こんにちは、Communeでデータサイエンティストをしているひぐです。
最近、LLMと周辺エコシステムの発展により、自律性と意思決定能力を持った"AIエージェント"の実現が現実味を帯びてきました。
例えば先日、sakana ai社から、AIが自律的にアイディアを複数案だして、実験内容を決定し、コードを修正した上で実験を回し、論文を書くようなシステムが発表されました。
AIエージェントは上手く組めば複雑なタスクを自律的に処理できるため、これまで規模が小さかったり、収益性が見込めなかった市場でも、人が介在せず、従来実現できなかった効率や少ないコストでタスクを完遂できるようになります。
つまり市場を新たに創出できる可能性があり、ビジネス観点でも非常に興味深い技術といえるでしょう。
一方で、AIエージェントの実装には、遅くて高コストで不安定なAPIを複雑につなぎ込む技術的な難しさや、開発エコシステムが発展中で選択肢が多いなかで、最適なアプローチを選ばないといけない技術選定の難しさなどに直面します。
本ブログは、そのような難しさに対応できる足がかりとなれるように、また魅力を理解していただけるように、以下の観点からAIエージェントの紹介をします。
- AIエージェントの定義
- AIエージェントがもたらすビジネス価値
- "技術ブログ自動生成エージェント"の実装例
- 主流ライブラリLangGraphとLangChainでの実装方法
- 実装を通じて得た所感
前半はビジネス的な側面、後半は実装的な側面について解説しています。興味のある箇所からお読みいただければ幸いです🙏
AIエージェントとは何か
まず、そもそもAIエージェントとは、何でしょうか。
AIエージェントを作成できるライブラリ、「LangGraph」のドキュメントではLLMのエージェントらしさ(Agentic)を”LLMがアプリケーションの制御フローを決定すること”と表現しています。
