Kafkaのオートスケールをk8s上で目指す - 後編 k8s側の話 -
遅れてしまいましたが、この記事は Kubernetes Advent Calendar 2022 の5日目の記事です。
AWS上でのKafkaのオートスケールを目指した話の後編になります
前編は
スケール方式の根本的な方式などは前編に記載されているので、事前に目を通してもらえると幸いです
この記事では、前編で紹介した手順をk8sの機能を利用して、自動で行うためにした方法についてまとめていきます。
Kafkaのオートスケールで解決したい課題(この記事のゴール)
(前編で記載と同じ内容です)
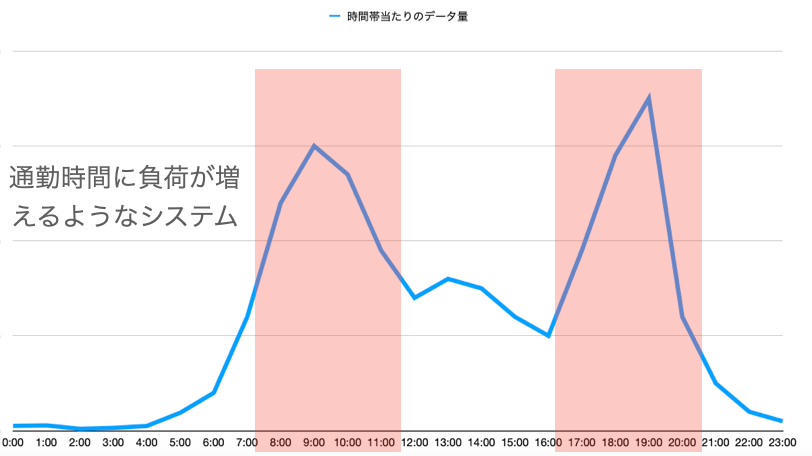
コスト削減を目的とした数分単位でのKafkaのスケールを実現したかったです。
1日の中である程度負荷の傾向が予測できるようなストリーミングシステムをAWS上で運用していました。処理部分はオートスケールを実現できていたのですが、Kafkaは常に一定のサイズで立ち上げていたため、何かコスト削減はできないかと調査を実施してみました。
前編のおさらい
前編ではkafkaの一般的なスケール方式(Partition/Brokerを増やす)では、拡張はできても縮小ができないので、垂直スケール的にBrokerに割り当てるCPU/Memory/ネットワーク・ディスク帯域を増減することでスケールをしようという話と、その際にクラスタを止めずに行う方法についてを書きました。一方でこれらの自動化については触れれませんでした。
手動では数分単位のスケール厳しい、ミスも入りやすい
章題通りで、前編で紹介した手動の手順では数分単位でスケールを行うのは厳しいし、またヒューマンミスも発生しやすくなるため、自動化を行いたいです。
今回はk8s上でKafka運用し、Pod(コンテナ)でBrokerを動かすことで、オートスケールを目指してます
k8sでのスケール方針検討
k8sでのスケールといってもスケール対象(Node/Pod), 技術は色々あるので
どのように実現するかを考えていきます
✖️ Podに割り当てるリソースをVPAで変更する?

前編の方式をそのまま考えるなら、Vertical Pod Autoscaler(VPA)でPodに割り当てるcpu/memoryを変動させる方法が考えれますが、
これは以下2つの理由で難しいです。
1. VPAだと結局コスト削減に繋がらない。
AWSなどのクラウドにおいてはPodに割り当てるリソースが変動したところで利用料金は変わりません。結局のところPodを載せるNodeのリソースを変動させないとコスト削減には繋がらないため、VPAはあまり効果的ではありません
Fargateだとコスト削減できる?
AWS EKSの場合Fargateが利用でき、FargateであればPodに割り当てたリソース = 課金額になるためコスト削減につながりそうに思えます。
ただ、FargateはEBSでのPersistent Volumeを現状サポートしていないため今回は候補から外しました。(EFS PVCはサポートしている、EFSを利用してのkafka動作は検証したが性能やコスト的に見送った)
EBS PVCを使う詳細は後述しています(スケール時にデータが吹っ飛ぶので使えないということです)
これを検討していた当時はまだサポートされていませんでしたが、最近無停止でVPAを行える仕組み(In-place Pod Vertical Scaling)がk8sに導入されたので、これがFargateでも利用可能になると少し夢は広がるかもしれません
2. CPU/Memory以外のDisk/Network帯域は変動させれない
KafkaではCPU/Memoryよりネットワーク帯域がボトルネックになりやすく、こちらがスケール基準になりやすいです。(実際今回もネットワークを基準としています)VPAのスケール対象はcpu/memoryのみのため、これはあまり効果的ではありません。
✖️ Kafka Pod専用のNodeを用意して, インスタンスタイプを変更する?
Kafka Podが占有するNodeを用意して、そのインスタンスタイプを変えてみようって話
これもないかと、k8s使う理由がなくなるし
最近のAWS向けだとKarpenterとかもあるけど、トリガがPendingのpodの要求キャパシティからやるという仕組みなので、ちょっと使い勝手が悪い

