論文の概要
Difference-in-Differences Designs: A Practitioner's Guideは、社会科学における因果効果の推定で広く使われる「差分の差分法(Difference-in-Differences, DID)」について、実践者向けにその考え方と応用を解説する論文です。
特に、従来の2期間・2グループという単純なケースを超えて、複数の期間や、異なるタイミングで処置が導入されるStaggered treatmentといった、より複雑な現実のデータにDIDを適用する際の課題と、その解決策について説明しています。
論文の中心的な主張は、複雑なDID分析も、基本的な「2期間・2グループ」の分析の組み合わせ(building blocks)として理解できるという点です。この考え方に基づき、明確な因果関係の解釈が可能な推定方法を構築するフォワード・エンジニアリングアプローチを提案しています。
この論文を三つのブログに分けて紹介していく予定です。本ブログはそのPart1となります。
メディケイド拡大と死亡率
この論文では、議論を具体的にするために、一貫して以下の例が用いられます。
- 研究課題: 低所得者向けに医療費を援助するメディケイドの拡大が、死亡率にどのような影響を与えたか?
-
分析の特徴:
- Staggered treatment: メディケイド拡大は、州によって開始年が異なります。(2014年から2023年にかけて段階的に導入)
- データ: 郡レベルの死亡率データ(2009年〜2019年)を使用します。
- 課題: どのグループを比較対象とするか、地域差などの共変量をどう扱うか、といった分析上の選択が重要になります。

2\times2
まず、DIDの最も基本的な形である「2期間・2グループ」のデザインについて説明します。
- 2グループ: 処置を受けるグループ(処置群)と、受けないグループ(対照群)
- 2期間: 処置が導入される前の期間(処置前)と、導入された後の期間(処置後)
メディケイドの例で言えば、以下のような状況です。
- 処置群: 2014年にメディケイドを拡大した州の郡
- 対照群: 2019年まで拡大しなかった州の郡
- 処置前: 2013年
- 処置後: 2014年
DIDの推定値は、「処置群での処置前後の変化」から「対照群での処置前後の変化」を差し引くことで計算されます。この背景には、「もし処置がなければ、処置群と対照群の死亡率のトレンドは同じだったはずだ(平行トレンド仮定)」という重要な仮定があります。
Causal effects and target parameters: The ATT
DIDで何を推定したいのかを明確にするため、Potential Outcomesという考え方を使います。
-
Y_{i,t}(1) i t -
Y_{i,t}(0) i t
現実には、あるユニットがある時点で処置を受けるか受けないかのどちらか一方しか観測できません。観測される結果
-
Y_{i,t} i t -
D_{i,t} - 処置を受けなかった場合(
D_{}=0 Y_{i,t}(0) D_{i}=1 Y_{i,t}(1)
No-Anticipation Assumption
DIDを正しく適用するための重要な仮定として、No-Anticipationがあります。これは、「処置が実施されるより前の時点では、処置の効果は現れない」という仮定です。例えば、メディケイド拡大が2014年に発表・実施されるとして、その発表によって2013年の死亡率が変化するようなことがない、ということを意味します。
処置群における平均処置効果 (ATT)
DIDが推定しようとする中心的な目標は、処置を受けたグループにおける平均的な処置の効果です。これは以下の数式で定義されます。
この式は、以下のように変形できます。
-
ATT(t) t -
\mathbb{E}[\cdot | D_i = 1] D_i=1 -
第1項
\mathbb{E}[Y_{i,t} | D_i = 1] -
第2項
\mathbb{E}[Y_{i,t}(0) | D_i = 1]
DIDの本質は、この観測できない第2項を、対照群のデータを使ってうまく推定することにあります。この論文では、ATTを推定する際に、単純な平均を取るか、人口などで重み付け(加重)した平均を取るかによって、推定されるパラメータの意味合いが変わる点も指摘しています。
Identifying assumptions: Parallel trends
前のセクションで、処置群の平均処置効果(ATT)を推定するには、観測不可能な反実仮想
仮定 PT(Parallel Trends) (2×2 平行トレンド)
処置がない場合、処置群と対照群における潜在的結果
-
\mathbb{E}_{\omega} \omega - 左辺: 処置群において、「もし処置がなかったとしたら」、時点2と時点1の間で死亡率がどれだけ変化したか、という平均変化量です。これは観測できません。
- 右辺: 対照群において、時点2と時点1の間で死亡率がどれだけ変化したか、という平均変化量です。対照群は処置を受けていないので、これはデータから観測できます。
この仮定は、「処置群で観測できなかった『もしも』の変化は、対照群で実際に観測された変化と同じである」と仮定することを意味します。この仮定が成り立つと、観測できない反実仮想を以下のように計算できます。
メディケイドの例でいえば、処置群の処置後の反実仮想(左辺)は、「処置群の処置前の死亡率」に「対照群で観測された死亡率の時間変化」を足し合わせることで推定できるということを示しています。これらの式を組み合わせることで、ATTを完全に観測可能なデータだけで表現できます。これがDIDの推定量です。
Estimation and inference: Four means or one regression?
