Context Engineering について
1. はじめに
近年、LLM(大規模言語モデル)を活用したシステム開発において、プロンプトエンジニアリングに加えて新たな概念が注目を集めています。それが「Context Engineering(コンテキストエンジニアリング)」です。
Context Engineering とは何か
Context Engineering とは、LLM に与える情報全体を体系的に最適化するアプローチです。従来のプロンプトエンジニアリングが単一の指示文の改善に焦点を当てていたのに対し、Context Engineering はより広範囲な情報管理を対象とします。
具体的には、システムプロンプト、ユーザーからの指示、過去の対話履歴、外部から取得した知識、利用可能なツールの情報など、LLM が参照するすべての情報を適切なタイミングで最適な形式で提供するシステム設計の手法です。
Context Engineering がトレンドとなったきっかけは、AI 界の重鎮である Andrej Karpathy 氏、Shopify CEO の Tobias Lütke 氏のツイートのようです。
なぜ今注目されているのか
Context Engineering が重要視される背景には、AI エージェントの台頭があります。これまで LLM は基本的に人間が直接操作するツールでした。ユーザーが質問を入力し、LLM が回答を返すという単発的なやり取りが中心だったため、プロンプトの内容に集中すれば十分でした。
しかし、エージェントは人間の介入なしに自動的に LLM を動作させ続けるシステムです。長時間にわたって複数のタスクを実行し、外部ツールとの連携を行い、過去の結果を踏まえて次のアクションを決定します。このような継続的な処理では、単一のプロンプトだけでなく、情報そのものをどう管理するかが成功の鍵となります。
また、エージェントが扱う情報量は膨大になりがちです。ツール実行の結果、検索で取得したデータ、過去の対話履歴などが蓄積されると、コンテキストウィンドウの容量制限に達したり、重要な情報が埋もれてしまったりする問題が発生します。これらの課題を解決するために、情報の取捨選択、圧縮、分割といった高度な管理手法が求められるようになったのです。
実際、エージェントの失敗の多くはモデル自体の性能不足ではなく、適切な情報が提供されなかったことによるコンテキストの問題であることが明らかになっています。
本記事の内容
本記事では、Context Engineering の基本概念から実践的な手法まで、体系的に解説します。
まず、プロンプトエンジニアリングから Context Engineering への発展過程を理解し、エージェント時代における新たな課題を明確にします。次に、Context Engineering が解決すべき具体的な問題を詳しく見ていきます。コンテキストウィンドウの物理的制約、情報の認識限界、不正確な情報の混入など、実際のシステム開発で直面する課題を取り上げます。
続いて、LLM が参照するコンテキストの構成要素を分類し、それぞれの役割と最適化方法を説明します。システムプロンプト、短期・長期メモリ、外部知識、ツール情報など、各要素の特性を理解することで、効果的な情報設計の基盤を築きます。
記事の中核となるのは、Context Engineering の 4 つの主要手法です。書き出し、選択、圧縮、分割という手法を、具体例とともに詳しく解説し、それぞれの適用場面と注意点を明確にします。
最後に、実際のシステム開発における適用例を紹介し、理論と実践の橋渡しを行います。会議スケジュール調整エージェントやコードエージェントなど、身近な事例を通じて、Context Engineering の実装方法を具体的に示します。
