Kafkaのオートスケールをk8s上で目指す - 前編 Kafka側の話 -
この記事は メッセージキュー Advent Calendar 2022 の4日目の記事です。
AWS上でのKafkaのオートスケールを目指した話を2回に分けて書いていこうと思います
この記事ではKafkaの仕組みの説明と手動で縮小/拡張を行う方法までをまとめています
次の記事では、この方式をk8sの機能と組み合わせることで自動化した話を書いています
次の記事は👇
Kafkaのオートスケールで解決したい課題(この記事のゴール)
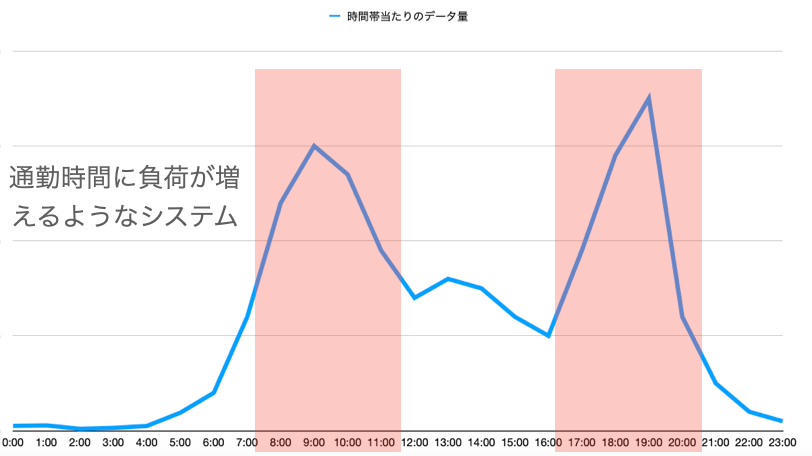
コスト削減を目的とした数分単位でのKafkaのスケールを実現したかったです。
1日の中である程度負荷の傾向が予測できるようなストリーミングシステムをAWS上で運用していました。処理部分はオートスケールを実現できていたのですが、Kafkaは常に一定のサイズで立ち上げていたため、何かコスト削減はできないかと調査を実施してみました。
課題解決のために満たすべき項目4点
課題の解決のために下記4点を達成する必要があります
(最後の1つは次記事で触れるため、あまり詳細には書いていません)
1. 無停止でスケールできること
長期的な運用で、数ヶ月に一度のタイミングで拡張のために一時クラスタを止めて、拡張するのは一般的だと思います。今回の要件である 数分単位 でのスケールで毎回クラスターが止まると問題なので、スケール時にクラスタとしては止まらず継続してproduce/consumeを受け付けれる必要があります。
2. 拡張・縮小どちらもできること
現在のキャパシティに対して負荷が増えてくると拡張が必要になりますし、余剰キャパシティになれば縮小してコスト削減を行うため、どちらも必要になります。
この後触れますが、Kafkaは公式に縮小をサポートしていないので色々考える必要があります
3. クライアント(Consumer, Producer)側で独自設定を開発せずに対応できること
この後詳細を書いていきますが、複雑化していくとクライアント側にも手を入れてしまいたくなるのですが(例えばクラスタースケールが行われるタイミングでイベントをクライアントに通知して、それによってよしなに動くような仕組み開発など)、それをするとメンテナンス性が落ちるので極力クライアントライブラリで解決できる範囲での対応を目指します。
4. システムメトリクスなどから自動でスケールされること(別記事で解説)
数分単位でスケールをしようとすると、毎回手動でやるのはあり得ないので自動化を目指します。
元々システムを全体的にk8sで運用していたのもあり、k8s上でkafkaを動作させ自動化を目指しました。
今回の記事ではここは触れておりません。
次の記事でここの詳細に触れていきます。
Kafkaでクラスターの縮小拡大を行う方法
達成したい課題を確認したところで、実際にKafkaで縮小・拡大を行う方法を考えていきます。
まず, Kafka初心者向けにもKafkaの基本概念から説明していきます
Kafkaの基本概念1(topic, partition, brokerとは?)
KafkaとはメッセージキューのOSSとなりますが、実際どのように動作されるかみていきます

初心者向けになんとなく理解してもらう向けの図なので、厳密には違うところはあります。
Brokerはサーバ上のプロセスとして動作します。実質的なKafkaのプロセスと言えます。
Brokerの集合で構成されるKafkaクラスターに対して、論理的なリソースであるTopicを作成すると、Topicの設定値で指定したPartition数分のログファイルのようなものが作成され、Brokerが起動しているサーバへ均等に分散されます。Topicへのデータ書き込み/読み込みを実際に行われるのはこのPartitionのファイルに対してとなります。
Kafkaの基本概念2(Producer, Consumer処理)

