こんにちは,株式会社エムニのエンジニア/PMの宮木です.
GPT-3.5が登場して以来、私は約3年間、B2B領域のLLMアプリケーション開発に没頭してきました。この数年、LLMの進化は凄まじく、「1ヶ月前の設計がもう古い」と感じるほどの速度で世界は変わっています。この変化の激しい時代において、一過性で終わらない、本当に価値のあるシステムとは何か。どうすれば、持続的に価値を生み出し続けるLLMアプリケーションを設計できるのか。その問いに対するヒントが、古くからある「ナレッジマネジメント(知識経営)」の考え方にありました。
本稿では、LLMアプリケーション、特に企業内システムにおける持続的な価値創出をテーマに、ナレッジマネジメントの古典理論「SECIモデル」を現代の技術でどう再解釈し、実装に落とし込むかを探求します。単なるプロンプトの工夫に留まらない、より本質的な「知識の流れ」の設計論です。
知識創造企業(新装版) - 野中郁次郎(著), 竹中弘高(著), 梅本勝博(翻訳)
DXの重心移動:プロンプトからコンテキストへ
LLMの登場は、デジタルトランスフォーメーション(DX)の重心を大きく動かしました。かつては「いかに多くの情報をデジタル化し、蓄積するか」が主眼でしたが、今は「蓄積したデータをいかに“意味のある知識”として組織で運用するか」が重要になっているような気がします。
また、ChatGPTの登場直後は、モデルへの“指示の書き方”を工夫するプロンプトエンジニアリングが注目されました。しかし、実際の業務アプリケーション、特に企業内の複雑な文脈では、一文のプロンプトを最適化するだけでは不十分です。
近年では、その最適化対象が「一文のプロンプト」から「情報の流れ全体」へと拡張し、コンテキストエンジニアリングという新しい概念が提唱されています。これは、どの情報を、どの順番で、どの形式でモデルに与えるかという文脈全体を設計するアプローチであり、ナレッジマネジメントの思想と深く結びつきます。
理論的基盤:SECIモデルで「知識の流れ」を設計する
ここで、本稿の基盤となるナレッジマネジメントの理論、SECIモデルを紹介します。これは、経営学者の野中郁次郎氏らが提唱した、組織的な知識創造のプロセスモデルです。個人の「暗黙知」と組織の「形式知」が相互に変換されながら、知識がスパイラル状に発展していく様子を描いています。
- 共同化(Socialization): OJTや雑談など、経験の共有を通じて個人の暗黙知を他者と共有するプロセス。
- 表出化(Externalization): 暗黙知を言語や図、モデルなどに変換し、形式知として表現するプロセス。
- 連結化(Combination): 既存の形式知を組み合わせ、新しい知識体系として統合・再構築するプロセス。
- 内面化(Internalization): 形式知を実践を通じて再び個人の暗黙知として吸収するプロセス。
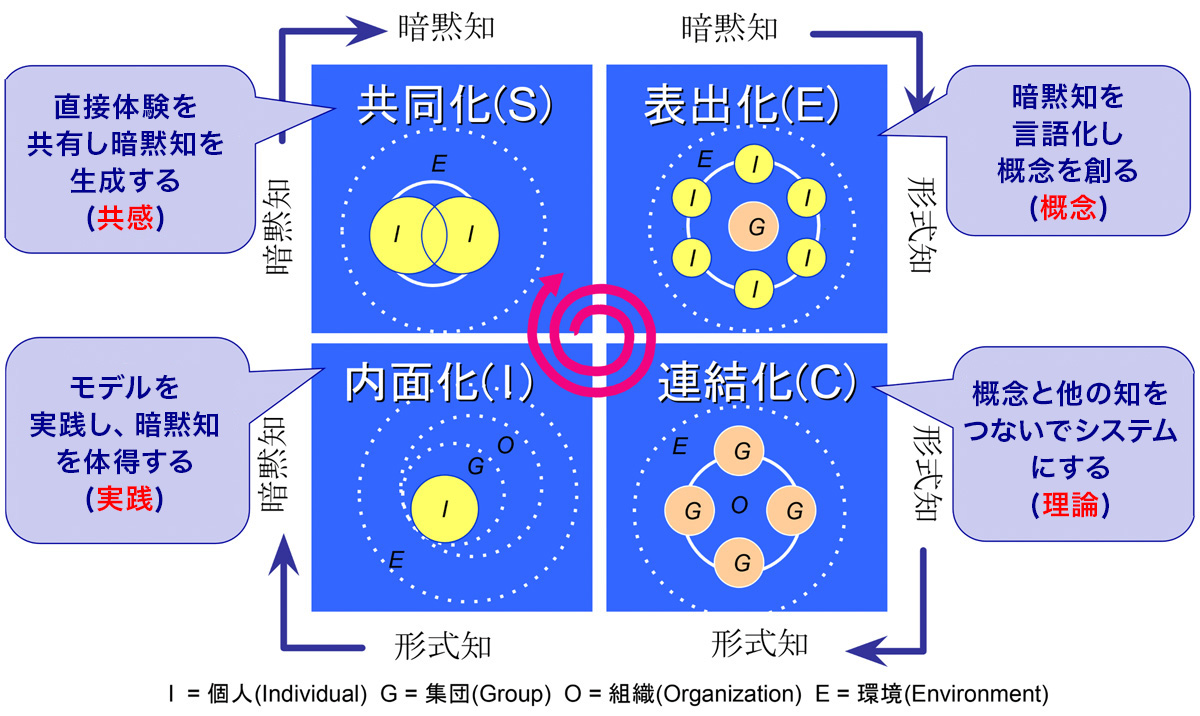
(図キャプション:SECIモデルによる知識創造のサイクル。引用元:https://coach.co.jp/interview/20200121.html)
SECIモデルとLLMアプリケーションの対応表
では、具体的にLLMはSECIモデルのどこに介入できるのでしょうか。各フェーズの典型的なタスク、LLMの介入方法、そしてその成功を測る指標(KPI)を以下の表に整理しました。これにより、自社のナレッジマネジメントにおける課題がどのフェーズにあり、どのような技術的アプローチが可能かを見極めることができます。