Context Engineering の基本原理を理解することで、より効果的で信頼性の高い LLM システムを構築するための知識が身につきます。次章では、プロンプトエンジニアリングから Context Engineering への発展過程を詳しく見ていきます。
2. プロンプトエンジニアリングから Context Engineering への発展
LLM の活用手法は、技術の発展とともに大きく変化してきました。初期の段階では「プロンプトエンジニアリング」が中心的な手法でしたが、エージェント技術の台頭により、より包括的なアプローチである「Context Engineering」が求められるようになりました。
プロンプトエンジニアリングの限界
プロンプトエンジニアリングは、LLM に対する指示文(プロンプト)を最適化することで、より良い出力を得る手法です。適切なキーワードの選択、例示の提示、思考過程の明示など、単一の指示文の品質向上に焦点を当てています。
この手法は、ユーザーが質問を投げかけて LLM が回答を返すという単発的なやり取りにおいては非常に有効でした。特定のタスクに対して最適化されたプロンプトを作成することで、高品質な出力を安定して得ることができます。
しかし、プロンプトエンジニアリングには構造的な限界があります。この手法は基本的に人間が直接 LLM を操作することを前提としており、一回限りの指示と応答のサイクルに最適化されています。長期間にわたる連続的なタスク実行や、複数の情報源からのデータ統合、動的な状況変化への対応といった要求には適していません。
エージェント時代の新たな課題
エージェント技術の導入により、LLM の利用方法は根本的に変化しました。エージェントは人間の継続的な介入なしに、自動的に LLM を動作させ続けるシステムです。一つのタスクを完了するまでに数十回、場合によっては数百回の LLM 呼び出しを行い、外部ツールとの連携や過去の結果の参照を繰り返します。
この環境では、単一のプロンプトの最適化だけでは不十分です。エージェントが扱う情報は時間とともに蓄積され、多様化します。実行履歴、ツールからの出力結果、検索で取得した外部データ、エラー情報など、様々な種類の情報が混在する状況が生まれます。
さらに、エージェントは長時間の実行中に情報の優先度が変化することも考慮しなければなりません。タスクの初期段階で重要だった情報が後半では不要になったり、新たに取得した情報が既存の判断を覆したりする場合があります。このような動的な情報管理は、静的なプロンプト設計では対処できません。
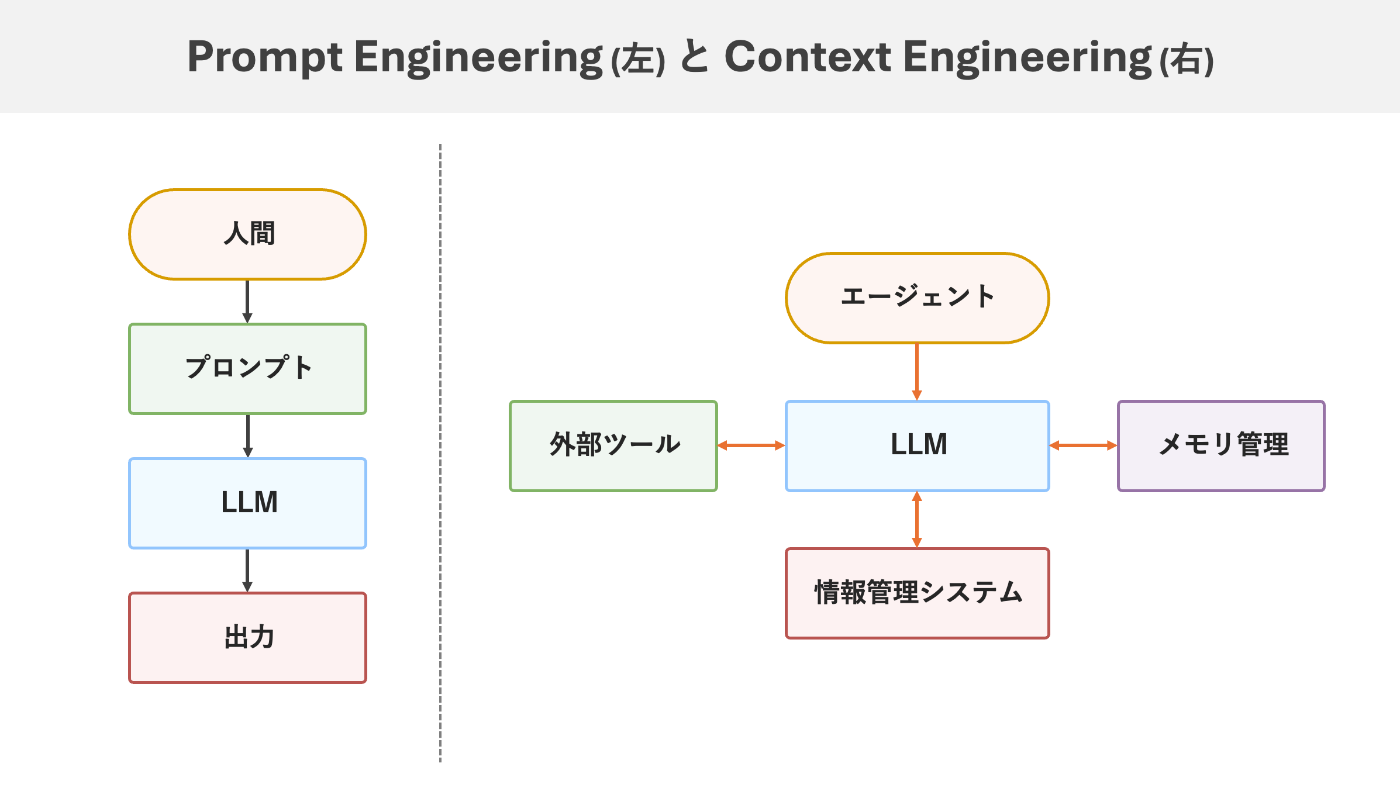
Context Engineering の定義
Context Engineering は、これらの課題に対応するために生まれた新しい設計思想です。単一のプロンプトの最適化から一歩進んで、LLM が参照するすべての情報とツールを動的に管理するシステム全体の設計を対象とします。
具体的には、「適切な情報とツールを適切なタイミングで提供するシステム設計」として定義できます。この定義には三つの重要な要素が含まれています。
第一に「適切な情報」とは、現在のタスクに関連性が高く、LLM の判断に必要十分な情報を指します。無関係な情報を排除し、重要な情報を強調する選択と編集のプロセスが含まれます。
第二に「適切なツール」とは、タスクの実行に必要な機能を過不足なく提供することです。ツールの数が多すぎると選択の混乱を招き、少なすぎると必要な機能が不足します。
