ELYZA開発チームのマネージャーのtarunonです。公に何かを出すのは久々になります。
ELYZAは2025年9月9日に、ELYZA Worksとしてサービスを公開しました。 我々のチームで開発をしたものですが、開発にあたってAIコーディングは活躍しており、その様子や、これまでの取り組みとの相乗効果について紹介します。
はじめに
Clineが話題になり、Claude Codeが出てきて、いよいよAIコーディングはソフトウェア開発のメインストリームの話題となりつつあると思います。たびたび言及されていることではありますが、AIに全てやらせるのではなく、既存の自動化技術との組み合わせで、より効率的に、安全にAIコーディングのメリットを享受できます。私もそう信じています。
元々、ELYZAの開発チームは「少ない人数だが定期リリースを安全にこなしたい、しかし回数は減らしたくない」ということから、自動化はそれなりに力を入れて取り組んでいました。AIコーディングを実際に導入してみて、自動化との相乗効果でその真価が発揮されるという確信を得ています。
この記事では、ELYZAが取り組んでいる自動化の紹介と、それがAIコーディング導入によりどのような相乗効果を生み出したか、一つずつ紹介していきます。新規性のある話というよりは、どこかで言及されたものの振り返りのような形になるかなと思います。
前提として、ELYZAの技術スタックは以下の通りです。
サービス全体の構成として、アプリケーションサービスと推論サービスをMessageQueueで繋ぐ構成となっています。
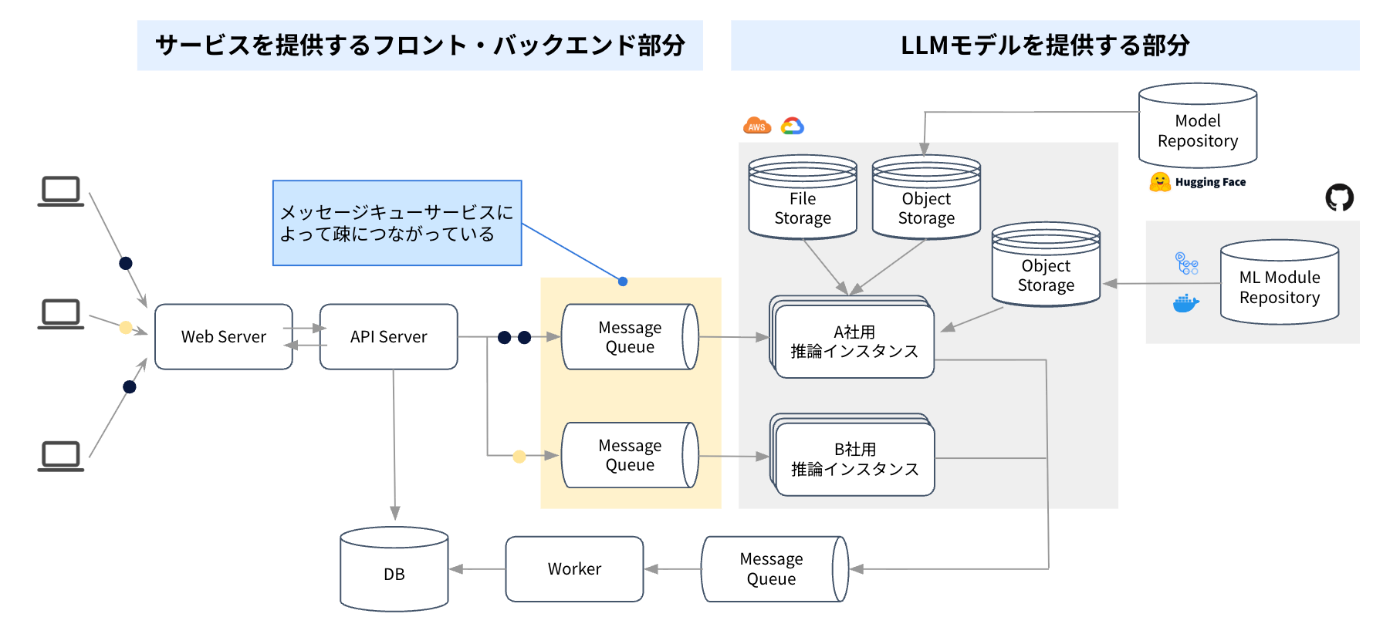
上記構成のうち、全てのアプリケーションサービスとインフラ構成を一つのリポジトリにまとめていて、所謂モジュラモノリスに近い構成となっています。
アプリケーションサービスにおいてはNext.jsとExpress.jsを採用しており、全てTypeScriptで記述しています。推論インスタンスはPythonのWorker(一部APIとして機能)として構成しています。
ブランチ戦略としてgit-flowを採用し、main, develop, feature/**をそれぞれproduction, staging, developmentの環境に割り当てています。リリースは週一の定期リリースとしています。
元々、ソリューション事業の成果をお客様に利用いただくためのプラットフォームとして開発していたものを、サービスにも展開したものなので、サービス公開は先週ですが、ソフトウェア自体の歴史は数年あるような状況となっています。
コーディングには専らClaude Codeを活用しています。Claude Proのプランから配って、上限に届くようであればClaude Maxにしています。大半のソフトウェアエンジニアはClaude Maxの契約になっています。リポジトリで .claude/commands/** を共有して、チームでノウハウを育てるようにしています。
コーディング規約ではなく、LintとFormatで完結させる
ELYZAのプロダクトのリポジトリは明確なコーディング規約を設けていません。強制するものがあれば、それは全てLint/Formatに実装する、実装できる範囲でやる、ということにしています。実装パターンに関しては「周りのコードを見て真似してね」という緩い方針はありますが、これも規約とはしていないです。(チームメンバーがしっかりしてくれているおかげで、コーディング規約による統治が必要なかった、という側面も大きいのですが)
AIコーディングにおいてコーディング規約に従わせたり、従わせるために試行錯誤をするよりも、Lintのエラーに応じて修正させたり、Formatで強制的に従わせる方が消費トークン数から見ても有利だろうと考えています。幸い、今日のAIコーディングは、周りのコードを見て真似をするというのは得意なようで、我々の戦略とうまく噛み合っていると思います。
ただ、Lintからの修正は万能ではなく、うまくいかないと // eslint-disable-next-line ... を使ってくるという課題はあります… が、差分見れば一発で看破できるのでトータルのレビューコストは安く済んでるのではないでしょうか。
また、CI用のコマンドを手元で走らせて必要に応じて修正を行う /finalize というカスタムコマンドをチームでシェアして活用しています。色々作業した後、とりあえず使っておくと差分が綺麗に整って便利です。
