はじめに
OpenAIが2024年2月15日に動画生成AIモデルのsoraを発表しました。
生成された動画の綺麗さに驚いた方も多いのではないでしょうか。

「Prompt: A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.」
Sora | OpenAI
また、昨今ではGPT4-oやGemini2.5Proなど様々なマルチモーダルモデルが登場し、できることがさらに広がってます。ただ、ここで一つの疑問が浮かび上がってきました。
結局マルチモーダルモデルって結局どうなってるの?
です。そこで、この記事はマルチモーダルモデルの理解を目的とし、その発展の歴史、マルチモーダルモデルのアプリケーション実装例、昨今話題になっている世界モデルの説明を実装例を示しつつ説明します。
マルチモーダルモデルの発展の系譜
マルチモーダルモデルは人間の様な複数の感覚情報を統合して理解・生成するAIを目指す領域でこの10年で大きく発展してきました。
Transformer登場以前
初期のマルチモーダルモデルはCNN(畳み込みニューラルネットワーク)とRNN(再帰型ニューラルネットワーク)で構成されていました。
CNNで画像をEncodeし、RNNでデコードしてキャプションを生成するモデルでした。
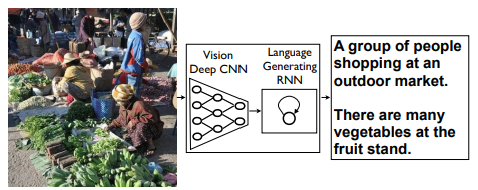
引用:Show and Tell: A Neural Image Caption Generator
Transformer登場以降
2018年頃まではこの方法がとられていましたが、ある一本の論文で状況が一変します。
2017年に発表された「Attention is all you need」の中で紹介されたTransformerモデルの登場です。
Transformerは「自己注意機構(Self-Attention)」を用いて、入力内のすべての単語(トークン)同士の関係性を計算しています。これが、画像にも応用され始め2020年には、“An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale” でVision Transformerが提案されました。これは、画像をパッチ単位に分割し、それを単語(トークン)としてTransformerに入力します。

引用:An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
これにより、単語と画像が一緒にTransformerに入力され始め、VLM(Vision Language Model)が発達し始めます。
代表的なモデル
- ViLBERT
- VisualBERT
モデルの大規模化
Transformerの発展に伴い、スケーリング則が注目されるようになりました。スケーリング則とは、「より大きなモデル、より多くの計算資源、より大量の学習データを投入すれば、モデルの性能は予測可能な形で向上する。」というものです。この考えに則りモデルがどんどん大規模化していき、Web上の大量の情報を入力する流れが強まります。

引用:Learning Transferable Visual Models From Natural Language Supervision
代表的なモデル
- CLIP
- ALIGN
- DALL-E
- Flamingo
LLMとの融合
VLMと並行してLLMが急激に発展したのを受けて、画像をEncodeしたものをLLMに渡してキャプションをつける。といったようにLLMとの融合が発展してきます。

引用:BLIP-2: Bootstrapping Language-Image Pre-training
with Frozen Image Encoders and Large Language Models
代表的なモデル
- BLIP
- PaLM-E
- LLaVA
統合マルチモーダルAIへ
モデル内部で、視覚・聴覚・テキストなどを単一のトークン空間で扱う方向へ発展。
さらに、動画、音声、行動の理解や生成にも拡張され始めています。
これらの根底には「世界モデル」の考え方があるとされています。
世界モデルに関しては後々説明します。
マルチモーダルモデルの構造の説明
ここからは、大規模化したVLMの構造に注目します。今回はCLIPとBLIPについて解説し、サンプルコードを用いて実際に動かしてみます。
CLIP(Contrastive Language-Image Pre-training)
CLIP(Contrastive Language-Image Pre-training)は2021年にOpenAIが発表したモデルで、画像とテキストを同時に学習することで、両者を同じ意味空間にマッピングできます。
はて?何のことやら?
人間の赤ちゃんは視界から受けとる対象物(画像)を指さして親から「それは犬(言語)だよ」と教えてもらいます。同様のことを機械にも教えてあげる必要があります。以下の図のようにDogの画像とDogの文字が近くに来るようにし、Catの画像とdogの文字が遠くなるように学習させます。こういった学習手法のことを対照学習といいます。