第三に「適切なタイミング」とは、情報やツールの提供時期を最適化することです。全ての情報を常に提供するのではなく、タスクの進行状況に応じて段階的に情報を開示したり、不要になった情報を除去したりします。
Context Engineering は、これらの要素を統合的に管理することで、LLM が最高の性能を発揮できる環境を構築する手法です。プロンプトエンジニアリングが文章レベルの最適化だったのに対し、Context Engineering はシステムレベルの設計アプローチといえます。
このように、プロンプトエンジニアリングから Context Engineering への発展は、LLM の利用形態の変化に対応した必然的な流れです。次章では、Context Engineering が具体的にどのような課題を解決するのかを詳しく見ていきます。
3. Context Engineering が解決する課題
Context Engineering が注目される背景には、従来のアプローチでは対処できない具体的な技術的課題があります。これらの課題は、LLM の性能向上だけでは根本的に解決できない構造的な問題であり、情報管理の観点からの対策が必要です。
入力長の限界
最も基本的な制約は、コンテキストウィンドウの物理的な容量制限です。LLM には一度に処理できるトークン数に上限があり、この制限を超えた情報は処理できません。エージェントが長時間実行される場合、ツールの実行結果、検索で取得したデータ、過去の対話履歴などが蓄積され、容易にこの制限に達してしまいます。
例えば、文書検索エージェントが複数の PDF ファイルから情報を収集する場合を考えてみましょう。各ファイルの内容、検索クエリの履歴、中間結果などが累積すると、新しい情報を追加する余地がなくなります。この状況では、重要な情報が処理されずに除外されたり、古い情報が残り続けて判断を阻害したりする可能性があります。
コンテキストウィンドウの制限は、単純にモデルの性能向上では解決できません。より大きなコンテキストウィンドウを持つモデルが開発されても、エージェントが扱う情報量の増加に比例して問題は残り続けます。根本的な解決には、情報の優先度付けと動的な管理が必要です。
認識の限界
コンテキストウィンドウに情報が収まったとしても、LLM がすべての情報を均等に認識できるわけではありません。特に「Lost in the Middle」として知られる現象では、コンテキストの中央部分に配置された情報が適切に参照されにくくなります。
これは、LLM の注意機構がコンテキストの始端と終端により強く注意を向ける傾向があることに起因します。重要な指示や最新の情報は適切に処理されますが、中間に配置された情報は見落とされがちです。エージェントが複数のタスクを並行して実行する場合、この問題は特に深刻になります。
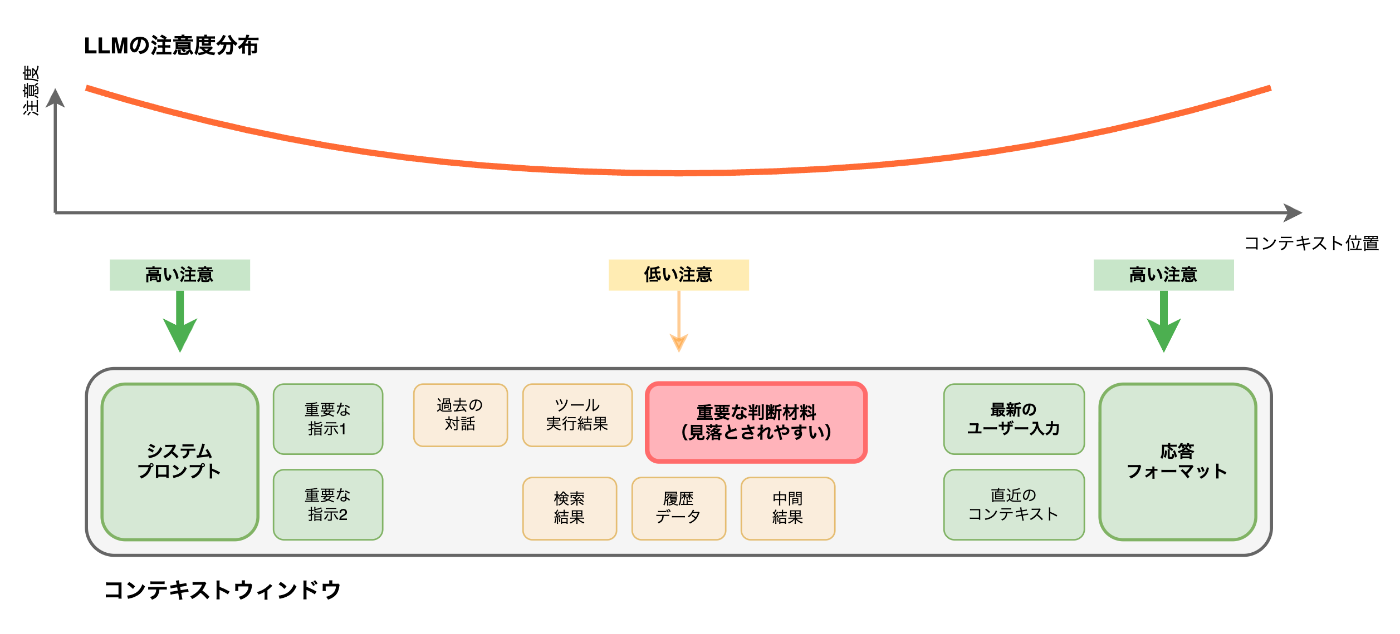
コンテキスト汚染
コンテキスト汚染とは、LLM が生成した不正確な情報(幻覚)がコンテキストに混入し、後続の判断に悪影響を与える問題です。エージェントは自身の出力を次の入力として使用するため、一度発生した幻覚が連鎖的に拡散する危険性があります。
具体的には、エージェントが検索結果を解釈する際に誤った結論を出力し、その結論が後の処理で事実として扱われる場合があります。この誤情報は訂正されることなく蓄積され、最終的な判断の品質を大きく低下させます。特に、複数の情報源から得られた正確な情報と混在すると、どの情報が信頼できるかの判別が困難になります。