API Schemaを先に定義しコード生成をするドキュメントファーストな開発
ELYZAではAPIの実装を行う際、まずOpenAPI(Swagger)で記述されたAPIドキュメントに、エンドポイントの仕様を記述することからはじめます。記載されたyaml形式のAPIドキュメントからTypeScriptのAPIクライアントを生成し、そのAPIクライアントの型情報を使って、ReduxのActionやExpressのhandlerをTypedにするような取り組みを行っています。API Schemaを変更せずにRequest/Responseの定義を勝手に変更するとコンパイルが通らなくなるので、必ずAPI Schemaから変更する必要があります。
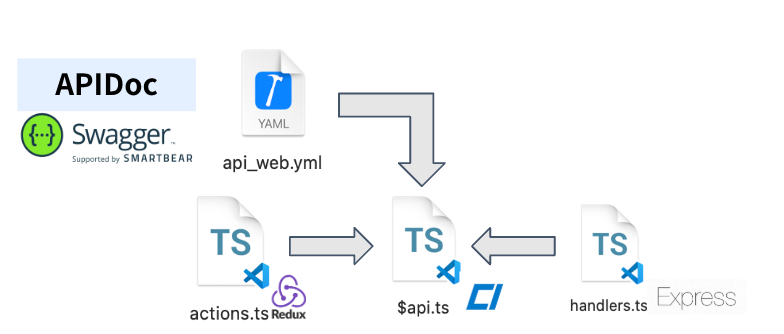
2018年頃にこの仕組みの基礎を作ったんですが、当時は「コードからAPIDocを生成する」アプローチや記事が多く、調査と選定に苦労したのを覚えています。
AIコーディングと組み合わせた現在においては、APIドキュメントに新しいエンドポイントを記載すれば、そこからAPIの実装をある程度AIに任せることができる、という相乗効果を生み出しています。
Next.jsのコードを全部生成してもらう、というのはまだうまく行かないですが、ReduxのActionやReducerまでの実装であれば、ある程度うまくいく印象です。
可能な限りIaCを進めること 開発環境がPR別に建てれること
ELYZAではインフラの定義を可能な限りTerraformで記述しています。Terraformで記述していないのは、公式のproviderが提供されていない一部の依存サービス(SendGridなど)のみであり、それらも変数経由でTerraformで記述済みのインフラから接続する形としていて、複数環境を統合管理できるように整えています。この成果の一つとして、PullRequestごとの独立した開発環境を作れるようになっています。
feature/** のブランチ名でPullRequestを立てると自動的に環境が立ち上がり、Merge/Closeをすると環境は破棄されるようになっています。

並行して複数の開発を進め、安全にQAが行える、また開発者にとってチャレンジングな変更を実証できる環境を実現しています。
AIを活用したプロジェクトにおいてAIが主体となるインフラ構成の変更は難易度が高く、失敗した事例も散見します。Replitの話は記憶に新しいです。
ELYZAにおいてはインフラの変更についても、AIが変更するのはコードのみになっています。またTerraform Planおよび、独立した開発環境の段階から影響のチェックを行っています。AIはproduction環境はもちろんのこと、開発環境であっても直接的なアプローチは行いません。
実際のところ、Terraformの記述をAIに変更させる場合であっても、うまくいく確率は通常のコーディングと比べてかなり低いという感覚があり、このことからも「直接browser-useでインフラを変更させる」のはたとえ開発環境であっても、試行錯誤の過程から再現性が担保できなくなる上、そもそも危険だろうなと考えています。
開発環境の整備は開発全体の生産性(コーディングからQAまで)の観点で重要な要素でしたが、AIの活用範囲を安全に広げる意味でも重要であると考えています。
ユニットテスト/E2Eテストの充実
テストケースが網羅されていること、E2Eテストによる基本シナリオの保護も大事な観点です。特に、AIコーディングによって生産性が上がったことで、確率によって発生するバグの個数も単純計算で増えることになります。エンバグを防ぐためのテストが充実していることは、AIコーディング以前よりも重要性が遙かに高くなったと思います。ユニットテストに関しては特にAPI Serverにおいてのサービスレイヤや、Web Serverにおいてのシンプルなコンポーネントに力を入れてテストケースを追加しています。カバレッジで測るのはどうかというのはありますが、サービスレイヤのカバレッジで70~95%、シンプルなコンポーネントについて60~80%程度のカバレッジとなっています。E2Eテストはアプリケーションの主なシナリオを中心に、コンポーネントテストとカバー範囲を分担して実装を進めています。開発環境はPR番号ごとに明確な機能差分を含んで独立しているので、E2Eテストが落ちた場合も、原因がはっきりしていて修正も明確です。
