【入門】フローマッチングのエッセンス
はじめに
2025年、生成AIの世界は新たな変革期を迎えています。拡散モデルが切り拓いた高品質なデータ生成の地平は、さらに効率的で柔軟な「フローマッチング(Flow Matching, FM)」というパラダイムへと進化を遂げようとしています。Meta AIが発表した「Flow Matching Guide and Code」(arXiv:2412.06264v1) は、このフローマッチングの数学的基盤から最新の拡張、さらにはPyTorchによる実装までを網羅した包括的なガイドであり、本記事はこのガイドを元に、フローマッチングのエッセンスを可能な限りわかりやすく紐解いていくことを目指します。
前回の記事「【入門】拡散モデルのエッセンス」では、ノイズからデータを徐々に復元する拡散モデルの本質に迫りました。フローマッチングは、その拡散モデルの考え方をさらに一般化し、より直接的かつ効率的にデータ間の「流れ」を学習する枠組みを提供します。画像、動画、音声、テキスト、さらにはタンパク質構造のような生物学的データまで、多様なドメインで最先端の性能を達成しており、まさに次世代の生成AIを駆動するコア技術と言えるでしょう。
本記事は、拡散モデルの基礎を理解された方が、次のステップとしてフローマッチングの世界へスムーズに移行できるよう構成されています。数式の厳密な導出や詳細な理論展開については、ぜひ上記のMeta AIのガイド(原著)や関連論文をご参照ください。
この記事が、皆様にとってフローマッチングというフロンティアを切り拓くための礎となり、そして生成AIのさらなる可能性を探求する旅の一助となることを願っています。
本記事の構成
- 第1章 フローマッチングへようこそ:新時代の生成モデリング
- 第2章 フローの数理:フローマッチングの基礎を固める
- 第3章 フローマッチングの核心:理論とアルゴリズム
- 第4章 フローマッチングの拡張(1):多様体上の流れ
- 第5章 フローマッチングの拡張(2):離散空間への挑戦
- 第6章 フローマッチングの一般化:ジェネレータマッチング
- 第7章 フローマッチングと拡散モデル:共通点と相違点
さあ、フローマッチングが織りなす連続的な変化の魔法を、数式という羅針盤を手に解き明かしていきましょう。
第1章 フローマッチングへようこそ:新時代の生成モデリング
この章のゴール:
この章では、フローマッチング(FM)の基本的なアイデアとその魅力を紹介します。拡散モデルとの関係性を概観しつつ、FMがなぜ注目されているのか、どのような利点があるのかを探ります。そして、FMの核となる「確率パス」と「速度場」の概念を、簡単な例を通して直感的に理解することを目指します。この章を読むことで、FMがどのようにしてデータ間の滑らかな変換を実現しようとしているのか、その全体像を掴むことができるでしょう。
(原著の §2 "Quick tour and key concepts" に相当する内容です。)
1.1 フローマッチングとは何か?:流れに乗ってデータを変換する
フローマッチング(Flow Matching, FM)とは、一言で言えば、ある確率分布(例えば、単純なノイズ分布)から別の確率分布(例えば、複雑な画像データの分布)へとサンプルを連続的に変換する「流れ(フロー)」を学習する生成モデリングのフレームワークです。
この「流れ」は、時間とともに変化するベクトル場(速度場)によって定義される常微分方程式(Ordinary Differential Equation, ODE)の解として数学的に記述されます。FMの目標は、このODEを駆動する速度場をニューラルネットワークでパラメータ化し、訓練データを用いて学習することです。
一度この速度場が学習されれば、既知の分布(ソース分布

図1.1:フローマッチングの基本概念。ソース分布
1.1.1 拡散モデルとの関係性
拡散モデル(特にDDPMやSBM)も、ノイズからデータを生成するという点でFMと似ています。実際、第7章で詳しく見ますが、拡散モデルの多くはFMの特殊なケースとして捉えることができます。
- 拡散モデル: 通常、固定されたノイズ付加プロセス(拡散過程)とその逆のノイズ除去プロセス(逆拡散過程)を考えます。逆拡散過程は、しばしば確率微分方程式(SDE)または対応するODE(確率フローODE)で記述され、そのスコア関数またはノイズ予測モデルを学習します。
-
フローマッチング: より一般的に、ソース分布
p_0 p_1 p_t t \in [0,1] p_0 p_1 u_t
FMは、拡散モデルで暗黙的に仮定されていた確率パスや速度場をより明示的に扱い、その設計自由度を高めることで、学習の効率性や生成品質の向上を目指します。特に、シミュレーションフリーな学習が可能である点が大きな利点です。
1.1.2 なぜフローマッチングなのか?その利点
FMが注目される主な理由は以下の通りです。
- シミュレーションフリーな学習: 多くのFMの手法では、学習時にODEを解く必要がありません。これは、特定の条件下でターゲットとなる速度場を直接回帰問題として学習できるためです(詳細は第3章)。これにより、学習が高速かつ安定します。拡散モデルのスコアマッチングもシミュレーションフリーでしたが、FMはより広範な確率パスの選択肢を提供します。
-
設計の柔軟性: ソース分布
p_0 p_1 p_t - 強力な性能: 画像、動画、音声、3D形状、分子構造など、様々なデータモダリティで最先端の生成品質を達成しています。
- 理論的明快さ: 連続正規化フロー(Continuous Normalizing Flows, CNF)のアイデアを基盤としつつ、その学習の難点を克服する形で発展しており、数学的な見通しが良いとされています。
1.2 クイックツアー:フローマッチングの2つのステップ
原著では、フローマッチングのレシピを2つの主要なステップで説明しています(原著 §2, Fig. 2)。
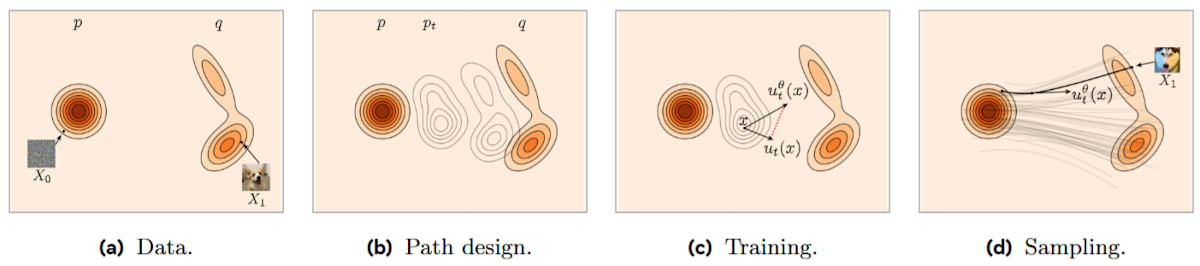
図1.2:フローマッチングの設計図。(a) 既知のソース分布
-
ステップ1:確率パスの設計
- 既知のソース分布
p_0 \mathcal{N}(x|0, I) p_1=q - これら2つの分布を滑らかに補間する時間連続な「確率パス」
p_t(x) t=0 p_0(x) t=1 p_1(x) - 原著の例では、「条件付き最適輸送パス」または「線形パス」と呼ばれるものが紹介されています。これは、ソースサンプル
X_0 \sim p_0 X_1 \sim p_1 X_t = (1-t)X_0 + tX_1 X_t \sim p_t t p_t(x) p_{t|1}(x|x_1) x_1 q(x_1)
具体的には、p_{t|1}(x|x_1) = \mathcal{N}(x|tx_1, (1-t)^2 I) t=0 \mathcal{N}(x|0, I) p_0 t=1 x_1 \delta_{x_1}(x)
- 既知のソース分布
-
ステップ2:速度場の学習
-
確率パス
p_t(x) u_t(x) \frac{dX_t}{dt} = u_t(X_t) -
この未知の真の速度場
u_t(x) u_t^\theta(x) -
学習は、回帰問題として定式化されます。つまり、ある損失関数(通常は二乗誤差)を用いて、
u_t^\theta(X_t) u_t(X_t) \theta \mathcal{L}_{FM}(\theta) = \mathbb{E}_{t, X_t \sim p_t} [\| u_t^\theta(X_t) - u_t(X_t) \|^2] \tag{\text{原著 Eq. 2.4}} -
しかし、周辺分布
p_t u_t(X_t) -
ここで巧妙なのは、「条件付きフローマッチング(Conditional Flow Matching, CFM)」という考え方です。学習データからランダムにターゲットサンプル
X_1=x_1 x_1 p_{t|1}(x|x_1) u_t(x|x_1) -
p_{t|1}(x|x_1) = \mathcal{N}(x|tx_1, (1-t)^2 I) u_t(x|x_1) = \frac{x_1 - x}{1-t} -
CFM損失は、この既知の条件付き速度場をターゲットとして回帰します。
\mathcal{L}_{CFM}(\theta) = \mathbb{E}_{t, X_0 \sim p_0, X_1 \sim q} [\| u_t^\theta(X_t) - u_t(X_t|X_1) \|^2] ここで、
X_t = (1-t)X_0 + tX_1
最も単純な線形パスX_t = (1-t)X_0 + tX_1 X_1 X_t = (1-t)X_0 + t x_1 u_t(X_t|x_1) x_1 - X_0 \mathcal{L}_{OT,Gauss CFM}(\theta) = \mathbb{E}_{t \sim U[0,1], X_0 \sim \mathcal{N}(0,I), X_1 \sim q} [\| u_t^\theta((1-t)X_0+tX_1) - (X_1 - X_0) \|^2] となります。
-
驚くべきことに、このCFM損失で学習しても、その勾配は元のFM損失の勾配と一致し(原著 §4.5 Theorem 4)、結果としてモデル
u_t^\theta(x) u_t(x)
-
1.2.1 サンプリング
学習後、新しいサンプルを生成するには、
- ソース分布
p_0 X_0 - 学習された速度場
u_t^\theta(X_t) \frac{dX_t}{dt} = u_t^\theta(X_t) t=0 t=1 - 最終的に得られた
X_1 q
この2ステップのアプローチ(パス設計と速度場回帰)が、フローマッチングの基本的な枠組みです。
1.3 なぜ「流れ」を学習するのか?その直感
フローマッチングは、データ空間内での確率分布の「地形」を変形させていく様子を捉えようとします。
ソース分布(例えば、一様に広がったノイズの「平原」)から、ターゲット分布(例えば、特定の形状を持つデータの「山脈」)へと、確率の塊を滑らかに「輸送」するイメージです。
-
確率パス
