はじめに
こんにちは、ELYZA Labチームの佐藤 (@shoetsu_sato)です。最近のLabチームの取り組みの1つとして行ってきたLLMエージェント開発の概要とELYZAにおける研究開発の内容について紹介します。
大規模言語モデル(LLM)は単なる対話システムを超えて「エージェント」としての活用が注目されています。エージェントとは、自然言語で与えられたタスクを理解し、外部ツールやデータベースを利用しながら、LLMコールを連続的に行い自律的に問題解決をする仕組みです。最近ではOpenAIやGoogle、Hugging Faceなどが次々にエージェント開発用フレームワークを公開しており、研究・産業ともに期待が集まっています。(LLM以前にもAI分野では環境とインタラクションするシステムを指してエージェントという単語は使われていましたが、本稿ではLLM Agentを指して「エージェント」と呼称します。)
エージェントを提供する実サービスに関してもManusや Genspark など、自然言語で大まかな指示を与えるだけでブラウザ操作・画像の収集や作成・コード実行をはじめとした多様なアクションを組み合わせてタスクを実行するサービスが既に登場しています。(例: Manusによる調査タスクの実行) これまでのLLMベースのサービスではLLMに入力する内容を検索・コピペなどで取得することや、LLMに提案された内容を実際に実行する所はユーザに委ねられていました。(ChatGPTなどは既に一部そうなっていますが)一方でエージェントは、自分で情報を取ってくる・実際に試した結果まで見せてくれるなど、問題解決にあたって自律的に動いてくれることの範囲が、ツール利用が可能になった事によって大きく広がりました。生成AI活用によって企業の生産性向上を目指すELYZAでも、解決できるタスクの幅・長さを向上させるLLM Agentに注目して研究開発を進めており、その中で得られた知見を共有できればと思います。
エージェント開発においてはコアのエンジンとなる大規模言語モデル (LLM) のテキスト・コード生成能力やプランニング能力もさることながら、外部ツールとの連携・実行環境の安全性・タスクによって変わり得る戦略的制御など、LLM本体に依存しない優れた設計と開発のノウハウが必要となります。特に、ELYZAが重きを置くビジネスユース向けソリューション・プロダクト提供では、想定される状況やタスクの違いから、学術研究で盛んに取り組まれている問題とはやや異なる試行錯誤が必要となりました。そこで本稿では、LLM開発そのものの取り組みは別記事に譲り、既存のOpenAI・AnthropicなどのクローズドLLMを用いた上で、エージェント開発の現実的な苦労と工夫に焦点を当ててご紹介します。
LLMエージェントについて

まずエージェントがどのように動作するのか、どこが開発のポイントとなるのかについて紹介します。前提として、ELYZAのLabチームではデベロッパーの規模、ユーザ数、必要となる機能の豊富さやカスタマイズ性の高さなどを考慮してGoogle ADK を用いたプロトタイプ作成を行ってきました。このフレームワークを例に説明すると、エージェントの基本的な動作は上図のような意外とシンプルなフローの繰り返しとなります。また、ここでLLMによって実行される "Function call" はエージェントでは「ツール」とも呼ばれ、多くの場合Pythonコードで実装された単一のメソッドを指します。エージェントはメソッドのdocstringに基づいてツールの使い方を把握し、引数を与えて実行することで内部でコード実行やブラウザ操作などを行います。
- そのステップのテキスト生成
(例: "まずデータを確認します。") - エージェントに登録されたツールと、与える引数を選択して実行
({"tool": "bash_tool", "kwargs": {"cmd": "head -n 20 sample.csv"}) - ツール実行の結果(stdout, stderrなど)をフィードバックとして受け取り、コンテキストに追加
そのため、エージェントを作り込む際は基本的にはいつ何をすべきかというインストラクション (prompt) と作業の効率化のためのツールの実装をまず行うことになります。言い換えると、プログラム上で厳密な条件分岐を実装せずとも、インストラクションを介して自然言語の形でフローを記述出来る事がエージェントの利点の一つと言えるでしょう。