| フェーズ | 典型タスク | LLMによる介入例 | 成功指標 (KPI) の例 |
|---|---|---|---|
| 共同化 | OJT、現場でのペア作業、ブレインストーミング | (限定的) 議事録の自動要約、動画記録からの論点抽出 | 参加者の発話量、アイデアの発散度 |
| 表出化 | 熟練者へのインタビュー、日報・報告書の作成 | AIによるヒアリング、音声/動画の文字起こしと構造化 | 暗黙知→形式知の転写数、ナレッジ作成時間 |
| 連結化 | 社内文書の検索、マニュアル作成、技術レポート統合 | RAG/GraphRAGによる関連知識の提示、文書の自動分類・タグ付け | ナレッジ再利用率、一次回答での解決率、検索時間 |
| 内面化 | シミュレーション研修、Q&Aシステムでの学習 | 対話型トレーニングボット、パーソナライズされた学習コンテンツの生成 | 習熟度テストのスコア、Q&Aシステムの利用率 |
LLMが介入しづらい「共同化」の壁と、その乗り越え方
上の表が示す通り、SECIサイクルの中でも特に「共同化」のフェーズ、すなわち「個人の暗黙知を組織の暗黙知に変換する」プロセスは、LLMによる直接的な支援が最も難しい領域です。このフェーズは、人間同士の信頼関係や、その場の空気といった非言語的な文脈共有が不可欠だからです。
しかし、完全に諦める必要はありません。AIが直接介入するのではなく、人間による共同化を間接的に支援する設計は可能です。例えば、以下のようなアプローチが考えられます。
- 観察と記録に徹する: 熟練者と若手のペア作業をビデオで撮影し、その映像と音声をAIが解析。発話内容や作業手順をテキスト化・構造化し、後の「表出化」のインプットとする。
- 触媒としての役割: ブレインストーミングの場で、多様な視点を提供するための「壁打ち相手」としてLLMを活用する。人間だけでは思いつかないような突飛なアイデアを生成させ、議論を活性化させる。
重要なのは、どこまでを人間が担い、どこからをAIに委ねるかという設計思想です。AIはあくまで「記録と整形」に徹し、人間が「意味づけと関係構築」に集中する。この役割分担こそが、人間中心の知識創造を実現する鍵となります。
設計原則:知識創造を促す5つの条件をどう実装するか
『知識創造企業』では、組織の知識創造を促進するために、以下の5つの組織的条件が必要だと述べられています。これらの条件を理解することは、単なる情報管理ツールではない、真に創造的なLLMアプリケーションを設計する上で不可欠です。それぞれの条件の概要と、それをLLMアプリケーションの設計要件にどう落とし込むかを見ていきましょう。
-
意図(Intention / Purpose)
組織として「どのような知識を、なぜ創造したいのか」という明確な目的意識です。この意図が、知識創造活動の方向性を定め、個人のエネルギーを集中させる羅針盤となります。 -
自律性(Autonomy)
個々のメンバーが、自らの裁量で自律的に行動できる環境を指します。トップダウンの指示を待つのではなく、現場のメンバーが自ら課題を発見し、新しいアイデアを生み出す機会を増やすことが、知識創造の源泉となります。 -
揺らぎと創造的カオス(Fluctuation and Creative Chaos)
組織が外部環境と絶えず相互作用し、内部に意図的な「揺らぎ」や「カオス」を生み出すことです。既存のやり方や前提を問い直すような、適度なストレスや不確実性が、新たな洞察や創造的なブレークスルーを促します。 -
冗長性(Redundancy)
