以下の記事は、LangChainを中心とした「Open Deep Research」ワークフローや、その具体的な利用手順について解説します。
OpenAIやGoogleなどの大手企業がリリースしているDeep Research機能を自前で構築・拡張可能にする取り組みとして、LangChainやopen_deep_researchなどのOSSが登場しており、加えてDifyなどのLow-Codeフレームワークでも似たような機能を実装する動きがあります。
本記事では、リポジトリのクローンから環境構築、レポートを生成する流れに至るまで、実践的なガイドをまとめました。
1. Deep Researchとは
LLM(Large Language Model)の強力なテキスト生成を活用し、複数の検索クエリや文献調査、プロンプトエンジニアリングなどを組み合わせて自動的に調査・分析レポートを作成する一連の仕組みを「Deep Research」と呼びます。OpenAIやGoogleが提供する公式機能もありますが、OSSとして開発が進むプロジェクトも存在します。代表例が以下のリポジトリです。
これらを活用すると、LLMベースの検索やレポート生成を自前で拡張し、独自のワークフローを構築できます。加えてDifyのようなサービスでも、類似の仕組みをUI経由で利用できます。
2. LangChain版 Open Deep Researchの仕組み
LangChainリポジトリのopen_deep_researchでは、レポート作成を以下のようなステップで進めています。
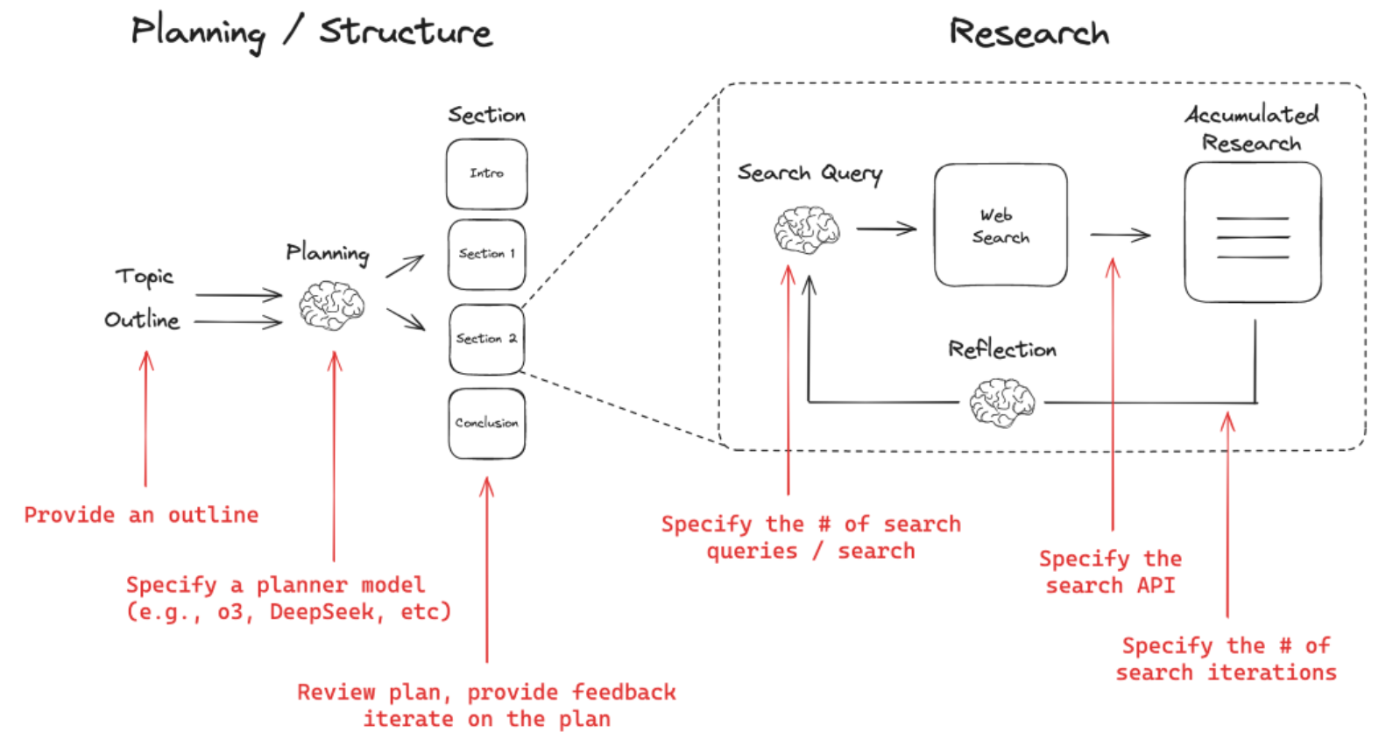
Planning / Structure
Topic と Outline(レポートの大まかな構成やトピック)を入力として受け取り、
Planner Model(たとえば o3 や DeepSeek など)に基づいて、最終的に Introduction、Section 1、Section 2、Conclusion といったセクション案を策定します。
作成されたプラン(セクション構成)をユーザーがレビューし、フィードバックを与えて再検討できます。
Research
決定したセクションの内容を深堀りするために Search Query(検索クエリ)を生成し、指定された Search API(Web Search ツール)に対して複数回の検索を行います。