p_t(x) t t=0 t=1 -
速度場
u_t(x) x p_t(x)
フローマッチングが学習するのは、この「流れのルール」そのものです。ルールさえ学習してしまえば、どんな初期状態(ソースサンプル)からでも、ルールに従って流れに乗せることで、最終的な目的地(ターゲットサンプル)に到達できる、というわけです。
拡散モデルでは、ノイズを徐々に加えていく固定の「拡散流」と、それを逆向きに辿る学習可能な「生成流」を考えていました。フローマッチングは、この「流れ」の概念をより一般化し、ソースとターゲットを直接結びつける流れを設計・学習することで、より効率的で表現力の高い生成モデリングを目指しています。
1.4 この章のまとめ:フローマッチングへの期待
この章では、フローマッチングの基本的な考え方と、その魅力について紹介しました。
- フローマッチングは、ソース分布からターゲット分布への連続的な変換(フロー)を学習するフレームワークです。
- このフローはODEによって記述され、そのODEを駆動する速度場をニューラルネットワークで学習します。
- 拡散モデルの一般化と見なすことができ、シミュレーションフリーな学習や設計の柔軟性といった利点があります。
- 基本的なレシピは、(1) 確率パスの設計、(2) 速度場の回帰学習、の2ステップです。
- 条件付きフローマッチング損失を用いることで、ターゲットとなる速度場を容易に得られ、効率的な学習が可能です。
フローマッチングは、確率分布間の「最適な輸送経路」を見つけ出す最適輸送の理論とも深く関連しており、その数学的な美しさと実用的なパワフルさから、今後の生成AI分野でのさらなる発展が期待されています。
次章では、この「フロー」や「速度場」といった概念をより厳密に理解するために必要な数学的基礎(ODE、プッシュフォワード、連続の方程式など)を整理します。これらの道具立てを身につけることで、フローマッチングの核心的なメカニズムへと踏み込んでいく準備が整います。
ここまでの議論のポイント:
- フローマッチング(FM)は、ソース分布からターゲット分布への連続的な「流れ」を学習する。
- 流れはODEで記述され、その速度場をニューラルネットでモデル化する。
- 拡散モデルの一般化と見なせ、シミュレーションフリー学習や柔軟なパス設計が利点。
- 主要なステップは「確率パス設計」と「速度場回帰」。
- 条件付きFM損失により、ターゲット速度場が簡単に得られ、効率的に学習できる。
第2章 フローの数理:フローマッチングの基礎を固める
この章のゴール:
この章では、フローマッチングの理論を理解し、実際にモデルを構築するために不可欠な数学的な概念を整理します。第1章で直感的に触れた「フロー(流れ)」や「速度場」が、どのように確率分布のダイナミクスを記述するのかを、常微分方程式(ODE)、プッシュフォワード写像、連続の方程式といった道具立てを通して見ていきます。また、フローモデルの学習における伝統的な課題であった尤度計算やシミュレーションコストについても触れ、フローマッチングがこれらの課題にどのようにアプローチするのか、その動機を明らかにします。この章を学ぶことで、フローマッチングがどのような数学的基盤の上に成り立っているのかを深く理解し、第3章以降の核心的な議論へと進むための強固な土台を築くことを目指します。
(原著の §3 "Flow models" に相当する内容です。)
2.1 フローモデルとは何か?:ODEによる決定論的変換
フローマッチングの「フロー(流れ)」は、数学的には時間依存の可逆な変換として定義されます。具体的には、ある
初期条件を
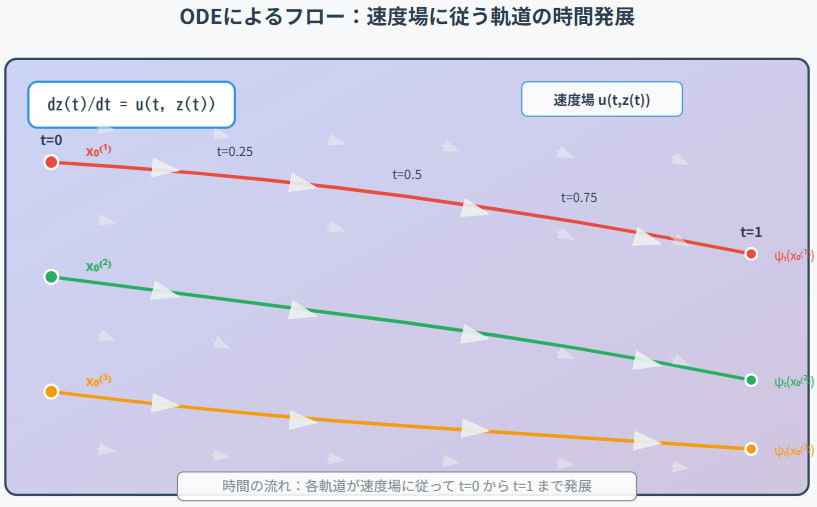
図2.1:ODEによるフローの概念図。初期点
フローの重要な性質:
-
可逆性(Invertibility): 速度場
u(t, x) \psi_t t \psi_t \psi_t^{-1} t z(t) 0 x_0 -
決定論性(Determinism): ODE (原著 Eq. 3.19a) は確率的な要素を含まないため、初期値
x_0 \psi_t(x_0)
フローマッチングでは、ソース分布
2.1.1 速度場とフローの等価性 (原著 §3.4.1)
速度場
逆に、可逆なフロー
と書けます。ここで
このように、速度場とフローは1対1に対応し、どちらかを指定すればもう一方が決まります。フローマッチングでは、学習の対象として速度場
2.2 プッシュフォワード:フローによる確率分布の変換
フロー
ソース分布
ここで、
-
\psi_t^{-1}(x) -
J_{\psi_t^{-1}}(x) \psi_t^{-1} x -
\det J_{\psi_t^{-1}}(x) -
|\cdot|
この式は、点
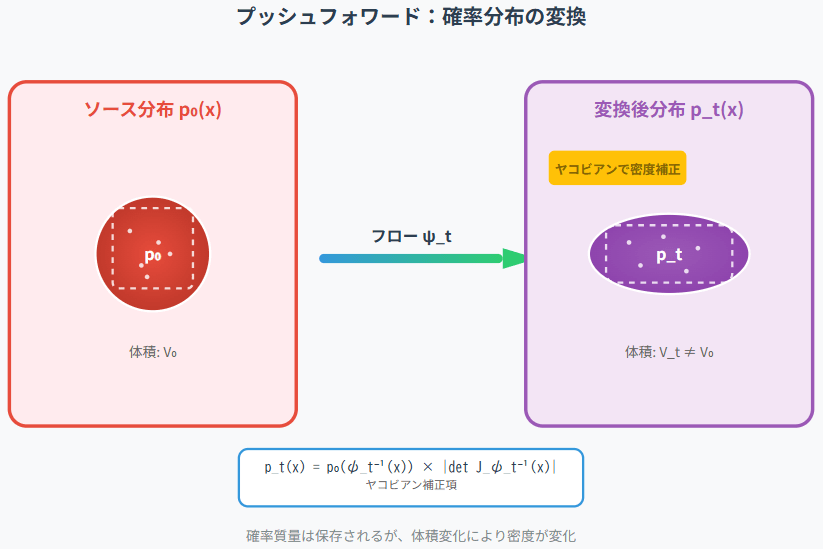
図2.2:プッシュフォワードの概念図。ソース分布
2.3 確率パスと連続の方程式 (原著 §3.5)
フローマッチングでは、ソース分布
ある速度場
ここで、
-
\frac{\partial p_t(x)}{\partial t} t p_t(x) -
\nabla_x \cdot (\cdot) \nabla_x \cdot v = \sum_j \frac{\partial v_j}{\partial x_j} -
p_t(x) u(t, x) x
連続の方程式は、ある微小体積内の確率の時間変化が、その体積から流れ出す(または流れ込む)確率流束の正味の量に等しいことを述べています。
定理(質量保存則、原著 Theorem 2):
確率パス
- 連続の方程式 (原著 Eq. 3.25) が
t \in [0,1) - 速度場
u_t p_t
この定理は、フローマッチングの理論的基盤となります。我々が設計した確率パス
2.4 瞬間的変数変換と尤度計算 (原著 §3.6)
フローモデルの魅力の一つは、尤度
時刻
この式の右辺は、フローの経路上での速度場の発散です。
このODEを
この式は、連続正規化フロー(CNF)の尤度計算式と同じです。
もし、速度場
- ターゲットサンプル
x_1 - ODE
\frac{dz(t)}{dt} = u(t, z(t)) t=1 t=0 z(1)=x_1 x_0 = z(0) - その逆向きの軌道に沿って
\int_1^0 \nabla_x \cdot u(t, z(t)) dt = - \int_0^1 \nabla_x \cdot u(t, z(t)) dt -
\log p_1(x_1) = \log p_0(x_0) + \int_1^0 \nabla_x \cdot u(t, z(t)) dt
2.4.1 従来のフローモデル学習の課題 (原著 §3.7)
この尤度計算 (原著 Eq. 3.31) は理論的には美しいですが、実際の学習に用いるにはいくつかの課題がありました。
-
発散計算のコスト: 高次元データの場合、
\nabla_x \cdot u(t, x) - ODEシミュレーションのコスト: 学習の各イテレーションで尤度を計算するために、(順方向または逆方向の) ODEを解く必要があり、これが学習全体の計算量を増大させます。
これらの課題のため、従来のCNFの学習は、最尤推定であっても計算コストが高いものでした。
フローマッチングは、このシミュレーションや発散計算を学習時には不要にする(または大幅に簡略化する)ことで、よりスケーラブルなフローモデルの学習を目指します。
2.5 この章のまとめ:フローマッチングを支える数学的道具
この章では、フローマッチングの理論的背景となるフローモデルの数学的な基礎を学びました。
-
フローモデル: 時間依存の速度場
u(t, x) \frac{dz(t)}{dt} = u(t, z(t)) \psi_t(x_0) -
プッシュフォワード: フロー
\psi_t p_0 p_t = (\psi_t)_{\#} p_0 -
確率パスと連続の方程式: ソース分布
p_0 p_1 p_t u_t \frac{\partial p_t}{\partial t} + \nabla \cdot (p_t u_t) = 0 - 瞬間的変数変換: フローに沿った対数尤度の変化は、速度場の発散で記述され、これによりターゲット尤度の正確な計算が(原理的には)可能です。
- 従来の課題: 尤度計算のための発散計算とODEシミュレーションはコストが高く、スケーラブルな学習の妨げとなっていました。
これらの数学的基盤と課題認識の上に、フローマッチングは「シミュレーションフリー」かつ「発散計算フリー(多くの場合)」な学習を実現する新しいアプローチを提案します。次章では、いよいよフローマッチングの核心的なアルゴリズムとその理論的保証について詳しく見ていきます。
ここまでの議論のポイント:
- フローはODEで定義される可逆な決定論的変換。速度場と1対1対応。
- プッシュフォワードで確率分布がフローに従って変換される。
- 確率パス
p_t u_t - フローモデルは原理的に正確な尤度計算が可能だが、発散計算とODEシミュレーションが学習時のボトルネックだった。
- フローマッチングはこれらのボトルネックを回避することを目指す。
第3章 フローマッチングの核心:理論とアルゴリズム
この章のゴール:
この章では、フローマッチング(FM)の心臓部である学習アルゴリズムとその理論的な正当性に深く踏み込みます。第1章で概観した「確率パスの設計」と「速度場の回帰学習」という2つのステップが、具体的にどのように実現されるのかを詳細に解説します。特に、なぜ単純な条件付きフローマッチング(CFM)損失で学習したモデルが、複雑な周辺速度場を正しく捉えることができるのか、その鍵となる「周辺化トリック(Marginalization Trick)」を理解することが重要です。また、損失関数として用いられるBregmanダイバージェンスの役割や、様々なデータ結合(カップリング)の概念にも触れ、フローマッチングの柔軟性と一般性を示します。この章を通じて、フローマッチングがどのようにして効率的かつ効果的な生成モデルの学習を可能にするのか、その数学的な仕組みを明らかにします。
(原著の §4 "Flow Matching" の内容に相当する内容です。)