手計算によるDID
前セクションで紹介したATTは4つのグループ平均を計算して差を取ることで、ATTを推定できます。
Table 2 には、この計算が具体的に示されています。

- 非加重(Unweighted)の場合: 処置群の変化は +9.3、対照群の変化は +9.1。その差(DID推定量)は +0.1となります。これは「メディケイド拡大は、拡大した『郡』の死亡率を10万人あたり0.1人増加させた」と解釈されますが、統計的に有意ではありません。
- 加重(Weighted)の場合: 処置群の変化は +3.7、対照群の変化は +6.3。その差(DID推定量)は-2.6となります。これは「メディケイド拡大は、拡大州の『住民』の死亡率を10万人あたり2.6人減少させた」と解釈でき、統計的に有意です。
回帰分析によるDID
DIDは、以下の回帰モデルを最小二乗法(OLS)で推定することでも得られます。
-
Y_{i,t} i t -
\mathbf{1}\{D_i=1\} -
\mathbf{1}\{t=2014\} -
\mathbf{1}\{D_i=1\} \times \mathbf{1}\{t=2014\} - このモデルでは、交互作用項の係数
\boldsymbol{\beta_{2 \times 2}} -
\epsilon_{i,t}
このモデルから得られる4つの平均値は以下のように表現できます:
- 処置群の処置後(2014年)の平均:
Y_{D=1,t=2014} = \hat{\beta_0} + \hat{\beta_1} + \hat{\beta_2} + \hat{\beta_{2 \times 2}} - 処置群の処置前(2013年)の平均:
Y_{D=1,t=2013} = \hat{\beta_0} + \hat{\beta_1} - 対照群の処置後(2014年)の平均:
Y_{D=0,t=2014} = \hat{\beta_0} + \hat{\beta_2} - 対照群の処置前(2013年)の平均:
Y_{D=0,t=2013} = \hat{\beta_0}
これらの式を
となります。
Table 3 は、この回帰分析の結果を示しており、手計算の結果と一致することを確認できます。

Incorporating covariates into 2×2 DID
これまでの議論では、処置群と対照群を直接比較してきましたが、実際にはこれらのグループ間で元々特性が異なる場合があります。例えば、メディケイドを拡大した州とそうでない州では、貧困率や人種構成が元から異なっているかもしれません。このような共変量の違いが、処置がなくても死亡率のトレンドに影響を与える可能性があります。
このセクションでは、共変量を分析に組み込むこんだDID分析について紹介しています。
Covariate balance: Is unconditional parallel trends plausible?