ここで制御フローとは、LLMが次に何をすべきか、利用できるツールからどれを使用すべきか、生成された回答が十分か、さらに作業が必要かの判断すること、などが挙げられています。
これらの決定をAI自身が行うことで、「AI自体が何をすべきか判断し、実行し、完遂するシステム」が実現します。
また、AIエージェントの自律性は段階的なものです。人間の介入度合いによって、その「エージェント性」はグラデーションを持ちます。自動運転車のレベル分けに似た考え方と言えます。
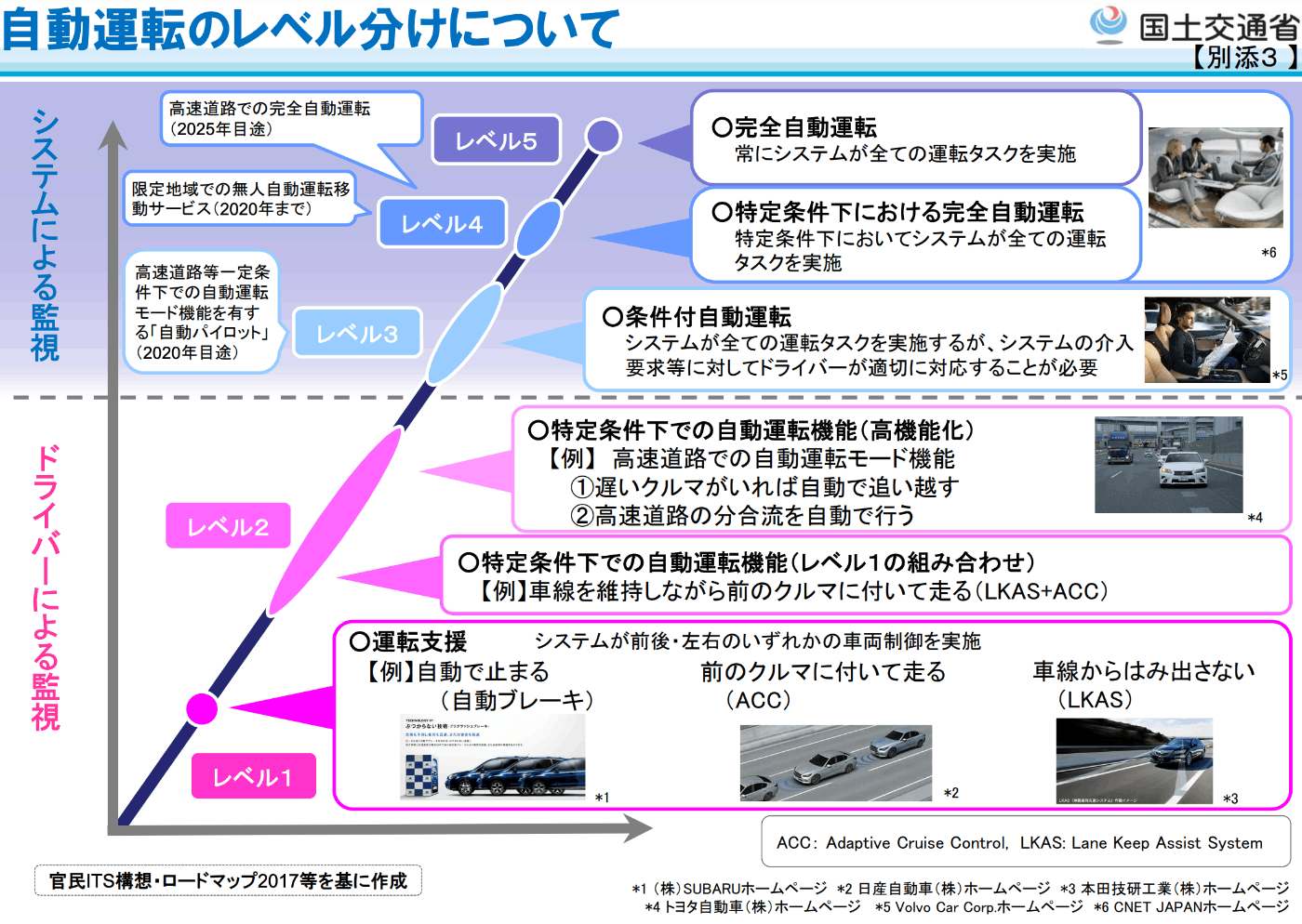
Agentic Workflows in 2024: The ultimate guideではAIエージェントのレベルを下記のように定義しています。
- レベル1(AIワークフロー): AIモデルが与えられた指示から出力を生成する際に決定を下す。
- レベル2(ルーターワークフロー): AIが事前定義された環境内でツールの選択やタスクの実行順序を決定する。
- レベル3(自律エージェント): AIがプロセス全体を制御し、独自のコードを書き、必要に応じてフィードバックを求める。
AIエージェントがもたらすビジネス価値
自律的なAIエージェントがビジネス上どのようなメリットをもたらすのでしょうか。
シリコンバレーを拠点とする著名なVC企業”Andreessen Horowitz”の記事で、次世代のB2B SaaSはよりAIが自律的な行動をする必要があると説明しています。
これまでのChatGPTのようなツールは、ユーザーがAIに情報を与え、それを元にAIが多数の情報を出力し、その情報を使い、人間がタスクを完遂するものでした。
今後はシステムがユーザのコンテキストに応じて適切な情報をバックグラウンドで収集し、タスクの完遂まで実現するようなシステムになるということです。