コンテキスト汚染の対策には、出力情報の検証機構や、情報源の明確な区別、定期的な情報の整理といった手法が必要です。単純に高性能なモデルを使用するだけでは、幻覚の発生自体を完全に防ぐことはできません。
コンテキスト混乱
コンテキスト混乱は、タスクに無関係な情報や矛盾する情報が混在することで、LLM の推論が阻害される問題です。この問題は複数の形態で現れます。
第一に、余計な情報による注意の分散があります。現在のタスクに関係のない過去の対話履歴や、類似しているが異なる文脈の情報が含まれると、LLM は重要な情報への集中が困難になります。
第二に、情報間の矛盾による判断の混乱があります。異なる情報源から取得したデータが相互に矛盾する場合、LLM はどの情報を優先すべきか判断できません。例えば、古い企業情報と最新の企業情報が混在する場合、時系列の考慮なしに処理されると不正確な結論に達する可能性があります。
これらの課題を解決するために、Context Engineering では情報の関連性評価、時系列の管理、矛盾検出といった手法を組み合わせて使用します。
Context Engineering が対処するこれらの課題は、LLM の基本的な制約に根ざした問題であり、技術的な解決策が必要です。次章では、LLM が参照するコンテキストの構成要素を詳しく分析し、効果的な情報管理の基盤を理解していきます。
4. コンテキストの構成要素
効果的な Context Engineering を実践するためには、LLM が参照するコンテキストがどのような要素で構成されているかを理解する必要があります。コンテキストは単一のプロンプトではなく、複数の異なる種類の情報が組み合わされた複合的な構造です。
システムプロンプト
システムプロンプトは、LLM の基本的な動作パターンや役割を定義する指示です。対話の開始時に設定され、全体を通じてモデルの振る舞いを制御します。具体的には、応答のトーン、専門性のレベル、禁止事項、出力形式の基本的なルールなどが含まれます。
エージェントシステムにおいて、システムプロンプトは特に重要な役割を果たします。長時間の実行中に一貫した動作を保証し、タスクの目的を見失わないための基盤となります。例えば、「あなたは企業の営業支援エージェントです。顧客情報の機密性を常に保持し、丁寧で専門的な対応を心がけてください」といった指示により、エージェントの基本的な行動指針が確立されます。
ユーザープロンプト
ユーザープロンプトは、現在実行すべき具体的なタスクや質問を示します。従来のプロンプトエンジニアリングで中心的に扱われてきた要素ですが、Context Engineering では全体の一部として位置づけられます。
エージェント環境では、ユーザープロンプトは人間からの直接的な指示だけでなく、システム内部で生成される中間的なタスク指示も含みます。複雑な目標を達成するために、エージェントが自動的に生成する詳細なステップも、この範疇に含まれます。
短期メモリ
短期メモリは、現在のセッション内での対話履歴と状態情報を保持します。ユーザーとエージェントのやり取り、ツール実行の結果、中間的な判断内容などが含まれます。この情報により、エージェントは文脈を理解し、一貫した対応を継続できます。
短期メモリの管理では、情報の鮮度と関連性のバランスが重要です。古い情報が現在のタスクに不要になった場合は適切に除去し、重要な決定事項は保持し続ける必要があります。
長期メモリ
長期メモリは、複数のセッションにわたって蓄積される持続的な知識です。ユーザーの好み、過去のプロジェクトの要約、学習した失敗パターンなど、将来の判断に活用される情報が保存されます。