◯ 1NodeあたりにのるPod数を変動させることでKafka垂直スケールを実現する
結局一般的な方式が一番やりやすい
1NodeあたりにのるBroker Pod数を変動させることでスケールを行う。
Nodeは一般的な水平スケールを行うことで、負荷に合わせたコスト最適化が行える
Podは明示的なスケールを行わずに、1Nodeあたりに乗るPod数で利用できるリソースが変動される(Brokerから見たときは垂直スケール)が達成される

Podに対してlimitを指定せず、かつnamespaceでもデフォのquotaを設定してない場合、node上のキャパシティを全て利用しようとするので

1Nodeに1Broker Podしかいない場合は、そのノードの全てのリソースが
1Nodeに3Broker Podいる場合は、1Broker Podは他のBroker Podとリソース奪い合って、大体1/3リソースが利用できるという考え
具体的なスケール方法
Nodeのスケール方法(一般的なEC2 autoscaling groupの方式利用)
AWSのk8sのNodeスケールではClusterAutoscalerやKarpenterというのがありますが、これらはどちらもpod数の変動を(PendingのPodや、余剰リソースNode)を基本的なトリガにするため、前述のPod自体へ明示的にスケールさせない今回の方式だと利用できません。
ここではNodeのEC2 autoscalingのスケーリングポリシーを利用してスケールを行います。

具体的にどのスケールポリシーを利用するか、設定値などは今回そこまで観点じゃないので詳細は割愛します
(CPU利用率とネットワークスループットでターゲット追跡スケーリングしてました)
Podのスケール方式
Podは前述の通りで、limitを指定せずにNodeの増減に合わせて均等に配置されるように移動させることでPodから見た時の垂直スケールを実現させる。この移動方式は後述する
ここでは、Podが移動(停止/別Nodeへ移動して再起動)する際にBrokerがproduceで受け付けたメッセージデータが消えないかを考える必要がある。
これはk8s上でのKafkaの運用方法によるけど、今回はStrimziというKafka OperatorでKafkaを構築しており、ここではKafkaをStatefulsetで提供している

Statefulsetで提供することにより、処理部とストレージがPodとPVCで分かれて管理されます
これにより、Podを停止させてもデータが消えることはありません。またPVCはAWSの場合デフォでEBSボリュームになるので、インスタンス間での移動が可能(アタッチ・ディタッチ)となります
(またstatefulsetなのでbroker-idなども正しく割り当てられることも保証できます)