引用:CLIPとは?画像とテキストを結ぶAI技術をコード付きで徹底解説!
もう少し詳しく
ざっくりとした説明で結局よくわからない方向けに、もう少し詳しく説明します。論文中に出てくる以下の図を用いて説明します。
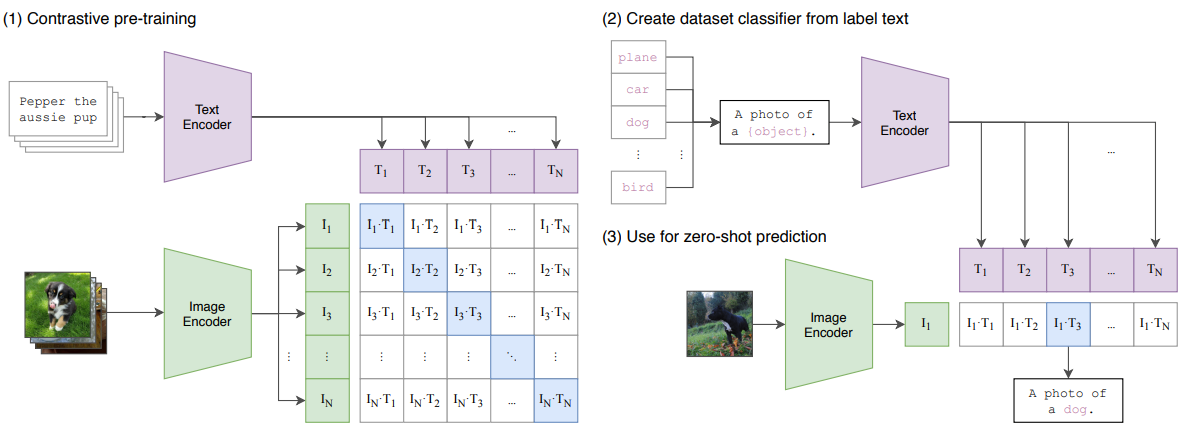
まず、任意の数のデータを準備します。(CLIPの場合は4億枚の画像とテキストのペア)その画像と文字からバッチ数(論文中では32,768枚)を取り出し、それぞれのEncoderに入れて任意の次元(論文中では512)にEncodeします。つまり、図のT1は「Pepper the aussie pup」が512次元にEncodeされた[1,512]のベクトルで、I1はペアとなる画像が512次元にEncodeされた[1,512]のベクトルです。どちらか片方を転置して、内積を取るとそれぞれの類似度が並んだ行列ができます。(図中のI1・T1からIN・TNまで)
これの対角成分が大きくなり、非対角成分が小さくなるように学習を進めれば、文字と画像のペア同士が似ているとされて、ペアではないものが似ていないと判断されます。(非常に難しいですね。。)
ゼロショット画像分類
画像も文字もEncodeされている段階で、画像や文字の特徴をつかんでくるので大量のデータで学習をさせると未知なデータに対しても画像の分類が出来ます。例えば、トイプードルとミニチュアダックスフンドを「a dog」と紐づけているとゴールデンレトリバーに対しても「a dog」と紐づくといった様子です。 従来の画像分類はラベルを付けてモデルを学習させないといけなかったのに、大量のデータで事前学習させることで言葉そのものがラベルとして機能するようになりました。(まさに画像認識分野での革命ですね)
Pythonで実装
- 入力:世界が誇るスーパースター大谷翔平選手の画像
- ライブラリ:open_clip
- 分類候補:ムーキー・ベッツ、大谷翔平、フレディー・フリーマン

