Cloud SpannerのMutationの運用に関するヒヤリハット
この記事はUniposアドベントカレンダー2022の6日目の記事です!
はじめに
Uniposのサーバーサイドエンジニアの周東です。
UniposがCloud Spannerで動き始めてから1年経ちました。導入当初は右も左もわからず実装してしまっていた部分を改善するフェーズに入っているのですが、その中で遭遇したヒヤリハットを共有したいと思います。
Cloud Spannerのデータ操作
Cloud SpannerにはMutationとDMLの二つのデータ操作の手段が用意されています。
DMLはクエリを記述して実行する方法で、Mutationは書き込み処理をシーケンスとしてまとめて実行する仕組みです。
公式docに違いがまとまっています。
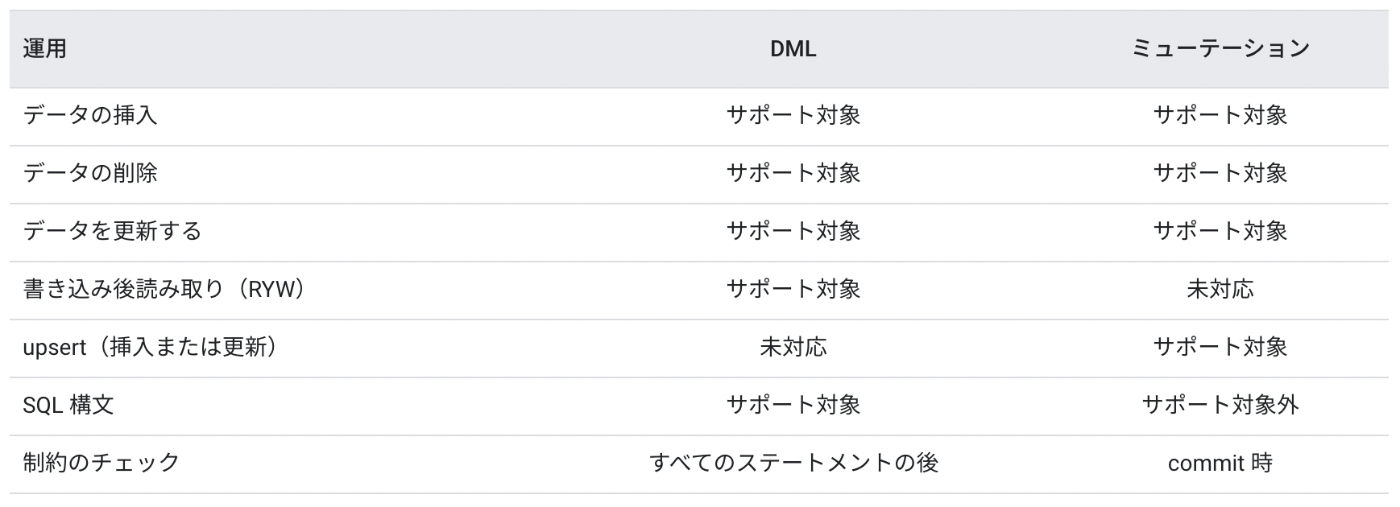
また、ベストプラクティスとして同じトランザクションでDMLとMutationを混在させてはいけないこともdocでは触れられています。DMLとMutationの実行に順序保証がないことが理由として挙げられています。Mutationはトランザクション内部でバッファリングしたデータ操作のシーケンスをアトミックに反映するものなので、トランザクションの最後にまとめてデータ操作を実行するからです。
DMLはデータ操作言語(Data Manipulation Language)で、Cloud Spannerのドキュメントを読む限りはSELECT文のサポートはされていません。データ操作の定義に選択演算は該当しないという解釈で良いと思います。
DMLは、Google Cloud Console、Google Cloud CLI、クライアントライブラリでINSERT、UPDATE、DELETE ステートメントをサポートします。
一般的な言葉としてのDMLにはSELECT操作も含む場合もあるようです。この記事では、主にMutationとクエリのトランザクションにおける実行タイミングの差に着目して議論をしたいので、SELECTもDMLに含まれるとして扱うことにしたいと思います。
ヒヤリハット
既存実装では、Mutationを用いた挿入・更新・削除を行なっている一方で、DMLによるデータの取得も行なっていました。具体的には下記のような形でdaoにして、内部で「DMLを使っているのか、Mutationを使っているのか」を隠蔽し、DBの都合を意識しない実装を行なっていました。
// WARNING: このコードは実装のイメージなので、実装は適当です
type HogeDao struct{}
// UpSertをMutationで実装
func (d HogeDao) InsertOrUpdate(ctx context.Context, tx *spanner.ReadWriteTransaction, e *Hoge) error {
e.ModifiedAt = spanner.CommitTimestamp
return d.apply(tx, e.InsertOrUpdate(ctx)) // YOが生成するメソッドを利用
}
// DeleteをMutationで実装
func (d HogeDao) Delete(ctx context.Context, tx *spanner.ReadWriteTransaction, e *Hoge) error {
return d.apply(tx, e.Delete(ctx)) // YOが生成するメソッドを利用
}
// Mutationをバッファに詰める
func (d HogeDao) apply(tx *spanner.ReadWriteTransaction, e *spanner.Mutation) error {
return tx.BufferWrite([]*spanner.Mutation{e})
}
func (d HogeDao) FindByFuga(ctx context.Context, tx spanner.YORODB, fuga string) {
return spanner.FindHogeByFuga(ctx, tx, fuga) // SQL文のDMLで実装されたメソッド
}
Usecase側ではこのような使い方になり、daoの内部実装を気にする必要がありません。
// WARNING: このコードは実装のイメージなので、実装は適当です