1つ前で出たTopic, Broker, Partitionsに対して、どのようにメッセージを送ったり、受け取ったりできるかをみていきます。
メッセージを送るクライアントのことをKafkaではProducerと呼びます。ProducerはTopic名を指定してメッセージを送ります。この際にクライアントライブラリが適当なパーティションを選択してメッセージを送ります(開発者は基本意識しなくていい)(厳密にはmsgのkeyをnull指定時)
Topicに保存されたデータを取得するクライアントのことはConsumerと呼びます
複数のconsumerでデータを読み取って何か処理したい場合に、重複で処理することは避けたくなります。その時はConsumer Groupというのでconsumerをまとめることで、同じconsumer group内であるパーティションの担当は1Consumerだけとなり、重複読み込みがなくなります(ちなみに、Partition数 < Consumer数の時は遊ぶcosnumerが出てきます)
また先ほど出たBrokerが実際にProducer/Consumerからのリクエストを受け取り処理を行います。
ちなみにここでみた仕様のように、Topicとしての順序保証はPartition単位であり、Topic全体としての順序保証はされていません
Kafkaの基本概念3(PartitionとBrokerを増やすことで、スケールできる)
ここまで説明したように、Brokerの性能がそのままKafkaクラスターの性能になることがわかると思います。
もちろんBrokerを増やしても処理対象のデータがなければ意味がないので、Partitionも新しいBrokerに配置する必要があります。
ので、1Broker上の1Partitionが処理できる量をN msg/sとすると3Broker, 3partitionは3N msg/s
6Broker, 6partitionは6N msg/sとなると言えます。

拡張はできても縮小はできない
拡張はできることは確認できたのですが、縮小はどうでしょうか?
単純に今のBrokerとPartitionを半減させれば良いでしょうか?
ステートレスなシステムだったらそれでいいのですが、これはデータを保持しているMQです。
縮小で削除対象となったBrokerが保持してたいPartitionのデータは何もしなければ削除されてしまいます。consumerがいる以上、このデータ消失も許容できません。
ので、データを消去せずにBrokerとPartitionを縮小する方法を考えたいです
Partitionを減らす方法
まずpartitionを縮小する方法を考えたいのですが、Kafkaはpartitionを減らす方法を提供していません
ワークアラウンドとして、partition数減らした別トピック用意して、そこにデータを移し替えるという方法があるのですが、ネットワーク経由での移動になるため、クラスター全体の帯域圧迫+クライアント側で接続先トピックの変更手続き必要などになります。メンテナンスとしてたまにやるとかなら許容できるかもしれませんが数分単位でのスケールでは許容できないです。
参考 -> https://stackoverflow.com/questions/45497878/how-to-decrease-number-partitions-kafka-topic
Brokerを減らす方法
Brokerを減らすことは一応可能ではあるのですが、
例えば6broker, 6partition -> 3broker, 6partitionにする場合3パーティションをネットワーク経由で別brokerに転送する必要があり。メッセージ数が多く溜まっている場合、ネットワーク帯域を圧迫してしまうことになります。

要件を満たしながらの縮小はできない
Paritionを減らすために、記載のように一度Produce/Consume処理などを止めて、別Topic移し替えなどが必要になるため、1. 無停止でスケールできること という要件が満たせません。
またBrokerを減らすとしても、その間データ転送処理にBrokerのCPUやネットワーク帯域といったリソースが消費され、本来のワークロードの負荷を捌けなくなる恐れがあります。
垂直スケールで拡張・縮小を目指す
ここで視点を変えてKafkaの元々の拡張方式とは別の方法を考えてみます。
元々の方式はBroker/Partitionを増やすという水平スケール的なアプローチです。
これの逆ということは垂直スケール方式ですね
Kafkaも結局ソフトウェアなので、割り当てられるCPU/Memory/ネットワーク・ディスク帯域といったシステムリソースによって性能が決まってきます。これを増減することで性能と費用を増減させようという寸法です(クラウドなのでインスタンスタイプで費用変わるので)
垂直スケール方式には限界あるのでできれば避けたい方式ですが(割り当てれるリソース/ソフトウェア的制約)、1日の中である程度最大/最低負荷が予測できる、今回のようなオートスケールでは有効的と考え挑戦してみました。

