本記事の目標
先端技術開発グループ(WAND)の佐藤碧と小島啓明です。2025年7月にAWSで開催されたNeuron Community Vol.2というイベントに参加してきました。当時のハンズオンに基づき、機械学習アクセラレーター「AWS Inferentia」で推論サーバーを立ち上げる手順を解説します。
当時のハンズオンではコンパイル済みモデルを使用しましたが、本記事ではInferentia用モデルのコンパイルから始め、任意のモデルをホストする一連の流れを紹介します。
AWS Inferentiaとは
AWS Inferentiaは、AWSが開発するAI専用チップで、GPUと比較して高いコストパフォーマンスを誇ります。特に、LLM(大規模言語モデル)のホストにおいて注目されています。下記の表は以前のAWS Summitの参加報告の記事の再掲です。
| インスタンスタイプ | アクセラレーター | アクセラレーターメモリ | バージニア(us-east-1) | 東京(ap-northeast-1) | 東京の1ドルあたりメモリ(GB・h/USD) |
|---|---|---|---|---|---|
| inf2.24xlarge | Inferentia2チップ×6 | 192 GB | USD 6.491 | USD 9.736 | 19.721 |
| inf2.48xlarge | Inferentia2チップ×12 | 384 GB | USD 12.981 | USD 19.472 | 19.721 |
| g6.48xlarge | L4 24GB GPU×8 | 192 GB | USD 13.350 | USD 19.362 | 9.916 |
| g6e.24xlarge | L40S 48GB GPU×4 | 192 GB | USD 15.066 | USD 21.850 | 8.787 |
| g6e.48xlarge | L40S 48GB GPU×8 | 384 GB | USD 30.131 | USD 43.699 | 8.787 |
| p4d.24xlarge | A100 40GB GPU×8 | 320 GB | USD 21.958 | USD 30.098 | 10.632 |
| p4de.24xlarge | A100 80GB GPU×8 | 640 GB | USD 27.447 | USD 37.622 | 17.011 |
※上記はEC2のオンデマンドインスタンスの1時間あたりの料金(2025年7月現在、AWSの公式より)。一番右の列は、1ドルあたりに利用できるアクセラレーターメモリ量(GB・h/USD)で、数値が高いほどコスト効率が良いことを示します。

免責事項
- 本記事は2025年8月時点の情報で、Neuron 2.25.0を前提としています。
- 動作確認はEC2 AMI「Deep Learning AMI Neuron (Ubuntu 22.04) 20250731」(
ami-0aea5bf206fcd4a09, us-east-1) を使用しています。 - Neuron SDKやvLLMは更新が速いため、本手順は将来的に利用できなくなる可能性があります。あくまで参考としてご覧ください。