Reflection(検討・再評価)を経て、蓄積された検索結果(Accumulated Research)をセクション執筆の材料として使います。
「検索クエリの数」「検索を行う回数(# of search iterations)」などを指定して調整することで、どの程度深くリサーチをするか制御できます。
3. セットアップ手順
ここではMac環境を例にopen_deep_researchを著者がローカルで起動した手順を示します。最新の手順は、GithubのREADMEを確認してください。
open_deep_research (LangChain)
- 環境準備
# 仮想環境の作成
python3 -m venv venv
source venv/bin/activate
# パッケージのインストール
pip install open-deep-research
- リポジトリのクローンと設定
git clone https://github.com/langchain-ai/open_deep_research.git
cd open_deep_research
cp .env.example .env # 必要に応じて編集
.env内で使用するモデルや検索ツールなどを指定します。AnthropicやOpenAIなど任意のLLMを組み合わせることが可能です。 今回は、Tabily SearchとOpenAIのo3-miniを利用しました。
- 環境変数の設定
外部APIキーなどは環境変数として設定します。
export TAVILY_API_KEY="XXXX"
export OPENAI_API_KEY="XXXX"
...
.envファイルを用意する場合は以下のように記載し、python-dotenv等で読み込むこともできます。
TAVILY_API_KEY="XXXX"
OPENAI_API_KEY="XXXX"
...
Tavily Search のAPIキー取得方法
Tavily https://tavily.com/ のトップページ右上などにある「Sign up」もしくは「Login」からアカウントを作成し、ログインします。
ユーザーダッシュボード(Account Settings など)へ移動すると、API キーを確認または発行できます。
OpenAI のAPIキー取得方法