まず、この章で議論するフローマッチングのフレームワークにおける主要な構成要素とその間の関係性を、図3.0に示します。この図は、フロー、速度場、確率パス、境界条件、そして様々な損失関数がどのように連携してフローマッチングを実現するかを俯瞰するものです。特に、複雑な周辺フローの構築(図上段)を、より扱いやすい条件付きフロー(図中段)に分解し、それを学習するというフローマッチングの核心的な戦略(青い矢印で示される関係性)に注目してください。本章の議論を通じて、この図の各要素がどのように機能するのかを明らかにしていきます。
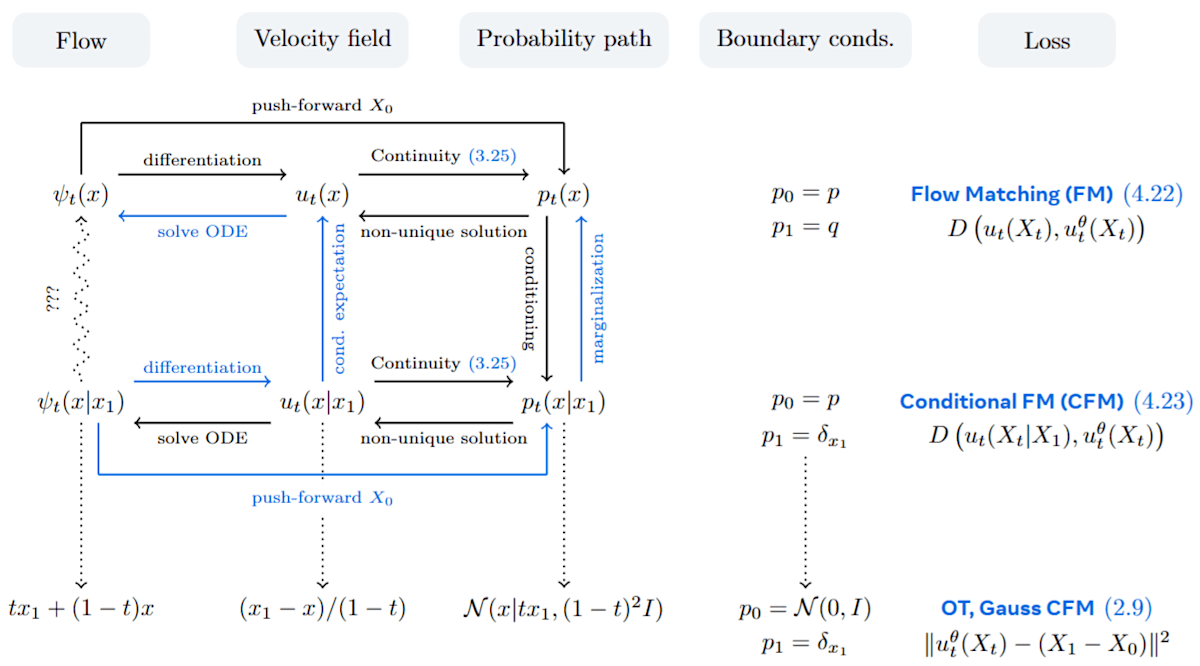
図3.0 (論文Figure 9):フローマッチングフレームワークの主要なオブジェクトとその関係性。フローは速度場によって表現され、確率パスを生成するランダムプロセスを定義する。フローマッチングの主なアイデアは、望ましい境界条件(上段)を満たす複雑なフローの構築を、より単純な境界条件を満たし、結果として解くのが容易な条件付きフロー(中段)に分解することである。矢印は異なるオブジェクト間の依存関係を示し、青い矢印はフローマッチングフレームワークで利用される関係性を示す。損失列は速度場を学習するための損失をリストしており、CFM損失(中段と下段)が実際に用いられる。下段はセクション2(本記事の第1章クイックツアー)で説明された最も単純なFMアルゴリズムの具体例をリストしている。(Meta AI "Flow Matching Guide and Code" Fig. 9 より引用)
3.1 データと確率パスの構築 (原著 §4.1, 4.2)
フローマッチングの出発点は、ソース分布
3.1.1 データ結合(カップリング)
確率パスを構築する際、ソースサンプル
-
独立カップリング: 最も単純なのは、
X_0 X_1 \pi_{0,1}(X_0, X_1) = p_0(X_0)p_1(X_1) -
依存カップリング:
X_0 X_1 X_0 X_1 X_0 X_1 (X_0, X_1)
フローマッチングの柔軟性の一つは、これらの異なるカップリングを自然に扱える点にあります。
3.1.2 条件付き確率パスの導入
周辺確率パス
周辺確率パス
最も一般的なのは、
原著の§4.2では、主に
この条件付き確率パス
-
t=0 p_{0|1}(x|x_1) = \pi_{0|1}(x|x_1) X_0 p_0(x) -
t=1 p_{1|1}(x|x_1) = \delta_{x_1}(x) x_1
これにより、周辺パス
例えば、原著で紹介されている線形補間パス(条件付きガウスパス、原著 §2の例。図3.0下段の
3.2 生成速度場の導出 (原著 §4.3)
条件付き確率パス
これは、第2章で見たように、条件付き確率パス
多くの場合、この条件付き速度場
例えば、確率変数
第1章で触れた線形パス
時刻
これを生成する
その時間微分
この速度場を
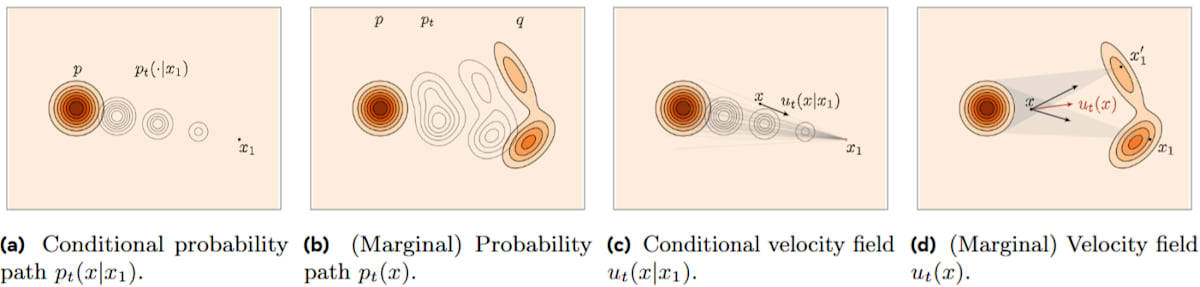
図3.1:フローマッチングにおけるパス設計。固定されたターゲットサンプル
3.3 周辺化トリック:条件付きから周辺へ (原著 §4.4)
さて、我々が最終的に学習したいのは、周辺確率パス
この周辺速度場
ここで、
この
しかし、フローマッチングの素晴らしい点は、この複雑な周辺速度場
定理(周辺化トリック、原著 Theorem 3):
(適切な正則性の仮定の下で)もし条件付き速度場
(ここで
この定理により、我々は単純な条件付きオブジェクト
3.4 フローマッチング損失 (原著 §4.5)
学習の目標は、ニューラルネットワークでパラメータ化された速度場
これは、Bregmanダイバージェンス
Bregmanダイバージェンスは、
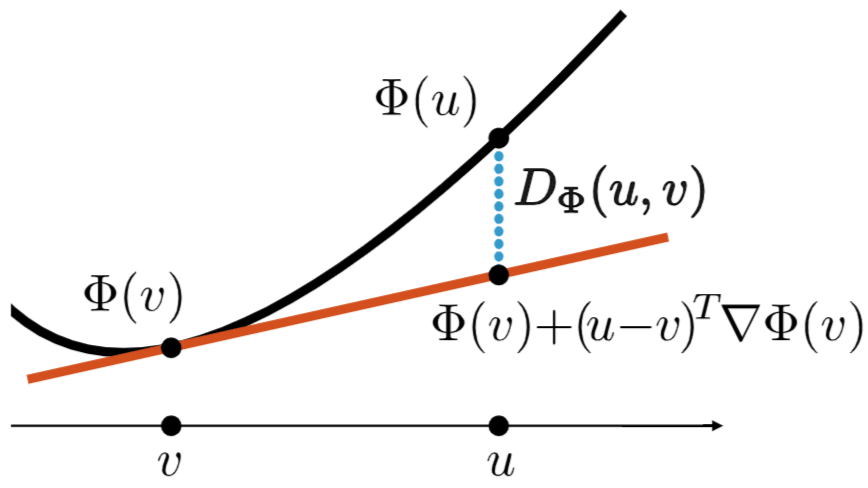
図3.2:Bregmanダイバージェンス。
しかし、前述の通り
ここで、
となります(サンプル
図3.0の下段「Loss」列に示される「OT, Gauss CFM」損失
定理(FM損失とCFM損失の勾配の等価性、原著 Theorem 4):
Bregmanダイバージェンス
が成り立ちます。つまり、CFM損失を最小化することは、FM損失を最小化することと(勾配の観点から)等価です。
さらに、CFM損失の最小解は、周辺速度場
この定理が、フローマッチングの学習を実用的なものにするための核心的な結果です。我々は、扱いやすい条件付き量をターゲットにして回帰学習を行うだけで、目的の複雑な周辺量を学習できるのです。
(原著 Proposition 1 は、この勾配等価性のより一般的な形を示しています。)
3.5 条件付きフローによる条件付き生成 (原著 §4.6)
これまで、条件変数
例えば、テキスト記述
このとき、確率パス
-
p_{0|y}(x|y) = p_0(x) y -
p_{1|y}(x|y) = q(x|y) y
となるように設計します。
そして、学習時には、
(ここで
サンプリング時には、所望の条件
(これは、第4章で見た拡散モデルの分類器無しガイダンスと似た構造を、より一般的に実現する方法と言えます。)
原著の§4.6では、
これは、確率パス
\psi_0(X_0|x_1) = X_0 -
\psi_1(X_0|x_1) = x_1
を満たすように設計されます(原著 Eq. 4.29)。この設計の自由度がフローマッチングの強みの一つです。
3.5.1 様々な条件付けの選択肢 (原著 §4.6.3, Fig. 11)

図3.3:フローマッチングにおける様々な条件付け形式と対応する条件付きフロー。左から、
条件変数
-
Z=X_1 \psi_t(X_0|X_1) u_t(X_t|X_1) -
Z=X_0 X_0 X_1 \psi_t(X_1|X_0) u_t(X_t|X_0) X_0 X_1 -
Z=(X_0,X_1) (X_0,X_1) \psi_t(X_0,X_1) t X_t \dot{\psi}_t(X_0,X_1) X_t X_0, X_1, t
重要なのは、これらの条件付きフローが適切に(例えば微分同相写像として)定義されれば、周辺化トリックによって、最終的に得られる周辺速度場
3.6 最適輸送と線形条件付きフロー (原著 §4.7)
条件付きフロー
動的OT問題は、あるコスト(例えば、移動する「運動エネルギー」
二次コストの場合、この解は「OT変位補間(OT displacement interpolant)」と呼ばれ、
フローマッチングでは、このOTのアイデアを条件付きフローに取り入れます。
具体的には、CFM損失の上界を最小化するような条件付きフローを考えると、それは線形条件付きフロー
であることが示されます(Liu et al., 2022; Lipman et al., 2022)。
このとき、対応する条件付き速度場は(
となります。これが、第1章のクイックツアーで紹介された最も基本的なフローマッチング損失であり、図3.0の下段に示される「OT, Gauss CFM」の具体例です。
この「条件付きOTフロー」は、学習を安定させ、サンプリング時のODEステップ数を減らす効果が期待されます。
3.7 アフィン条件付きフローとその仲間たち (原著 §4.8)
線形条件付きフロー
の特殊なケースです。ここで、
このアフィン条件付きフローに対応する条件付き速度場は
この速度場
3.7.1 ガウスパス (原著 §4.8.3)
特に重要なのは、ソース分布
このとき、アフィン条件付きフローから導かれる条件付き確率パス
となります。
これは、拡散モデルで用いられるノイズ付加過程と非常によく似た形をしています。
例えば、
-
Variance Preserving (VP) スケジューラ:
\alpha_t = \sqrt{1-e^{-\beta_t}}, \sigma_t = e^{-\beta_t/2} -
Variance Exploding (VE) スケジューラ:
\alpha_t = 1, \sigma_t = \sigma_{\text{max}}(1-t)
(ここで\sigma_{\text{max}}
あるいは、より一般的に\sigma_t t=0 t=1 0
これらのガウスパスの場合、周辺スコア
3.8 この章のまとめ:フローマッチングの動作原理
この章では、フローマッチングの核心的な理論とアルゴリズムについて、図3.0のフレームワークを参照しながら学びました。
- 確率パスは、扱いやすい条件付き確率パス
p_{t|z}(x|z) u_t(x|z) - 周辺化トリックにより、条件付き量をターゲットとしたCFM損失で学習すれば、目的の周辺速度場が学習されることが保証される。これはBregmanダイバージェンスの性質に由来する。
- 条件付きフロー
\psi_t(X_0|x_1) \psi_t(x_0|x_1) = (1-t)x_0 + t x_1 - より一般的なアフィン条件付きフローや、ソースがガウス分布の場合のガウスパスは、拡散モデルとの繋がりを示唆する。
フローマッチングは、これらの理論的基盤の上に、多様なデータモダリティやタスクに対して柔軟かつ効果的に適用できる生成モデリングの枠組みを提供します。
次章以降では、この基本的なフローマッチングの考え方を、リーマン多様体上のような非ユークリッド空間や、離散データ空間へと拡張していく様子を見ていきます。
ここまでの議論のポイント:
- 確率パスは条件付きパスとその速度場から構築。
- 周辺化トリック:CFM損失で周辺速度場を学習可能。
- 条件付きフローの設計が鍵。線形OTフローが基本。
- アフィンフロー、ガウスパスは拡散モデルと関連。
第4章 フローマッチングの拡張(1):多様体上の流れ
この章のゴール:
これまでの章では、主にユークリッド空間
(原著の §5 "Non-Euclidean Flow Matching" の内容に相当する内容です。)
4.1 リーマン多様体:曲がった空間の幾何学
まず、フローマッチングを拡張する先の舞台となる「リーマン多様体(Riemannian Manifold)」について簡単に触れておきましょう。