垂直スケールの具体的な方法 in AWS
Brokerを配置しているインスタンスのインスタンスタイプを順次変更していけばいいでしょう

単純にBrokerを止めるとクラスターも止まる
何も考えずに上記を手動でやっていくと、クラスター自体が壊れてしまいます
インスタンスタイプを上げるために一時停止する間、そのBrokerが持つパーティションが利用不可になります、特にConsumerが古いデータを読み取れなくなるのが問題です(Producerは正直生きてるパーティションにだけ送るとかできる)
そのため、Brokerが停止している間も、元々そのBrokerで管理していたパーティションが利用できることが必要になります
そのためにはReplica, Min in-sync replicaという設定が必要になってきます
Replica, Min in-sync replicaの説明
replicaはTopic内の設定値(Replication Factor)によって作成されるものになります。
1つのパーティションがこの値で設定された数分、作成されます
これ自体が前段で説明したPartitionの実態になっています。(Partitionもある意味論理リソース)
例えば3replica, 3partitionで作成したTopicは合計9つのreplicaが作成されることになります
この時9つのreplicaはBrokerへ均等に配置されます。

このとき1partitionは3つのreplicaを持つということになるのですが
(上記の図では同じ色のreplicaが同じpartitionに属するという整理をしています)
同じpartitionに属するreplicaは異なるBrokerへ配置されます
さらに3replicaのうち1つのreplicaだけがLeader Replica, 残りがFollower Replicaとクラスターによって選出されます。(Broker間でLeader Replicaの数がなるべく均等になるように選ばれます)

このLeader ReplicaだけがProducer/Consumerから処理を受け付けれるReplicaとなります

Follower ReplicaはLeaderに対してfetchリクエストを送り、常にLeaderが保持しているデータと同じデータを持てるようにします
(Follower ReplicaはRDSでのリードレプリカ的な役割もできません。ただコピーを保持するだけとなります)
また、そのパーティションの最新のメッセージまで保持しているレプリカのことを
In-sync replica(ISR) と言います(リーダーと同じデータを保持しているレプリカ数(リーダー含む)と思えばいい)

Topicにはさらにmin in-sync replica(min isr)という設定も可能です
これはTopicが期待する常に維持されるISR数を指定します
この設定がされたTopicへProducer側でacks: all(-1)の設定でメッセージを書き込むと、
リーダーがメッセージ書き込み完了後+もう一つのfollower replicaが書き込みに成功すると、Producerへ書き込み成功レスポンスが返ります。
これによりProducer成功した時点でそれが2つ以上のreplicaを持っていることを保証できます

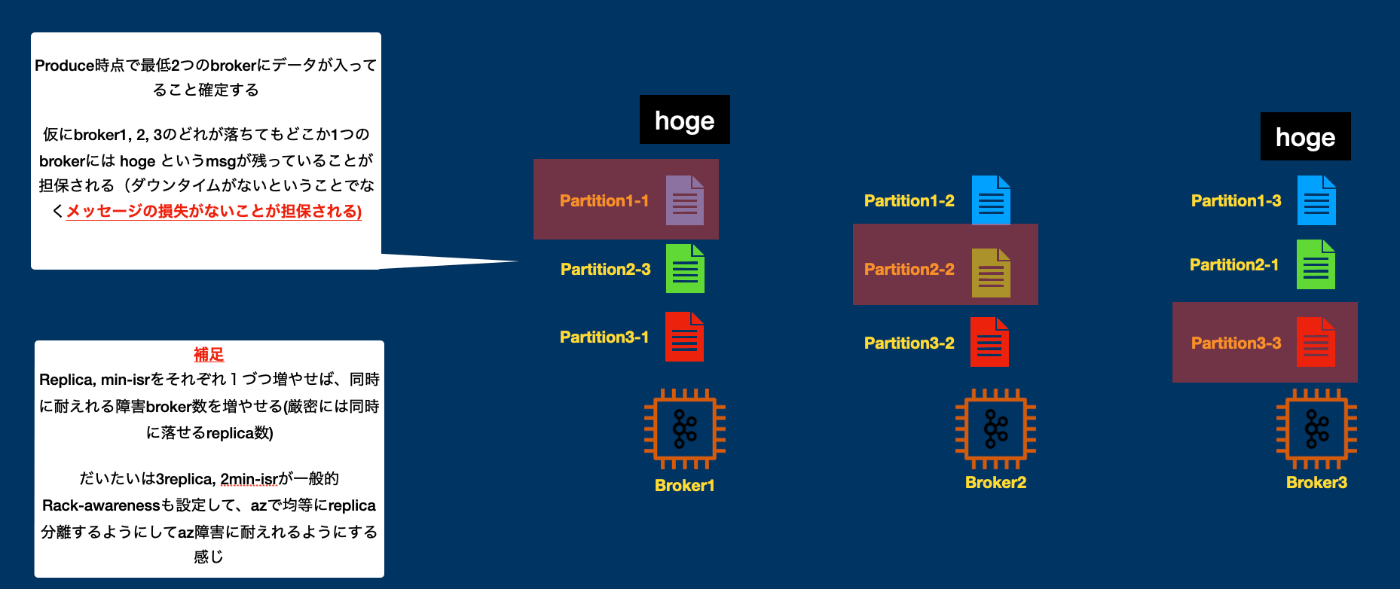
ここで紹介したreplica, min isrの設定が行われている場合、いくつかのBrokerの停止を許容できます。
例えば3repkica, 2min isrの場合は同時に1台のBrokerの停止を許容できます(厳密には1replicaの停止(同一パーティションのrelicaが異なるブローカーへ配置されることは保証されるので、Broker単位での停止許容)
なぜならメッセージ書き込まれた時点で確実に2replicaがあるので、仮にその状態でLeaderが停止しても、ISRの別replicaにLeaderを切り替えることで処理を継続できるからです
実際のスケールの流れ
replica, min isrを設定することで、インスタンスタイプを変更するために一時的にサーバを停止してもクラスタとして処理を継続できることを確認しました。
最後にこれらを組み合わせて実際にどのように垂直スケールするかをみて終わりとします。

