はじめまして、株式会社エクサウィザーズのWANDチームでインターンをしている村井です。
エクサウィザーズTechBlogの以前の記事では、AWS Inferentia2を用いてLlama 3.2 の推論サーバーを立ち上げました。この記事ではさらにユースケースを検討するために、(1) インスタンスごとに動かせる最大モデル, (2) Neuronコンパイルによる推論性能の変化 の2点を検証したのち、Cline上でコーディングエージェントとして動かすことを試みます。
AWS Inferentia2 とは
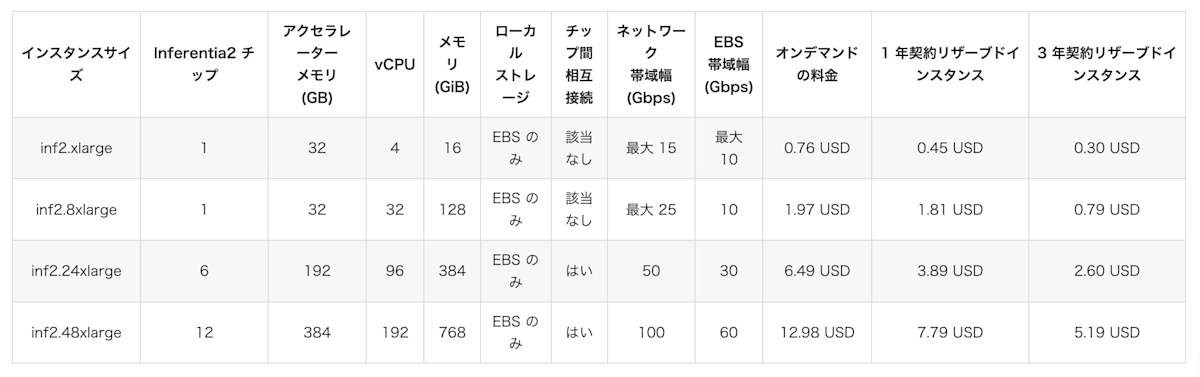
以前の記事で詳しく説明していますが、AWS Inferentia2 はAWSの開発した深層学習モデルの推論用のチップです。AWS EC2ではinf2.xlarge から inf2.48xlarge までの4種類のインスタンスが提供されており、概ねGPUインスタンスよりも安価に大きなVRAM (に相当するメモリ) を確保し、大型の言語モデルなどをホストできる点が強みです。以下の料金表はAWSのEC2 Inf2 インスタンスのページから引用しました。
Inferentia上の推論では、AWS Neuron SDK と呼ばれる独自のコンパイラを用いて、torchやTFで書かれたモデルを変換する必要があります。そのため同じモデルでも使い勝手が異なり、(1)実際にどのインスタンスでどのぐらいのモデルが動くのか、 (2)GPUに比べてパフォーマンスが落ちないか、というところが未解明です。そこで、この記事では主に Llamaの中規模モデルをサイズを変えながらコンパイルを試し、推論性能についてベンチマークを取りました。
インスタンスごとの起動可能サイズ
inf2上でモデルをコンパイルするとき、 max_len と tensor_parallel_size というパラメータを指定することができます。 max_len についてはモデルの扱えるコンテクストの最大長で、 tensor_parallel_size はTensor Parallel (TP) という並列化のパラメータです。TPについては公式ドキュメント やAWSブログのこちらの記事に詳しく書かれています。
大事なところを確認すると、まずTensor Parallel は複数のコアにテンソルを分けて計算することで、メモリを効率的に使うための技術です。実際、TP=1の場合はほとんどのモデルが動きませんが、適切にTPを増やすことで長いコンテクスト長でも動かすことができます。
先述のブログ記事によると、inf2では現在、TPの値として1、2、4、8、24がサポートされています。1つのInferentia2チップが二つのコアを持つので、例えば1つのチップがある inf2.xlarge や inf2.8xlarge ならTP=2, 6つのチップがある inf2.24xlarge なら TP=12 (は対応していないので、TP=8) までは効果が見込めます。ということで以下、TPについては小さいインスタンスでは2, 大きいインスタンスでは8として検証を行いました。
inf2.xlarge / inf2.8xlarge での起動可能サイズ
この二種のインスタンスはInferentiaのチップ数が同じで、使用できるCPUとデバイスのメモリが異なります。しかし、検証した限りでは Inferentiaチップがボトルネックになるため、この二つのインスタンスで扱えるモデルの大きさは大差ないようでした。
コンテクスト長を増やしていったところ、1024トークンまでは起動させられました。
| max_len | TP | コンパイル可能 | 推論可能 | コンパイル時間 |
|---|---|---|---|---|
| 256 | 2 | OK☑️ | OK☑️ | 20分 |
| 1024 | 2 | OK☑️ | OK☑️ | 25分 |
| 2048 | 2 | NG❌ | NG❌ | NaN |
当初の見込みでは、大きなモデルのコンパイルにはメモリを多く使うはずなので、コンパイルのみを大きなインスタンスで行い、推論のみを小さいインスタンスで行うことで効果的にEC2を使えると考えていました。しかしInferentiaチップのボトルネックが大きく、TPの度合いを増やせない小さいインスタンスでは、予想よりも使えるコンテクスト長が限られます。
Inf2.24xlarge での起動可能サイズ
次に、6つのInferentiaチップを持つ inf2.24xlarge で実験を行うと以下のようになりました。
| max_len | TP | コンパイル可能 | 推論可能 | コンパイル時間 |
|---|---|---|---|---|
| 2048 | 8 | OK☑️ | OK ☑️ | 12分 |
| 8192 | 8 | OK ☑️ | OK ☑️ | 16分 |
| 32768 | 8 | OK ☑️ | OK ☑️ | 38分 |
| 65536 | 8 | OK ☑️ | NG ❌ |
コンパイルは65Kトークン程度まで行えますが、推論サーバーを立ち上げることはできませんでした。実質32Kトークン程度が上限ということがわかりました。
また、TPの強さを比較すると以下のような結果が得られました。
| max_len | TP | コンパイル可能 | 推論可能 | コンパイル時間 |