DID分析を行う前段階として、処置群と対照群が処置開始前にどれだけ似ているかを確認するバランスチェックが非常に重要です。そこで正規化差を用います。正規化差は、単位に依存せず、変数のばらつきを考慮したグループ間の差を示す指標です。
正規化差の計算式
-
\bar{X}_{\omega,T} -
\bar{X}_{\omega,C} -
S^2_{\omega,T} -
S^2_{\omega,C}
この式の構造を分解してみましょう。
-
分子 (
\bar{X}_{\omega,T} - \bar{X}_{\omega,C} - これは処置群と対照群の平均値の差です。単純な差であり、これが正規化の対象となります。
-
分母 (
\sqrt{(S^2_{\omega,T} + S^2_{\omega,C})/2} - これは処置群と対照群の標準偏差をプールしたものです。
- まず、両群の分散 (
S^2 - この分母は、その共変量が平均的にどれくらいばらついているかを示す指標となります。
つまり、正規化差は「両群の平均値の差が、プールされた標準偏差の何倍あるか」を示しています。正規化差の絶対値が 0.25 を超える場合、グループ間に潜在的に問題となる不均衡が存在する可能性を示唆します。これはあくまで経験則であり、絶対的な基準ではないみたいです。
論文のTable 4では、この正規化差が実際に計算されています。
-
上段 (2013 Covariate Levels):
- 例えば「Unemployment Rate」の非加重(Unweighted)の正規化差は
0.16 - 一方、Median Incomeの正規化差は
0.43 0.25
- 例えば「Unemployment Rate」の非加重(Unweighted)の正規化差は
-
下段 (2013-14 Covariate Differences):
- ここでは、共変量の変化量について正規化差を計算しています。
- 例えば、Unemployment Rateの変化量の正規化差は
-0.21
このように正規化差を計算することで、処置群と対照群の比較する際に、どの共変量が問題になる可能性があるかを評価する材料となります。
Table 4 は、メディケイドの例における共変量のバランスを示しています。

DID with covariates: Identification under conditional parallel trends
共変量のインバランスがある場合、より弱い仮定である条件付き平行トレンド仮定:Conditional Parallel Trends, CPTを用います。
仮定 CPT (2×2 条件付き平行トレンド)
同じ共変量の値を持つ処置ユニットと比較ユニット間で、
仮定CPTは仮定PTと同じ構造を持ちますが、PTが全人口・ユーザーに対して成り立つのに対し、CPTは各共変量固有の層(covariate-specific stratum)内で成り立つと仮定します。