!pip install -q open_clip_torch
import open_clip
import torch
from PIL import Image
import io
import requests
model_name = "ViT-B-32-quickgelu"
model , _ , preprocess = open_clip.create_model_and_transforms(model_name, pretrained='laion400m_e32')
tokenizer = open_clip.get_tokenizer(model_name)
query_image = Image.open(io.BytesIO(requests.get("https://ogden_images.s3.amazonaws.com/www.altoonamirror.com/images/2025/06/17233352/Ohtani-1100x733.jpg", verify=False).content))
word_list = ["Markus Lynn Betts","shohei Ohtani" , "Frederick Charles Freeman"]
text = tokenizer(word_list)
with torch.no_grad(), torch.amp.autocast(device_type='cpu'):
image_features = model.encode_image(preprocess(query_image).unsqueeze(0))
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
torch.set_printoptions(sci_mode=False)
print("Label probs:", word_list[text_probs.argmax().item()])
出力結果:Label probs: shohei Ohtani
となり、ちゃんと大谷翔平選手が認識されていました。素晴らしいですね。
BLIP
BLIP-2(Bootstrapping Language-Image Pre-training
with Frozen Image Encoders and Large Language Models)は2023年にSalesforceが発表したモデルで、強力なLLMの能力を凍結しつつ画像モデルとLLMの橋渡しをするQuerying Transformer(Q-Former)を使用することで画像のキャプション生成や視覚対話を可能にしました。
詳しくは以下の記事が参考になるのですが、ここではQ-Formerについて説明します。
Q-Former
Q-Formerのモチベーションは非常にシンプルで、CLIPが画像と文字を同じ空間に埋め込もうというのに対して、Q-formerはVisionモデルはVisionモデルで大きく発展させて、LLMはLLMで大きく発展させる。文字と画像という異なる属性のものを橋渡しするものを学習させれば、最小のコストで精度の高い[画像ー文字]のマルチモーダルモデルモデルが出来るのではないか?つまり、CLIPが文字と画像を一緒に学習させるのに対してBLIPは文字は文字で、画像は画像で学習させたものを後付けでつなげばいいよね。というものです。
Q-Formerの事前学習
事前学習は以下のような構造です。

Q-Formerの目的は、Learned Query(学習可能なパラメータ)を最適化することです。Learned Queryは、様々な画像に対してテキストと対応する情報をうまく抽出・要約するための「情報の入れ物」のようなパラメータです。
Q-Formerは2つのTransformer構造から成ります。右側はテキストを入力し、左側は画像エンコーダの出力とLearned Queryを入力します。
Self Attention:
左側(画像側): Learned Query(例: 32個のベクトル)同士がbidirectional(双方向)に情報を交換します。
右側(テキスト側): Input Textがuni-modal(Causalマスク、未来を見ない)で情報を処理します。
Cross Attention(左側のみ):
Self Attentionを通ったLearned QueryがQuery (Q) となり、Cross Attentionによって画像エンコーダの出力(Key/Value)を参照します。これにより、Learned Queryに画像情報が書き込まれます。
情報制御 (Masking):
multimodal causalマスクにより、テキスト側は画像側(クエリ)を参照できますが、画像側はテキスト側を参照できません(カンニング防止)。
誤差関数:
この構造を使い、Image-Text Matching(ITM)、Image-Text Contrastive Learning(ITC)、Image-Grounded Text Generation(ITG)という3つのタスクを同時に解きます。
これらの誤差に基づき、Q-Former全体(Learned Queryを含む)とテキストTransformerのパラメータを更新します。これによって最終的に、様々な画像と文字の対応関係を学習した「Q-Former(とLearned Query)」が手に入ります。
これによって最終的に、様々な画像と文字に対して対応関係を学習したLearned queryが手に入ります。
学習済みのQ-formerによる画像キャプション生成
学習済みのQ-Formerが手に入ると、推論時には入力画像を使います。
- 画像を入力し、画像エンコーダで特徴量を得ます。
- Q-Formerは、学習済みのLearned Query(パラメータ)を初期入力として使い、Cross-Attentionで画像の情報を参照します。
- Q-Formerは、画像情報が反映された最終出力ベクトルを生成します。
- この最終出力ベクトルにフィードフォワード層を挟んで次元を調整し、LLMのプロンプトとして入力します。
これにより、LLMは画像情報(Q_{final}

Pythonによる実装
入力:先ほどと同様に大谷選手の画像
!pip install transformers
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-large")
from PIL import Image
import requests
def generate_caption(image_url):
raw_image = Image.open(requests.get(image_url, stream=True, verify=False).raw).convert('RGB')
w,h = raw_image.size
display(raw_image.resize((w//15,h//15)))
text = "a photography of"
inputs = processor(raw_image, text, return_tensors="pt")
out = model.generate(**inputs, min_length=20, max_length=50)
generated_caption = processor.decode(out[0], skip_special_tokens=True)
print(generated_caption)
generate_caption('https://ogden_images.s3.amazonaws.com/www.altoonamirror.com/images/2025/06/17233352/Ohtani-1100x733.jpg')
出力結果:a photography of a baseball player pitching a ball on a field with a crowd watching him from the stands
となり、正しくキャプションをつけることが出来ていました。
さいごに
マルチモーダルってどういう構造なのかな?という軽い気持ちで調べていたのですが、思っていたよりヘビーな内容でした。。。
続編では、マルチモーダルモデルを用いたマルチモーダルRAGの実装、発展系の世界モデルの話をしたいと思います。
Discussion