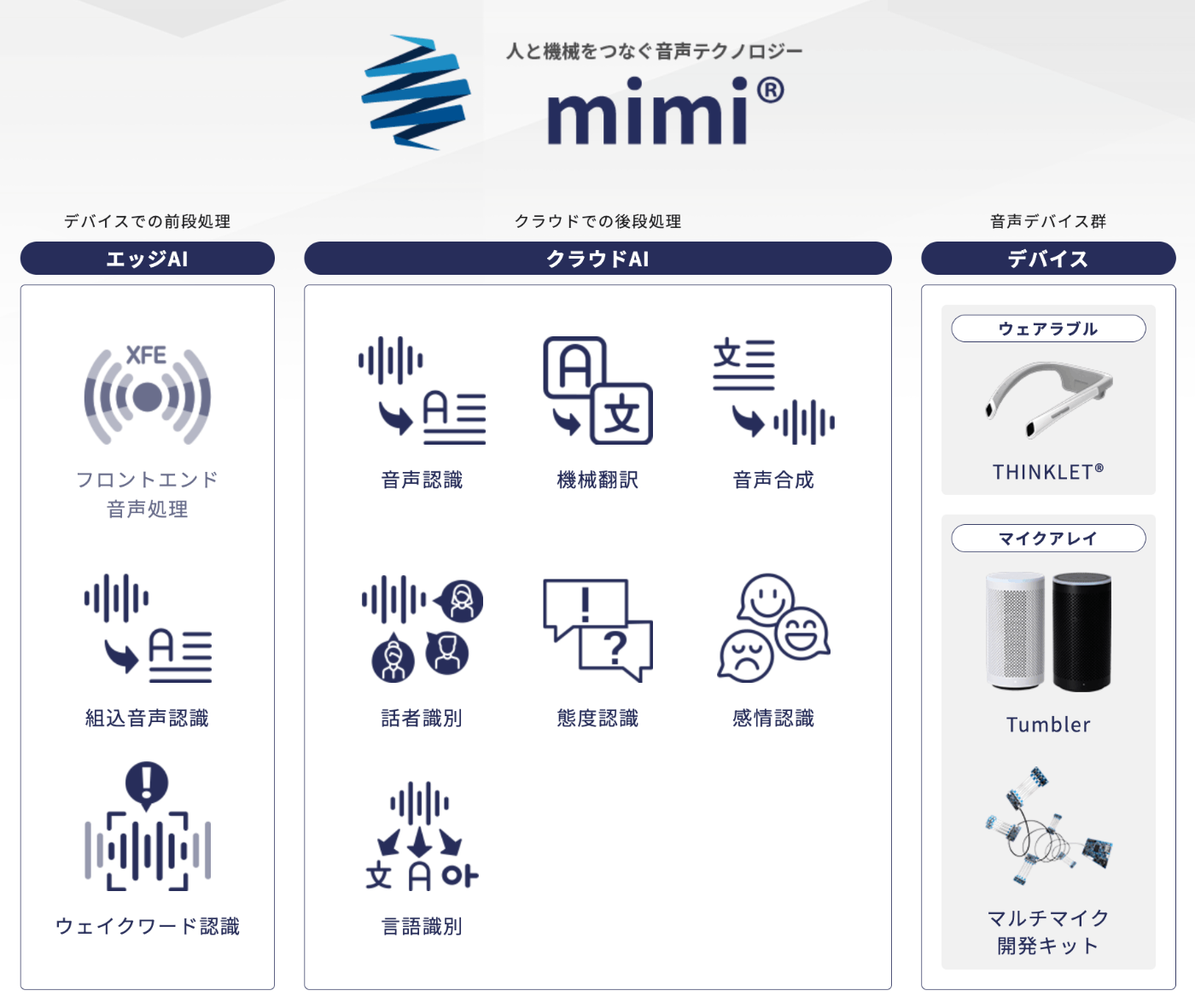
これらの各機能の詳細は上述の当社サイトに詳しく書かれているため割愛しますが、興味のある方は上記リンクを参照ください。早速ですが、以下がmimi® クラウドAIの機能を提供する(非常に簡略化した)サーバーアーキテクチャです。

図中に(1)(2)(3)と示しているところが本記事での説明ポイントです。
(1) 開発者用の管理機能
(1)はこれ自体が音声処理の機能を提供するわけではなく、クラウドAIのWeb APIを利用するために使う管理機能です。クラウドAIを利用するための認可情報を作成・管理するための機能が中心で、主に当社が提供する開発者コンソール(mimi API Console:図中左上)というWebサイト上から利用します。
クラウドAIの利用時は、開発者コンソールで作成した認可情報を用いて発行されたアクセストークンを使って、利用者のプログラムからWeb APIへアクセスします。
(2) 音声を入力とする機能
(2)は音声データを入力として受け付けるAPIおよびバックエンドの構成です。上述のクラウドAIで提供している音声処理の機能群のうち、機械翻訳と音声合成以外はすべてここに該当します。このAPIエンドポイントはWebSocketプロトコルを用いています。あらかじめ音声ファイルとしてまとまっている形式でも受け付けられますが、下図のように人が話した音声をリアルタイムに受け付けながら音声処理結果を何回も非同期で返却するユースケースでの利用を重視しているためです。