長期メモリには複数の種類があります。手続き記憶は「特定の状況でどのような手順を実行すべきか」という知識を、エピソード記憶は「過去にどのような出来事が発生したか」という具体的な経験を、意味記憶は「この企業の主力製品は何か」といった事実情報を格納します。
外部知識(RAG)
RAG(Retrieval-Augmented Generation)による外部知識は、リアルタイムで検索・取得される関連情報です。LLM の内部知識では対応できない最新情報や専門的なデータを補完します。企業の内部文書、業界データベース、ウェブ検索結果などが典型例です。
外部知識の活用では、検索精度と情報の信頼性が課題となります。関連性の高い情報を効率的に取得し、複数の情報源からの矛盾する内容を適切に処理する仕組みが必要です。
利用可能ツール
利用可能ツールは、エージェントが実行できる機能の定義です。各ツールの名称、パラメータ、実行条件、期待される出力形式などの情報が含まれます。メール送信、データベース検索、ファイル操作、外部 API 呼び出しなど、多様な機能がツールとして提供されます。
ツール情報の提示方法は、エージェントの性能に大きく影響します。類似した機能を持つツールが多数存在する場合、適切な選択を支援するための詳細な説明や使用例が重要になります。
構造化出力
構造化出力は、LLM の応答形式を制御する指示です。JSON 形式、表形式、特定のテンプレートなど、後続の処理で扱いやすい形式での出力を求めます。エージェントシステムでは、出力結果が他のシステムやツールに渡されることが多いため、一貫した形式の維持が不可欠です。
構造化出力の指定により、応答の解析エラーを防ぎ、自動化された処理の信頼性を向上させることができます。
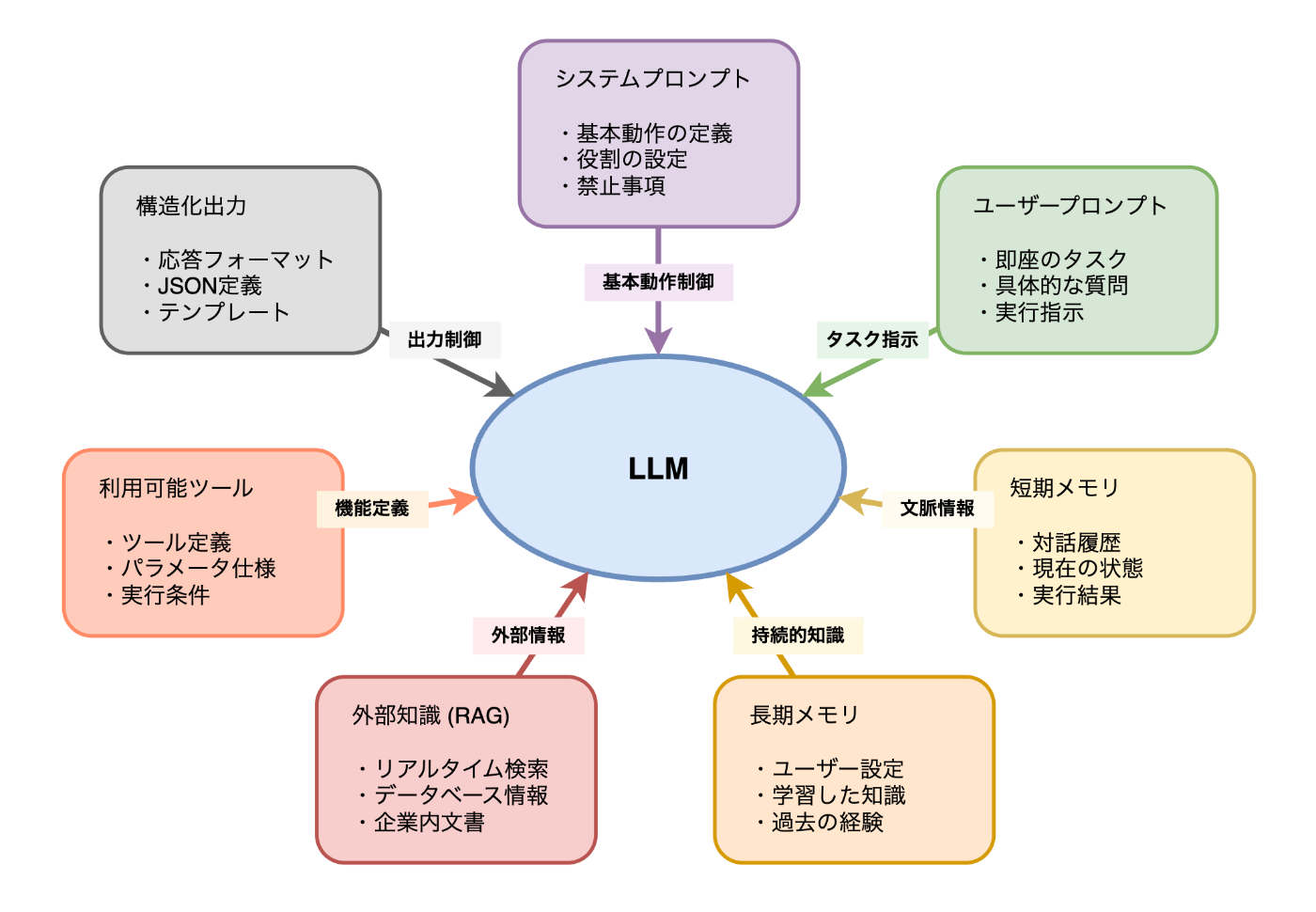
これらの構成要素は独立して機能するのではなく、相互に関連し合いながら LLM の推論を支援します。次章では、これらの要素を効果的に管理するための Context Engineering の 4 つの主要手法について詳しく解説します。
5. Context Engineering の 4 つの手法
Context Engineering では、LLM のコンテキストウィンドウを効率的に活用するために、4 つの主要な手法が使用されます。これらの手法は相互に補完し合い、組み合わせることでより効果的な情報管理を実現します。
書き出し(Write Context)
書き出しは、重要な情報を外部のストレージに保存し、コンテキストウィンドウの容量を確保する手法です。エージェントが長時間実行される際に蓄積される情報を適切に管理し、必要な時に再利用できるようにします。
メモ書きの保存
メモ書きの保存では、実行手順や重要な判断根拠を外部ファイルに記録します。例えば、複雑なデータ分析タスクを実行する際に、各ステップで得られた知見や次に実行すべき手順を記録しておくことで、セッションが中断されても続きから再開できます。
# メモ書き保存の概念例
def save_memo(content, memo_type):
memo_data = {
"timestamp": datetime.now(),
"type": memo_type,
"content": content,
"priority": calculate_priority(content)
}
memo_storage.append(memo_data)
この手法は、「Lost in the Middle」問題の対策としても有効です。重要な情報をメモとして保存することで、コンテキストの中央部分に埋もれることを防げます。
記憶の書き出し