本記事の目標や全体像
本記事では、Meta社のLlama-3.2-11B-Vision-Instructをコンパイルし、デプロイすることを目指します。
Neuron SDKの公式チュートリアルでも同様のことを行っていますが、仮想環境のPyTorchのバージョン(公式チュートリアルでは2.6ですが、本記事では2.7を使用)や、モデルの変換方法が少し異なります。
2025年8月現在、InferentiaでのLLMのコンパイルとホスティングは、OSSのvLLMを用いるのが主流です。vLLMを利用することで、Neuron SDKの実装を抽象化しつつ、OpenAI互換のエンドポイントを簡単に構築できます。
今回のアーキテクチャは以下の通りです。
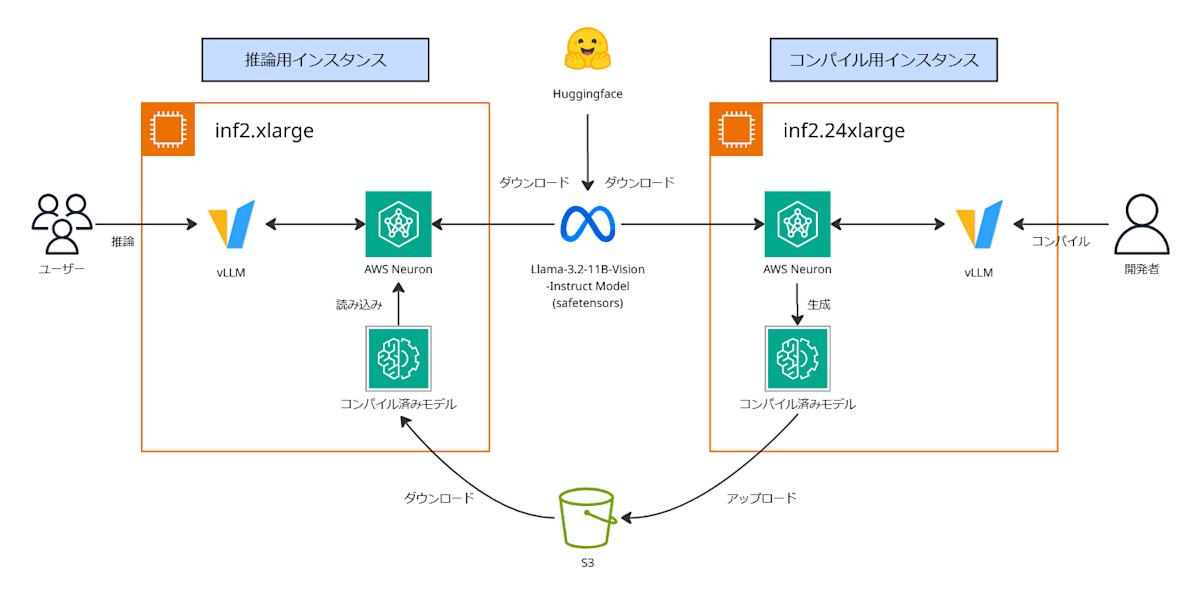
vLLMはホスティング時にモデルをコンパイルできますが、それにはinf2.24xlargeのような大型で高価なインスタンスが必要です。
そのため、本記事ではコスト効率を考え、まず大型インスタンスでモデル(Llama-3.2-11B-Vision-Instruct)をコンパイルしてS3に保存し、推論時はinf2.xlargeのような小型インスタンスでそのモデルを読み込んでホストします。
事前準備1:Hugging Face
Llama 3.2はダウンロードに認証が必要なため、Hugging Faceのアカウントが必要です。持っていない場合はアカウントを作成してください。
Hugging Face上でLlama-3.2-11B-Vision-Instructのモデルアクセスを申請し、「You have been granted access to this model」と表示されている状態にします。
EC2からのモデルダウンロードに使用するため、Hugging Faceのトークンを取得します(右上のアイコン→Access Tokens)。「Read」権限が必要です。
事前準備2:VPCの作成
以下のアーキテクチャ図のVPCを作成します。ap-northeast-1の場合は、inf2.48xlarge
のような大きなインスタンスが欠品していたため、us-east-1でテストしています。
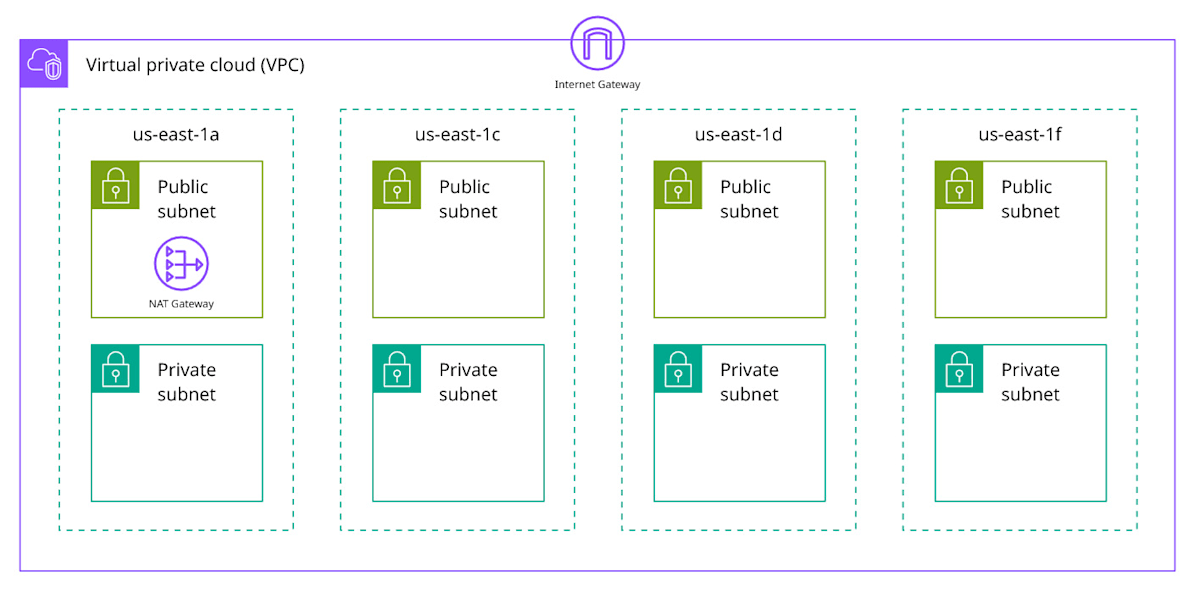
us-east-1の場合は、2025年8月現在、「1a, 1c, 1d, 1f」のAZでinf2.24xlargeが利用可能でした。EC2をプライベートサブネットに配置し、外部からモデル等をダウンロードするためにNATゲートウェイを設定します。接続にはSession Managerを使用します。
EC2でモデルをコンパイルする
EC2の作成
コンパイルでは推論と比べて大量のホストメモリが必要です。Neuron Communityで後から教えていただいたのですが、コンパイルで必要なのは「アクセラレーターのメモリではなくホストメモリで、モデルのコンパイルだけであればinf2でなくCPUインスタンスでも実行可能です!」とのことでした。貴重な情報ありがとうございました!