業務遂行に最低限必要な情報だけでなく、意図的に重複する情報を組織内で共有することです。同じ情報に異なる視点から触れることで、個人の暗黙知が刺激され、より多角的な解釈や新しい意味の発見につながります。 -
最小有効多様性(Requisite Variety)
組織が複雑な外部環境の変化に対応するためには、組織内部にもそれに匹敵する多様性が必要だという考え方です。多様な専門性や経験を持つ人材がフラットに情報をやり取りできる環境が、組織全体の情報処理能力を高め、環境変化へのしなやかな対応を可能にします。
これらの抽象的な概念を、具体的なLLMアプリケーションの設計要件に落とし込み、より実践的なシステムを構築することを考えてみましょう。
| 知識創造の条件 | LLMアプリケーションにおける設計要件 |
|---|---|
| 1. 意図(Purpose) | - 明確なユースケース定義: システムが解決するべきビジネス課題(OKR)を明確にする。 - 利用ガイドラインと禁止事項: モデルの目的外利用を防ぐためのガードレールを設ける。 |
| 2. 自律性(Autonomy) | - 柔軟な権限設定: ユーザーが自身の知識を自由に投稿・編集できる権限(ロールベースアクセス制御)を付与する。 - ボトムアップの改善提案: ユーザーがプロンプトや知識ベースの改善を提案できるフィードバックループを設ける。 |
| 3. 揺らぎと創造的カオス | - 実験的な利用枠(サンドボックス): 本番環境とは別に、新しいプロンプトや機能を試せる実験環境を提供する。 - 多様な情報ソースの接続: 意図的に多様な(時には矛盾する)情報ソースを入力させ、新たな発見を促す。 |
| 4. 冗長性(Redundancy) | - 多角的な視点の許容: 同じ事象に対して、複数の異なる説明や解釈が知識ベースに存在することを許容する設計。 - バージョン管理: 知識の変更履歴を保存し、過去の文脈を参照できるようにする。 |
| 5. 最小有効多様性(Variety) | - 部門横断的な知識アクセス: 組織内のサイロを越えて、必要な情報にアクセスできる検索・推薦機能。 - 多様なデータ形式への対応: テキストだけでなく、図表、音声、動画など、多様な形式の情報を扱えるようにする。 |
これらの要件をシステムに組み込むことで、単なる情報検索ツールではなく、組織全体の知識創造をドライブするプラットフォームへと進化させることができるのでないでしょうか。
実装パターンとアンチパターン:理論から実践へ
SECIモデルをさらに発展させると、知識創造のプロセスは以下の5つのステップに整理できます。この流れを設計の基盤として捉え、各ステップでLLMをどう活用できるかの実装パターンを見ていきましょう。また、陥りがちな失敗=アンチパターンも併せて紹介します。
知識創造の5ステップと実装パターン
-
暗黙知の共有(SECIにおける共同化)
- 実装パターン: 熟練者と若手の対話や現場作業を録画・録音し、LLMで文字起こしと論点整理を行う。誰が、いつ、どのような文脈で、何を発言したかを構造化データとして保存する。
-
コンセプトの創造(SECIにおける表出化)
- 実装パターン: 文字起こしされたテキストを元に、LLMがインタビュー形式で深掘りを行う(例:「なぜその手順が必要なのですか?」)。抽出されたコンセプトを、ナレッジグラフのノードやエッジとして自動生成する。
-
コンセプトの正当化
- 実装パターン: 生成されたコンセプト(ナレッジ)を専門家がレビューし、承認・修正するワークフローをシステムに組み込む。承認されたナレッジは「信頼済み」としてマークされ、検索時の優先度が高まる。
-
原型(アーキタイプ)の構築(SECIにおける連結化)