記憶の書き出しは、複数のセッションにわたって活用される情報を長期メモリとして蓄積します。ユーザーの好み、過去の失敗事例、成功パターンなどを記録し、将来の判断に活用します。
記憶の種類に応じて保存方法を最適化することが重要です。手続き記憶は実行手順として、エピソード記憶は具体的な事例として、意味記憶は事実データとして整理します。
実践上の注意点
書き出し手法の実装では、情報過多による逆効果に注意が必要です。すべての情報を保存すると、検索時のノイズが増加し、関連性の低い情報が選択される可能性があります。
対策として以下の手法が有効です。
- 情報の重要度に基づいた自動削除
- 出力内容の構造化による散漫化の防止
- RAG システムとの連携による効率的な検索
- 古いデータの定期的な整理
選択(Select Context)
選択は、膨大な情報の中から現在のタスクに必要な情報のみを取得する手法です。適切な情報選択により、コンテキストウィンドウの効率的な利用と推論の質の向上を実現します。
メモリの読み込み
保存されたメモや記憶から、現在のタスクに関連する情報を選択的に読み込みます。新しいセッションの開始時や、タスクの切り替え時に実行されることが多く、エージェントが次にやるべきことを把握するために使用されます。
# メモリ選択の処理フロー例
def select_relevant_memories(current_task, memory_pool):
relevant_memories = []
for memory in memory_pool:
relevance_score = calculate_relevance(current_task, memory)
if relevance_score > threshold:
relevant_memories.append(memory)
return sort_by_priority(relevant_memories)
ツールの選択
エージェントが利用できるツールが多数存在する場合、現在のタスクに適したツールのみを選択して提示します。ツールの説明が重複していると、LLM は適切な選択に迷いが生じるため、RAG を活用したツール選択が効果的です。
最新の研究では、RAG ベースのツール選択により、選択精度が 3 倍向上することが報告されています。ただし、ツール選択の精度は使用する LLM の性能に大きく依存するため、高性能なモデルの使用が推奨されます。
情報の検索
RAG システムを活用して、外部知識から関連情報を検索・取得します。企業内の機密情報や最新のデータベース情報など、LLM の内部知識では対応できない情報を補完します。
以下の図は、情報選択の処理フローを示しています。
圧縮(Compress Context)
圧縮は、コンテキストに含まれる情報の密度を高め、重要な内容のみを保持する手法です。情報量がコンテキストウィンドウの制限に近づいた際に実行されます。
コンテキストの要約
長大な対話履歴やツール実行結果を要約し、要点のみを保持します。要約処理では、以下の段階的なアプローチが採用されます。
- メッセージレベルの要約:個別の応答の要点抽出
- セクションレベルの要約:関連する複数のやり取りの統合
- 全体レベルの要約:セッション全体の重要事項抽出
古い情報の削除
時系列に基づいて、現在のタスクに不要になった情報を削除します。単純な時間ベースの削除だけでなく、情報の関連性や重要度を考慮した選択的削除が効果的です。
圧縮時の注意点
圧縮は必要な情報の欠落リスクを伴うため、可能な限り避けるべき手法です。圧縮が必要になる前に、タスクの分割や情報選択の最適化を検討することが重要です。