|---|---|---|---|---|
| 2048 | 8 | OK ☑️ | OK ☑️ | 12分 |
| 2048 | 2 | OK ☑️ | OK ☑️ | 26分 |
| 8192 | 8 | OK ☑️ | OK ☑️ | 18分 |
| 8192 | 2 | OK ☑️ | NG ❌ | 2時間 |
| 32768 | 8 | OK ☑️ | OK ☑️ | 38分 |
| 32768 | 2 | NG ❌ | NG ❌ | 4時間 |
TP=2の場合、max_len = 8K でも推論ができませんが、TP=8にすることで max_len = 32K まで推論が可能です。さらに、少ないTPの場合に比べてコンパイル時間も非常に高速になっていることがわかります。
まとめ:各インスタンスでの起動可能サイズ
| インスタンス | チップ数 | コンパイル・推論可能サイズ |
|---|---|---|
| inf2.xlarge | 1 | 1024 (TP = 2) |
| inf2.8xlarge | 1 | 1024 (TP = 2) |
| inf2.24xlarge | 6 | 32768 (TP = 8) |
ベンチマーク
AWS Inferentia で言語モデルを動かすとき、Neuron で動作可能にするためにコンパイルが入ります。実用上はそこで性能低下などが起きないか気になるところです。そこで、 (1) GPU + CUDA + Torch で動かす素の Llama3.2-11B-Vision-Instruct, (2) 同じモデルをNeuronコンパイルして Inferentia で動かしたもの, 最後に (3) AWS Bedrock で提供されているLlama3.2-11B-Vision-Instruct の3種類の性能を比較します。
ベンチマークには lm-eval こと lm-evaluation-harnessを用います。今回はLlama公式の設定にならって、gsm8kという算数のデータセットを 8-shot, CoTあり、評価指標は flexible-extract (解答の最後に出てくる数字を正規表現で取得し、答えと同じなら正) で解かせます。なお参考までに、Llama3 8B のスコアは 公式のTechnical Report によると 84.5% です。
ベンチマーク1. GPUの場合
実験はAWS EC2 の g6e.2xlarge インスタンスで行いました。NVIDIA L40S Tensor Core GPU が1枚載っているインスタンスです。その他のGPUでも手順は同様です。
手順として、まずはCUDA + Python環境を用意して pip install lm-eval で lm-eval をインストールします。
GPUの場合はHugging Face を用いるので、Llama 3.2 のライセンスに同意したのち、トークンを取得して環境変数に設定しておきます。
export HF_TOKEN=xxxxxxxxxxx
その後、次のコマンドを打つと自動的にHFから重みを取得し、ベンチマークを走らせてくれます。
lm_eval --model hf \
--model_args "pretrained=meta-llama/Llama-3.2-11B-Vision-Instruct" \
--tasks gsm8k_llama \
--apply_chat_template \
--log_samples \
--batch_size auto \
--output_path ./results_hf/results.json
結果は以下のようになりました。
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| gsm8k_llama | 3 | flexible-extract | 8 | exact_match | ↑ | 0.7710 | ± | 0.0116 |
ベンチマーク2. Neuron + Inferentia の場合
Inferentia の場合、まずは前回の記事の手順でinf2サーバーの localhost:8000 でサーバーを起動します。inf2のサーバー上でベンチマークを行うこともできますが、今回はポートフォワーディングを行って、接続元のPCから動かすことにします。
VSCodeでGUIから接続している場合は、PORTSタブからEC2インスタンスにポートフォワーディングを行うことができます。ターミナルでSSM接続をしている場合は、新しいターミナルで次のコマンドを打ちます。
aws ssm start-session \
--target <インスタンスID> \
--profile <AWSのプロファイル名>\
--document-name AWS-StartPortForwardingSession \
--parameters '{"portNumber":["8000"], "localPortNumber":["8000"]}'
ポートフォワーディングをしている場合はローカルで、していない場合はEC2上でlm-evalをインストールした環境を用意し、以下のコマンドを打ちます。いずれにしても打つコマンドは同じです。
lm_eval --model local-chat-completions \