- 実装パターン: 承認された複数のナレッジを組み合わせ、特定のタスク(例:異常検知、見積もり作成)を解決するための手順書やチェックリストをLLMが自動生成する。これがアプリケーションのプロトタイプ(原型)となる。
-
知識の転移(SECIにおける内面化と新たな共同化)
- 実装パターン: 生成された手順書を若手が利用し、その結果をフィードバックする。利用頻度の高い知識や、評価の高い知識をランキング表示し、組織全体での利用を促進する。この利用データが、新たな暗黙知共有のきっかけとなる。
陥りがちなアンチパターン集
理論通りに進まないのがプロジェクトの常です。以下に、LLMナレッジマネジメントシステムでよく見られる失敗パターンを挙げます。
- プロンプトの過負荷: 一つのプロンプトにあまりに多くの指示や制約条件を詰め込みすぎて、モデルの性能が劣化する。役割ごとにプロンプトを分割し、段階的に処理する設計が必要です。
- RAGにおける情報品質の未管理: あらゆる文書をただベクトル化して投入するだけで、情報の鮮度、信頼性、関連性が考慮されず、検索精度が低下する。文書のメタデータ管理と定期的な棚卸しが不可欠です。
- アクセス制御の欠如: ユーザーの権限を考慮せずにRAGを構築し、本来アクセスできないはずの機密情報が検索・生成結果に含まれてしまう。RBAC/ABACの実装が必須です。
- 評価指標の不在: KPIを定めずに「なんとなく」でプロンプトやモデルを更新し続け、改善しているのか改悪しているのか判断できない。A/Bテストやゴールデンセットによる定量評価が重要です。
- 組織インセンティブとの不整合: 知識の共有や提供が個人の評価に結びついていないため、誰もナレッジを投稿・更新しなくなる。人事制度との連携が成功の鍵です。
評価と運用:知識の価値をどう測り、育てるか
システムは作って終わりではありません。その価値を継続的に評価し、改善していく運用プロセス(LLMOps)が不可欠です。特に、知識の「質」や「鮮度」といった、従来のシステム開発ではあまり問われなかった指標が重要になります。
KPI / 成功指標
何を以て「成功」とするかを定義しなければ、改善の方向性は定まりません。以下に、ナレッジマネジメントシステムにおけるKPIの例を挙げます。
- ナレッジ品質: 一次回答での解決率、ユーザーによる評価(Good/Bad)、専門家による承認率
- ナレッジカバレッジ: 検索クエリに対するヒット率、未解決質問の数
- 業務効率: タスク完了までの時間短縮率、問い合わせ件数の削減率
- 知識循環: ナレッジの再利用率、新規ナレッジの投稿数、更新頻度
評価方法
- オフライン評価: 新しいモデルやプロンプトを導入する前に、事前に用意した評価データセット(ゴールデンセット)で精度を検証します。実世界の多様な質問を模した合成データや、過去の問い合わせログが有効です。
- オンライン評価: 実際にユーザーが利用する環境で、A/Bテストなどを行い、複数のモデルやロジックの性能を比較します。ユーザーのフィードバック(採用率、再質問率など)を直接的な指標とします。
ドリフト検知とガードレール
- ドリフト検知: ビジネス環境の変化(新製品、組織変更など)により、知識ベースが古くなる「コンセプトドリフト」を監視します。文書の更新頻度や、使われ始めた新しい用語を検知する仕組みが必要です。
- ガードレール: 個人情報(PII)のマスキング、不適切な表現のフィルタリング、企業のポリシーに反する回答のブロックなど、安全な利用を保証するための仕組みを組み込みます。
コスト最適化
