Vue.js+textlint+機械学習でRPGツクールMZ用文章校正プラグインを開発して得られた知見
成果物
これを作るときにいろいろ問題にぶつかったので得られた知見をまとめます。
開発期間は3か月です。
目標
RPGツクールMZで動作する実用レベルの文章校正プラグイン
実現できた機能
- それなりに誤りを検出できる
- ゲーム内のどのデータを校正するか選べる
- 校正の進捗がわかる
- 校正中はいつでも実行を停止できる
- プラグインだけで簡易的にチェックするかサーバーを使って精密にチェックするか選べる
- 配布するファイルは1ファイルだけで他のプラグインと同じように使用できる
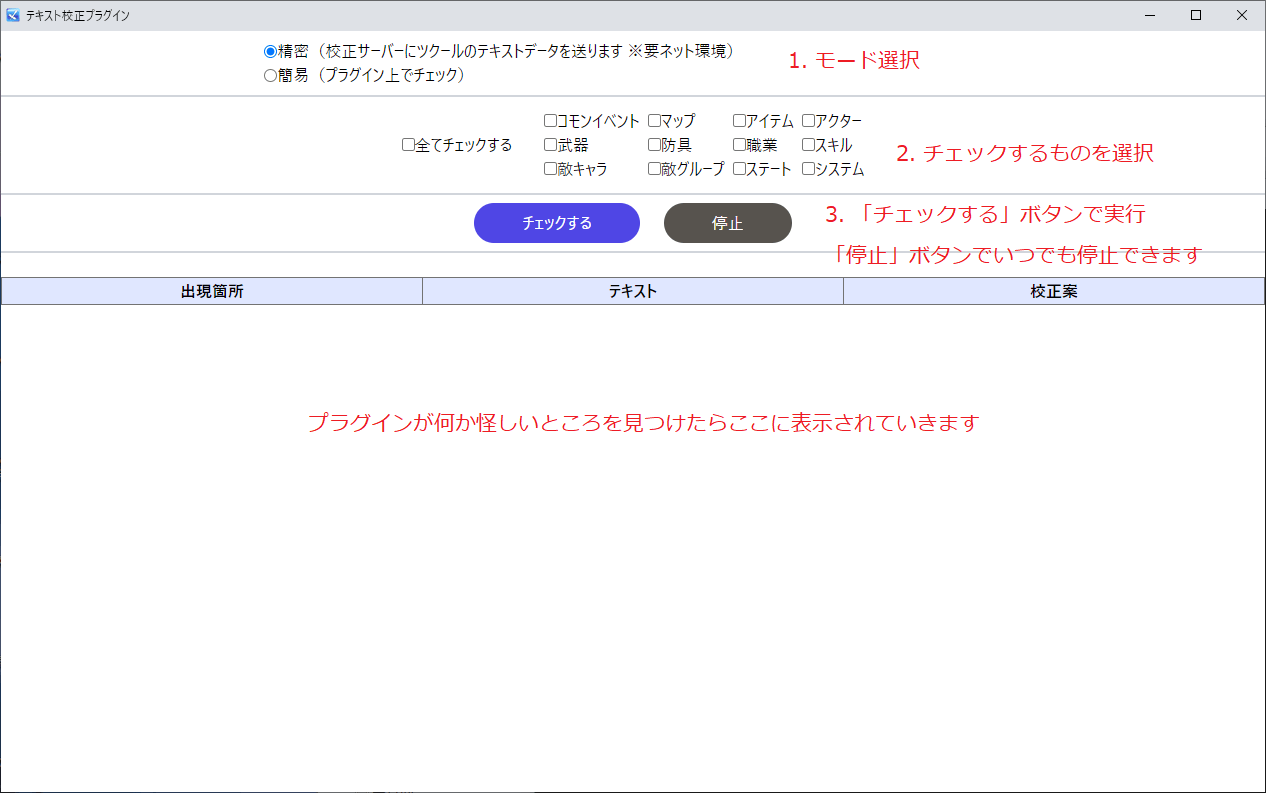
画面
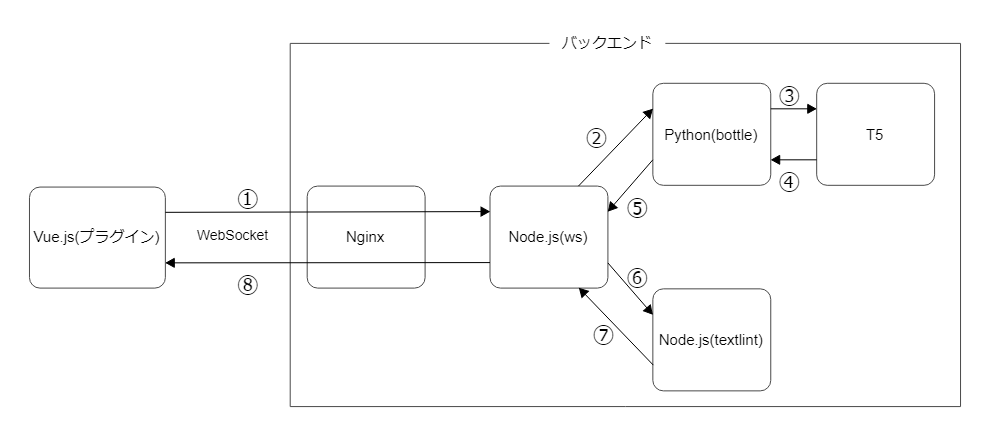
構成図
主な使用技術と選定理由
- Vue.js
- 慣れている。使いやすいようにいくらかリッチなUIにしたかったため。
-
textlint
- ルールベースの文章校正ができるOSS。必須。
-
T5 sonoisa/t5-base-japanese
- ルールベースのアルゴリズムでは検出に限界があり、漢字の誤字や送り仮名の誤りなどのカバーが困難なので検出精度のためにやむを得ず機械学習モデルも利用しました。文章校正ができる自然言語処理のモデルは他にもBERT等いろいろありますが、入力と出力がともにテキストになる特徴を持っていて非常にわかりやすく、校正にも適しているように思えたのでT5を採用。
T5を文章校正用にファインチューニング
公開されている事前学習済みモデルを使ってGoogle Colab上でファインチューニングしました。日本語Wikipedia入力誤りデータセットをデータセットに使用しています。
日本語データセットをT5が読めるように成形し、日本語T5を使って文章生成 〜ヒロアカのキャラ名予測〜のコードをほぼそのまま使用して学習させました。
正解の文,間違いの文
...
...
当たった問題
データセットが大きすぎてColabに乗らないし学習が終わらない
70万セットあるのでこれをそのまま使おうとするとメモリ不足で学習できません。最上級プランであるPro+でもなかなか50GB以上のメモリを引き当てられず無理でした。
機械学習ではバッチサイズを小さくすればその分使用メモリが少なくなりますが、Colabに乗せるにはバッチサイズ1など極端に少なくする必要があり、そうすると70万セットを1エポック回すのに400時間かかると出たのでやはり無理です。
次にGoogleが提供しているVertexAIを利用し、ハイスペックなCPUと巨大なメモリを持つ仮想環境でGPUを4つ同時に使ったところ一応現実的な時間(確か1エポック20時間ぐらい)で学習できるようになりました。
しかしなぜか不安定でインスタンスが突然落ちたり二度と入れなくなったり学習結果が飛んだりして使い勝手が悪かったです。
これは1時間数百円の高価な環境のためあまり時間をかけて試していると破産すると思い断念しました。
最終的にデータセットを1万セットほどに縮小し、メモリ12GBのColabで学習しました。
RPGツクールMZのプラグインをVue.jsで作る
実現の可能性はあるのか