AWSコンソールから、コンパイル用にinf2.24xlargeまたはinf2.48xlargeなどの大きめのインスタンスを作成します。特にinf2.48xlargeの場合、vCPUが192のため、クォーターに抵触し、上限解放申請が必要な場合があります(「Service Quotas」→「Amazon EC2」→「Running On-Demand Inf instances」を193以上にする)。
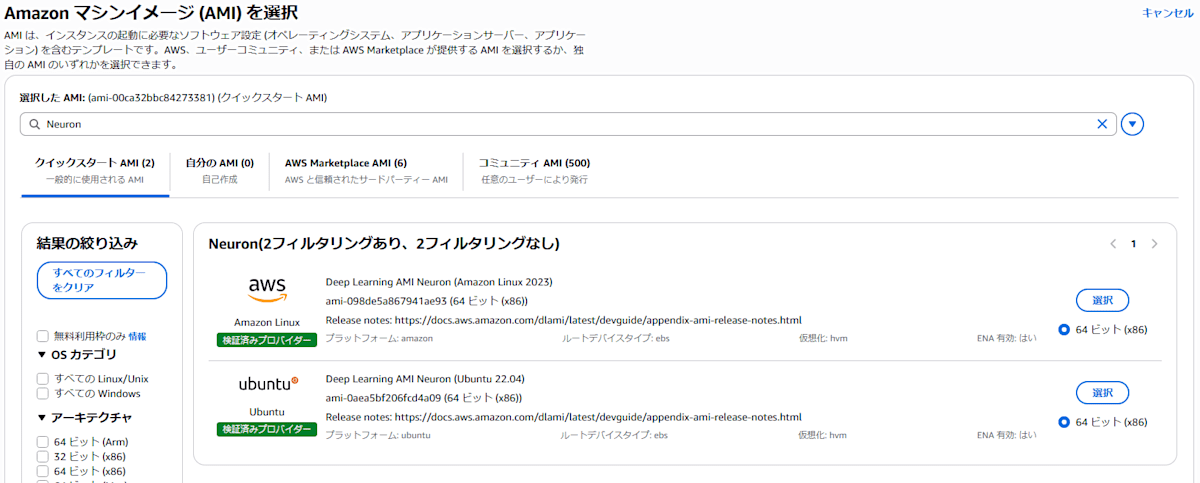
AMIは「その他のAMIを閲覧する」をクリックし、「Neuron」で検索し、「Ubuntu」のOSを選択します。プライベートサブネットとします。
出力用S3バケットに読み書きでき、AmazonSSMManagedInstanceCoreポリシー(Session Manager用)を持ったIAMロールを作成し、EC2作成時にインスタンスプロファイルとしてアタッチしておきます。
一連のコンパイル作業は、長い場合に1~2時間かかります。ライブラリのインストールやモデルのダウンロード、Neuronでのコンパイルなどが時間を要します。
接続と環境の確認
「EC2 > インスタンス > 自分の作成したインスタンス」で、接続をクリックし、セッションマネージャーで接続します。仮想環境に入ります。
# ubuntuユーザーに切り替え
sudo su ubuntu
# 仮想環境に入る
source /opt/aws_neuronx_venv_pytorch_2_7_nxd_inference/bin/activate
cd ~
※Neuron SDKのチュートリアルには、PyTorch2.6 が書いてありますが、bash: /opt/aws_neuronx_venv_pytorch_2_6_nxd_inference/bin/activate: No such file or directoryと表示され、このAMIには存在しませんでした。
仮想環境の一覧はls /optで見られます。
$ ls /opt/
amazon aws_neuronx_venv_jax_0_6 aws_neuronx_venv_pytorch_2_7_transformers
aws aws_neuronx_venv_pytorch_2_7 aws_neuronx_venv_tensorflow_2_10
aws_neuron_venv_pytorch_1_13_inf1 aws_neuronx_venv_pytorch_2_7_nxd_inference containerd
aws_neuron_venv_tensorflow_2_10_inf1 aws_neuronx_venv_pytorch_2_7_nxd_training eni
また、ライブラリのバージョンは以下の通りになっています。
$ pip list | grep neuron
libneuronxla 2.2.8201.0+f46ac1ef
neuronx-cc 2.20.9961.0+0acef03a
neuronx-distributed 0.14.18122+d467a294
neuronx-distributed-inference 0.5.9230+dcf1e2da
torch-neuronx 2.7.0.2.9.9357+08e1f40d
vLLMのインストール
vLLMをインストールする際は、Neuronに対応したAWS公式のフォークリポジトリ「upstreaming-to-vllm」を指定します。