LLMの利用コストは無視できません。特に、大量の知識を扱うシステムでは、問い合わせの度に高価なモデルを呼び出すと、コストが膨大になります。以下の手法を組み合わせ、精度とコストのバランスを取ることが重要です。
- キャッシュ: 同じ質問に対しては、計算結果を再利用する。
- 段階的精度: まずは安価で高速なモデル(または単純なキーワード検索)で回答を試み、それで不十分な場合にのみ、より高価で高精度なモデルを呼び出す。
- コンテキスト圧縮: RAGで検索した文書をそのまま入力するのではなく、一度LLMで要約してから次のLLMに渡すことで、入力トークン数を削減する。
セキュリティとガバナンス:信頼の基盤を築く
特にB2B領域では、ナレッジマネジメントシステムが扱う情報の機密性は非常に高いです。したがって、設計の初期段階からセキュリティとガバナンスを組み込むことが極めて重要です。
-
アクセス制御(Authorization): 誰が、どの情報にアクセスできるかを厳密に管理します。ロールベースアクセス制御(RBAC)や、ユーザーの属性(所属部署、役職など)に基づいて動的にアクセスを制御する属性ベースアクセス制御(ABAC)の導入が不可欠です。これは特に、前述の「アクセス制御の欠如」アンチパターンを防ぐために重要です。
-
監査ログ(Audit Log): 「いつ、誰が、どの情報にアクセスし、何を生成したか」をすべて記録します。インシデント発生時の追跡調査や、システムの利用状況分析に不可欠です。
-
データガバナンス: 収集した情報の保有期間ポリシーを定め、不要になったデータは適切に削除する仕組みを構築します。
事例:エムニの「AIインタビュアー」に見る知識創造プロセス
理論や設計原則だけでは、具体的なイメージが湧きづらいかもしれません。ここで、私たちが開発している製造業向け技能伝承プロダクト「AIインタビュアー」を例に、これまでの議論がどのように実装されているかを紹介します。
このシステムは、熟練技術者が持つ暗黙知を、LLMがインタビュー形式で抽出し、GraphRAGで利用可能なナレッジグラフとして形式知化することを目的としています。これは、まさにSECIモデルにおける「表出化」と「連結化」を強力に支援するツールです。
具体的な対話例(表出化の瞬間)
以下の動画は、熟練技術者とAIインタビュアーとの対話の例です。AIが単純な文字起こしや情報の構造化に留まらず、なぜその作業が必要なのか、背景にある「暗黙知」を深掘りしようとしている様子がわかります。
この対話を通じて、単なる「コンデンサの動作不良による機器の停止」という不具合(形式知)だけでなく、「過電圧」や「回路短絡の発生」といった不具合の真因や背景(暗黙知)が引き出され、構造化されていきます。
まとめ:人間中心の知識循環を設計する
LLMを使って「知識の完全自動化」を目指すアプローチは、一見魅力的に見えます。しかし、本質的に重要なのは、組織のどこで知識の循環が止まっているのかを観測し、その流れを再び活性化させることです。
AIが人間を置き換えるのではありません。人間が創造性を発揮し、知識を生み出し続けるための“流れ”を設計すること。それこそが、ナレッジマネジメントの核心であり、これからのLLMアプリケーション開発者に求められる視点です。
あとがき
株式会社エムニでは、LLMの社会実装を共に進めていくメンバーを募集しています。最新技術に触れながら、自らのアイデアを形にできる、エンジニアにとって非常に刺激的な環境です。生成AIを活用したアプリケーション開発に興味をお持ちの方は、ぜひカジュアル面談からお気軽にお声がけください。

Discussion