加えて複雑なタスクにおいてはプランナーと呼ばれる、はじめのユーザ入力を受け取ってからChain-of-Thought (CoT)に基づく手法で計画を立て、一つ一つ確実にステップを進めていくための機能が採用されます。特にエージェントに関する近年の論文ではどう事前のプランニングをエージェントの挙動を安定させるか・フィードバックをどう与えるか・難しいタスクで有望そうな行動をどう探索するか、といった行動決定のための研究が盛んに行われています。[1][2][3] また現実的には、Manusによるエージェント構築のガイド[4]でも述べられているようなTodoリストによる管理などもコストパフォーマンスが良く使われる事が多い印象です。
特化エージェント開発例: データ分析タスク
Labチームがソリューションやプロダクト利用を見据えてエージェントのプロトタイプを検討した際、前提とした状況は既存研究やベンチマークでしばしば想定される「エージェントが事前に明確な計画を立て、長期にわたって複雑な行動を単独で実行する」ケースではありませんでした。ELYZAが共同研究などを通じて生成AIの社会実装を進める中で見えてきたのは、現場のユーザ自身が何をしたいのか、どう進めたいかをはっきり認識していない状況が多いという課題です。そのため汎用的なエージェントを導入しても、ユーザ主導で自身の状況を明確にAIに伝えた上でタスクを進める、という結果にはなりにくいと考えました。そこで、ある程度ユースケースを規定した特化エージェントを設計する事でエージェント主導でタスクを実行し、加えて適切なタイミングでインタラクティブにユーザのニーズを引き出しながらタスクを進める事で、ユーザの負担の軽減に伴うUI/UXの向上、高速化、省コスト化が可能になるのではないかと考えました。
開発においては、ELYZAが社会実装を進める中で得られたニーズや市場ポテンシャルをもとに対象タスクを選定しました。ここではその1つとしてデータ分析タスクの例を紹介します。ここでのデータ分析タスクは入力としてCSVデータが与えられ、データの傾向や有用な知見が書かれたレポートを出力するタスクとします。なお、以下では求人・採用のサンプルデータとして弊社が実験のために作成したダミーデータを例として用います。エージェントの作業内容としては出力となるレポートの記述・データを整理するためのコーディング・シェルの操作全般などとし、簡単のため検索エンジンを用いた情報収集など追加の処理は行わせないものとします。

汎用的・簡易なインストラクションとツールのみを定義し、基本的なタスクのフローはLLMの判断に大部分を委ねたシンプルなエージェントでこのタスクを実行してみます。近年のLLMの生成能力の高さから、基本的なツール呼び出し・シェルの実行やPythonコーディングなどは人間から見てもかなりのレベルで実行してくれる事が多いですが、そうしたエージェントではどういった問題が発生するでしょうか?
コンテキスト・生成するテキスト量の肥大に伴う高コスト化
エージェントを作ってみようと試行錯誤を始めた開発者の多くが感じるであろう点に、エージェントはトークン消費量が非常に大きいという事があります。経験的にはシンプルなエージェントは軽量なタスクで100~500k tokens, ある程度重いタスクになると1M~ tokens以上、エージェントがおかしな挙動を示した場合はそれ以上⋯のトークンを消費し、それは主にInput側のテキスト量の多さに起因します。簡単のため1M tokensのReadとして考えると、Claude-4-Sonnetでは$6, Gemini-2.5-proでは$2.5と、かなり1回の実行が高額になってしまいます。
消費トークンが大きくなってしまう要因として、エージェントは自身のプロンプトに加えて生成したテキスト+function callの実行内容、ツールとして実行されたfunction callの結果を順次コンテキストに加えてタスクを進めます。そのため、例えばコマンド実行の結果生じたエラーやwarningのログであったり、サイズの大きいデータをcatコマンドで全表示する処理をエージェントが実行し、結果を素直にコンテキストに追加し続けると以降数十回のLLM呼び出しの入力として負担となり続けてしまい、最悪最大入力長制限などで処理が停止してしまいます。