補足: Strimziについて
k8s上でKafkaを運用するためのKafka Operatorになります。
KafkaクラスターやTopicなどをk8sのCRDとして定義しているため、ほぼ全てをk8sマニフェストで完結できるようになるような点や、後述しますがdrain-cleanerなどk8s+cloudでkafkaを運用する際のサポートなどがある点で、k8sでkafkaを運用するためのOSSとしては最近人気なものだと思っています。
Topicの例
スケール時の挙動整理
NodeとPodのスケール方針を整理したところで、実際に負荷が増減して拡張・縮小を行いたい時どのように連携して動くかを考えます。
拡張時
- スケーリングポリシーによりNodeが増加する
- Nodeが増加したことに伴い、新しいNodeへBroker Podを移動させる
縮小時
- スケーリングポリシーによりNodeが減少しようとする
- 停止対象のNodeを止める前に、その中で動いてるBroker Podを別のNodeへ退避させる
- 別Nodeへ全てのBroker Podが移動後に停止対象のNodeを停止させる
対応しないといけない課題
実際のスケール挙動から、下記の課題を解決する必要が出てきます
- Node増加時はデフォルトでは別のNodeへPodは移動しない
- Node縮小時に安全にpodを移動させないと、長い時間kafkaクラスタが止まる恐れがある
- 複数のBroker Podが同時に移動するとクラスタが壊れる可能性がある
1つずつ詳細と解決方法を見ていきます
1. Node増加時はデフォルトでは別のNodeへPodは移動しない
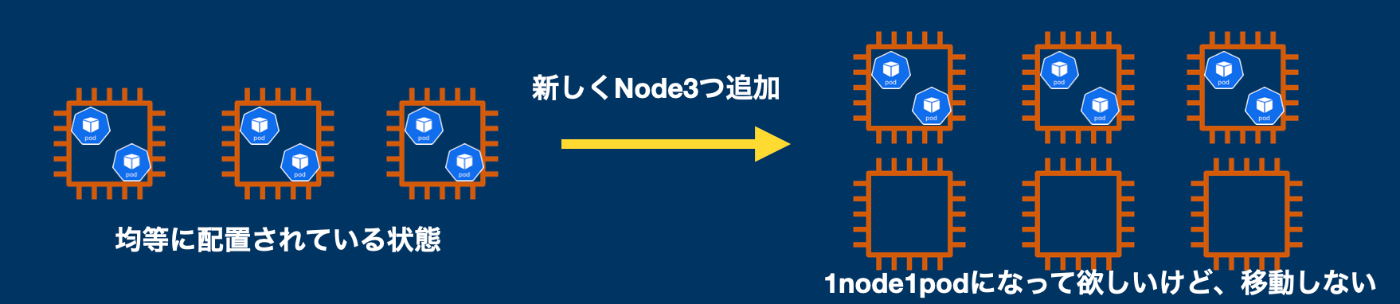
k8sはデフォではなるべくNode間に均等にPodを配置しようとしますが(Scheduler)これはあくまで、Pod起動時のみで、すでに立ち上がってるPodを均等配置しようとする機能はありません
これの解決としては、現在動作しているPodをいくつかの停止してSchedulerの対象にさせてあげる必要があります
K8s周辺ツールでこれサポートするのがdeschdedulerとなります
deschedulerは設定で渡したルールをクラスター内のpodが守っているかを定期チェックして、違反していた場合は削除してくれます(Deployment/statefulsetsなどの場合はpod再作成が行われて、その時にschedulerが均等に配置してくれるという考え方)
今回はルールにtopology spread constrainsの違反チェックを指定しています
Kafka用のNodeに乗ってるBroker Pod数が、他のどのKafka用NodeGroupのNodeとの差も1以下になるようにしました。(確実に均等配置)