--model_args "model=/home/ubuntu/Llama-3.2-11B-Vision-Instruct,base_url=http://localhost:8000/v1/chat/completions" \
--tasks gsm8k_llama \
--apply_chat_template \
--log_samples \
--batch_size auto \
--output_path ./results_inf/results.json
OpenAI 互換サーバーで動かす場合は --model 引数を local-chat-completions にして、--model_args にモデル名とURLを指定します。このモデル名は、inf2でサーバーを立ち上げた際に MODEL_PATH に指定したものと同じである必要があります。さて、推論結果は以下の通りです。
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| gsm8k_llama | 3 | flexible-extract | 8 | exact_match | ↑ | 0.7642 | ± | 0.0117 |
素のモデルに比べて0.7%ほど正答率が悪化しましたが、ほぼ同程度と言って差し支えない結果になりました。
ベンチマーク3. Amazon Bedrock の場合
最後に、AWSで言語モデルを使うなら選択肢に入るであろう、Amazon Bedrock のモデルを試します。これはAmazonがホストしている推論エンドポイントで、us-east-1 ではLlama-3.2-11B-Vision-Instruct も用意されています。
ところで、Bedrockは独自のAPIを持っており、そのままでは lm-eval で動かせません。そこで LiteLLM を用いて、推論リクエストを Bedrock に渡す OpenAI 互換のサーバーを建てます。まず、lm-evalと同じ環境に pip install boto3 "litellm[proxy]" で boto3 と litellm をインストールします。
続いて、Bedrockのアクセストークンを取得します。このトークンには12時間で切れる短期のものと、失効するまで使える長期のものがあります。短期の場合、次のように環境変数に設定します。
export AWS_BEARER_TOKEN_BEDROCK=xxxxxxxxxxx
長期の場合は、アクセスキーIDとシークレットアクセスキーの二つが発行されます。それぞれ環境変数に設定します。
export AWS_ACCESS_KEY_ID=xxxxxxxxxxx
export AWS_SECRET_ACCESS_KEY=xxxxxxxxxxx
次に、litellm 用の設定ファイルである config.yaml を用意します。次の内容を config.yaml として保存します。
litellm_settings:
drop_params: true
model_list:
- model_name: bedrock/llama3-2-11b-instruct
litellm_params:
model: bedrock/us.meta.llama3-2-11b-instruct-v1:0
aws_region_name: us-east-1
aws_session_token: os.environ/AWS_BEARER_TOKEN_BEDROCK
いくつか注意があります。まず、モデルによってはモデル名 (例: meta.llama3-2-11b-instruct-v1:0 )を指定する必要があり、その他のモデルは推論エンドポイント名 (例: us.meta.llama3-2-11b-instruct-v1:0) を指定する必要があります。
また、先ほどの手順で長期トークンを発行した場合は、aws_session_token は不要です。代わりに litellm_params に次のように書きます。
aws_access_key_id: os.environ/AWS_ACCESS_KEY_ID
aws_secret_access_key: os.environ/AWS_SECRET_ACCESS_KEY
さて、 config.yaml を作ったら、ターミナルで次のコマンドを打つとOpenAI形式のサーバーが立ち上がります。
litellm --config config.yaml
デフォルトではポート番号4000を使っています。あとはInferentiaの場合と同じようにベンチマークを走らせます。
lm_eval --model local-chat-completions \
--model_args "model=bedrock/llama3-2-11b-instruct,base_url=http://localhost:4000/chat/completions" \
--tasks gsm8k_llama \
--apply_chat_template \
--log_samples \
--batch_size auto \
--output_path ./results_bedrock/results.json
model_args の model には、先ほどのconfig.yamlで設定した model_name と同じものを入力します。長かったですが、これでBedrockのモデルのベンチマークが取れました。結果は次のとおりです。