さらには、たとえば「リアルタイムで音声認識しながら感情認識も同時に行いたい」というニーズに対し、利用者側のプログラムでわざわざ音声入力を二系統に分けてAPIに入力しなくても済むよう、ひとつのAPIエンドポイントで音声データを受け付け、複数の音声処理結果をクライアントに返却できる設計にしています。
ここは次章「音声入力エンドポイントの裏側」でもう少し詳しく説明します。
(3) テキストを入力とするAPI
機械翻訳と音声合成は、テキストを入力として受け取るため、HTTPによるシンプルなWeb APIとして利用できます。たとえば音声認識した結果のテキストを「他の言語に機械翻訳し」「さらにはその翻訳結果を音声合成してスピーカーから発声させる」といったプログラムも開発しやすい形となっています。
音声入力エンドポイントの裏側
さて、上記(2)の節で「ひとつのAPIエンドポイントで音声データを受け付け、複数の音声処理結果をクライアントに返却できる」と書きました。その裏側の構成を補足します。ざっくりいうと「エンドポイントからさらに後段の各音声処理エンジンに音声入力を振り分けているだけ」ではあります。ただし、mimi® は自社製のエンジンに加えてサードパーティ製のプロプライエタリな音声処理エンジンも取り扱っている都合上、音声入力エンドポイントからすべての音声処理エンジンに同じ接続方法でアクセスできるわけではありません。
そのため、下図右側の中段・下段のように、音声入力エンドポイントとその後段の音声処理エンジン(または外部システム)との間に中間サーバーを置き、あくまで音声入力エンドポイントからは同一のAPI仕様でアクセスできるよう多段構成としている箇所もあります。こうすることで、音声入力エンドポイントの後段で提供する機能が増えたとしても、音声入力エンドポイント上では後段のサーバーの設定を増やすだけ(つまり、音声処理エンジン個別の実装を考慮しなくてよい)という設計になっています。
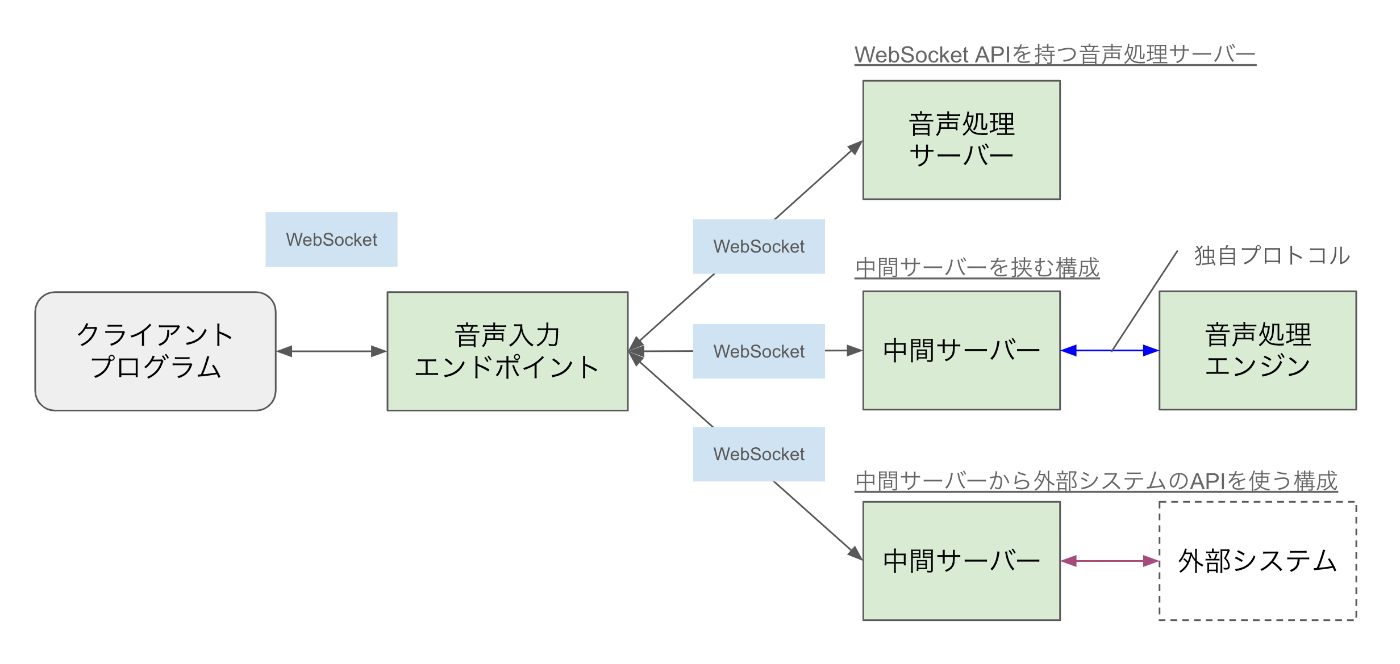
さて、そうなると、プロトコルを変換する中間サーバー部分の開発が大変になってくるわけです。当社がRustを採用したきっかけはまさにそこにあり、2022年のRust.Tokyoのセッション[6]でお話したりもしました。Zennでもいずれ記事にしたいと思いますのでしばらくお待ちください。(カジュアル面談を受けてくださればいくらでもお話しします)
さらには、WebSocketのような(HTTPに比べ)長時間の接続時間を持ち、なおかつサイズの大きいモデルデータを扱う音声処理エンジンを運用するクラウドインフラ周りの扱いにも日々苦労していますので、それらについても今後紹介していきたいと考えています。
おわりに
当社では、本記事で紹介したサーバー開発・運用や、デバイス製品の開発を一緒にやってくれるエンジニアを募集しております。製品・事業の間で壁の少ないチーム運営を心がけておりますので、組み込みからサーバーまで幅広い技術に触れられます。また、これはかねてからの切なる願いですが、私吉川が開発・実装に没頭できるよう代わりにマネージャーないし部長を担ってくれる人も大募集しております。音声技術とデバイスで顧客に最大限の価値を届けつつ、私たちのすばらしいエンジニアライフを目指して、ぜひとも協力してください!

Discussion