まず、ツクールMZのゲーム製作画面自体に変更を加える方法は用意されていないようでした。よってプラグイン経由で動作するソフトウェアを作らなければなりません。これが可能なのかどうかを調査するため、MZやMVのいろいろなプラグインのうち開発時に使用するものを見て回りました。
【プラグイン】デバッグ支援
運よく同じことをやっていそうなプラグインは見つかりました。これによるとhtmlファイルを別途作ってプラグインからロードしているようです。つまりプラグイン経由で動作するものは作れそうです。
NW.jsのAPIを使ってRPGツクールMVの開発環境を改善する
この記事によってプラグインからNW.jsの機能もNode.jsの機能も問題なく使えることがわかりました。
webpack + babelを使ってRPGツクールMVのプラグインを書いてみた その1
Webpackを使ってのバンドルもできるようです。
得られた情報をまとめると、RPGツクールMZのプラグインをVue.jsで作ることはできそうです。
当たった問題
Node.jsのコア機能がブラウザで動作しない
そもそもNode.jsのコードはローカル環境で動作するもので、fsモジュールなどのコア機能をブラウザで動作させるようにはなっていません。Webpackもローカルで動かすのかブラウザで動かすのかターゲットを決めてからビルドするのが普通です。しかし、作りたいのはhtmlをロードしつつローカルのブラウザで動くいわばハイブリットなアプリです。
これはブラウザで動作するVue.jsの部分とhtmlをロードするプラグインの部分を分離することで解決しました。Vue.jsで作ったアプリ本体を文字列として扱い、プラグイン部分に埋め込んでしまえば可能です。こうするとVue.jsからコア機能を使いたいときはNW.js経由で利用でき、プラグイン部分はNode.jsの書き方でそのまま利用できます。
import * as fs from 'fs';
import * as path from 'path';
import prebundlejs from './assets/DRS_TextProofread.prebundleapp';
let app_html = `
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>テキスト校正プラグイン</title>
</head>
<body>
<div id="app"></div>
<script>${prebundlejs}</script>
</body>
</html>
`
const html_filename = "DRS_TextProofread_MainWindow.html";
fs.writeFileSync(path.join(process.cwd(), html_filename), app_html);
nw.Window.open(html_filename, {}, function(win) {
win.width = 1280;
win.height = 800;
win.on('close', function () {
try {
fs.unlinkSync(path.join(process.cwd(), html_filename));
} catch (e) {
console.log(e);
} finally {
this.close(true);
}
});
})