また、ツールやプロンプトの定義によってはエージェントはやや非効率的なシェルコマンドの実行によって全てを解決しようとしがちです。例えばあるPythonスクリプトを実行し、エラーが出たことを確認して書き換える場合、人間であれば1行変えるだけの処理のために、エージェントは時折 "cat {修正したコードの全文} > {元のファイル}" のような全文を再生成する処理を実行し、結果的に生成テキスト量の肥大化、レスポンスの遅さを招きます。そのため理想的にはシェルに接続されていれば(sedコマンドなどを組み合わせることで)実行可能な処理であっても、例えば「文字列置換ツール」のような特定の処理をツール化する事で確実性・効率性の改善が可能です。
それ以外にも個々の詳細については書ききれませんが、エージェントの効率や挙動に影響する工夫としていくつかの要素を列挙いたします。
- KVキャッシュの効率的な利用
- ツール定義の時点でエージェントに返す情報量の上限を設定し、ログは必要に応じて後から参照
- タスク内の個々の処理の難易度に応じて高価な・安価なLLMを使い分ける
- 特化対象のタスクにおいて頻繁に行う共通処理のコード化
仮想環境上でのセキュアな実行環境整備の苦労
エージェントの開発を始めてレポジトリを構築し、まずは自分たちの目標とするデータ分析タスクのエージェントを素朴に作り、とりあえず実行してみよう⋯となったとします。するとエージェントのプロセスが立ち上がり、分析に必要なPythonコードや中間結果の画像、テキストファイルを無秩序に作成し、時に怪しげなシェルコマンドの実行を行い、ファイルの削除・移動も行います。そう、レポジトリが存在するローカル環境(例: 自分の管理するPC・サーバ上)で。
これは我々のタスクにおいてエージェントによるコード生成・シェルコマンドの実行が必要になる事に起因する問題ですが、安全かつ安定的にエージェントの実行を行うためには、サンプルコードで紹介されるような「とりあえずタスクは実行できる」状態のエージェントでは不十分でした。特にサービスでの実運用の際は不特定多数のユーザによる実行が並列に走るため、各セッションの独立性を保ち互いに干渉しないようにする事、悪意のあるコマンドを実行させようとする試みを防ぐ事などを考えると、専用の仮想環境(サンドボックス)を用意する事が必須です。個人的な余談として、Labでプロトタイプ開発を行っていた時点では導入が面倒そうだしもっと後で良いのでは⋯?と楽観的に考えていましたが、実験の際にエージェント自身のREADMEやファイルの書き換えが生じ、それに気づかずgit commitしてしまったあたりでいよいよ危機感を覚えました。
多くのエージェントフレームワークはサンドボックス連携は想定されているものの、まだ黎明期である事から痒い所に手が届かない状態だったため色々と拡張機能の追加・工夫が必要でした。ここではその一部を紹介します。
簡便に利用可能なサンドボックスラッパーの構築
複数人でエージェントの開発を行う場合、開発者は必ずしもエージェントフレームワークの仕組みやサンドボックスの利用に慣れ親しんでいないため、サンドボックス実行自体は可能なら透過的に扱え、ツール実装者に負担をかけない事が好ましいです。そのため下記のように、通常のツール定義のようにPythonメソッドを書き、@execute_in_sandbox のようなデコレータを適用するだけでその部分の処理がサンドボックス内で実行されるような仕組みを作りました。
@execute_in_sandbox
async def bash_tool(command: str) -> dict[str, Any]:
"""与えられたコマンドをBashで実行する"""
...
サンドボックスと連携したファイル管理・ファイル更新状況のコンテキスト管理
サンドボックス上でコード生成・コード実行した場合、当然その結果はサンドボックス上にのみ存在します。これらの生成物・途中過程で使ったコードをユーザが受け取りたい・確認したい場合もあるでしょうし、逆にローカル環境からファイルをアップロードしたい場合もあります。加えて、そうした環境内のファイルの変化は必ずしもエージェントに伝わりません。例えば、何らかのコマンド・ツールを実行した結果複数のファイルがダウンロードされたとしても、その一覧や内容は人間と同じくログを頼りにファイルを把握し、実際に開いてみるまで分かりません。こうした状況で、エージェントが混乱せずタスクを達成できるようにするため、Google ADKのartifact、callback機能などを活用し、サンドボックス・ローカルセッション間のファイル状況を省コストで常に同期できるような仕組みを作りました。