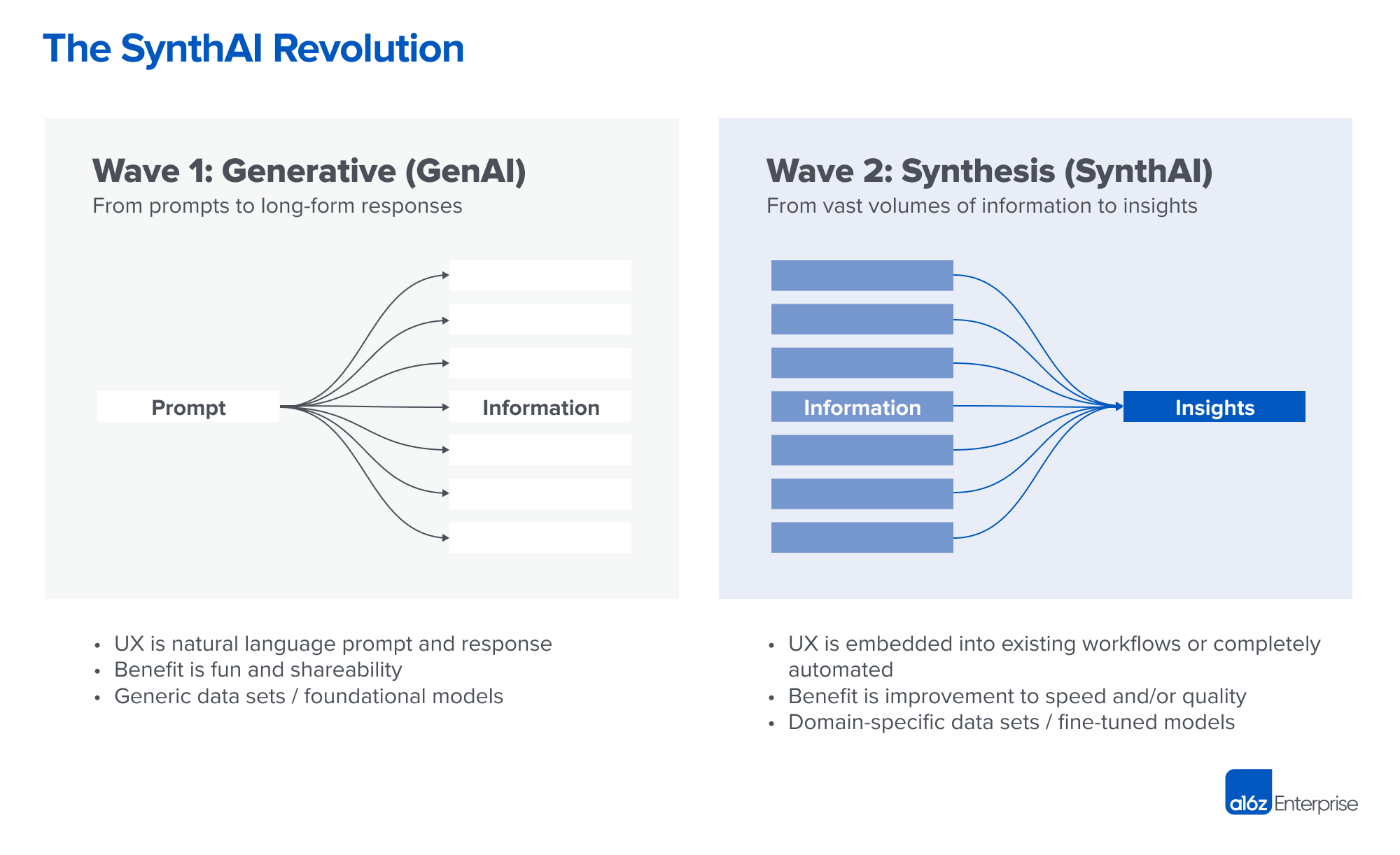
記事では、エージェンティックなAI活用例が紹介されています。
例えば、ホワイトボードツールFigJamは、ボード上の付箋を読み取り、ボタン一つでサマリを提供します。ドキュメントツールMacroは、複数人が非同期で編集したドキュメントの変更箇所をサマりし、最終案を提案します。
このようなシステムではより人間の介在が減り、少ない労力で多くの複雑なタスクを完遂できます。
また、ビジネスPodCast"Off Topic"の「「AIネイティブ」とは何か」の回では、AIがより進化することで、ビジネスモデル自体にもイノベーションが起こるという話をしていました。
従来のCopilot(副操縦士)的な考え方のAIツールは、従業員の効率性をどれだけ上げられるれるかで、プロダクトの値付けがされています。
購入の便益 ≒ 1従業員にかかるコスト * 生産性向上率という感じです。金額は1人あたり月額20ドルのように値付けされます。
一方で、AIが従業員の生産性向上ではなく、労働そのものを代替するのであれば、プロダクトは1人あたりいくらではなく、1作業いくらとプライシングの単位が変わります。
市場規模の変数が従業員の数から、業務の実行回数に変わることで、従来では収益性が見込めない市場でも新しくビジネスが出来るようになると言及しています。podcast内では、人身傷害弁護士の要求書簡の自動生成の例(=従業員換算の市場は小さいものの、タスクあたりの単価が高く、回数も多い)が紹介されていました。
このような複雑な業務自体を代替するには、人が介在せず、どのようなタスクをするべきかを選び意思決定する、いわゆるエージェンティックなAIである必要があります。
AIエージェントの実装のしかた
上記のようなAIエージェントはどのように実装できるのでしょうか?