DRS_TextProofread.prebundleappが事前にビルドしたVue.jsのアプリで、htmlにそのまま埋め込めます。これをもう一度ビルドします。
textlintのオリジナルルールを作る
textlintには様々なルールが公開されていて、用途に合わせてプラガブルに使えます。ただ、多くのルールはより良い文章にすることを主眼としていそうです。例えば文章の形式やですます調の不統一、日本語として望ましくない表現なども誤りにしてしまいます。
今回校正するのはRPGツクールのゲームという創作作品のテキストであり、何も固い文章にしてほしいわけではありません。クリエイターの表現を邪魔しないで明らかな間違いだけ検出したいです。そのためオリジナルのルールを作ることにしました。
これ一つに集約すれば他のルールは使わずに済みます。
当たった問題
このシステムの環境ではtextlintが動作しない
textlintをNode.jsで動作させることは可能です。
簡単なtextlintサーバーを作る
しかし今作っているものはアプリ部分とプラグイン部分を分離しており、ブラウザで動くアプリ部分でtextlintを動作させることはできません。この問題については先駆者が何人かいるようですが、見るからに面倒です。
webpack で Chrome 拡張を作って得られた知見
幸いにもtextlintの開発者であるazu氏は需要と問題を察知されており、解決法を用意してくださっていました。
サーバにデータを送る必要がない文章の校正ツール、スペルチェッカーを作っている
textlint 12リリース、ブラウザで動くtextlint editorをベータリリース
これによるとtextlintをブラウザで動かしたい場合はscript-compilerで生成されたWebWorkerが使えるということです。
textlint-editorが作るWebWorkerはmorpheme-matchの辞書ファイルをバンドルできない
これはオリジナルルールを作ったもう一つの理由でもあります。
せっかくブラウザで動かせるのに、一部のルールではWebWorkerになった後も外部に辞書ファイルが必要でした。これではプラグイン配布時に面倒です。
issuesを立てて聞いてみましたが現時点ではできないので読み込むように修正する必要があるとのことでした。
[script-compiler] Can morpheme-match dictionaries be bundled with worker?
issuesを立ててしまった手前やらねばならぬと思ってforkしましたが、開発環境を整えようと四苦八苦した挙句に何もわからなくなったので断念しました。
script-compilerがバンドルできるルールであれば良いのです。冒頭の通りオリジナルルールで解決しました。
WebWorkerをVue.jsから読み込む
WebWorkerが生成されるのでこのファイルを何らかの方法で読み込む必要があります。
外部ファイルとするのは配布時に問題になるのでやはりNGです。
4パターンのWebWorker生成方法とインラインワーカーの技法
これによるとBlobとして扱って生成できるようです。Vue.jsをhtmlに埋め込んだ時と同じような方法で無理矢理Blobであるということにします。
import textlintWorker from "./assets/textlint-worker.prebundleapp";
...