メディケイド例での解釈: Table 4のベースライン共変量に関して、この仮定は2013年時点で同じ女性・白人・ヒスパニック比率、失業率・貧困率・所得中央値を持つ拡大郡と非拡大郡間で、
CPTは、共変量固有のトレンドが拡大郡と非拡大郡で共通であることのみを要求します。
仮定 SO (Strong Overlap)
未処置潜在アウトカム成長の決定要因である観測共変量
仮定CPTの両方の期待値が全ての
ATT(2)の識別
仮定CPTとSOの下で、ATT(2)は識別されます:
- 第1行: ATT(2)の定義を再記述
-
第2行: 繰り返し期待値の法則を用いて、処置群全体の反実仮想平均を
X_i - 第3行: 仮定CPTを用いて、反実仮想を予期なし仮定(Assumption NA)の下での観測可能な人口量として書き直し
-
第4行: 再度繰り返し期待値の法則を用いて項をグループ化し、ATT(2)を観測変数
(Y_{i,t=2}, Y_{i,t=1}, G_i, X_i)
ATT(2)は処置群が経験したアウトカムの変化(左辺の項)から、各共変量値に対する比較群のアウトカム変化を処置群の共変量分布で平均したもの(右辺の項)を差し引いた値に等しいということです。
DID estimation with covariates: TWFE
基本的なDID分析から一歩進んで、共変量(分析対象の個人や地域が持つ、介入以外の特性。例:年齢、性別、所得など)を考慮に入れるこんだDID分析について紹介しています。しかし、共変量が連続変数であったり、数が多かったりすると、単純なグループ分けと平均値の比較では対応が難しくなります。そのため、実務では回帰分析を用いるのが一般的です。特に、TWFEモデルは簡単で馴染み深いため、非常によく使われます。
TWFEモデルの基本形
典型的なTWFEの回帰モデル式は以下のように表されます。
-
Y_{i,t} i t -
\theta_t t -
\eta_i i -
D_{i,t} -
\beta_{treat} -
X'_{i,t} -
\beta_{covs} -
e_{i,t}
時間とともに変化する共変量
このモデルは、共変量のベースラインでの値が、介入後の結果のトレンドにどう影響するかをコントロールしようとするものです。
論文では米国のメディケイド拡大が死亡率に与えた影響を共変量を入れて分析した例を紹介しています。表5

上記のようにどの共変量をどのようにモデルに含めるかによって、推定結果が大きく変わってしまうこともあります。したがって、回帰分析で推定された係数
TWFEモデルの問題点と解釈の難しさ
TWFEモデルは実務でよく使われる一方で、重要な理論的課題を抱えています。特に、共変量を組み込むと、推定係数
TWFEの2つのモデル
TWFEモデルには、共変量の扱い方によって主に2つの形式があります。どちらを選ぶかによって、何をコントロールしているのかが大きく変わってきます。
モデル1:
- 基本的な考え方:各観測単位について、期間1から期間2への変化量を直接分析する