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| gsm8k_llama | 3 | flexible-extract | 8 | exact_match | ↑ | 0.8127 | ± | 0.0107 |
ベンチマークのまとめ
今までの結果をまとめると、次のようになります。
| Model | Filter | n-shot | Metric | Value | Stderr | Time [s] | ||
|---|---|---|---|---|---|---|---|---|
| CUDA + GPU | flexible-extract | 8 | exact_match | ↑ | 0.7710 | ± | 0.0116 | 7950 |
| Neuron + inf2 | flexible-extract | 8 | exact_match | ↑ | 0.7642 | ± | 0.0117 | 5757 |
| Bedrock | flexible-extract | 8 | exact_match | ↑ | 0.8127 | ± | 0.0107 | 2900 |
推論精度を考慮すると、GPUで動かした Hugging Face (transformers) のモデルはfloat32で推論しているのに対して、Neuronのモデルはvllmのためfloat16で推論を行なっているはずです。
そのためNeuronのモデルの正答率が多少落ちるのは想像通りですが、Bedrock のモデルが元のものよりも正答率が高いという疑問の残る結果になりました。念のため数回走らせましたが、分散は僅かでした。Bedrock上のモデルはベースプロンプトや推論パラメータが内部でチューニングされている可能性が考えられます。
推論時間については、GPU (NVIDIA L40Sx1) が2.2時間、Neuron+inf2が1.6時間、Bedrockが0.8時間という結果になりました。厳密な計測はできていませんが、AdaシリーズのGPUよりも1.4倍ほどInferentiaが高速だというのは嬉しい結果です。
また、オリジナルの報告された性能がもう少し高いのも疑問です。この点については、以下のディスカッション が参考になりそうでした。手元では試せていませんが、Meta llamaチームの方曰く、 fewshot_as_multiturn などの設定を付け加えて、さらに時間をかけて推論すると正答率が上がるようです。
Llama+Clineでコーディングエージェント
最後に、実際のユースケースとして、Llamaの推論サーバーを用いてコーディングエージェントを立ち上げます。今回はオープンソースで使える Cline を用いました。
まず、Visual Studio Code に Cline の拡張機能をインストールします。先ほど行ったようにポートフォワーディングを行い、ローカルからLlama推論サーバーにポートがつながっているものとします。今回はデフォルト設定で動かしたものとして localhost:8000/v1 を推論エンドポイントとして用います。
Cline の API Configuration に以下のように入力します。
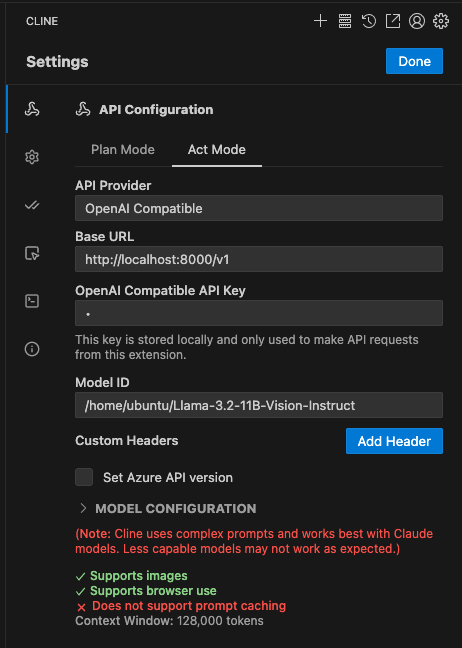
OpenAI Compatible API Key は今回不要ですが、空欄にするとエラーになるので、任意の文字列を入力しましょう。特に詰まらなければ、Clineのチャット画面に何か指示を出すと動いてくれるはずです。試しにFizzBuzzを書いてもらいました。
Cline を動かすにはコンテクスト長が最低12000程度は必要です。最初に長いメッセージが与えられるためです。そのため、残念ながらInferentiaでコーディングエージェントをセルフホストするには、inf2.24xlarge のような巨大なインスタンスを使う必要があるようです。
また、Cline上ではコンテクストは128kと表示されていますが (これはLlama 3.2-11B の標準コンテクスト長です) Neuronでコンパイルしたモデルを使う時はそちらで指定した長さまでしか対応していません。
おわりに
この記事では、AWS Inferentia2 とLlama 3.2-11B-Vision-Instruct を用いて、扱えるコンテクスト長、ベンチマーク、推論速度について検証を行いました。結果として、シングルストリームでの推論速度はAda世代のGPUよりも高速なものの、長いコンテクストを扱うにはかなり大きなインスタンスが必要で、そこがボトルネックだとわかりました。検証には含めていませんが、今回はVision 付きのモデルの他に、別途テキストのみの Llama3.1-8B も動かしました。しかし、テキストのみのモデルでも扱えるコンテクスト長は大きく変わらないようでした。
一方でNeuronのコンパイルには、今回は触れていない大量のパラメータがあるため、さらに最適化を強めることで小さいインスタンスでも動作する可能性があります。neuron-monitor を用いたメモリ監視なども行いたかったものの、手元の環境ではうまく動かすことができませんでした。これらは今後の課題とするところです。

Discussion