特に重要なのは、圧縮処理自体でミスが発生する可能性があることです。要約過程で重要な詳細が失われたり、文脈が変化したりする場合があります。
分割(Isolate Context)
分割は、複雑な問題を小さな部分問題に分けることで、各部分で必要となるコンテキストを削減する手法です。
処理の分割
複数のエージェントが異なる専門領域を担当し、それぞれが独立したコンテキストウィンドウで作業します。各エージェントは特定のツール群と知識領域に特化することで、効率的な問題解決を実現します。
この手法の利点は、各エージェントのコンテキストを狭い範囲の問題に集中できることです。一方で、エージェント間の協調や、最大 15 倍のトークン使用量増加といった課題もあります。
単一セッション内での分割
同一エージェント内でも、短期的なゴール設定を行うことで実質的な分割が可能です。大きなタスクを段階的に実行し、各段階で必要な情報のみを保持します。
分割の順序
分割手法の適用には優先順位があります。
- 短く明確な指示による単純化
- 細かなゴール設定による単一セッション解決
- 独立したセッションの繰り返し実行
- 複数の専門エージェントによる分散処理
この順序に従うことで、不要な複雑化を避けながら効果的な問題解決を実現できます。
これらの 4 つの手法を適切に組み合わせることで、LLM が最高の性能を発揮できる環境を構築できます。次章では、これらの手法が実際のシステムでどのように活用されているかを具体的な事例を通じて見ていきます。
6. 実践的な適用例
Context Engineering の理論的な概念を理解したところで、実際のシステムでどのように活用されているかを具体的な事例を通じて見ていきます。これらの事例は、適切なコンテキスト管理がシステムの品質に与える影響を明確に示しています。
「安いデモ」と「魔法のようなエージェント」の違い
Context Engineering の効果を最も分かりやすく示すのが、同じ機能を持つシステムでも情報管理の質によって大きく異なる結果を生む例です。
「安いデモ」レベルのエージェントは、ユーザーからの単純な入力のみを処理します。例えば、「明日の会議について確認したい」という要求に対して、基本的なプロンプトのみで応答を生成します。結果として、「明日の会議について詳細を教えてください。何時からでしょうか?」といった機械的で役に立たない返答になりがちです。
一方、「魔法のようなエージェント」は、同じ要求に対して Context Engineering の手法を活用します。まず、ユーザーのカレンダー情報を取得し(選択)、過去のメール履歴から相手との関係性を把握し(RAG 検索)、会議の背景情報を整理します(書き出し)。その結果、「田中部長との四半期レビューですね。明日の午後 2 時からの予定ですが、前回の議事録を確認したところ、売上データの準備が必要でした。最新の数値をお送りしますか?」といった具体的で実用的な応答を生成できます。
この違いは、コードの複雑さではなく、LLM に提供するコンテキストの質によって生まれます。
会議スケジュール調整エージェントの事例分析
会議スケジュール調整は、Context Engineering の 4 つの手法すべてが活用される典型的な事例です。以下のシーケンス図は、充実したコンテキスト管理を行うエージェントの処理フローを示しています。
このフローでは、単純な要求から豊富なコンテキスト情報を組み立てることで、ユーザーの意図を正確に把握し、適切なアクションを実行しています。
コードエージェントにおける RAG の活用