OpenAI https://auth.openai.com/create-account のサイトでアカウントを作成(または既存アカウントにログイン)します。
Dashboard内のAPI Keys ページにアクセスすると、Create new secret key ボタンが表示されるので、そこから新規キーを発行します。
- LangGraphサーバーの起動
# uvパッケージマネージャのインストール
curl -LsSf https://astral.sh/uv/install.sh | sh
# 依存関係のインストールとLangGraphサーバー起動
uvx --refresh --from "langgraph-cli[inmem]" --with-editable . --python 3.11 langgraph dev
ブラウザで https://smith.langchain.com/studio/?baseUrl=http://127.0.0.1:2024 を開き、LangGraph Studio UIにアクセスすることで、アシスタントの設定やレポート生成フローを可視化・操作できます。
※LangSmithのAPIが無いというWarning が出たので、.envに追加しています。
LANGSMITH_API_KEY="XXXX"
または、export LANGSMITH_API_KEY="XXXX" を実行
LangSmith の API キー取得方法
LangSmith https://smith.langchain.com/ にアクセスし、アカウントを作成またはログインします。
ログイン後、左メニューのSettingsから、「API Key」の項目があるので、そこから新規キーを発行できます。
4. カスタマイズ可能な要素
-
LLMモデル
- OpenAI(GPT系)、Anthropic、Groq、その他OSSモデルを利用可能。
- How to init any model in one line とfull list of supported integrationsを確認し、そこに記載されたモデル名やプロバイダを init_chat_model() に渡すことで、柔軟にカスタマイズできます。Structured outputsをサポートしている必要があります。
-
検索API
- Tavily、Perplexity、Exa、ArXiv、PubMed、Linkup、DuckDuckGo、Googleなどを設定可能。