-
主な特徴:時間不変変数(個人固定効果
\eta_i
モデル2:
-
基本的な考え方:ベースライン時点(
t=1 - 主な特徴:ベースライン特性を保持し、それらが時間経過とともに結果変数に与える異質的な影響を調整
この2つのモデルの違いをまとめると以下のような感じになると思います。貧困率をコントロールしたいと考えた場合:
モデル1の場合:貧困率の変化(
- 例:「2013年から2014年にかけて貧困率が3%上昇した地域」の効果をコントロール
モデル2の場合:ベースライン貧困率(2013年時点)をコントロール
- 例:「2013年時点で貧困率が20%だった地域」の効果をコントロール
同じ貧困率をコントロールでも、実際には全く異なる要因をコントロールしており、推定結果も大きく変わる可能性があります。
TWFEモデルの根本的問題
TWFEで推定される
共変量の変化
条件付き平行トレンドとStrong Overlapが成り立つと仮定すると:
この計算から分かるように、
共変量コントロールがもたらす具体的なリスク
共変量を不適切にモデルに含めることで、以下のような問題が生じる可能性があります。
1. 時間不変変数の脱落
モデル1では
例えば、メディケイド拡大研究において、各州の恒常的な医療リソース格差は差分で消えてしまうため、これらが死亡率トレンドに与える影響を直接コントロールできません。
2. Bad Controls問題
処理自体が共変量
例えば、メディケイド拡大が貧困率を下げる効果があるとき、拡張後(2014年)の貧困率や2013-2014年の貧困率変化をコントロールに含めると、メディケイド拡大の真の効果を過小評価してしまいます。
3. 重み付けと符号逆転の問題(Caetano & Callaway 2024)
TWFEの最も深刻な問題は、推定される
各共変量層での条件付き平均処理効果:
このように、TWFEモデルは便利である一方で、多くの落とし穴があることが分かります。次のセクションでは代替的手法について解説されています。
DID estimators with covariates that target the ATT(2)
この式は、介入グループの実際の変化(第1項)から、介入グループが非介入だった場合の条件付き期待値(第2項)を差し引いた形になっています。第1項は標準的な2×2デザインと同じで、サンプル平均
ここで紹介する3つの手法(RA、IPW、DR)は、いずれも条件付き並行トレンド仮定CPTとSOの下で、第2項をどのように推定するかによって区別されます。
1. 回帰調整(Regression Adjustment, RA)アプローチ
RAアプローチは、非介入グループの結果変化パターンを直接モデル化して、介入グループの反実仮想を予測する手法です。
推定手順:
ステップ1: 非介入グループ(
ステップ2: 推定したモデルを使って、すべての個人(介入グループを含む)について予測値