- 多様体(Manifold): 局所的にはユークリッド空間のように見える空間のことです。例えば、地球の表面(球面)は、我々の身の回りでは平らな2次元平面のように見えますが、大域的には曲がった2次元の多様体です。
- リーマン計量(Riemannian Metric): 多様体の各点にある「接空間(Tangent Space)」(その点で多様体に接するユークリッド空間のようなもの)上で、ベクトルの長さや角度を測るための「内積」を滑らかに定義したものです。このリーマン計量があることで、多様体上で曲線や距離、曲率といった幾何学的な量を考えることができます。
- リーマン多様体: リーマン計量が備わった多様体のことです。
フローマッチングをリーマン多様体
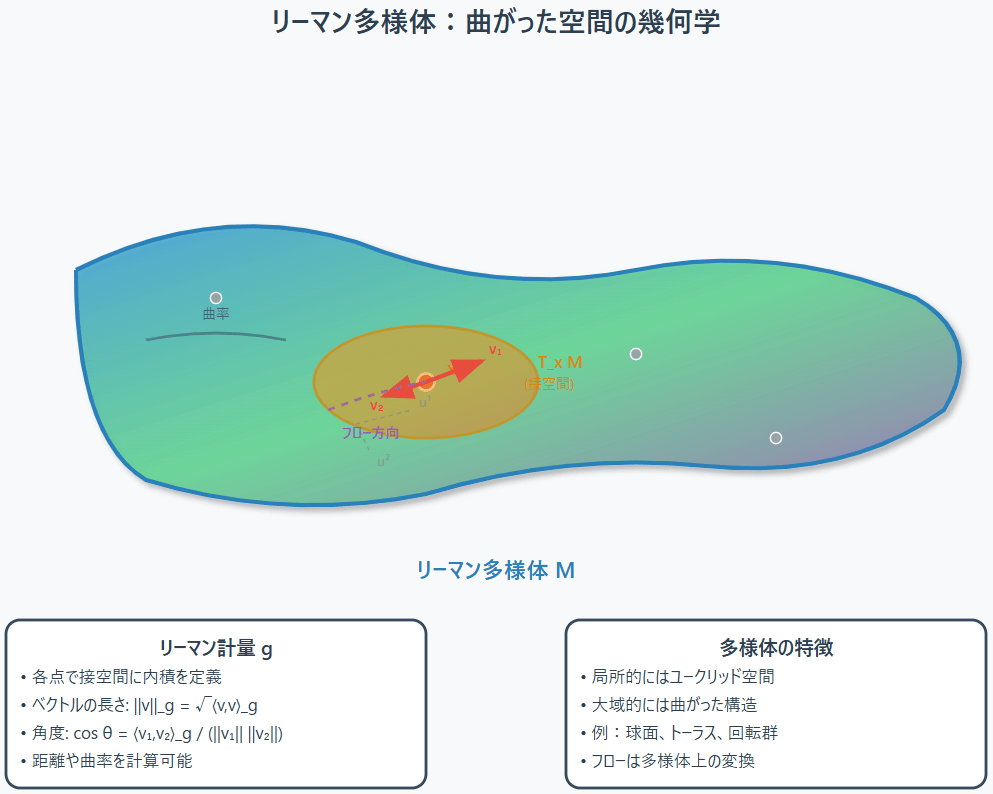
図4.1:リーマン多様体のイメージ。局所的にはユークリッド的だが、大域的には曲がっている。各点には接空間
4.2 多様体上の確率、フロー、速度場 (原著 §5.1, 5.2)
ユークリッド空間での概念を多様体上に一般化します。
-
確率密度: 多様体
\mathcal{M} p(x) x \in \mathcal{M} d\text{vol}_x \int_{\mathcal{M}} p(x) d\text{vol}_x = 1 -
フロー: 時間依存のフロー
\psi_t: \mathcal{M} \to \mathcal{M} t -
速度場: 速度場
u_t(x) x \in \mathcal{M} t T_x\mathcal{M} u_t(x) \in T_x\mathcal{M}
フロー\psi_t(x_0) \frac{d\psi_t(x_0)}{dt} = u_t(\psi_t(x_0))
4.2.1 多様体上の連続の方程式と瞬間的変数変換
第2章で見た連続の方程式や瞬間的変数変換の公式も、リーマン多様体上に自然に拡張されます。
- リーマン連続の方程式 (原著 Eq. 5.1):
ここで
- リーマン瞬間的変数変換 (原著 Eq. 5.3):
これらの式はユークリッド空間の場合と形式的には同じですが、発散演算子がリーマン計量を考慮したものに置き換わっています。
これにより、多様体上でもフローモデルの尤度計算や、速度場と確率パスの関係性を理論的に扱うことができます。
4.3 多様体上の確率パスと周辺化トリック (原著 §5.3, 5.4)
フローマッチングの核となる確率パスの構築と周辺化トリックも、リーマン多様体上に拡張できます。
-
多様体上の確率パス (原著 Eq. 5.6):
周辺確率パスp_t(x) p_{t|1}(x|x_1) x, x_1 \in \mathcal{M} q(x_1)
条件付きパスは、境界条件
-
多様体上の周辺化トリック (原著 Theorem 10):
ユークリッド空間の場合と同様に、適切な正則性の仮定(原著 Assumption 2)のもとで、条件付き速度場u_t(x|x_1) \in T_x\mathcal{M} p_{t|1}(x|x_1) u_t(x) = \mathbb{E}_{X_1 \sim p_{1|t}(\cdot|x)} [u_t(x|X_1)] p_t(x)
これにより、多様体上でも条件付き量をターゲットとした学習が正当化されます。
4.4 リーマンフローマッチング損失 (原著 §5.5)
学習に用いる損失関数も、多様体の構造を考慮したものになります。
リーマン条件付きフローマッチング(RCFM)損失は、各点
ここで、
ユークリッド空間と同様に、このRCFM損失の勾配は、周辺量をターゲットとしたリーマンフローマッチング(RFM)損失の勾配と一致します(原著 Theorem 11)。
4.5 多様体上の条件付きフロー:測地線とプレメトリック (原著 §5.6)
フローマッチングの設計において重要なのは、扱いやすく、かつ効果的な条件付きフロー
4.5.1 測地線フロー (Geodesic Flow)
リーマン多様体において、ユークリッド空間の「直線」に相当する概念が「測地線(Geodesic)」です。測地線は、2点間の最短経路(局所的には)を与えます。
この測地線を用いて、条件付きフローを構築することができます。
まず、多様体上の2点
-
指数写像 (Exponential Map)
\exp_{x_0}: T_{x_0}\mathcal{M} \to \mathcal{M} x_0 v \in T_{x_0}\mathcal{M} v x_0 -
対数写像 (Logarithmic Map)
\log_{x_0}: \mathcal{M} \to T_{x_0}\mathcal{M} x_1 \in \mathcal{M} x_0 x_1 \log_{x_0}(x_1) x_0 x_1
これらを用いると、測地線条件付きフローは以下のように定義できます(原著 Eq. 5.17)。
ここで、
これは、
-
t=0 \kappa(0)=0 \psi_0(x_0|x_1) = \exp_{x_0}(\mathbf{0}) = x_0 -
t=1 \kappa(1)=1 \psi_1(x_0|x_1) = \exp_{x_0}(\log_{x_0}(x_1)) = x_1
これは、ユークリッド空間での線形補間
この測地線フローは、単純な多様体(球面、双曲空間など)で指数・対数写像が閉じた形で計算できる場合には、シミュレーションフリーなフローマッチングを可能にします。これは、多様体上の拡散モデルがしばしば複雑なスコア計算やSDEシミュレーションを必要とするのと対照的です。
4.5.2 プレメトリックを用いたフロー
しかし、一般的な多様体では指数・対数写像の計算が困難であったり、測地線が一意に定まらなかったり(カットローカスを越える場合など)、あるいは測地線が望ましい経路ではない場合もあります(例えば、データが特定の制約を満たすように多様体内に埋め込まれているが、測地線はその制約を破ってしまうなど)。
そこで、より柔軟なアプローチとして、測地距離
具体的には、条件付きフロー
ここで
この条件を満たすフローに対する最小ノルムの条件付き速度場は、以下のように与えられます(原著 Eq. 5.19)。
(ただし、
このアプローチの利点は、
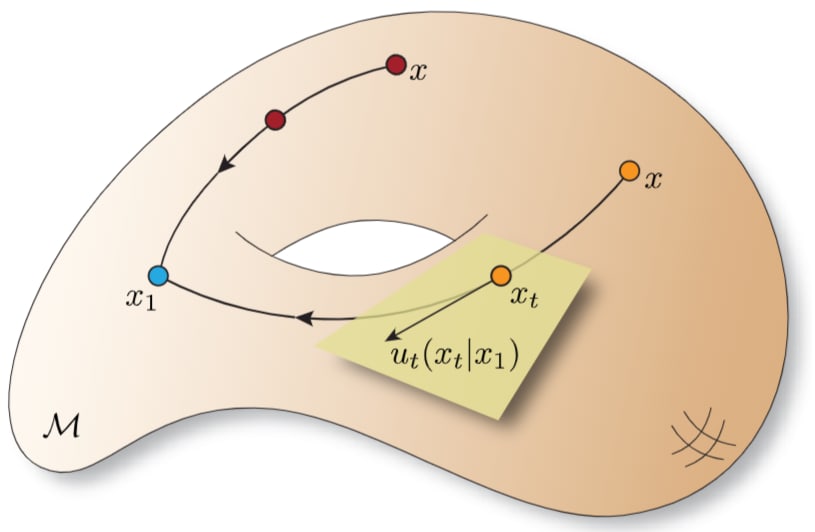
図4.2:多様体
4.5.3 測地線フローの課題と対処
測地線フローやプレメトリックフローには、特異点の問題が伴うことがあります。
例えば、球面上での測地線距離
これらの問題に対処するため、実際には以下のような工夫が考えられます。
-
スケジューリング関数の調整:
\kappa(t) \tilde{\kappa}(t) t x_0, x_1 - 非縮退条件の緩和: プレメトリックの勾配がゼロになる点の集合の測度がゼロであれば、実用上は問題ないことが多い(原著 p.39 "Non-degenerate (relaxed)")。
原著のCode 8では、球面上での測地線フローを用いたフローマッチングの訓練例が示されています。そこでは、モデルが出力した速度ベクトルを、現在の点における接空間に射影する操作が含まれており、これは多様体上で速度場を扱う際の重要な実践的ステップです。
4.6 この章のまとめ:フローマッチングの幾何学的な拡張
この章では、フローマッチングの枠組みをユークリッド空間からリーマン多様体へと拡張する方法を学びました。
- リーマン多様体は、局所的にユークリッド的だが大域的に曲がった空間であり、リーマン計量によって幾何学的な構造が定義される。
- 多様体上でも、確率分布、フロー、速度場、連続の方程式、瞬間的変数変換といった概念が自然に定義され、フローマッチングの理論的基礎が保たれる。
- 周辺化トリックも多様体上で成り立ち、条件付き量をターゲットとした学習(RCFM損失)が正当化される。
- 多様体上の条件付きフローを構築する主要な方法として、
- 測地線フロー: 多様体上の「直線」である測地線に沿って点を移動させる。指数・対数写像が計算可能ならシミュレーションフリー学習も可能。
-
プレメトリックフロー: 一般的な距離関数
d(x,y)
- 特異点の存在など、多様体特有の課題もあるが、実用的な対処法も研究されている。
この拡張により、フローマッチングは、より広範な種類のデータ(特に複雑な幾何学的構造を持つもの)に対して適用可能な、強力で柔軟な生成モデリングのツールとなります。タンパク質構造生成、分子動力学シミュレーション、ロボティクス、コンピュータグラフィックスなど、多様な分野での応用が期待されます。
次章では、フローマッチングのもう一つの重要な拡張として、連続的な空間ではなく、カテゴリカルな値を取るような離散的な状態空間でのフローマッチング(Discrete Flow Matching)について見ていきます。これはテキスト生成などの分野で特に重要となります。
ここまでの議論のポイント:
- リーマン多様体は曲がった空間。接空間とリーマン計量が重要。
- フロー、速度場、連続の方程式、周辺化トリックは多様体上にも拡張可能。
- RCFM損失で学習。
- 条件付きフローの設計:測地線フロー(指数・対数写像)、プレメトリックフロー。
- 多様体特有の課題(特異点など)への対処も必要。
第5章 フローマッチングの拡張(2):離散空間への挑戦
この章のゴール:
これまでの章では、フローマッチングを連続的な空間(ユークリッド空間やリーマン多様体)で扱ってきました。しかし、現実世界の多くのデータ、特に自然言語(テキスト)やカテゴリカルな特徴量は、離散的な状態空間に存在します。この章では、フローマッチングのアイデアを、このような離散的な空間へと拡張する「離散フローマッチング(Discrete Flow Matching, DFM)」について探求します。連続時間マルコフ連鎖(Continuous Time Markov Chain, CTMC)という数学的ツールを導入し、それが離散空間における「フロー」の役割をどのように果たすのかを理解します。そして、DFMがどのようにして確率パスを設計し、生成的な「速度」(遷移率)を学習し、最終的に新しい離散データを生成するのか、そのメカニズムを明らかにします。この章を通じて、フローマッチングの適用範囲が連続空間だけでなく離散空間にも広がり、テキスト生成などの重要なタスクに取り組むための道が開かれることを見ていきます。