例えば、前述の"AIが事前定義された環境内でツールの選択やタスクの実行順序を決定する"レベル2のワークフローを実装する場合、AIが利用できるツールを事前に提示し、利用するか判断してもらい、次のタスクの実行順序を決めてもらう必要があります。
これはAIに対して、コンテキストを与えた上で、「ツールX,Y,Zが利用可能で、後段のタスクはA,B,Cがある。使うツールとタスクを出力せよ」のように、プロンプトで指示します。そして、AIの出力をパースし、制御構文で後段の処理を割り当てることで実現できます。
また、PythonのLangChainや、LangGraphなどの特化したライブラリを用いることで、AIにツールをプロンプトで与えたり、タスクの実行順序を指示することをより簡単に実装することができます。
実装例:技術ブログ自動生成システム
では実際に、Pythonを使って簡単なAIエージェントを実装してみましょう。
代表的な二つのライブラリ、LangChainとLangGraphで実装してそれぞれ比較していきます。今回は下記のフローで、文章を書き、レビューし、ブラッシュアップしていくエージェントにします。
- Writer Agentがユーザーからトピックを受け取り、一度だけネット検索で情報を集めてブログを書く
- Reviewer Agentがそのブログを読んで点数をつける
- もし8点未満なら、Writer Agentに戻して書き直させる。
- 8点以上になるまでこの流れを繰り返し、基準を満たせば完了とする。
プロンプトの定義
まず、WriterとReviewerのプロンプトを定義します。
Writerにはトピックと検索結果、Reviwerからのレビューを入力し、ブログを出力させます。Reviewerには、Writerのブログを入力し、定量評価を出力させます。
Reviewerは下記のように加点式で文章に点数をつけていきます。
- 技術的正確性 (2点): 情報が最新で正確か
- 具体的なコード例 (2点): 実用的なコードサンプルが含まれているか
- 記事の長さ (2点): 5000字以上あるか
- 構成と読みやすさ (2点): 論理的な構成で、読みやすいか
- 独自性と洞察 (2点): 独自の視点や深い洞察が含まれているか
Writerはそのレビューを経て文章を改善をしていきます。
今回はOmegaconfを使って、プロンプトの変数を管理しやすくできるようにyamlで定義しています。
Writerのプロンプト
messages:
- - system
- |
あなたは経験豊富な技術ブログのライターです。与えられたトピックについて、最新の情報と正確な内容を含む技術ブログ記事を書いてください。
以下の指示に従ってください:
${instructions}
- - human
- |
トピック: {input}
検索結果: {search_results}
前回のレビュー: {review}
この情報を基に、技術ブログ記事を書いてください。以下は記事の構成例です:
${article_structure}
各セクションで深く掘り下げ、読者が実践できる情報を提供してください。
instructions:
- 記事の構成を明確にし、見出しを適切に使用してください。
- コードサンプルを含める場合は、説明とともに提供してください。
- 技術的な概念を分かりやすく説明してください。
- 可能な限り、実際の使用例や事例を含めてください。
- 記事の長さは5000字以上を目指してください。
article_structure:
- はじめに
- 技術の概要
- 主要な機能や特徴
- 実装例(コードサンプル付き)
- ユースケースや適用事例
- 他の技術との比較
- まとめと今後の展望
Reviwerのプロンプト
messages:
- - system
- |
あなたは厳格な技術ブログのレビュアーです。提供された記事を評価し、1から10の尺度で点数をつけてください。
また、改善点を具体的に指摘してください。以下の評価基準を厳密に適用してください:
1. 技術的正確性 (2点): 情報が最新で正確か
2. 具体的なコード例 (2点): 実用的なコードサンプルが含まれているか
3. 記事の長さ (2点): 5000字以上あるか
4. 構成と読みやすさ (2点): 論理的な構成で、読みやすいか
5. 独自性と洞察 (2点): 独自の視点や深い洞察が含まれているか
- - human
- |
以下の技術ブログ記事を評価してください:
{blog_content}
各評価基準について詳細にコメントし、改善点を具体的に指摘してください。
最後に、「総合評価: X/10」の形式で全体的な評価を記載してください。
8点以下の場合は、必ず改善のための具体的な提案を含めてください。
評価例:
1. 技術的正確性: 1.5/2 - [コメント]
2. 具体的なコード例: 2/2 - [コメント]
3. 記事の長さ: 1/2 - [コメント]
4. 構成と読みやすさ: 1.5/2 - [コメント]
5. 独自性と洞察: 1/2 - [コメント]
総合評価: 7/10
改善提案:
1. [具体的な提案1]
2. [具体的な提案2]
```yaml
LangChainでの実装例
より簡単な記法で実装できるLangChainから紹介していきます。
LangChainは、LLMを活用したアプリケーションを開発をするためのPythonライブラリです。
Agentの定義
まず、タスクを実行するAgentを生成します。
Agentの実体はツール(ex. Web検索API)の出力と事前定義したプロンプトをLLMに渡し、テキストを出力するメソッドになります。
WriterはプロンプトにWeb検索結果とレビュー内容をわたし、プロンプトを完成させ、LLMに入力します。Web検索にはTavilyというAPIを利用したツールを使います。
Reviewerは単純にWriterが書いたアウトプットを受け取り、点数をつけてレビュー内容をWriterに再度返します。