ステップ3: ATT(2)の識別式の第2項の内側の条件付き期待値
ステップ4: 第2項全体を以下のように推定します:
これは処置群の共変量値に対する予測値の加重平均、つまり処置群が非処置だった場合の予測される平均変化を表します。
ステップ5: 最終的なATT推定量は、第1項(介入グループの実際の平均変化)から第2項を引いて:
これを整理すると:
処置グループの実際の変化(
モデルが誤特定されている場合、結果として得られるRA推定量にバイアスが生じます。
2. 逆確率重み付け(IPW)アプローチ
RAが結果をモデル化したのに対し、IPWは誰が処置を受けるかの確率(傾向スコア)をモデル化します。そして、この確率を使って非介入グループを重み付けし直し、介入グループと同じような特徴を持つ比較グループを作り出します。
介入グループと非介入グループで共変量の分布が異なる場合、単純に比較するとバイアスが生じます。そこで、非介入グループの中でも介入グループに似た特徴を持つ人により大きな重みを与えることで、バランスの取れた比較を実現します。
パネルデータが利用可能で、仮定CPTとSOの下で、以下のように表現できます:
ここで、重みは以下のように定義されます:
推定手順:
ステップ1: 全サンプルを使って、介入を受ける条件付き確率(傾向スコア)
ステップ2: 推定された傾向スコア
ステップ3: これらの重みを使ってATTを推定します:
重みの直感的理解:
IPWの課題と対策:
- 傾向スコア
\hat{p}_\omega(X_i) \hat{w}_{\omega,D=0}(D,X) - 実際には極端な傾向スコア(0.995以上など)を持つ観測値は除外(トリミング)することが推奨されます
- 下図のような傾向スコアの分布を確認し、介入・非介入グループ間で十分な重複があることを確認する必要があります
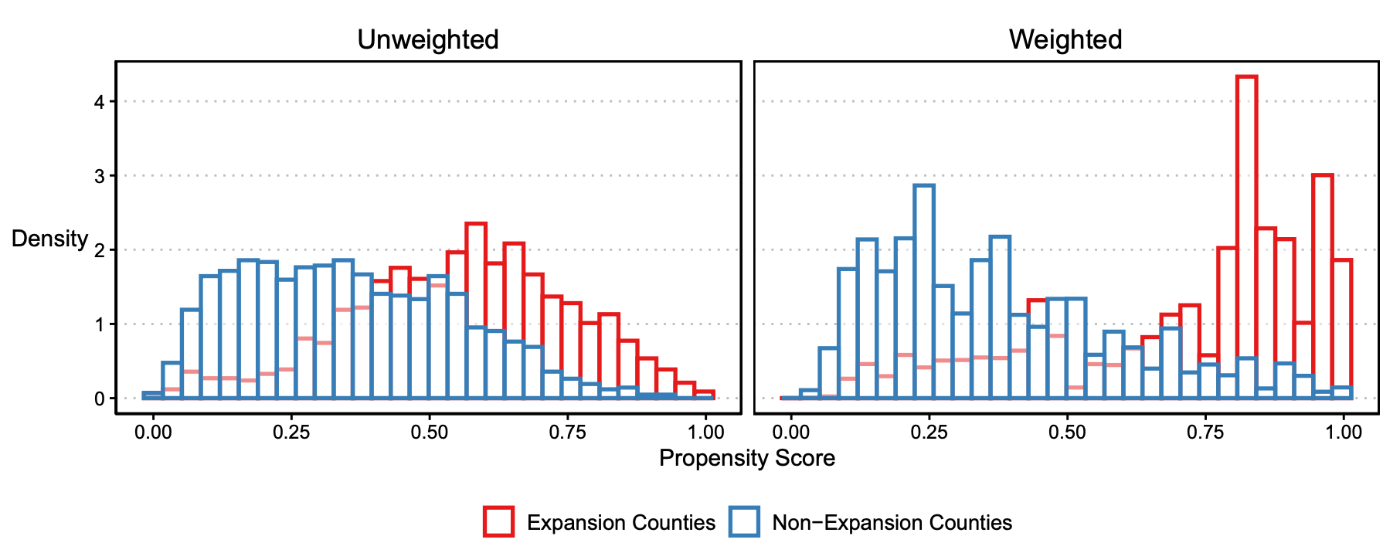
この図は、拡大州(赤)と非拡大州(青)の傾向スコア分布を示しています。対照群で極端に高い傾向スコアを持つ観測値が少なく、両グループの分布が良好に重複していることが確認できます。
3. 二重に頑健な(Doubly Robust, DR)アプローチ
DRアプローチは、RAとIPWのいいとこ取りをした手法です。
基本的な発想:RAは結果モデルが正しければ有効、IPWは傾向スコアモデルが正しければ有効です。DRは両方のモデルを組み合わせることで、どちらか一方でも正しければOKという頑健性を実現します。
この式は、IPWの重み付け構造(
推定量:
ここで、
「二重に頑健」の意味:
- 結果モデル(
\mu p - 逆に、傾向スコアモデルが正しければ、結果モデルが間違っていても一致推定量が得られます
- 両方が少し間違っていても、それらの誤差が乗法的に作用し、DR推定量は(漸近的に)どちらか単独よりも良い性能を示します
3つの手法の関係と実証結果
Table 6の実証結果