- APIキーやカスタムサーチエンジンIDを取得し、環境変数で指定。
-
探索深度・検索回数
- 設定画面や
.envで調整できる。トピックの複雑さに応じて増やすことが可能。
- 設定画面や
-
構成案のプロンプト
- セクション数や内容の粒度を変更可能。余計な章を省いたり、日本語出力に強制したりできる。
左下のManage Assistantで、利用するSearchやLLMをカスタマイズ

以下は検証に使ったサンプルです。
Report Structure : デフォルトのままです
Use this structure to create a report on the user-provided topic:
1. Introduction (no research needed)
- Brief overview of the topic area
2. Main Body Sections:
- Each section should focus on a sub-topic of the user-provided topic
3. Conclusion
- Aim for 1 structural element (either a list of table) that distills the main body sections
- Provide a concise summary of the report
Number Of Queries : 2
Max Search Depth : 2
Planner Provider : openai
Planner Model : o3-mini
Writer Provider : openai
Writer Model : o3-mini
SearchAPI : tavily
search api config : null
Recursion limit : 25
- 今回は、Tavily Search とLLMはOpenAIのo3-miniを利用
5. レポート作成の流れ
-
トピックの入力
Compare LangSmith to LangGraph to LangChain「LangSmithとLangGraphとLangChainを比較して」というように、レポートで扱うトピックを指定します。

-
構成案(Report Plan)の生成
LLMがレポートのセクション案を提案してきます。