if _, err := client.ReadWriteTransaction(ctx, func(ctx context.Context, tx spanner.*ReadWriteTransaction) error {
// トランザクションの独立性を利用したいので、削除対象の取得も同一トランザクションに入れる。
// Hogeを取得
hoge, err := hogeDao.FindByFuga(ctx, tx, param.fuga)
if err != nil {
return err
}
// 取得できたら削除
if err := hogeDao.Delete(ctx, tx, hoge); err != nil {
return err
}
return nil
}); err != nil {
return err
}
ここで、daoの実装をusecase実装者が意識する必要がない一方で、usecase実装者は「Mutation」「DML」といったデータ操作方法のバリエーションやその違いを知らないとも言えます。ゆえに、今usecaseで使っているトランザクション内の「どこで」「何が」使われているのかも意識せずに実装することになります。これが恐怖ポイントです。
commitリクエストでトランザクションにDMLステートメントとミューテーションの両方が含まれている場合、Spannerはミューテーションの前にDMLステートメントを実行します。
とあるので、上記のusecase側の処理では問題が発生しないのですが、これがMutationとDMLの処理順序が逆になるようなトランザクションだと予期しない動作をする可能性があります。
ひよっこエンジニアが肝を冷やすにはこれだけで十分でした。今まで正常に動いていたところに安心して、それに倣って実装したり、仕様変更でトランザクションに処理を追加した途端にusecaseが壊れる可能性があったということです。真にusecaseの実装がDBの都合に影響を受けないようにするには、データ操作方法を統一する必要がありました。
対応の検討
これはまずいということで、対応を検討しました。
対応案としてはReadWriteTransaction#UpdateWithOptionsを使って、挿入・更新・削除をDMLベースの実装に変更を行うというのが有力でした。Mutationをやめることで、Write時のパフォーマンスの低下が起きる可能性を考慮して、リクエストログを付与してパフォーマンスを監視するためにOptionsでトランザクションタグとリクエストタグを付与するということを考えてました。
ですが、最終的には今回はあえて対応を行わないことにしました。
理由としては下記です。
- そもそも現状のUniposではWriteしてからReadするというusecaseは存在しない
- ドメインモデルを取得して更新を行うというケースしかない
- UpdateしてReadするなどの場合は、そもそもusecase側が分離するなど、立ち返って考えるべきではないか
- usecaseでトランザクションを生成したり、既にSpannerの都合がdaoから滲み出てしまっているので、ある程度は妥協すべきではないか
データ操作の統一を行わない代わりに、Spannerのベストプラクティスに反した形になっている理由をADRとして残すことにして、将来的に「Writeした後にReadせざるを得ず、usecase(or トランザクション単位)の分離も難しいusecase」が生まれた場合には再度この問題の検討をできるように備えることにしました。
同様の課題に直面している方は他にもいるようで、ソシャゲのAPIサーバでWriteからReadをしたいという需要があったのでDMLに統一しているケースや、ORMを提供する上でユーザがデータ操作方式を意識する必要がないようにDMLのみをサポートしたケースなどを観測しました。
弊社ではCloud SpannerのGolangテンプレートコードの生成にメルカリさんのyoを利用させていただいています。本当にメルカリさんには頭が上がらない。yoが生成するコードはMutationとDML(主にSELECT)が混在するファイルを生成するので、実装者さんたちがどんな思想でどんな運用をしているのかは個人的に気になるところでした。
さいごに
1年強Cloud Spannerを利用してみて、ある程度知見も溜まり、理解度も高まったところで、リファクタリングのフェーズに入ってきました。今後もリファクタリングの途中で遭遇した落とし穴やその対応があれば、共有していきますのでどこかの誰かの役に立てれば幸いです。
Discussion