これによりNodeが増加時に追従して、Podの移動も可能となりました
補足: topology spread constrainsとcordonの組み合わせ
k8s v1.23以前ではtopology spread constrainsはNodeのLabelでしか判定してくれませんでした。これの何が問題かというと、この後出てくるcordonでNodeにnode.kubernetes.io/unschedulable:NoScheduleのTaintsをつけても考慮されないということです。
たとえば、3nodeあって、各nodeに1podづつ乗っている状態かつtopolgy sread constraintsでmax skew=1を設定している場合に、1つのnodeにcordon&drainを実行すると、そのNodeに載っているPodが削除されて、他2つの Nodeのどちらかにスケジュールされようとしますが、その時にtopolgy sread constraintsはcordonされたNodeもReadyだという判定をしてしまうので、別のNodeに起動させると、そのNodeとcordonされたNodeでskew=2になる規約違反ということで配置できず無限に止まるという状況になります。
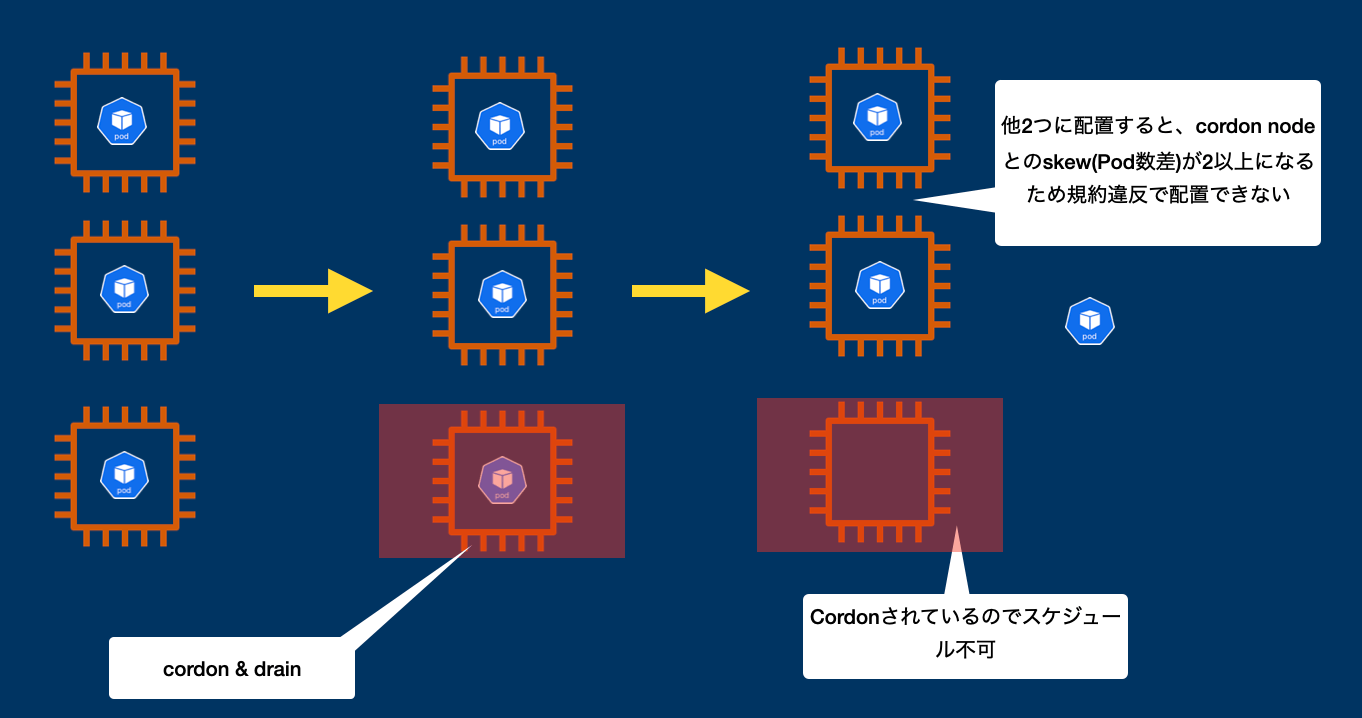
回避策として、k8sのイベントをウォッチして、cordonされたNodeにはtaintsだけじゃなくてlabelを付与(topolgy sread constraintsが解釈できる形)にする対応なんかをしました
がv1.24でこちらのバグは修正されて、taintsなども考慮されるようになったようです。
現在EKSも1.24まで出てるので、現在の最新のバージョンを利用する場合はこれはあまり考える必要ないです
2. Node縮小時に安全にpodを移動させないと、長い時間kafkaクラスタが止まる恐れがある
デフォだとkubeletが先に落ちてしまう
何も対策せずにNodeを削除(希望台数を減らす)すると、問題が発生します
削除対象となったインスタンス(Node)、その上に乗るPodはネットワーク的に不通になってしまいます。そして、Pod, Nodeのステータスは不通になってから1分後くらいにやっとNotReadyになってPod再作成が行われます。

Node上でPodの管理してくれたりネットワーク周りやってくれるkubelet, kube-proxyが落ちちゃうのが原因で、 kubelet落ちて一分後くらいにやっとControl Planeが疎通できないから落ちた判定して、そのNode落としてくれる(EKSだとここの設定値はマネージド部分なので変更不可です)
-> Podの状態を通知してくれる役割のやつ自体が落ちるので、状態が不明になる
こちらの記事がこの辺の仕様詳しく書かれており参考になりました。
安全に停止するためのcordon/drain
そのため, kubeletなどを落とす前に安全にpodを移動させて、最後にkubeletを停止 -> Node停止という流れを踏む必要があります。
これは手動メンテの場合、kubectl drain, kubectl cordonで行われます
- Drainは対象のNode上のPodを全て削除する -> 再スケジュール対象にさせる
- Cordonは対象のNodeをスケジュール対象外にする -> 別ノードにスケジュールを強制させる
というものになります。
EKSだとマネージドにcordon/drainされるよ
これをオートスケールのたびに毎回手動でやるのは流石に面倒です。。。
AWS EKSの場合は node-termination-handlerというのが使えます(EKS Managed-Nodegroup使うと自動で設定されてます!, 通常のNodegroupだと設定されていないので注意)
Amazon EKS マネージド型ノードグループでは、Kubernetes アプリケーションを実行するためのコンピューティング性能を提供する Amazon EC2 インスタンスを個別にプロビジョニングしたり登録する必要はありません。1 回の操作で、クラスターのノードを作成、自動的に更新、または終了できます。ノードを更新し、終了させることで、ノードを自動的にドレーンし、アプリケーションを利用できる状態にしておきます。
EC2 Autoscaling機能のライフサイクルフック機能が使われており、インスタンスが削除されるときに、インスタンスの停止を一度止める(待って)そのNodeにcordon/drainを実行してくれます
そしてそのNode上のpodが全て移動するまで削除を待ってくれ、移動が完全に完了したら止めておいたインスタンス停止を再開->完全に停止となります。
また前編でも触れたようにKafkaにはgraceful shutdown機能があり、今回利用したstrimziではpod停止時にこれが実行されているようになるので、これにより安全な移動が実現されています。
3. 複数のBroker Podが同時に移動するとクラスタが壊れる可能性がある
前編で触れた内容ですが、KafkaのBroker(厳密にはreplica)は同時に停止可能な台数が決まっています
例えばTopicの設定で3replica, 2min isrの場合は同時に1台のBrokerの停止を許容できます