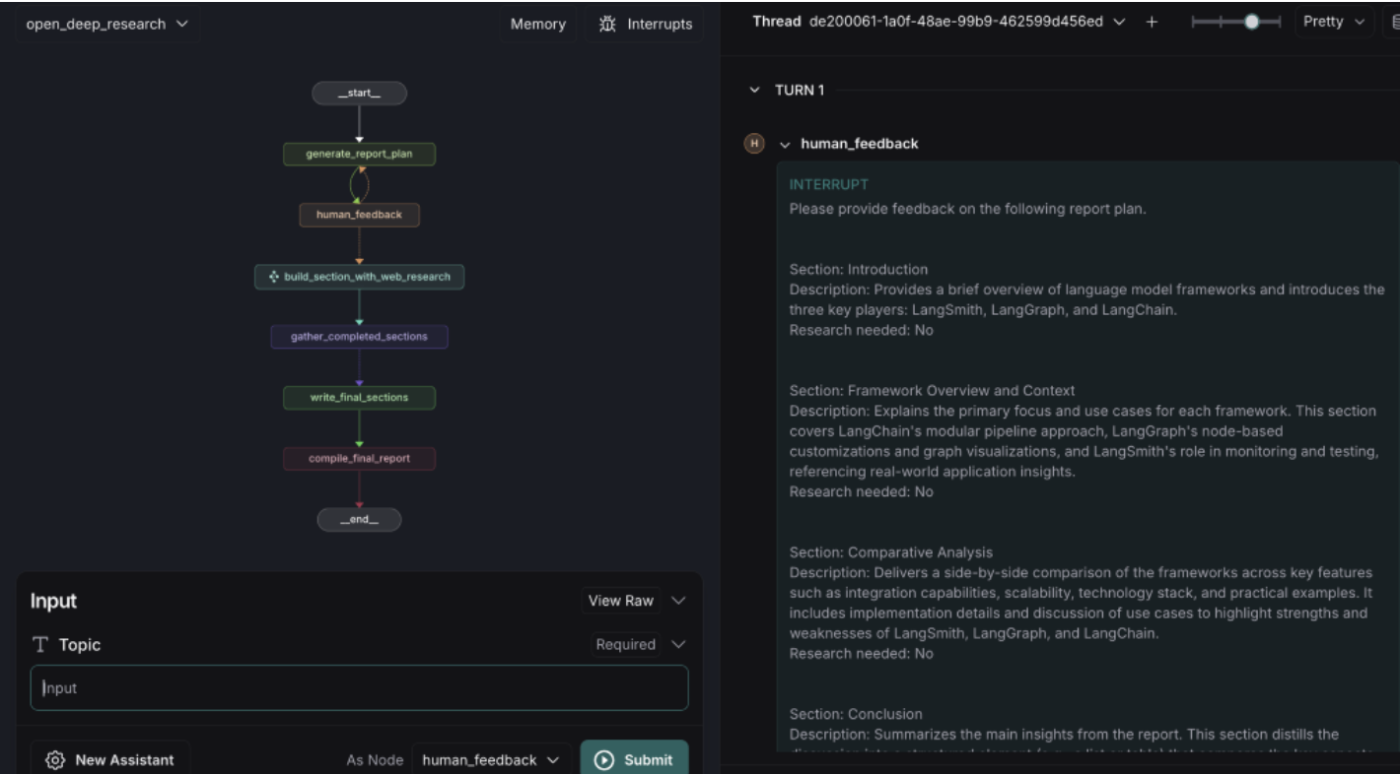
-
Human in the loop でのフィードバック
必要に応じてProvide 1 Section Demand in the world「世界の需要のセクションを入れて」などの指示を与えて再生成。

問題なければ、Trueを返して先に進めます。
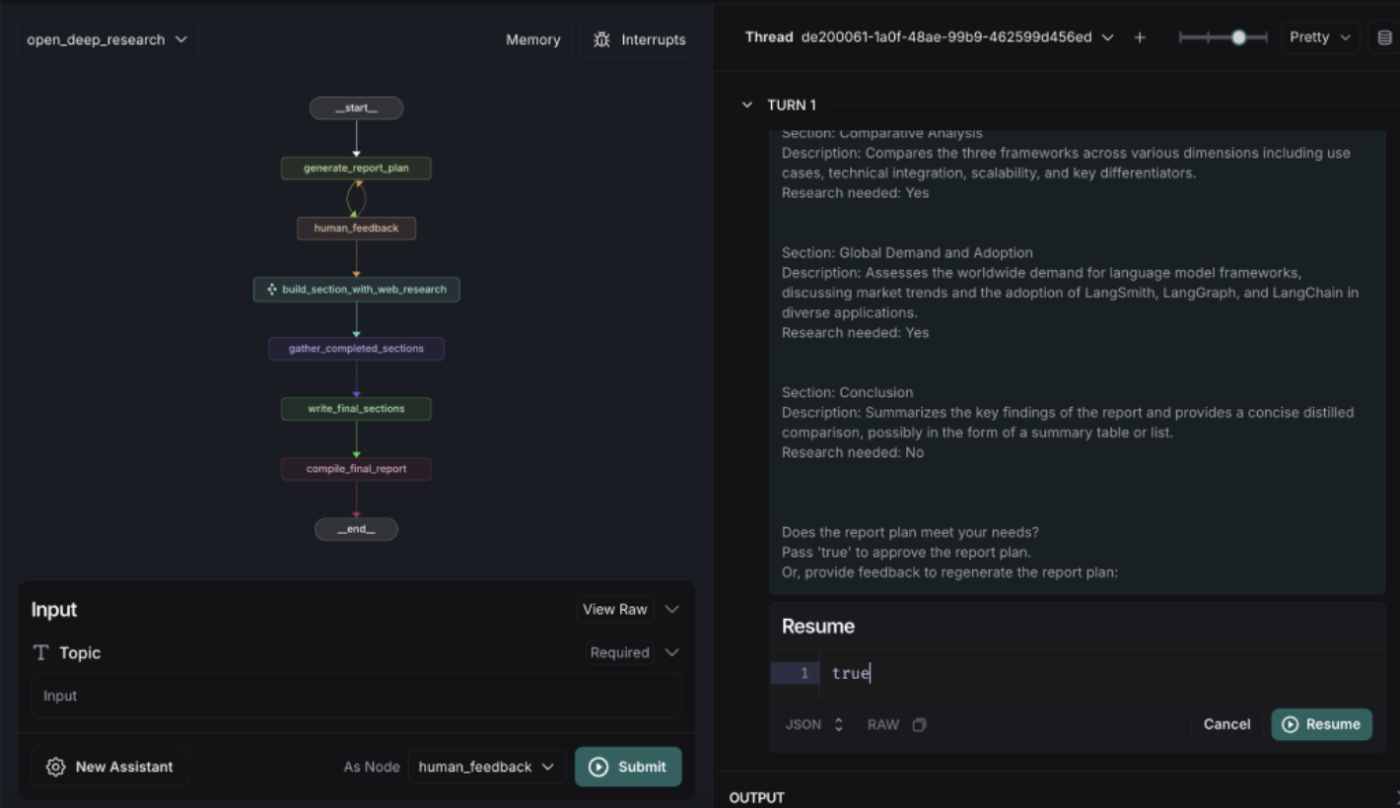
-
検索クエリの生成
各セクションごとに最適化されたクエリ(例: “LangChain’s prompt engineering best practices” など)をLLMが提案し、指定した検索APIに送信します。

-
セクションごとの原稿作成
検索結果や既存のコンテキストを踏まえて、各セクションをLLMが文章化。
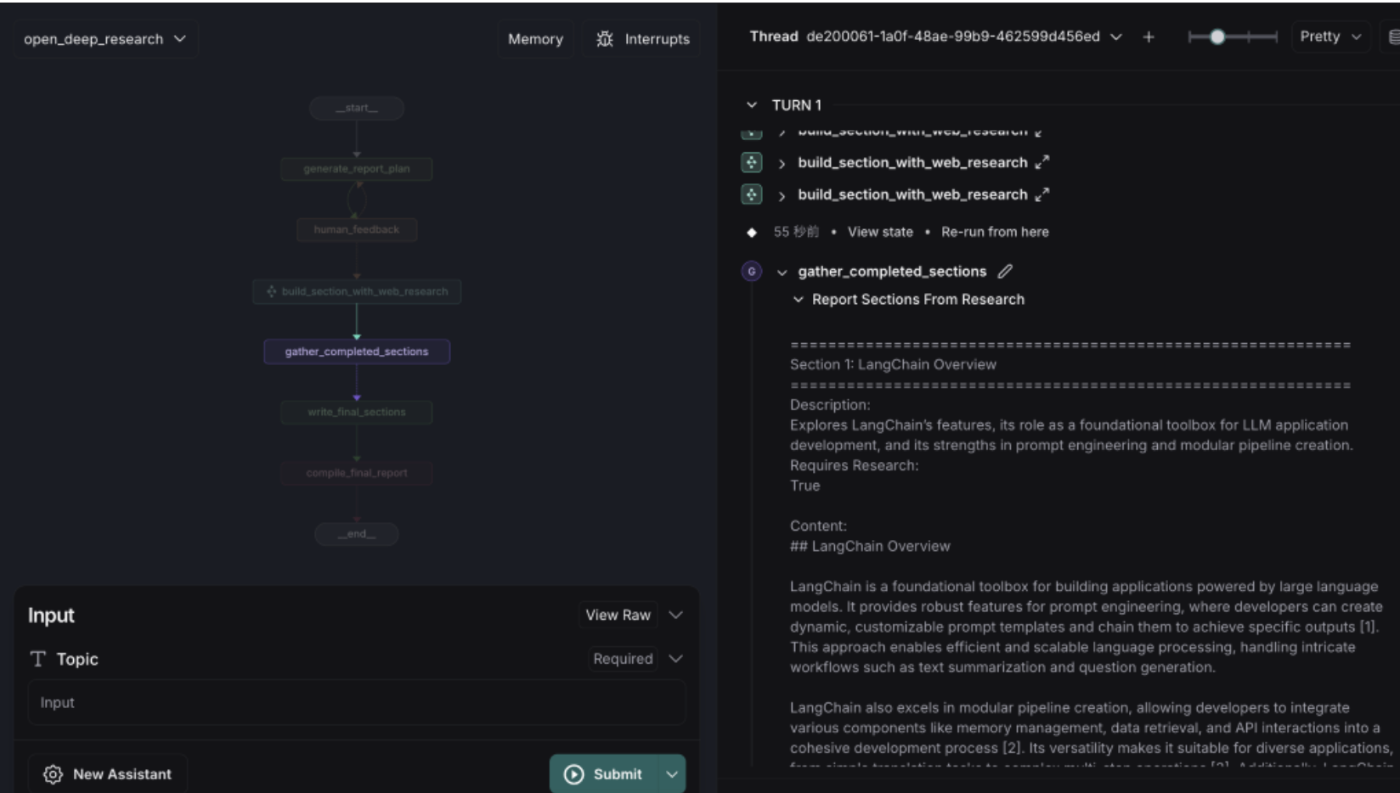
-
結論・導入文の作成
最後にIntroductionとConclusionを生成します。

-
レポートの統合・完成
すべてのセクションを統合して最終版のレポートを出力します。

6. API情報
導入後は以下のURLからAPI Callすることができます。
- 🚀 API: http://127.0.0.1:2024
- 📚 API Docs: http://127.0.0.1:2024/docs

7. まとめ
LangChainを利用したOpen Deep Researchは、複数の検索ツールやLLMモデルを統合し、自動的に段階的なレポート作成を進める上で非常に有用です。今後の展開として社内の情報と組み合わせてレポートを作成したり、精度を向上させるPrompt開発などが行われてくるでしょう。
本記事で紹介した手順やカスタマイズ項目を参考に、ぜひ自分のプロジェクトに合わせたDeep Research環境を構築してみてください。
参考
当記事の内容は以下の参考文書を元にしています。
open_deep_research (LangChain) https://github.com/langchain-ai/open_deep_research
LangChainのOpen Deep Research を動かしてみた(内部の動き) https://zenn.dev/dxclablinkage/articles/05a306793c18e5
Discussion