「これじゃない」感のある挙動とユーザ固有の背景共有の難しさ
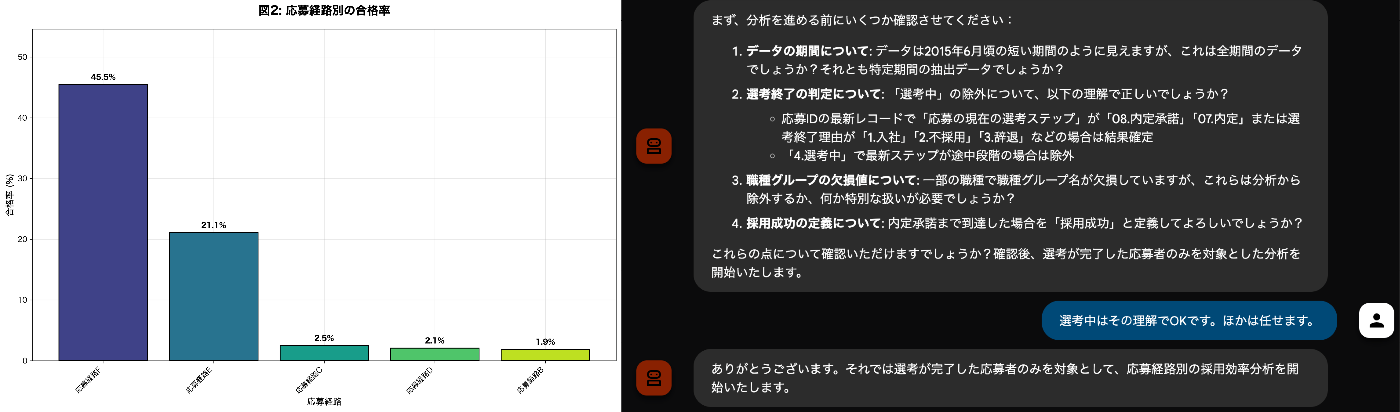
ユーザがLLMやエージェントにクエリを投げタスクを依頼する際、求める出力に必要な情報がきっちりとフォームに記載された状態でタスクが実行される事は稀です。前述したデータ分析の場合、データをアップロード後に「このデータを分析して」くらいのクエリを入力して結果が得られるのがユーザにとっても便利なサービスでしょう。しかし、このような入力の自由度の高い状況では「データを分析するとは何か?」「どういう順序で、何を実行すべきか?」「どういう出力がユーザに喜ばれるか?」はエージェント任せとなり、特にコスト削減のため高性能なLLMが使えない状況では一定確率で不安定な挙動を示し、場合によってはエラーを繰り返しタスクのゴールまでたどり着けない状況も発生します。

例えば上図は実験の中でエージェントが出力したグラフの一例です。ユーザを採用担当者と想定し、どういう応募経路で採用が上手く行っているか、採用の課題はどこにあるかといった知見が得られる事を期待して入力しましたが、ユーザの状況や課題感が十分に伝わっていない状況ではエージェントが可能なデータ操作を手当たり次第試すという挙動になり、結果「日ごとの応募数」のような、細かすぎたり想定した課題に対して有用とは言い難いデータ操作を行ってしまうこともあります。
このような失敗以外にも、ユーザの要望やデータの背景について詳細な入力クエリ、あるいはユーザとのインタラクティブなやり取り無しでは判断が難しいケースも存在します。例えば、入力CSVのカラムにエンジニアとEngineerのセルが混在しており、その区別に事前情報が与えられなかった場合、それはまとめて集計するべきでしょうか?別として扱うべきでしょうか?人間の作業であればデータに詳しい担当者に前提の確認をする必要が生じるでしょう。あるいはユーザにとっても何を知りたいか不明瞭な場合、分析テーマをエージェント側から複数提示してユーザとのやり取りの中でタスクを明確化、などのやり取りが必要になるでしょう。このように、想定されるタスクにおいてユーザとのインタラクションをいつどのように行うかというフローの設計、人間の知見や感覚をエージェントに与える事によって確実性の向上・タスクのコンパクト化が可能になると考えました。
こうした背景から、特化エージェントのワークフローの定義(データの確認・分析可能なテーマの立案・背景の問い合わせ)やツール定義をデータ分析に対して作り込むとどう変わるか?という検証、プロトタイプの開発を行ってきました。 下図はエージェントとのやり取りと、出力レポートを一部抜粋したものです。CSVデータだけアップロードした状態から、何について分析するかをエージェント側から提案し、データに関する前提(例: 選考中のものは除いて良いのか?)などを自律的に問い返し、分析者の知りたい情報に絞った素早い分析を行えています。


メタエージェントによる自動最適化の研究
ここからはやや発展的な、Labの取り組みの一つとして行っている研究内容の紹介になります。先程紹介したエージェント開発の節ではインストラクションによるワークフローの定義や確実性を高めたい処理のツール化によって挙動が大きく変わる、という説明をしてきました。
しかし実際に特化エージェントを開発してみると、プロンプトやツール設計といった比較的限定された要素の調整であっても必要な試行錯誤が膨大となる上に、対象タスクごとに前提知識や背景情報が異なります。こうした細かなケースについて人手で捌くことは現実的ではありません。そこでエージェントが人間のように作業できるのであれば、エージェント自身にエージェントを設計・改良させてしまえばよいのではないか、あわよくば人間が作ったものよりも良いものが見つかるのでは、という発想につながります。こうした背景から、近年は「エージェントを作るエージェント」、すなわちメタエージェントによるコーディング・最適化に関する研究も進み始めています。[5][6]
ELYZAの過去のブログでも紹介したように、Cline, Claude CodeなどAIによるコーディング支援はもはやエンジニアにとって一般的になっていますし、数学など科学技術分野においてはAIによるアルゴリズム探索が盛んに行われ、一部の領域では既に人間が考案したものよりも効率的・高速なアルゴリズムの発見に成功しています。[7][8]