(原著の §6 "Continuous Time Markov Chain Models" および §7 "Discrete Flow Matching" の内容に相当する内容です。)
5.1 離散状態空間と連続時間マルコフ連鎖(CTMC)
まず、DFMの舞台となる離散状態空間と、その上でのダイナミクスを記述するCTMCについて理解しましょう。
5.1.1 離散状態空間 (原著 §6.1)
状態空間
簡単のため、まずは1つのトークン(つまり状態空間が
離散空間上の確率分布は、確率質量関数(Probability Mass Function, PMF)
また、ある特定状態
5.1.2 連続時間マルコフ連鎖 (CTMC) モデル (原著 §6.2)
CTMCは、離散的な状態空間
-
遷移率(Transition Rates): 状態
x \in \mathcal{S} y \in \mathcal{S} y \neq x u_t(y,x) \ge 0 -
保持時間(Holding Times): ある状態
x \sum_{y \neq x} u_t(y,x)
微小時間
これは、フローモデルにおけるODE
-
u_t(y,x) \ge 0 y \neq x -
\sum_{y \in \mathcal{S}} u_t(y,x) = 0 x u_t(x,x) = -\sum_{y \neq x} u_t(y,x)
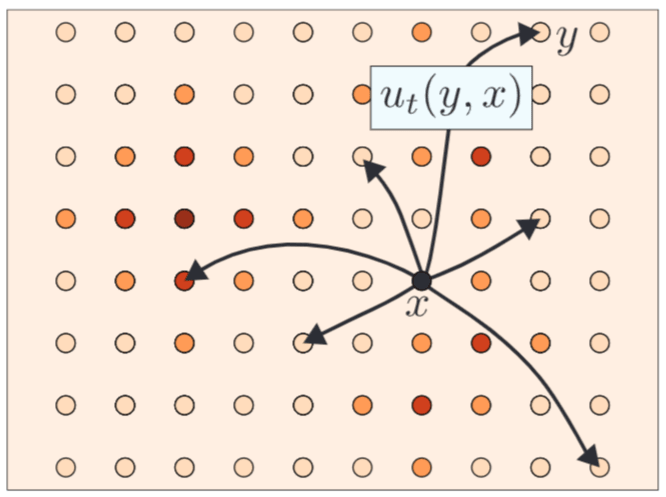
図5.1:CTMCモデル。状態間の確率的な遷移が遷移率(速度)
5.1.3 確率パスとコルモゴロフ方程式 (原著 §6.3)
CTMC
または、ベクトル形式で
これは、連続空間での連続の方程式 (2.4) に対応するものです。
ある遷移率
定理(離散質量保存則、原著 Theorem 13):
遷移率
5.2 離散フローマッチング(DFM)の枠組み (原著 §7)
連続空間でのフローマッチングのアイデアを、このCTMCの枠組みを用いて離散空間に持ち込みます。
DFMの目標は、ソースPMF
DFMのレシピも、連続FMと同様のステップを踏みます。
5.2.1 データと離散確率パスの構築 (原著 §7.1, 7.2)
-
データ結合: ソースサンプル
X_0 \sim p_0 X_1 \sim p_1 \pi_{0,1}(X_0,X_1) - テキスト生成のようなタスクでは、
p_0 X_1 \pi_{0,1}(X_0,X_1) = \delta(X_0, \text{MASK}) p_1(X_1)
- テキスト生成のようなタスクでは、
-
条件付き離散確率パス: 条件変数
Z=z Z=X_1 t p_{t|z}(x|z)
境界条件は、
5.2.2 離散空間の周辺化トリック (原著 §7.3)
連続空間と同様に、離散空間でも周辺化トリックが成り立ちます(原著 Theorem 14)。
もし条件付き遷移率
周辺遷移率
5.2.3 離散フローマッチング(DFM)損失 (原著 §7.4)
学習対象の遷移率モデルを
DFM損失は、状態
ここで、遷移率ベクトルはレート行列の条件を満たす空間
そして、条件付きDFM(CDFM)損失は、
となります。ここでも、勾配の等価性
5.3 因子化パスと速度:シーケンスへの拡張 (原著 §7.5)
ここまでは状態空間
この問題に対処するため、「因子化速度(factorized velocities)」という考え方を導入します(Campbell et al., 2024; Gat et al., 2024)。
基本的なアイデアは、状態
つまり、
このとき、全体の遷移率
ここで
この
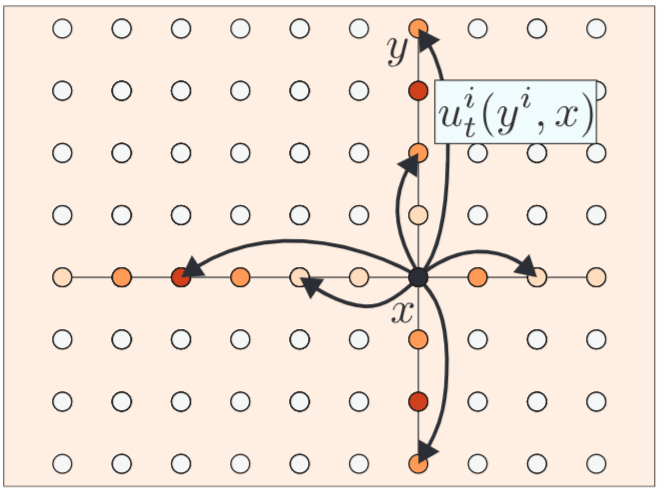
図5.2:因子化CTMCモデル。状態間の非ゼロ遷移率(速度)は、一度に最大1つの座標(トークン)が変化する場合にのみ許される。(Meta AI "Flow Matching Guide and Code" Fig. 14 より引用)
5.3.1 因子化確率パス (原著 §7.5.2)
驚くべきことに、確率パス
(実際にはこれは強すぎる仮定で、原著では条件付きパス
それを生成する遷移率もまた、上記のような因子化された形になることが示されます(原著 Proposition 2, Theorem 16)。
これにより、学習ターゲットとなる条件付き遷移率も
5.3.2 混合パス (Mixture Paths) とその遷移率 (原著 §7.5.4)
DFMで実用的に用いられる条件付き確率パスの一つが「混合パス(Mixture Path)」です。
条件変数
と定義します。ここで
つまり、時刻
このパスを生成する因子化された条件付き遷移率
(
という形で与えられます。
直感的には、まだソース
この混合パスと対応する遷移率は、DFMの具体的な実装において非常に重要です。
学習時には、
サンプリング時には、初期状態(例えば全てMASKトークン)から始め、学習された遷移率
原著のCode 9, 10, 11 は、この混合パスを用いたDFMのPyTorch実装例(おもちゃデータでのスタンドアロンコード含む)を示しており、具体的なアルゴリズムの流れを理解する上で非常に参考になります。
5.4 この章のまとめ:離散データ生成への道筋
この章では、フローマッチングのアイデアを離散状態空間へと拡張するDFMについて学びました。
- 離散空間でのダイナミクスは、連続時間マルコフ連鎖(CTMC)とその遷移率
u_t(y,x) - 確率PMFの時間発展はコルモゴロフ方程式に従う。
- DFMも、(条件付き)離散確率パスの設計と、それを生成する(条件付き)遷移率の回帰学習という2ステップで構成される。
- 離散空間の周辺化トリックにより、扱いやすい条件付き遷移率をターゲットとしたCDFM損失で学習すれば、目的の周辺遷移率が学習される。
- シーケンスデータを扱うため、遷移を一度に1トークンに限定する「因子化速度」と、それに対応する「因子化確率パス」を導入する。
- 実用的なパスとして、ソースとターゲットのトークンを時間に応じて混合する「混合パス」があり、その遷移率は解析的に求められる。
DFMは、フローマッチングの原理をテキストのような重要な離散データに適用するための強力な枠組みを提供します。これにより、従来の自己回帰型モデルとは異なるアプローチで、高品質かつ多様なテキスト生成などが期待されます。
次章では、フローマッチングの考え方をさらに一般化し、フロー(ODE)やCTMCだけでなく、拡散過程(SDE)やジャンプ過程など、より広範なマルコフ過程を統一的に扱える「ジェネレータマッチング(Generator Matching)」という枠組みについて見ていきます。これは、フローマッチングの究極的な形とも言えるでしょう。
ここまでの議論のポイント:
- 離散空間のダイナミクスはCTMC(遷移率、コルモゴロフ方程式)。
- DFMは離散確率パスと遷移率学習。周辺化トリックも有効。
- シーケンスには因子化速度とパスが重要。
- 混合パスが実用的な選択肢。
第6章 フローマッチングの一般化:ジェネレータマッチング
この章のゴール:
これまでの章で、フローマッチングが連続空間(ユークリッド空間、多様体)や離散空間でどのように機能するかを見てきました。この章では、これらのアイデアをさらに一般化し、フロー(ODE)、連続時間マルコフ連鎖(CTMC)、さらには拡散過程(SDE)やより一般的なジャンプ過程といった、広範な連続時間マルコフ過程(Continuous Time Markov Process, CTMP)を統一的に扱える「ジェネレータマッチング(Generator Matching, GM)」という枠組みを導入します。CTMPの「ジェネレータ(生成作用素)」という数学的対象が、速度場(フロー)や遷移率行列(CTMC)の役割を一般化したものであることを理解し、GMがどのようにしてこのジェネレータを学習し、任意のデータモダリティとマルコフ過程の組み合わせで生成モデルを構築可能にするのか、その強力な統一性と柔軟性を探求します。この章を通じて、フローマッチングが持つポテンシャルの広大さと、生成AIのフロンティアを切り拓くためのより普遍的な原理を掴むことを目指します。
(原著の §8 "Continuous Time Markov Process Models" および §9 "Generator Matching" の内容に相当する内容です。)
6.1 連続時間マルコフ過程(CTMP)とそのジェネレータ
まず、ジェネレータマッチングの基礎となるCTMPとそのジェネレータについて理解を深めましょう。
6.1.1 一般的な状態空間とCTMP (原著 §8.1)
GMは、状態空間
-
\mathbb{R}^d - 離散集合(言語、カテゴリなど)
- リーマン多様体(幾何学的データ)
- あるいはこれらの直積(マルチモーダルデータ、例:画像とテキストのペア)
であっても構いません。必要なのは、\mathcal{S}
このような一般の空間
CTMPは、遷移核(Transition Kernel)
6.1.2 ジェネレータ(生成作用素) (原著 §8.2.1)
CTMPの微小時間での振る舞いを記述するのが「ジェネレータ(Infinitesimal Generator)」または「生成作用素」
これは、時刻
このジェネレータ
テスト関数 f の役割について
テスト関数
-
確率分布の「観測」: 確率分布
p(x) f \mathbb{E}_{X \sim p}[f(X)] f p(x) -
ジェネレータの作用の具体化: ジェネレータ
\mathcal{L}_t f [\mathcal{L}_t f](x) f -
数学的一般性と厳密性: テスト関数を用いることで、確率分布が密度関数を持たない場合や、ジェネレータが単純な微分演算子で書けない場合など、より広範な状況を数学的に厳密に扱えるようになります。これは、GMのような一般理論を構築する上で不可欠です。
GMの文脈では、テスト関数は特に後述するコルモゴロフ前向き方程式(KFE)の弱形式での定式化や、ジェネレータをパラメータ化する際のカーネル
-