しかしk8sで運用している場合でたとえば同時に2podが削除対象になってしまうと、同時に2podが停止してしまい、replicaのデータが消えてしまう恐れがあります

これを回避するために、複数のBroker Podが削除対象になっても1台づつ停止というややこしい指示を自動化に組み込む必要があります

Strimzi Drain Cleanerで1台づつの移動を実現
これを解決するのが今回利用したstrimziのdrain-cleanerという機能になります
(これがあるから採用したと言ってもいいかもです)
まず、前提としてPodDisruptionBudgetsのmaxUnavailableを0に設定します。
Deploy Kafka using Strimzi and configure the PodDisruptionBudgets for Kafka and ZooKeeper to have maxUnavailable set to 0. This will block Kubernetes from moving the pods on their own.
こうすることで、前述のdeschedulerやdrainでpodが削除対象になってもk8sの機能としては削除されず、削除対象という情報だけがイベントとして残ります。
そしてdrain-cleanerはk8sのPod削除イベントをwebhookで取得して, k8sに変わって削除を担当するようになります。これにより1台づつ、Broker停止->別nodeで起動isr全部追いついたら次のbroker削除という複雑な移動手順を実現できます。
まとめのスケールイン/アウト時の図
最後に3つの機能をまとめつつ、スケール時の挙動の図を整理して終わりとします。
スケールイン時
スケールイン時は、EKSのnode-termination-handlerにより、移動対象のpodが全て移動するまで、Nodeの停止を待ってくれます。移動対象のPodは削除されようとします、しかしPodDisruptionBudgetsのmaxUnavailableを0に設定しているため、実際の削除は行われません。
そして削除処理担当を受け継いだstrimzi drain-cleanerにより、1podづつ安全に移動が行われれます

スケールアウト時
スケールアウト時は、Nodeが増えた後に定期実行されるdeschedulerにより、幾つのPodが移動対象として削除されようとします。しかしPodDisruptionBudgetsのmaxUnavailableを0に設定しているため、実際の削除は行われません。
代わりにスケールイン時と同様にstrimzi drain-cleanerにより、1podづつ安全に削除->移動が行われれます

最後に
前編・後編合わせてKafkaでオートスケールする方式を検討してきました。
KafkaはやはりCloudがまだ商用当たり前という時代前のプロダクトということもありかオートスケールがコア機能に入っていないのかなという所感のため、かなり無理矢理な方法になってしまったと思います。(最初のQ&Aでも書いたように可能なら、Pravegaなどcloud nativeでオートスケールをコア機能としてプロダクトを採用した方がいいんじゃないかと思います)
今回のアイデア程度に受け取ってもらえると幸いです。
実際に負荷をかけると動作不安定ですし、NodeのPod抱え込み数に合わせてBroker間の負荷を変動できるわけではないので、実際にスケール可能な台数は(Broker6台の場合)インスタンス1,2,3,6台になります(Broker台数を綺麗に割れる数だけ)
-> Broker6に対して、インスタンス4とかにすると2インスタンスだけ2broker乗るかつ、全ブローカーに均等に負荷が流れれば、その2台だけ負荷が偏る
などなど色々あるため。
Discussion