一方で、1つのアルゴリズムやコードの改変だけではなくエージェント全体の改良・最適化となると、対象となるシステムの複雑度は高く、ステップごとの評価も明確に行う事が難しいため、メタエージェントが作成したエージェント(以下、子エージェント)の改善ループを安定化させる事にも様々な課題が存在します。

上図が単純化した、我々のメタエージェント実行フレームワークの概要図です。ここでは簡単のため、改良の対象をエージェントのツール定義とインストラクションに絞っています。メタエージェントの基本的な動作は以下の通りです。
- 初期状態(空のインストラクションだけを持ったエージェント)を含めた既存の子エージェントから親を選択し、評価セットと合わせてサンドボックス環境にコピー
- メタエージェントがサンドボックスにアクセスし、事前に定義されたインストラクション・ツールに基づき子エージェントを改変
- サンドボックス上で子エージェントを実行し、出力(この例ではデータ分析のpdf)を得る
- 改変した子エージェントをサンドボックスからコピーし、次のバージョンとして登録
- LLMベースの評価モジュールによって子エージェントを評価し、スコア付けを行う。このスコアを使って次のステップの親を選択する
また、このフレームワークの構築にあたってのポイント、重要と感じる点をいくつか紹介します。
メタエージェント自体はタスク非依存に設計
ややこしいのですが、例えば対象タスクの実行にコード生成が必要になる場合、メタエージェントが行うべき仕事は「『与えられたタスクに必要なコードを生成』出来る子エージェントのコード生成」であって、タスクそのものを解くことではありません。そのためタスク固有の情報、例えばデータ分析でどういう事をすべきで、どういった出力が良いとされるかなどはメタエージェント側の実装には含まれず、メタエージェント自体はどのファイルが改良対象か、編集の際に何に気をつけるべきかといった指示や、編集・実行・評価に関連するツールなど、子エージェントの編集に専念する構造となっています。
我々の設計では、タスク固有の情報はテストケースである入力クエリと分析対象のデータ、評価モジュールで用いるプロンプトのみによって定義されます。このような設計を採用する事で、タスクが変わってもやるべき事は良い評価基準と評価データを用意する事に絞られ、開発・実験がコンパクトになり、多様なタスクに対応したエージェントの初期実装を進めやすくする事を企図しています。
メタエージェント・子エージェントの詳細なロギング
前節のエージェント開発過程でもそうでしたが、エージェントの実行はとにかく長く、複雑なものになりがちです。特にメタエージェントでは自身が実行する開発ステップに加えて、複数の子エージェントによるタスク実行がサンドボックス上という微妙にアクセスしにくい環境で行われます。そうした状況では子エージェントがテスト時におかしな挙動を示した時、それが何故起こったのか?このステップでメタエージェントはどういう変更を行ったのかを、単純なログやセッション履歴を眺めて調査する事は非常に手間です。我々の研究開発ではOpikを用いたロギングによって各エージェントの実行を追跡しやすい形で記録する事に加えて、メタエージェントの各ステップでどういう変更を行ったか、実行時に子エージェントがどのような問題を起こしたかなど、LLMベースのサマリを作成するなどの工夫で、作業コストの軽減・メタエージェントにとっての次ステップのヒントとなる情報の集約を図っています。
多角的な情報による評価
前述したアルゴリズムの自動探索のようなケースと違い、我々が対象とするようなタスクでは出力に対する一意なルールベース的評価が難しく、エージェントの実行時にそれが良くなったのか?を正確に評価することは容易ではなく、ここをどこまで改善し、有用なフィードバックと出来るかがとても重要だと考えています。
子エージェントの出力に対するタスクごとの評価基準をしっかりと設計し、タスクの出力を人間が好ましく感じる方向へと誘導することは勿論ですが、問題は出力のクオリティだけではなく、子エージェントの実行時間やステップ数が膨大になっていないか?むやみにツールを定義して過度に子エージェントが複雑化していないか?などの要素も加味する必要があります。また、探索初期のエージェントでは能力の低さからそもそもタスクの完了までたどり着かずにエラーで終了してしまうケースもあるため、人間の作業者による開発と同様に子エージェントがどういう挙動を示したのかのログも有用な手がかりとなるのですが、そうした情報をのべつまくなしに使おうとすると今度はコンテキスト長の問題が生じます。そのため、実行ログを分析して要約を別途出力させる、といった工夫も必要となりました。