フロー(ODE)の場合 (原著 §8.2.2, Eq. 8.17):
d_t X_t = u_t(X_t) dt \implies [\mathcal{L}_t f](x) = \langle \nabla f(x), u_t(x) \rangle
(速度場u_t(x) -
拡散過程(SDE)の場合 (原著 §8.2.2, Eq. 8.26):
d_t X_t = \sigma_t(X_t) dW_t \implies [\mathcal{L}_t f](x) = \frac{1}{2} \text{Tr}(\sigma_t(x)\sigma_t(x)^T \nabla^2 f(x))
(拡散係数\sigma_t(x) \nabla^2 f(x) \frac{1}{2}\sum_{i,j} (\sigma_t\sigma_t^T)_{ij} \frac{\partial^2 f}{\partial x_i \partial x_j} -
ジャンプ過程の場合 (原著 §8.2.2, Eq. 8.36):
遷移強度測度Q_t(dy, x) \implies [\mathcal{L}_t f](x) = \int_{\mathcal{S}} [f(y)-f(x)] Q_t(dy,x) -
CTMC(離散空間のジャンプ過程)の場合 (原著 §8.2.2, Eq. 8.38):
遷移率行列u_t \implies [\mathcal{L}_t f](x) = \sum_{y \in \mathcal{S}} f(y) u_t(y,x) = f^Tu_t
(最右辺はf u_t
普遍的表現定理(原著 Theorem 18, §8.4, Eq. 8.68):
(適切な正則性の下で)ユークリッド空間
ここで
ジャンプ項(jump term)と補償項について
より一般的なレヴィ過程の理論では、ジャンプ測度
しかし、原著を含め多くのフローマッチングや拡散モデルの文脈では、議論を簡潔にするため、あるいは特定の仮定の下で、上記の補償なしの形式が用いられます。
以下の図6.1(原著の Table 2 より引用)は、フロー、拡散、ジャンプ、CTMCのジェネレータを並べて示しており、この構造を理解する助けになります。
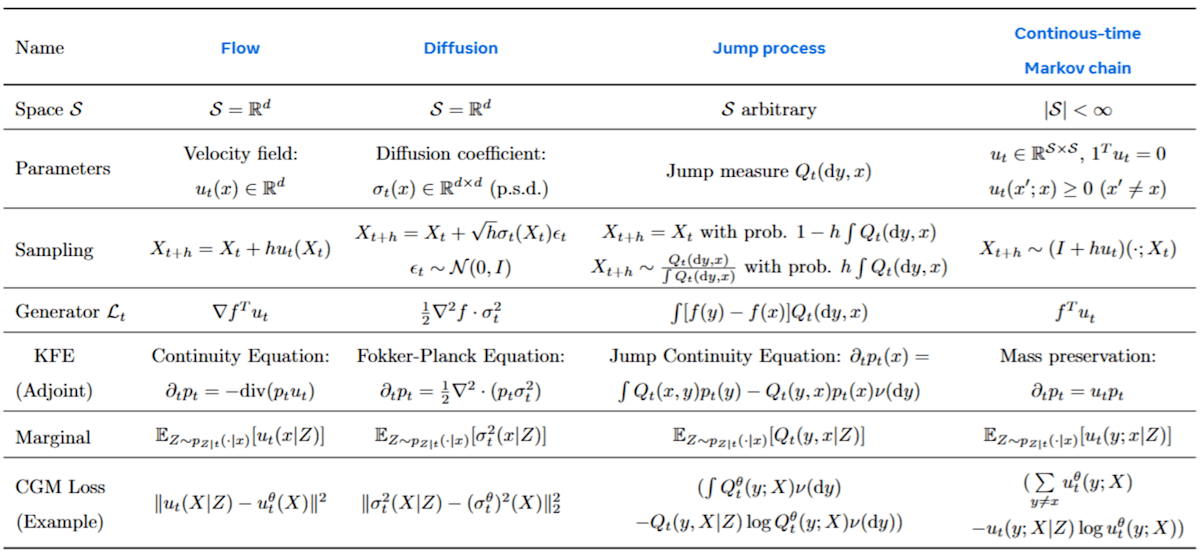
図6.1:CTMP生成モデルの例とジェネレータマッチングによる学習方法。フロー、拡散、ジャンプ過程、連続時間マルコフ連鎖(CTMC)がジェネレータの形で統一的に記述される。(Meta AI "Flow Matching Guide and Code" Table 2 を一部修正 (CTMCのGeneratorの式を修正))
6.1.3 ジェネレータとコルモゴロフ前向き方程式 (原著 §8.3)
マルコフ過程の「瞬間的な変化のルール」であるジェネレータ
KFEを理解することは、「ジェネレータ
KFEには主に2つの表現形式があります。
-
弱形式(テスト関数とジェネレータを用いた形式)(原著 Eq. 8.40):
\frac{d}{dt} \langle p_t, f \rangle = \langle p_t, \mathcal{L}_t f \rangle -
何をしているか: 左辺は、テスト関数
f p_t \mathcal{L}_t f f p_t -
意味: 確率分布
p_t -
利点:
p_t
-
何をしているか: 左辺は、テスト関数
-
強形式(密度関数と随伴ジェネレータを用いた形式)(原著 Eq. 8.47):
もしp_t \nu p_t(x) \frac{d p_t(x)}{dt} = [\mathcal{L}_t^* p_t](x) -
何をしているか: 左辺は、各点
x p_t(x) \mathcal{L}_t^* \mathcal{L}_t p_t -
意味: 各点での確率密度の時間変化は、現在の確率分布全体に
\mathcal{L}_t^*
-
何をしているか: 左辺は、各点
随伴ジェネレータ L_t^* の役割について
随伴ジェネレータ
内積
を満たすものとして定義されます(原著 Eq. 8.41)。これは、作用素
これを用いると、弱形式のKFEは
随伴ジェネレータの具体例:
-
フロー:
\mathcal{L}_t f = \langle \nabla f, u_t \rangle \implies \mathcal{L}_t^* p_t = -\nabla \cdot (p_t u_t) -
拡散:
\mathcal{L}_t f = \frac{1}{2} \text{Tr}(\sigma_t\sigma_t^T \nabla^2 f) \implies \mathcal{L}_t^* p_t = \frac{1}{2} \sum_{i,j} \frac{\partial^2 (\Sigma_{t,ij} p_t)}{\partial x_i \partial x_j}
随伴ジェネレータを考えることで、ジェネレータのパラメータ関数(速度場や拡散係数など)が、我々がよく知る密度関数の偏微分方程式の中にどのように現れるかを具体的に見ることができます。
ジェネレータ
6.2 ジェネレータマッチング(GM)の枠組み (原著 §9)
GMの目標は、所望の確率パス
6.2.1 ジェネレータの線形パラメータ化 (原著 §9.3)
多くのCTMPのジェネレータは、テスト関数
ここで
学習するのは、このパラメータ関数
例:
-
フロー:
K_f(x) = \nabla f(x) F_t(x) = u_t(x) -
拡散:
K_f(x) = \frac{1}{2}\nabla^2 f(x) F_t(x) = \sigma_t(x)\sigma_t(x)^T -
CTMC:
K_f(x) = f F_t(x) = u_t(\cdot, x)
6.2.2 周辺ジェネレータと条件付きジェネレータ (原著 §9.4)
フローマッチングと同様に、GMでも条件付けと周辺化のトリックを用います。
-
条件付き確率パス
p_{t|z}(dx|z) - それを生成する条件付きジェネレータ
\mathcal{L}_t^z F_t(x|z) -
周辺化トリックの一般化(原著 Theorem 19):
周辺確率パスp_t(dx) = \int p_{t|z}(dx|z) p_Z(dz) \mathcal{L}_t \mathcal{L}_t F_t(x)
と、条件付きパラメータ関数
6.2.3 ジェネレータマッチング損失 (原著 §9.5)
学習は、ニューラルネットワーク
そして、フローマッチングと同様に、この損失は勾配が等価な条件付きジェネレータマッチング(CGM)損失に置き換えることができます。
定理(GM損失とCGM損失の勾配の等価性、原著 Theorem 20):
かつ、CGM損失の最小解は、所望の周辺パラメータ関数
この定理がGMの核心であり、これにより、任意のCTMPに対して、扱いやすい条件付きパラメータ関数
6.2.4 条件付きジェネレータの求め方 (原著 §9.6)
CGM損失で学習するためには、ターゲットとなる条件付きパラメータ関数
から、ジェネレータ
原著では、例としてジャンプ過程(混合パスを含む)での
6.3 モデルの組み合わせと拡張:GMの創造力 (原著 §9.7, 9.8)
ジェネレータマッチング(GM)の強力さは、統一的な学習フレームワークを提供するだけに留まりません。その数学的な構造は、既存のモデルを自在に組み合わせたり、新しい機能を付け加えたりするための、非常に柔軟な「創造のプラットフォーム」として機能します。このセクションでは、その具体的な方法を探ります。
6.3.1 ジェネレータの線形結合:モデルの重ね合わせ (原著 Proposition 3)
この創造力の源泉は、ジェネレータ
Proposition 3(モデルの組み合わせ):
ある確率パス
-
マルコフ・スーパーポジション (Markov Superposition):
もし\mathcal{L}_t \mathcal{L}_t^{\prime} p_t \alpha_t^{(1)} \mathcal{L}_t + \alpha_t^{(2)} \mathcal{L}_t^{\prime} (ただし
\alpha_t^{(1)}, \alpha_t^{(2)} \ge 0 \alpha_t^{(1)} + \alpha_t^{(2)} = 1 p_t - 意味: これは、異なる種類のダイナミクスを「混ぜ合わせる」ことを可能にします。例えば、普段は滑らかに動くフロー(ODE)に、時々ランダムなジャンプを加えるような、よりリッチな挙動を持つモデル(区分的決定的マルコフ過程)を簡単に設計できます。学習は、それぞれのコンポーネントを個別にGMで学習するか、あるいは両方を同時に学習することで行えます。
-
発散ゼロ成分の追加 (Divergence-free Components):
もし\mathcal{L}_t p_t \mathcal{L}_t^{\text{div}} \mathcal{L}_t + \beta_t \mathcal{L}_t^{\text{div}} (ただし
\beta_t \ge 0 p_t 発散ゼロとは?
ジェネレータ
\mathcal{L}_t^{\text{div}} p_t \mathcal{L}_t^{\text{div}} p_t
数学的には、KFEの右辺がゼロになる、すなわち\langle p_t, \mathcal{L}_t^{\text{div}} f \rangle = 0 f -
意味: これは極めて強力な概念です。我々は、元の生成過程の軌道(確率パス
p_t
-
意味: これは極めて強力な概念です。我々は、元の生成過程の軌道(確率パス
-
予測子・修正子スキーム (Predictor-Corrector):
もし\mathcal{L}_t p_t \bar{\mathcal{L}}_t p_t \alpha_t^{(1)} \mathcal{L}_t + \alpha_t^{(2)} \bar{\mathcal{L}}_t (ただし
\alpha_t^{(1)}, \alpha_t^{(2)} \ge 0 \alpha_t^{(1)} - \alpha_t^{(2)} = 1 p_t なぜこの条件なのか?