ソフトウェア開発支援エージェントは、大規模なコードベースを扱う際に Context Engineering が特に重要になる領域です。従来のアプローチでは、関連するファイルをすべてコンテキストに含めようとして容量制限に達していました。
現在の高度なコードエージェントでは、以下の手法を組み合わせています。
- 選択的インデックス化:抽象構文木(AST)解析により、意味的に重要な境界でコードを分割し、エンベディング検索の精度を向上させる
- 段階的検索:grep 検索、ファイル検索、知識グラフベースの検索を組み合わせて関連情報を絞り込む
- 再ランキング:検索結果を関連性の順序で並び替え、最も重要な情報のみをコンテキストに含める
これらの手法により、数万行のコードベースからでも適切な情報を選択し、効率的な開発支援を実現しています。
企業内情報検索システムでの実装例
企業内の膨大な文書から必要な情報を抽出するシステムでは、Context Engineering の全手法が統合的に活用されます。
典型的な実装では、以下の構成を採用します。
| 手法 | 実装方式 | 具体例 |
|---|---|---|
| 書き出し | 検索履歴の記録 | ユーザーの関心領域を学習 |
| 選択 | 多段階フィルタリング | 部署・権限・関連性による絞り込み |
| 圧縮 | 動的要約 | 長文書の要点抽出 |
| 分割 | 専門エージェント | 法務・技術・営業別の処理 |
実際の処理では、ユーザーの質問に対して関連部署の文書を検索し、アクセス権限を確認し、専門性に応じて適切なエージェントに処理を委譲します。各エージェントは独自のコンテキストウィンドウで専門的な分析を行い、最終的に統合された回答を生成します。
この手法により、従来は人間が数時間かけて調査していた複雑な企業内情報の検索を、数分でより正確に実行できるようになりました。
これらの事例が示すように、Context Engineering は理論的な概念ではなく、実際のシステム開発で具体的な価値を提供する実践的な手法です。
7. おわりに
本記事では、Context Engineering の基本概念から実践的な手法まで、体系的に解説してきました。LLM を活用したシステム開発において、情報管理がいかに重要な役割を果たすかが明らかになったと思います。
Context Engineering の重要性の再確認
Context Engineering は、単なる技術的な最適化手法ではありません。エージェントシステムの成功と失敗を分ける決定的な要因です。優れたコードや高性能なモデルを使用しても、適切な情報が適切なタイミングで提供されなければ、期待される結果は得られません。
現在、多くのエージェントの失敗がモデルの性能不足ではなく、コンテキストの問題に起因していることが判明しています。つまり、Context Engineering の技術習得は、実用的な LLM システムを構築するための必須要件となっています。
エージェント開発における核心技術としての位置づけ
Context Engineering は、エージェント開発において中核的な位置を占める技術領域です。書き出し、選択、圧縮、分割という 4 つの手法は、個別に使用するのではなく、システムの要求に応じて組み合わせることで真価を発揮します。
これらの手法を適切に実装することで、限られたコンテキストウィンドウの中で最大限の性能を引き出し、長時間実行されるエージェントでも一貫した品質を維持できます。企業レベルの実用システムを構築する際には、Context Engineering の設計が全体のアーキテクチャを左右する重要な要素となります。
参考文献
Discussion