/code-review のカスタムコマンドをチームでシェアしていますが、このレビュー観点の中でもテストの追加/修正また妥当性を要求しており、維持しやすい環境にしています。
テストを書くことををサボっていると「‼️重大な問題点」と容赦無く指摘してくれます。人間がそれを指摘する場合に比べ、心理的ハードルが低く済んでいる点は、大きなメリットになっていると感じます。なおレビューを受けてテストケースを追加するのは専らClaude君になりますが…
セキュリティの取り組み
ELYZAではセキュリティの取り組みの自動化も進めています。
代表的なのは3つあって、1つはDependabotのパッチについて、CIが通っていれば自動でマージし、staging環境まで配信する仕組みがあります。これは結構ありふれてそう。
もう1つは、GMO Flatt Securityさんから提供されているShisho Cloudを活用して、自動的にリソースの監視を行っています。
最後に、GMO Flatt Securityさんから提供されているTakumi byGMOや、Claude Codeで提供されている /security-review のコマンドを組み合わせて、PRベースの脆弱性チェックを実現する取り組みを進めています。
金曜日は借金返済!
普段進める大きな機能開発の枠組みで取り扱わない、プロダクトの細かいバグやコードベースの改善といったものはチケットに切ってBacklogに置いてます。大体こういうものは、置きっぱなしの溜まりっぱなしになりがちで、そのあと棚卸しをして「やっぱやりたいっすよね」→(やらない)までがよくある光景かなと思います。
ELYZAでは細かいバグの修正やコードベースの改善をするためにチーム全体で20%の工数を取ると明示的に決め、毎週金曜日に借金返済をする、と謳って取り組んでいます。もともと僕がマネジメントの傍らで借金返済に勤しんでいたのですが、おおよそチーム工数のうちの15%程度の出力で借金増加の傾向があったため、チームで20%つかうことにしよう、と決めて取り組んでいます。Backlogに積み上げるチケットも、ソフトウェアエンジニアが自ら問題を定義してチケットを切れるので、根本的にこれやらないといけないんだよな〜みたいなタスクにも取り組めるようにしています。
ただし、緊急のタスクが発生してる時は借金返済は手伝ってもらえなくなります🥺 マネージャーを緊急タスクの頭数に入れると碌な事にならないので、結果としてちょっと暇なマネージャーがいそいそ借金返済をする事になります。
まとめ
この記事ではELYZAで取り組んでいる自動化と、それがAIコーディングと組み合わせた時にどのように作用したかを振り返ってきました。一つひとつは別に新規性のある話では無く、「ちゃんとやろうね」「やりたいね」という、言ってしまえばAIコーディング以前に出尽くした古い話です。
AIコーディングを導入しようとする時、初めて触った時、キラキラした魔法みたいな上手くいくハックがあるんじゃないか?と夢見てしまうものだと思います。
LLMにプロンプトを渡せばそれなりの結果が返ってくる。良い結果にするためのフローをいくつも作ってたくさんの推論コストをかければ、大体のことは実現できるでしょう。でも、例えばコードにformatterをかけたり、テストを実行してその結果を検証する、また一部のコード生成などは、古典的な手法を組み合わせることで推論コストを低く抑え、良い結果を得やすくなります。
全然キラキラしていない、ちょっとカビ臭いぐらいのありふれた自動化こそが、AIコーディングを進めていく上での車輪の片側になるのではないでしょうか。
ELYZAの開発チームでは、AIコーディングを導入し、2025年度において開発しているリポジトリのPRのマージ数を生産量として前年同期比で1.8倍にするという目標を掲げています。
7,8,9月期は1.6倍程度で推移しています。まだまだ小さいチームで人数による影響も無視できなく、道半ばで他にもこれからやっていきたいことがあります。
ELYZAではソフトウェアエンジニアを募集しています。この記事を読んで志を同じく、開発を進めていけるのではと思った方、ぜひカジュアル面談でお話ししましょう。

Discussion