まず3replica, 3partition, 2min isr設定でのTopicに対して処理をしているとします。
ここではわかりやすくするためにpartition1へのproduceだけをみていきます。
1. インスタンスタイプ変更のため、Broker1のサーバを停止する

インスタンスタイプ変更のためにサーバを停止します。停止前にブローカープロセスを停止するとgraceful shutdownが実行され、Partition1のリーダーが異なる別のreplicaへ変更されます
Producerは停止直後のProduce処理は失敗しますが、メタデータを取得し新しいリーダーを確認して新しいリーダーに対してretryで書き込みを行い処理を継続できます
2. インスタンスタイプを変更して再起動後、Brokerは停止時にProduceされた分を取得する
インスタンスタイプ変更して再起動後、Brokerが元々持っていたreplicaはそのまま残っています。
しかし全てisrではなくなっている可能性が高いでしょう(停止中もProduceが行われていたのであれば), 起動後リーダーへfetchリクエストを行い、遅れを取り戻す(isrになる)ことを目指します

3. 負荷均一化のためにLeader再選出
2で遅れていたreplicaがisrになってそれで終了ではないです。
各Brokerが持っているLeader Replica数が偏っています。
前述の通り、Leader Replicaが実際のProduce/Consume処理を受け付けるためFollower replicaと比べてリソース食うことになります。そのためなるべくBroker間でLeader replica数を揃える必要があります。
ISRに追いついた後に手動or定期実行でリーダーの再選出を行うことで、Broker間でLeader replica数を揃えてあげます
(このリーダーの選出は、リーダー担当を変更するだけでBroker間でデータの移動が走るわけではないので、性能劣化を起こさずに行えます)

まとめ
Kafkaのオートスケールを目指すために満たすべき項目を整理後にKafkaの基本的なスケール方式を確認しました
そこでKafkaの基本的なスケール方式(Broker/Partition増減)は要件2の拡張・縮小どちらもできること が満たせない = 縮小対応が難しいことを確認しました。
次に視点を変えて、垂直スケール的な割り当てリソースを変更することで要件2の拡張・縮小どちらもできることへ対応できることを確認しました。
またReplicaを適切に設定することで、リソース割り当て変更中も要件1の無停止でスケールできること、また性能劣化少なく対応できるを確認しました。
また、今回紹介した方式はKafkaの基本的な機能のみを利用しており、Kafkaクライアントライブラリが暗黙的にやってくれる処理のため、要件3のクライアント(Consumer, Producer)側で独自設定を開発せずに対応できることも満たせていると考えています。
この記事ではMQのアドベントカレンダーということもあり、Kafkaに特化した説明をしてきました
次の記事では、要件4の自動化について、k8sを利用して実現した話を書いているため、よかった読んでください
次の記事は👇
Discussion