以下の表は、Sant'Anna and Zhao (2020)およびCallaway and Sant'Anna (2021)の推定量に含まれる回帰・傾向スコアモデルの結果を報告しています。最初の2列は非重み付け回帰の結果を報告し、後の2列は重み付け回帰モデルの結果です。回帰モデルは、2014年にMedicaidを拡大しない1,222郡について、2013年の共変量値の関数として結果変数(死亡率)の変化を予測しています。傾向スコアモデルは2013年の全2,200郡のデータを使用し、2013年の共変量レベルに基づく拡大指示変数のロジットモデルを推定しています。標準誤差(括弧内)は郡レベルでクラスター化されています。
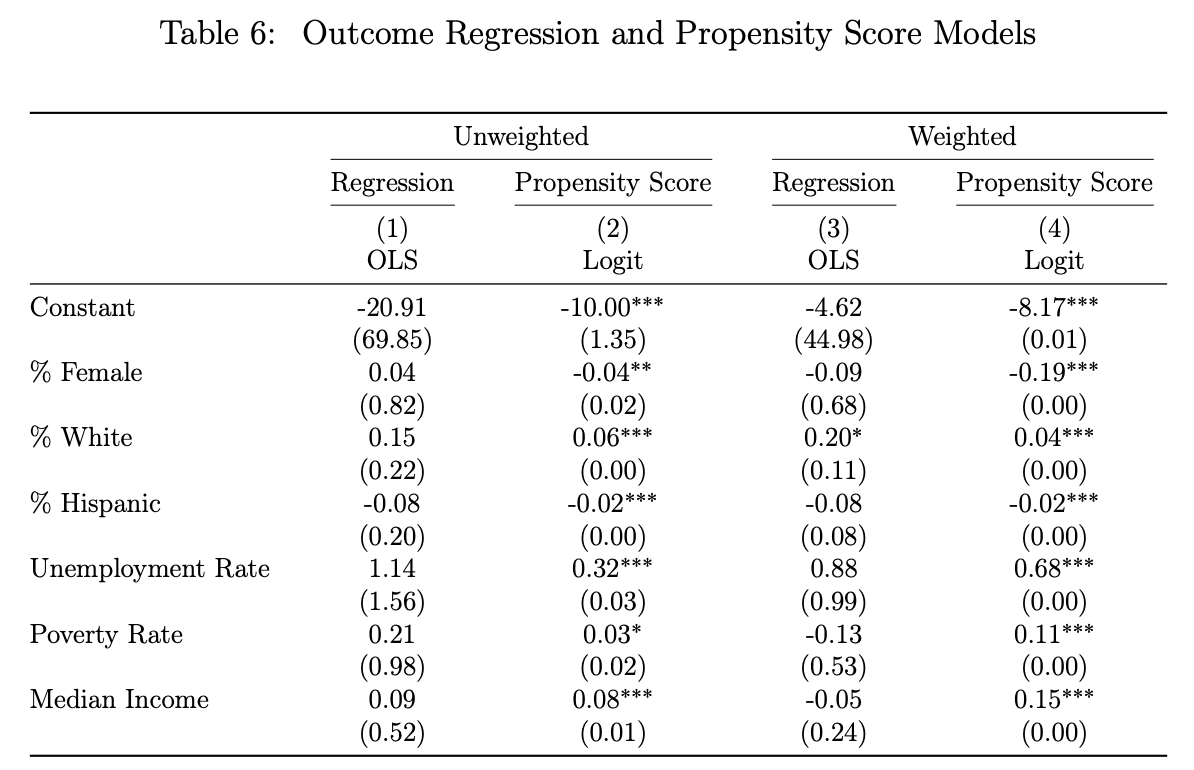
列1,3の解釈:
- 非拡大州における死亡率変化は基準共変量と弱い関係のみ
- 大部分の係数が統計的に有意でない→モデルが非介入結果トレンドをうまく説明できていない
列2,4の解釈:
- 多くの係数が統計的に有意
- 傾向スコアモデルが拡大決定をよく説明している
これは共変量は死亡率トレンドよりもMedicaid拡大をよく説明していると言えるのかなと思います。
Table 7の実証結果(Medicaid拡大の死亡率への影響):
第1列は回帰調整を使用した結果を報告し、第2列は含まれる共変量を使用した傾向スコアモデルに基づく逆確率重み付けを使用し、第3列は2つのアプローチの二重に頑健な組み合わせを使用している。標準誤差(括弧内)は郡レベルでクラスター化されている。
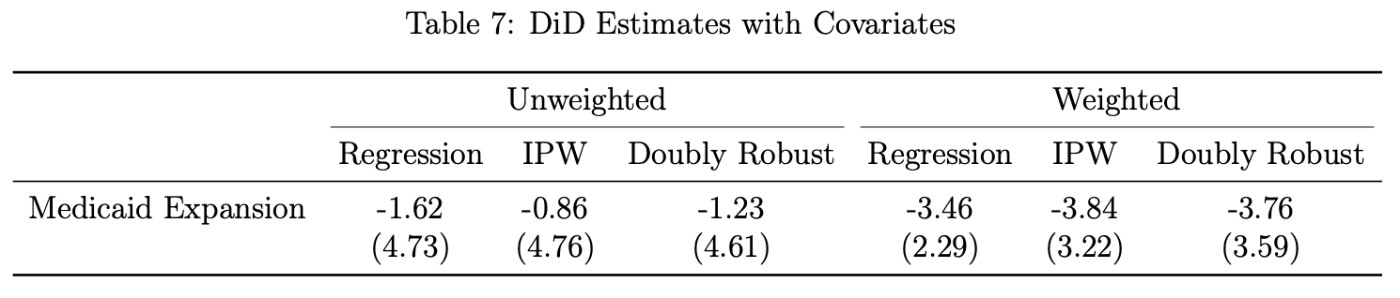
(解釈は表の通り。省略)
Heterogeneity analysis
共変量を使用する別の動機は、共変量の値
仮定CPTとSOにより、条件付きATTパラメータを識別することもできます:
離散共変量の場合
全ての共変量が離散的な場合、
分割の具体例:
共変量が「性別(男性/女性)」と「教育レベル(高校以下/大学以上)」の2つの離散変数だとします。この場合、以下の4つの分割グループを形成できます:
-
x_1 -
x_2 -
x_3 -
x_4
各分割
連続共変量または多数分割の場合
一部の共変量が連続的であるか、層が非常に多く各層の観測値が少ない場合でも、
このような場合、
この層別ATTの概念を形式化するため、PART
仮定CPTとSOの下で、以下が成り立ちます:
これにより、以下の集約関係が導かれます:
最後に
本ブログでは、DID分析の基礎である2×2デザインから、共変量を考慮した発展的な手法まで論文の前半部分について解説しました。
DID分析は一見シンプルに見えますが、実際の応用では多くの選択肢と注意点があることがわかったと思います。特に、共変量の扱い方や推定手法の選択によって結果が大きく変わる可能性があることを、メディケイド拡大の例を通じて確認しました。
Part2では、より複雑な設定におけるDID分析について解説します。

Discussion