逆時間ジェネレータ
\bar{\mathcal{L}}_t \frac{d}{dt} \langle p_t, f \rangle = - \langle p_t, \bar{\mathcal{L}}_t f \rangle
この性質を使うと、新しいジェネレータ\mathcal{L}_t^{\text{PC}} \begin{aligned} \langle p_t, \mathcal{L}_t^{\text{PC}} f \rangle &= \langle p_t, (\alpha_t^{(1)} \mathcal{L}_t + \alpha_t^{(2)} \bar{\mathcal{L}}_t) f \rangle \\ &= \alpha_t^{(1)} \langle p_t, \mathcal{L}_t f \rangle + \alpha_t^{(2)} \langle p_t, \bar{\mathcal{L}}_t f \rangle \\ &= \alpha_t^{(1)} \left( \frac{d}{dt} \langle p_t, f \rangle \right) + \alpha_t^{(2)} \left( - \frac{d}{dt} \langle p_t, f \rangle \right) \\ &= (\alpha_t^{(1)} - \alpha_t^{(2)}) \frac{d}{dt} \langle p_t, f \rangle \\ &= \frac{d}{dt} \langle p_t, f \rangle \end{aligned} となり、確かに元の順時間KFEを満たすことがわかる。
-
意味: このスキームは、確率的微分方程式(SDE)に基づく拡散モデルのサンプラーで中心的な役割を果たします。
-
予測子 (Predictor):
\alpha_t^{(1)} \mathcal{L}_t -
修正子 (Corrector):
\alpha_t^{(2)} \bar{\mathcal{L}}_t p_t
この組み合わせにより、純粋なODE/SDEサンプラー(
\alpha_t^{(2)}=0 -
予測子 (Predictor):
-
6.3.2 応用例:MCMCによるサンプリングの改善
Proposition 3の2番目のレシピ「発散ゼロ成分の追加」が、実際にどのように機能するのか、2つの有名なMCMCアルゴリズムを例に見てみましょう。これらのアルゴリズムは、与えられた分布
-
例1: ランジュバン動力学 (Langevin Dynamics) (原著 §9.7, Eq. 9.38)
状態空間が\mathbb{R}^d p_t(x) dX_t = \frac{\beta_t^2}{2} \nabla \log p_t(X_t) dt + \beta_t dW_t -
何をしているか: この過程は、確率密度の高い方向へ向かうドリフト項(
\nabla \log p_t(x) dW_t -
なぜ発散ゼロなのか: このSDEに対応するジェネレータの随伴作用素(フォッカー・プランク演算子)を
p_t [\mathcal{L}_t^{\text{Langevin}}]^* p_t = 0 p_t -
GMでの活用: この事実により、我々は任意のGMモデル(フロー、ジャンプなど)のジェネレータ
\mathcal{L}_t \mathcal{L}_t^{\text{Langevin}} p_t
-
何をしているか: この過程は、確率密度の高い方向へ向かうドリフト項(
-
例2: メトロポリス・ヘイスティングス (Metropolis-Hastings)
より一般的な状態空間(離散空間を含む)では、メトロポリス・ヘイスティングスアルゴリズムが発散ゼロのジャンプ過程を構築する方法を提供します。これは、提案分布からのジャンプを、詳細釣り合い条件を満たすような採択確率で受け入れる/棄却する手続きです。Q_t(y,x)p_t(x) = Q_t(x,y)p_t(y) この条件を満たすジャンプ過程のジェネレータは、自動的に発散ゼロになります。したがって、どんなGMモデルにも、この種のメトロポリス的なジャンプを追加して、サンプリングを改善することが可能です。
6.3.3 マルチモーダルモデルへの道
GMの一般性は、状態空間が複数のモダリティの直積
6.4 この章のまとめ:フローマッチングの究極形へ
この章では、フローマッチングの考え方を極限まで一般化したジェネレータマッチング(GM)について学びました。
- GMは、任意のデータモダリティ(状態空間
\mathcal{S} - CTMPのダイナミクスは、その「ジェネレータ(生成作用素)」
\mathcal{L}_t - 確率パス
p_t \mathcal{L}_t - GMの学習は、ジェネレータの「パラメータ関数」
F_t(x) F_t(x|Z) - GMは、異なる種類のモデルの組み合わせや、マルチモーダルデータの生成も自然にサポートする。
GMは、フローマッチングが持つ柔軟性と強力さを最大限に引き出し、まさに「任意のデータ」を「任意の過程」で生成するための普遍的な設計図を提供します。これにより、これまで個別に研究されてきた多くの生成モデル(フロー、拡散、自己回帰など)を統一的な視点から理解し、それらを自在に組み合わせて新しいモデルを創造する道が開かれます。
次章では、このGMの視点から、特に重要なクラスのモデルである拡散モデル(および関連するノイズ除去モデル)がどのように位置づけられるのかを再訪し、フローマッチングと拡散モデルの関係性をより深く掘り下げます。
ここまでの議論のポイント:
- GMは任意のデータ・マルコフ過程を扱える究極のFM。
- CTMPはジェネレータ
\mathcal{L}_t \mathcal{L}_t -
p_t \mathcal{L}_t - GM学習は、ジェネレータのパラメータ関数
F_t(x) - モデルの組み合わせやマルチモーダル生成も可能。
第7章 フローマッチッチングと拡散モデル:共通点と相違点
この章のゴール:
フローマッチング(FM)と拡散モデル(Denoising Diffusion Models, DDM)は、現代の生成モデリングを牽引する二大パラダイムです。一見すると、それぞれ異なる理論的背景から発展してきたように見えますが、実は両者の間には深く、そして本質的な繋がりが存在します。この最終章では、これまで学んできたフローマッチング、そしてその一般化であるジェネレータマッチング(GM)の視点から、拡散モデルを再訪します。拡散モデルがどのようにFM/GMの特殊なケースとして位置づけられるのかを、時間パラメータの慣習、確率パスの構築、学習アルゴリズム、サンプリング手法、そして時間反転の役割という5つの重要な側面から徹底的に比較・分析します。この章を通じて、二つのアプローチが共通の数学的原理を共有していることを理解し、同時にフローマッチングがなぜより高い柔軟性と一般性を提供するのか、その理由を明らかにします。これは、個別のモデルを越えた、生成モデリングのより普遍的な原理を掴むための重要なステップとなるでしょう。
(原著の §10 "Relation to Diffusion and other Denoising Models" に相当する内容です。)
7.1 時間パラメータの慣習の違い (原著 §10.1)
フローマッチングと拡散モデルを比較する上で、最初に解消しておくべき混乱の元は、時間のパラメータ化に関する慣習の違いです。これは単なる表記上の問題ですが、両者の理論を結びつける上で非常に重要です。
-
フローマッチング(FM)の時間
t
本記事で一貫して用いてきたように、FMでは時間はt=0 t=1 -
t=0 p_0 -
t=1 p_1=q
-
-
拡散モデル(DDM)の時間
r
一方、多くの拡散モデルの論文では、時間は逆向きにパラメータ化されます。フォワードプロセス(ノイズ付加)はr=0 r=T r=+\infty r=0 r -
r=0 q -
r=+\infty
-
この2つの時間軸を対応させるために、単調減少する連続関数
ここで、相互変換に用いる関数
-
k(1) = 0 t=1 r=0 -
\lim_{t \to 0} k(t) = +\infty t=0 r=+\infty
この対応関係を念頭に置くことで、拡散モデルのフォワードプロセスや学習則を、フローマッチングの確率パスや損失関数として解釈することが可能になります。
7.2 フォワードプロセスと確率パス (原著 §10.2)
拡散モデルの根幹をなすのは、データ分布
ここで、
-
X_r r -
a_r(x) -
g_r -
W_r - 初期条件
X_0 q
このSDEは、時間とともにデータにノイズを付加していく過程を記述します。
さて、このフォワードプロセスは、フローマッチングの観点から見ると何に対応するのでしょうか?
答えは、「特定の確率パスを構築するための一つの具体的な方法」です。
第6章で学んだように、任意の連続時間マルコフ過程(このSDEもその一つ)は、確率パスを定義します。具体的には、
-
条件付き確率パス
\tilde{p}_{r|0}(x|z) X_0=z r X_r P(X_r=x|X_0=z) -
周辺確率パス
\tilde{p}_r(x) X_0 \sim q r X_r P(X_r=x)
チルダ ~ 表記について
以降、混乱を避けるために、
- 拡散時間
r ~を付けて表記
(\tilde{p}_r, \tilde{\alpha}_r, \tilde{\sigma}_r - フローマッチング時間
t
(p_t, \alpha_t, \sigma_t
することで両者を区別します。
これらをFM時間
7.2.1 アフィン・ドリフトとガウスパス
拡散モデルの理論と実践において特に重要なのは、フォワードSDEが解析的に解ける場合です。これは主に、ドリフト項
このとき、SDEの解である条件付き確率パス
ここで、
この式をFM時間
となります。ただし、
この式は、我々が第3章の§3.7.1で議論したフローマッチングにおける「ガウス確率パス」と全く同じ形をしています。
つまり、以下の重要な結論が得られます。
拡散モデルで一般的に用いられるフォワードプロセス(アフィン・ドリフトを持つSDE)は、フローマッチングにおけるガウス確率パスを構築する一つの方法に他なりません。
したがって、拡散モデルは、フローマッチングの枠組みの中で、特定の確率パス(ガウスパス)を選択した場合として捉えることができます。
7.3 学習:ノイズ除去スコアマッチングはフローマッチングの一種 (原著 §10.3)
次に、モデルの学習方法を比較します。拡散モデルは、「ノイズ除去スコアマッチング(Denoising Score Matching, DSM)」という損失関数を用いて学習されます。これは、ノイズが加わったデータ
一方、フローマッチングは、速度場
驚くべきことに、拡散モデルのDSM損失は、フローマッチングの特定のCFM損失と等価であることが示せます。
原著では、FMの損失として「
まず、
モデル
ここで、
この損失関数は、以下の2つのステップでDSM損失と等価な形に変形できます。
(i) ネットワークの再パラメータ化:
まず、学習するネットワークを
この関係を用いることで、ネットワークの出力をスコアとして解釈し直すことができます。
(ii) 損失の変形:
次に、最適解の性質を利用します。
また、ノイズ除去スコアマッチングのターゲットとなるスコアは、条件付き分布のスコア
となります。
モデルのスコア予測
この関係から、元の
原著では、この関係性を利用して、
結論として、拡散モデルの学習アルゴリズム(ノイズ除去スコアマッチング)は、フローマッチングの枠組みにおいて、以下の特定の条件下での学習と等価です。
- 確率パス: ガウス確率パス(アフィン・ドリフトを持つSDEから導かれる)を用いる。
-
パラメータ化: 速度場をスコア関数で再パラメータ化する(または
x_0
これは、フローマッチングがいかに拡散モデルの学習を自然に包含しているかを示す、非常に強力な結果です。
7.4 サンプリング:確率フローODEとSDE (原著 §10.4)
次に、学習済みモデルからのサンプリング方法を比較します。拡散モデルでは、主に2種類のサンプリング手法が用いられます:決定論的なODEサンプリングと確率的なSDEサンプリングです。これらもまた、FM/GMのサンプリング手法の特殊ケースとして理解できます。
7.4.1 決定論的サンプリング(ODE)
拡散モデルからの決定論的サンプリングは、「確率フローODE(Probability Flow ODE)」を解くことで行われます。これは、フォワードSDE (10.4) と同じ周辺分布
このODEを、学習されたスコア関数
このプロセスをフローマッチングの視点から見てみましょう。
FMでは、学習された周辺速度場
これら二つのODEは、時間再パラメータ化
まず、確率フローODEをFM時間
となります。右辺が、FMの速度場
この式は、第3章で見た、ガウスパスの場合の周辺速度場とスコア関数の関係式(原著 Eq. 4.78, 10.11)と一致します。
したがって、拡散モデルの確率フローODEによるサンプリングは、フローマッチングにおけるODEサンプリングと完全に等価です。
7.4.2 確率的サンプリング(SDE)
拡散モデルのもう一つのサンプリング方法は、フォワードSDE (原著 Eq. 10.4) を時間反転させた「リバースSDE」を解くことです。このリバースSDEもまた、学習されたスコア関数を用いてシミュレーションされます。
一方、第6章の「6.3.2 応用例:MCMCによるサンプリングの改善」(原著 §9.7)で、任意のCTMP生成モデルに「ランジュバン動力学」を追加できることを見ました。これは、決定論的なフローに確率的なノイズ項を加えることに相当します。
確率フローODEにランジュバン動力学を追加したSDEは、以下のようになります(原著 Eq. 10.15)。
ここで
拡散モデルのリバースSDEは、この一般化されたSDEにおいて、特定のノイズ強度
したがって、拡散モデルのSDEサンプリングは、ジェネレータマッチングの枠組みで、確率フローに特定のランジュバン動力学を追加したサンプリング手法と等価です。
GMの視点からは、追加するノイズの強さ
7.5 時間反転の役割:必要か、十分か? (原著 §10.5)
拡散モデルの理論では、「時間反転(Time Reversal)」の概念が中心的な役割を果たします。サンプリング過程(リバースプロセス)は、ノイズ付加過程(フォワードプロセス)を時間反転させることで数学的に導出されます。
この時間反転の考え方は、フローマッチングやジェネレータマッチングの文脈ではどのように捉えられるのでしょうか?