vLLMのNeuron対応機能はこのリポジトリで開発されています。今回はバージョン2.25.0を使用しますが、リポジトリで最新版を確認してください。
# vLLM のインストール(-bでバージョンを指定)
git clone -b 2.25.0 https://github.com/aws-neuron/upstreaming-to-vllm.git
cd upstreaming-to-vllm
pip install -r requirements/neuron.txt
VLLM_TARGET_DEVICE="neuron" pip install -e .
# ホームディレクトリに移動
cd ~
モデルのダウンロード
「事前準備:Hugging Face」で、meta-llama/Llama-3.2-11B-Vision-Instructへのモデルアクセスの承認と、Hugging Faceのトークンを取得済みとします。
# Hugging Face CLIのインストール
pip install hf_transfer "huggingface_hub[cli]"
# --tokenにHugging Faceのトークンを入力
hf download meta-llama/Llama-3.2-11B-Vision-Instruct \
--local-dir ./Llama-3.2-11B-Vision-Instruct \
--exclude "original/" \
--token hf_xxxxxxxxxx
モデルのコンパイル
2025年8月現在のvLLMでは、推論サーバーを起動したときにコンパイル済みのモデルが NEURON_COMPILED_ARTIFACTS にない場合、モデルのコンパイルが走ります。その後、NEURON_COMPILED_ARTIFACTS にコンパイル済みモデルが保存されます。このコンパイルに大きなメモリが必要なので、初回だけ推論サーバーとは独立したインスタンスで行います。
# 元モデルのパスと、コンパイル済みモデルの保存先を指定
export MODEL_PATH='/home/ubuntu/Llama-3.2-11B-Vision-Instruct'
export NEURON_COMPILED_ARTIFACTS='/home/ubuntu/Llama-3.2-11B-Vision-Instruct-neuron'
# 推論サーバーを起動(コンパイル)
python3 -m vllm.entrypoints.openai.api_server \
--model $MODEL_PATH \
--device neuron \
--tensor-parallel-size 2 \
--max-model-len 256 \
--max-num-seqs 1
モデルのコンパイル中、Neuronのメモリが不足した場合は、--max-model-lenや--tensor-parallel-sizeを調整します。テンソルパラレルは、モデルを複数のチップに分割して処理するための設定で、モデル構造上割り切れないと失敗するケースがあるため注意してください。このコンパイルには数十分要しますが、以下のような表示が出れば完了です。
INFO: Waiting for application startup.
INFO: Application startup complete.