加えて子エージェントの評価について、複雑度が高いタスクでは単一のLLM呼び出しだけでは評価が難しい要素も多数存在します。例えば前述したデータ分析タスクでは、子エージェントが間違った分析をしていないか、本当に与えられたデータからその結論を導けるのかという点に関しては厳密には出力だけではなく、実際のデータと照らし合わせて確認する必要がありますし、分析の結果行う提案の有用性やもっともらしさについては過去の類似事例を検索するなども良い手がかりとなると考えられます。現在の我々のアプローチではLLMベースのシンプルな評価モジュールを採用していますが、近年では他のエージェントにエージェントの評価をさせる手法[9] なども提案され始めており、そうした手法の導入が今後の課題の一つとして考えています。
最後に、メタエージェントのステップが進むにつれ子エージェントの出力がどう変わるかの一例を紹介します。同じくサンプルデータを使ったデータ分析タスクにおいて、下図左が1ステップ目(メタエージェントが初回実装し、フィードバックが得られていない状態)、右がその数ステップ後の子エージェントの出力したグラフです。変化が分かりやすい例として、特に指示を与えない状態でmatplotlibなどのグラフ描画ライブラリを用いる処理をエージェントに実装させると、日本語でクエリ・データを与えているにも関わらずフォントの文字化けや英語ラベルの表記など、不自然なグラフの作成が行われる事があります。そこで例えば評価尺度として「図の見やすさ」やその基準として「日本語で書かれていること」などを与える事で、ステップを重ねるうちに下図右のように比較的自然な図表を出力するようになります。

メタエージェントがフィードバックを用いた修正を行う前(左)、後(右)
おわりに
本記事では、ELYZA Labチームで行ってきたエージェント研究開発の一部と、その中で得られた知見について紹介いたしました。エージェントの登場によりAIが可能な作業の範囲が広がるにつれ、言語処理や機械学習の知識だけではなくUX、セキュリティ、安定性、コストパフォーマンスなどサービス導入にあたり留意すべき事の幅、部署を跨いだ協力体制の必要性なども広がり、AI分野における総合格闘技として困難なテーマだと感じられる一方で、これからのAI社会を形作る上で避けて通れない重要な課題であるとも考えています。
ELYZA はリサーチャーはもちろん、ソフトウェアエンジニアや AI コンサルタントなど、様々な職種で一緒に事業を前に進めてくれる仲間を募集しています。詳しくは下記をご覧ください。
-
REACT: SYNERGIZING REASONING AND ACTING IN
LANGUAGE MODELS (Yao+, 2023) ↩︎ -
Tree of Thoughts: Deliberate Problem Solving
with Large Language Models (Yao+, 2023) ↩︎ -
Reflexion: Language Agents with
Verbal Reinforcement Learning (Shinn+, 2023) ↩︎ -
Context Engineering for AI Agents: Lessons from Building Manus ↩︎
-
AFLOW: AUTOMATING AGENTIC WORKFLOW GENERATION (Zhang+, 2025) ↩︎
-
AlphaEvolve: A coding agent for scientific and
algorithmic discovery (Novikov+, 2025) ↩︎ -
Mathematical discoveries from program
search with large language models (Romera-Paredes+, 2023) ↩︎ -
Agent-Testing Agent: A Meta-Agent for Automated Testing and Evaluation of Conversational AI Agents (Komoravolu and Mrini, 2025) ↩︎

Discussion