まず、原著の表記に従い、拡散モデルが学習しようとする「リバースプロセス」を
拡散モデルにおける「時間反転」には、実は2つの異なるレベルの要求が存在します。
-
周辺分布の一致(Marginal Reversal): リバースプロセス
\bar{X}_r X_r r \in [0, R] \bar{X}_r \stackrel{d}{=} X_{R-r} が成り立つことです。ここで
\stackrel{d}{=} \bar{X}_r \tilde{p}_{R-r} -
厳密な時間反転(Strict Time Reversal): 単に各時点での周辺分布が一致するだけでなく、過程全体の同時分布が一致すること。
この2つの概念を念頭に置き、3つの等価な問題設定を比較してみましょう。
-
周辺分布の時間反転 (Time-reverse marginals):
- フォワードプロセス
X_r \tilde{p}_r \bar{X}_r \sim \tilde{p}_{R-r} \bar{X}_r - 拡散モデル(DDM)のアプローチ。
- フォワードプロセス
-
確率パスの生成 (Generate probability path):
- ターゲットとなる確率パス
p_t \tilde{p}_{k(t)} - フローマッチング(FM)のアプローチ。
- ターゲットとなる確率パス
-
KFEを解く (Solve KFE):
- 確率パス
p_t - ジェネレータマッチング(GM)のアプローチ。
- 確率パス
これら3つの問題は、実質的に同じゴールを目指しています。それは、「所望の周辺分布の系列(=確率パス)をたどるようなダイナミクスを見つける」ということです。時間反転は、この問題を解くための強力な一つのツールですが、唯一の方法ではありません。
次に、より強い条件である「厳密な時間反転」について考えます。これは、拡散モデルのオリジナルの理論(Anderson, 1982)で議論されている概念で、任意の時間点の集合
この式が意味するのは、リバースプロセス
しかし、生成モデリングの多くの応用では、最終的なサンプル
この観点から見ると、厳密な時間反転は、生成モデリングの目的を達成するためには過剰な制約である可能性があります。
有名な例が、前節で見た確率フローODEです。確率フローODEを解いて得られるリバースプロセスは、一般にフォワードSDEの厳密な時間反転ではありません(つまり、同時分布は一致しない)。しかし、それはフォワードSDEと全く同じ周辺分布を生成し(つまり、周辺分布の一致は満たす)、かつSDEサンプラーよりも少ないステップ数で高品質なサンプルを生成できることが多く、現在の最先端手法となっています。
これは、厳密な時間反転という「より難しい数学的問題」を解くことが、必ずしも実用上最良の結果をもたらすとは限らないことを示唆しています。FM/GMの枠組みは、この「厳密な時間反転」という制約から解放され、同じ確率パスを生成する多様なダイナミクス(ODEやSDEのファミリー)の中から、より効率的なものを選択する自由を提供します。重要なのは、どの方法を選んでも「周辺分布の一致」という生成モデルの基本的な要件は満たされるという点です。
7.6 その他のノイズ除去モデルとの関係 (原著 §10.6)
拡散モデルの成功に触発され、リーマン多様体上のデータや、その他のモダリティ(テキスト、グラフなど)に対しても、「フォワードプロセスでノイズを加え、それを時間反転させて復元する」というアプローチを取る「ノイズ除去モデル(Denoising Models)」が数多く提案されてきました。
これらのモデルとGMの関係は、これまで見てきたDDMとFM/GMの関係と全く同じです。
一般的に、これらのノイズ除去モデルは、特定のGMモデルとして以下のように特徴づけることができます。
-
時間パラメータの慣習: DDMと同様に、時間が
0 - 確率パスの構築: 「フォワード」または「ノイズ付加」過程を設計することで、暗黙的に確率パスを定義する。
- KFEの解法: 対応するKFE(またはその離散版)を解くための一つの特定の方法として、フォワードプロセスの「時間反転」を用いる。
GMのフレームワークは、これらのモデルを個別のトリックの集まりとしてではなく、統一的な原理(確率パスの設計とジェネレータの学習)に基づいた、広大なモデル空間の中の特定の点として理解することを可能にします。これにより、異なるモデル間の比較や、新しいモデルの設計がよりシステマティックに行えるようになります。
7.7 まとめ:統一的な視点からの再訪
この章では、フローマッチング(FM)と拡散モデル(DDM)の関係性を、FMの一般化であるジェネレータマッチング(GM)の視点から深く掘り下げました。両者は別々の道を歩んできたように見えますが、その根底には共通の原理が流れています。
- 拡散モデルはFM/GMの特殊ケース: DDMで用いられる時間パラメータ、フォワードプロセス(ガウスパス)、学習則(ノイズ除去スコアマッチング)、サンプリング手法(確率フローODE、リバースSDE)はすべて、FM/GMの枠組みにおける特定の選択肢に対応する。
-
FM/GMはより高い柔軟性を提供: FM/GMは、確率パスの設計、学習ターゲット(速度場、スコア、
x_0 - 時間反転の再評価: DDM理論で中心的な時間反転は、所望の確率パスを生成する過程を見つけるための強力なツールの一つですが、唯一の、あるいは常に最良の方法とは限りません。FM/GMは、この制約から解放された、より広い視野を提供する。
結論として、拡散モデル(DDM)は、ジェネレータマッチング(GM)という広大なフレームワークの中で、特定の(しかし非常に強力で効果的な)設計選択を行った、輝かしい成功例であると位置づけることができます。FM/GMは、DDMの成功の根底にある原理を抽出し、それをより柔軟で拡張性の高い形で提供することで、次世代の生成モデリングの新たな地平を切り拓いています。
ここまでの議論のポイント:
- FM/GMとDDMは深く関連し、DDMはGMの特殊ケースと見なせる。
- DDMのフォワードプロセスは、FMのガウスパス設計に対応する。
- DDMのスコアマッチング学習は、FM/GMの特定の条件下での学習と等価。
- DDMのサンプリング手法(ODE/SDE)も、FM/GMのサンプリングの特殊ケースとして理解できる。
- 時間反転はDDMの強力な指針だが、FM/GMの枠組みでは必須ではない。FM/GMはより柔軟な設計を許容する。
おわりに
本記事では、Meta AIの包括的なガイド「Flow Matching Guide and Code」を道しるべとして、フローマッチングという新時代の生成モデリングパラダイムの核心に迫りました。
- 第1章では、フローマッチングの基本的なアイデアと、拡散モデルとの関係性を概観しました。
- 第2章では、フロー、速度場、ODE、プッシュフォワード、連続の方程式といった、FMを支える数学的基盤を整理しました。
- 第3章では、FMの学習アルゴリズムの核心である「周辺化トリック」と、最適輸送に動機付けられた線形条件付きフローの重要性を学びました。
- 第4章では、FMをリーマン多様体という複雑な幾何学的空間へ拡張し、測地線フローやプレメトリックフローといった概念に触れました。
- 第5章では、FMを離散状態空間へと拡張する離散フローマッチング(DFM)と、そのための因子化パスや混合パスのアイデアを見ました。
- 第6章では、FMを究極的に一般化するジェネレータマッチング(GM)という統一的枠組みを導入し、任意のデータとマルコフ過程を扱える可能性を探りました。
- 第7章では、FM/GMと拡散モデル(DDM)の関係性を詳細に比較し、両者がどのように共通の原理を共有しつつ、FM/GMがより柔軟な設計を可能にするのかを理解しました。
フローマッチングは、ソース分布からターゲット分布への連続的な変換を学習するという、直感的でありながら強力なアイデアに基づいています。シミュレーションフリーな学習、柔軟な確率パス設計、多様なデータモダリティへの適用可能性といった利点から、画像、動画、音声、テキスト、さらには科学的発見に至るまで、幅広い分野での応用が進んでいます。
本記事が、読者の皆様にとってフローマッチングという魅力的な世界への第一歩となり、Meta AIのガイドや関連論文を読み解く上での助けとなれば幸いです。生成AIの旅はまだ始まったばかりです。フローマッチングが切り拓く新たな可能性を、ぜひご自身の目で確かめてみてください。
関連リソース
記事
-
要約:Flow Matching for Generative Modeling (Part 1)
Qiita 記事。定理の証明を含め FM の数理を日本語で丁寧に整理し、実装イメージを掴みやすくしてくれる。(qiita.com) -
Optimal Transport Conditional Flow Matching – 拡散モデルに取って代わる次世代の生成技術?
OT-CFM を図解付きで紹介する日本語 Zenn 記事。条件付き生成まで扱う応用視点が充実。(zenn.dev)
論文
-
Flow Matching for Generative Modeling
FM の原点論文。シミュレーション不要のベクトル場回帰で CNF を学習し、OT 経路で高速化・高品質生成を実現する方針を提案。(arxiv.org) -
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
“直線フロー”を学習して 1-step 生成に迫る高速変種。FM の速度場を直線経路に制限する利点と理論的根拠を解説。(arxiv.org) -
Discrete Flow Matching
高次元離散データ(コード生成など)に FM を拡張。確率経路スケジューラと大規模モデル実験で離散拡散との差を検証。(arxiv.org) -
Generator Matching: Generative modeling with arbitrary Markov processes
FM/拡散モデルを包括する GM の提案。無限小生成作用素を直接回帰し、ジャンプ過程のスーパー ポジションで多モーダル生成と性能向上を実証。(arxiv.org) -
α-Flow: A Unified Framework for Continuous-State Discrete Flow Matching Models
情報幾何に基づき CS-DFM を統一し、一般化運動エネルギー最小化の観点を提示する最新理論。(arxiv.org)
Youtube 動画
-
【AI論文解説】Consistency ModelsとRectified Flow ~解説編Part1~
Consistency Models と Rectified Flow に関する最新の研究動向を、スライドとともに解説した動画。理論的背景や実装のポイントを視覚的に整理。(youtube.com) -
How I Understand Flow Matching
ホワイトボード形式で FM と拡散モデルの関係を直感的に可視化し、要点をスッキリ整理。初心者向け。(youtube.com)
実装チュートリアル
-
facebookresearch/flow_matching
本記事で扱ったMeta AIの「Flow Matching Guide and Code」(arXiv.org) の公式 PyTorch 実装。連続/離散 FM の学習・サンプリングスクリプトと画像/テキストのデモを収録。(github.com) -
MIT 6.S184 “Flow & Diffusion Models” オンライン教材
FM/拡散モデルを体系的に学べる講義ノート+ Colab 演習。数式とコードを往復しながら手を動かせる。(diffusion.csail.mit.edu)
Discussion