「/home/ubuntu/Llama-3.2-11B-Vision-Instruct-neuron」というフォルダがホーム以下に作成され、その中身に model.pt などがあることを確認してください。
リクエストを送る(オプション)
上のコマンドは vLLM サーバーも起動しているので、推論リクエストを送ることができます。推論サーバーとして利用するにはインスタンスが大きすぎるため、コストが高額になります。検証程度にとどめて、小さなインスタンスで検証をした方が良いです。
サーバーの起動によってシェルがブロックされているため、新たにシェルを起動して(EC2のコンソールから接続した場合は新たなSession Manager)以下のコマンドを実行します。
# オプション:ブラウザ経由のSession Managerのみ必要
sudo su ubuntu
cd ~
# モデルのパスを指定
export MODEL_PATH='/home/ubuntu/Llama-3.2-11B-Vision-Instruct'
# リクエストの送信
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "'"$MODEL_PATH"'",
"messages": [
{
"role": "user",
"content": "What is the capital of Italy?"
}
]
}'
以下のように「The capital of Italy is Rome.」と出力されればOKです。
{"id":"chatcmpl-0eedbd632f7f4cde98d642d64add519a","object":"chat.completion","created":1756382152,"model":"/home/ubuntu/Llama-3.2-11B-Vision-Instruct","choices":[{"index":0,"message":{"role":"assistant","reasoning_content":null,"content":"The capital of Italy is Rome.","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":42,"total_tokens":50,"completion_tokens":8,"prompt_tokens_details":null},"prompt_logprobs":null,"kv_transfer_params":null}
モデルの重みを S3 にアップロードする
適当に S3 バケットを作成し、EC2インスタンスがそれに読み書きできるものとします。S3バケットに、作成された重みを保存します。
# zipに圧縮
zip -r ./Llama-3.2-11B-Vision-Instruct-neuron.zip ./Llama-3.2-11B-Vision-Instruct-neuron/
# S3にアップロード
aws s3 cp ./Llama-3.2-11B-Vision-Instruct-neuron.zip s3://<バケット名>/<パス>
コンパイル用のインスタンスは使用しないので停止します。
EC2で推論用のvLLM サーバーを起動する
ここからは推論用に、より安価なインスタンスを用意します。「Llama-3.2-11B-Vision-Instruct」の場合、inf2.xlargeで動作することを確認済みです。
方法として、インスタンスを新規作成するか、コンパイル用インスタンスのタイプを変更するかの2通りがあります。
後者の場合、インスタンスを停止してからタイプを変更し、「コンパイル済みモデルのダウンロード」の節へ進んでください。本記事では、前者(新規作成)の手順を解説します。
(新規にインスタンス作成する場合)環境構築とモデルダウンロード
コンパイル用のインスタンスと同様に、プライベートサブネットにS3の権限を与えた上でEC2を作り、Session Managerで接続します。仮想環境に入り、vLLMをインストールします。
# 仮想環境に入る
sudo su ubuntu
source /opt/aws_neuronx_venv_pytorch_2_7_nxd_inference/bin/activate
cd ~
# 同じインスタンスで行っていない場合
# vLLM のインストール
git clone -b 2.25.0 https://github.com/aws-neuron/upstreaming-to-vllm.git
cd upstreaming-to-vllm
pip install -r requirements/neuron.txt
VLLM_TARGET_DEVICE="neuron" pip install -e .
cd ~
Hugging Faceからモデルをダウンロードします。
# Hugging Face CLIのインストール
pip install hf_transfer "huggingface_hub[cli]"
# --tokenにHugging Faceのトークンを入力
hf download meta-llama/Llama-3.2-11B-Vision-Instruct \
--local-dir ./Llama-3.2-11B-Vision-Instruct \
--exclude "original/" \
--token hf_xxxxxxxxxx
コンパイル済みモデルのダウンロード
S3バケットからコンパイル済みモデルをダウンロードします。
aws s3 cp s3://<バケット名>/<パス> ./Llama-3.2-11B-Vision-Instruct-neuron.zip
unzip ./Llama-3.2-11B-Vision-Instruct-neuron.zip
解凍後のディレクトリは以下のようなファイル構成になっています。
$ ls -l ./Llama-3.2-11B-Vision-Instruct-neuron
total 237220