llm = ChatOpenAI(temperature=0.7, model="gpt-4o-mini")
search = TavilySearchResults(max_results=2)
# === Define the chain ===
def get_search_results(inputs: dict[str, Any]) -> Any:
if "search_results" in inputs:
return inputs["search_results"]
return search.run(inputs["input"])
writer_chain = (
{
"input": lambda x: x["input"],
"search_results": get_search_results,
"review": lambda x: x.get("review", "初回の記事作成のため、レビューはありません。"),
}
| writer_prompt
| llm
| StrOutputParser()
)
reviewer_chain = reviewer_prompt | llm | StrOutputParser()
パイプで繋げた記法はLangChain Expression Language(LCEL)と呼ばれる記法で、パイプの前から後ろに入出力が渡されます。この一連の動作フローをchainと呼びます。
詳しくは下記の記事にあります。
Workflowの定義と実行
最後に、実行ワークフローを定義します。上記chainを使って、while文で定量評価が8点以上になるまで、ブログ内容とレビュー内容と二つのエージェントに受け渡してブラッシュアップと執筆を繰り返させます。
def run_blog_creation_process(topic: str) -> tuple[str, str]:
search_results = search.run(topic)
blog_content = writer_chain.invoke({"input": topic, "search_results": search_results})
review = reviewer_chain.invoke({"blog_content": blog_content})
score = parse_score(review)
while score <= 8:
blog_content = writer_chain.invoke(
{"input": topic, "search_results": search_results, "review": review}
)
review = reviewer_chain.invoke({"blog_content": blog_content})
score = parse_score(review)
print(f"最終スコア: {score}")
return blog_content, review
topic = "LangGraphのMulti Agent Systemを使った技術ブログを書いてください。"
final_blog, final_review = run_blog_creation_process(topic)
出力
簡易的な実装なため、残念ながら点数は上下に振動し、あまりイテレーティブに改善はされていないです。プロンプトやエージェント、入力データをさらに洗練する必要がありそうです。
出力
はじめに
近年、人工知能(AI)と自然言語処理(NLP)の技術は目覚ましい進化を遂げており、特にマルチエージェントシステムの構築が注目を集めています。LangGraphは、こうしたマルチエージェントシステムを簡潔に構築できるフレームワークとして、多くの開発者に利用されています。本記事では、LangGraphを用いたマルチエージェントシステムの概要、主要な機能、実装例、ユースケース、他技術との比較、そして今後の展望について詳しく解説します。
技術の概要
LangGraphとは
LangGraphは、エージェントベースのアプリケーションを構築するためのフレームワークです。簡潔なグラフ構造を利用して、エージェント同士のコミュニケーションや情報のやり取りを容易にします。このフレームワークは、自然言語処理を含む様々なAI技術を組み合わせることができ、強力なマルチエージェントシステムを構築するための基盤を提供します。
マルチエージェントシステムの概念
マルチエージェントシステムとは、複数のエージェントが相互に作用し、協力または競争を通じてタスクを達成するシステムのことです。各エージェントは独立した知識や能力を持ち、他のエージェントとの情報交換を行うことで、全体としてのパフォーマンスを向上させます。
主要な機能や特徴
LangGraphは、以下のような主要な機能を提供しています。
-
ノードとエッジの構造: LangGraphでは、エージェントをノードとして表現し、エージェント間の関係をエッジとして定義できます。このグラフ構造により、エージェントの相互作用を視覚的に理解しやすくなります。
-
アクティベーション条件の設定: 各エージェントには、他のエージェントからのメッセージに応じてアクティベートされる条件を設定できます。これにより、必要なタイミングで適切なエージェントが応答できるようになります。
-
簡易なAPI: LangGraphはシンプルなAPIを提供しており、開発者が迅速にエージェントを設定し、テストできる環境を整えています。
-
スケーラビリティ: 大規模なシステムにも対応可能で、エージェントの数や複雑さに応じてシステムを拡張できます。
実装例(コードサンプル付き)
ここでは、LangGraphを使ったシンプルなマルチエージェントシステムの実装例を示します。この例では、ユーザーのリクエストに応じて異なるエージェントが応答します。
環境設定
最初に、LangGraphをインストールします。Python環境で以下のコマンドを実行してください。
pip install langgraph
... (中略)...