const url = URL.createObjectURL(
new Blob([textlintWorker], { type: "text/javascript" })
);
サーバー側の構築
機械学習を採用してしまったのでサーバーを用意して通信を行うのは必須になっています。
T5が1回の推論で受け付けられる文字数や精度を考えると、どうしてもテキストデータは小分けにせざるを得ません。さらに全体の進捗状況をモニタリングしたいです。
すると一旦全部受け取ってからサーバー側で小分けにするより、送信する前の時点で小分けにするほうが実装が簡単そうでした。
小分けに送信するとなるとPOSTのオーバーヘッドが少々気になるので、有効かどうか定かではありませんがWebSocketを採用しました。
このサーバーの主な構成要素はPythonとNode.jsとNginxです。OSは慣れているAlmaLinuxにしています。
- Python
- 余計なものは一切不要なので最もシンプルと思われるbottleでT5を動作させるバックエンドを作りました。
- Node.js
- wsでNginxから通されるWebSocketの送受信部分を作り、受け取ったテキストデータをtextlintとPythonに連携するロジックを担当させました。
- Nginx
- ただのリバースプロキシで後ろのNode.jsにリクエストを通すだけです。httpのリクエストをhttpsにリダイレクトさせるぐらいはしています。
当たった問題
T5で推論するの無理
T5のモデルは推論するときもメモリを大量に使う上に1回の推論があまりにも遅いです。とてもCPUでは動かせません。CPUで動かせないということは、その辺の安いVPSなどにはデプロイできないということです。
しかしだからといってGPUが使える環境は高すぎて長い間借りていられません。
すると恐ろしいことに自宅サーバーが選択肢に入ってきます。私の契約しているプロバイダーはIPv4とIPv6の接続を別々に利用できるので、ハブとルーターを買えば普段ネットに繋いでいるIPv6のネットワークと外部公開用のIPv4のネットワークを分離できそうです。
IPv6とIPv4を共存させ同時接続する方法
T5のモデルがギリギリ乗る2GBのメモリ容量とそれなりの性能があって中古価格も手ごろなグラボGeForce GTX750tiを軸に、メルカリとヤフオクで安い部品を揃えてPCを一台組みました。電気代も計算上は月1000円以下になるはずです。
さらにCloudflareを使ってIPアドレスとドメインを紐づけます。昔でいうDDNSは、今ではCloudflareで十分できるようです。
課題
機械学習モデルの精度がよくない
学習したデータセットが少なすぎるのか、Wikipediaを学習したモデルを創作に適用するのは限界があるのか、
理由はわかりませんが実用レベルを目指したシステムとしては満足のいく精度ではありません。
使える文章を提案してくれるのは3割から4割ぐらいで、別に検出してほしくない箇所を検出する場合が多いです。
衍字には結構強いと感じますが、表現として許容すべきら抜き言葉やい抜き言葉をも検出してしまうので、用途を考えるとそこまでの強みにはなっていません。
とりあえずチェックしてみて、本当に直す必要がある箇所だけを直す使い方をするしかないです。
むしろ簡易モードを使ってtextlintのみでチェックしたほうが実用性があるかもしれません。
モデルが遅すぎる
textlintの動作速度はさすがにルールベースなのでなかなか早いです。しかしT5の推論速度がGPUをもってしてもこの程度なのは不本意です。コストを抑えるためのGTX750tiなので仕方ない面もあるかもしれませんが、遅いと単純に不便なので困ります。
コードとロジックがひどすぎる
リファクタリングはもとよりいろいろな部分に改良が必要。
所感
案外苦労しました。
実は当初日本語の校正なんてルールベースで事足りると思ってなめてました。調査するうちにtextlintで対応できない文があると知り、精度のためには機械学習が必要という結論になってかなり落胆しました。
ただ動作するものはできたし、全く使い物にならないわけでもないので相応に満足です。
Discussion