-rw-rw-r-- 1 ubuntu ubuntu 225627028 Aug 27 10:51 model.pt
-rw-rw-r-- 1 ubuntu ubuntu 11013 Aug 27 10:32 neuron_config.json
-rw-rw-r-- 1 ubuntu ubuntu 454 Aug 27 10:51 special_tokens_map.json
-rw-rw-r-- 1 ubuntu ubuntu 17210088 Aug 27 10:51 tokenizer.json
-rw-rw-r-- 1 ubuntu ubuntu 55808 Aug 27 10:51 tokenizer_config.json
推論サーバーを起動
vLLMで推論用のサーバーを起動します。vllm.entrypoints.openai.api_serverの引数をコンパイル時と揃えることで、再コンパイルを抑えることができます。
export MODEL_PATH='/home/ubuntu/Llama-3.2-11B-Vision-Instruct'
export NEURON_COMPILED_ARTIFACTS='/home/ubuntu/Llama-3.2-11B-Vision-Instruct-neuron'
python3 -m vllm.entrypoints.openai.api_server \
--model $MODEL_PATH \
--device neuron \
--tensor-parallel-size 2 \
--max-model-len 256 \
--max-num-seqs 1
「Application startup complete.」と表示されたら、起動完了です。
リクエストを送る
新しく Session Manager 接続をして、仮想環境に入るところまで行ってください。
# オプション:ブラウザ経由のSession Managerのみ必要
sudo su ubuntu
cd ~
# 仮想環境に入る
source /opt/aws_neuronx_venv_pytorch_2_7_nxd_inference/bin/activate
# 推論エンドポイントにリクエストを送信
export MODEL_PATH='/home/ubuntu/Llama-3.2-11B-Vision-Instruct'
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "'"$MODEL_PATH"'",
"messages": [
{
"role": "user",
"content": "What is the capital of Italy?"
}
]
}'
「The capital of Italy is Rome.」と表示されれば無事完了です。
今後の応用
vLLMのvllm.entrypoints.openai.api_serverは、OpenAIのAPI形式でホストしているため、OpenAIのSDKからの推論リクエストや、OpenAIのAPI形式に対応しているコーディングエージェントからのリクエストも容易に対応できるはずです。これは今後機会があれば書いていきたいです。
neuronx-patternsを使わなかった理由
当初、AWS BatchベースのOSS aws-cdk-neuronx-patterns の利用を試みましたが、解決が難しいコンパイルエラーが多発し、数日レベルで詰まってしまったため、採用を見送りました。
主な問題点
-
vllm serve実行時の内部エラー - 独自にコンパイルコードを書こうとすると、マルチモーダルモデルなど、特定のアーキテクチャでコンパイルが通らない
- ベースのイメージを変えても通らない
- CDK→Terraformベースの再現や移植の難しさ(Batchは動いたものの内部でコンパイルエラーが出ている)
EC2上でDockerを立てて調査したところ、ここ数ヶ月のアップデートによるライブラリ間のバージョン差異が原因と考えられました。このため、今回はEC2上で直接コンパイルする方法を選択しています。公開当時は正常に動いたはずです。
結果的には、Neuron Communityのイベントのハンズオンをほぼ踏襲する形となりましたが、ご容赦ください。当時のハンズオンはNeuron CommunityのDiscord上で公開されており、Gradioによるデモアプリのホストなどが続きます。これ以外にも多数有益なコンテンツがありますので、ぜひこちらも参照してみてください。
- Neuron CommunityのDiscord上で公開されている日本語ハンズオン
- AWS Neuron Community (Discord) : https://discord.gg/DUx4g3Z3pq
- 【開催報告】Neuron Community – Vol.2
まとめ
本記事では、AWSのAIアクセラレーター「Inferentia2」上で、LLM(Llama 3.2)をコンパイルし、vLLMで推論サーバーをホストするまでの一連の手順を解説しました。
特に、高価な大規模インスタンスでコンパイルを行い、安価な小規模インスタンスで推論するという、コスト効率の良い実践的な手法を紹介しました。
当初検討していた aws-cdk-neuronx-patterns はライブラリのバージョン差異により断念しましたが、結果としてNeuronのAMIや事前に用意されている仮想環境が強力であることがわかりました。Docker化は近年の開発の定石ですが、Neuronに関しては、EC2上で直接環境を構築するアプローチが現状では近道かもしれません。
今後この仕組みを自動化するなら、「Step Functions」や「SSM Run Command」などを活用することが考えられます。機会があれば、そちらも検証していきたいです。
本記事について
本記事は、サマーインターンのオンボード資料として、技術検証していたものですが、一定需要がありそうなのでテックブログとして公開いたしました。
技術検証については佐藤碧が担当し、記事執筆については小島啓明が担当しています。

Discussion