レビュー
-
技術的正確性: 2/2 - 提供された情報は最新で正確そうであり、LangGraphの機能やマルチエージェントシステムの概念について正確に説明されています。
-
具体的なコード例: 2/2 - 実用的なコードサンプルが含まれており、具体的なエージェントの実装が示されています。コードの解説も明確で、読者が理解しやすいです。
-
記事の長さ: 1/2 - 記事は5000字には達しておらず、もう少し詳細な情報や具体例を追加することで、より長くすることが可能です。
-
構成と読みやすさ: 1.5/2 - 論理的な構成であり、各セクションが明確に分かれているため、読みやすさは高いですが、さらに見出しや箇条書きを活用して情報の整理を強化することができると思います。
-
独自性と洞察: 1/2 - LangGraphの利点やユースケースについて触れていますが、他のフレームワークとの比較において、もう少し具体的なデータや実例を示すことで、独自性や洞察を深められる余地があります。
総合評価: 7.5/10
...(中略)...
レビューv2
-
技術的正確性: 1.5/2 - 記事はLangGraphおよびマルチエージェントシステムに関する基本的な情報を正確に提供していますが、最新の研究や特定の使用事例に関する具体的なデータや引用が不足しています。最新の情報を参照することで、より信頼性を高めることができるでしょう。
-
具体的なコード例: 2/2 - コード例は非常に明確で、LangGraphを使用したシンプルなマルチエージェントシステムの実装が示されています。各エージェントの動作やグラフ構造の扱いが具体的に記述されているため、実際のプロジェクトに応用しやすいです。
-
記事の長さ: 1/2 - 記事の内容は概ね充実していますが、5000字には達しておらず、さらなる詳細や具体例を追加することで、より深い理解を促すことができるでしょう。
-
構成と読みやすさ: 1.5/2 - 記事は論理的に構成されており、各セクションが明確に分かれています。ただし、いくつかのセクション間での繋がりが弱い部分が見受けられるため、よりスムーズな流れを持たせるために、各セクションの結びつきを強化することが望ましいです。
-
独自性と洞察: 1/2 - 記事はLangGraphの特徴や利点について述べていますが、独自の視点や深い洞察が不足しているため、読者に新たな理解を提供するには工夫が必要です。特に、LangGraphを使った具体的な成功事例や他の技術との比較に対する独自の分析を加えることで、独自性を高めることができます。
総合評価: 7/10
改善提案:
- 最新の研究や実際の適用事例を引用し、技術的正確性を高めるために、参考文献やリンクを追加してください。
- 記事の内容をさらに拡充し、5000字以上にするために、各ユースケースの詳細な説明や実際のプロジェクトでの体験談を追加してください。
LangGraphの基礎
では次に、LangGraphを利用した実装を紹介します。LangChainに比べて、出てくる概念が多いので、はじめに全体像と主要要素を説明します。
LangGraphは、LLMを使用して状態を持つマルチエージェントシステムを構築するためのライブラリです。LangChainと比較すると、より多くの概念が登場しますが、アプリケーションのフローと状態の両方をきめ細かく制御できる点が特徴です。
LangGraphの技術構成要素
LangGraphでは、エージェント間の相互作用を「State」、「Node」、「Edge」という3つの要素を使用してグラフとして構築します。
State(状態)
StateはGraph間に渡る情報を保持するクラスです。PydanticやTypedDictで定義します。
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
sender: str
どのようにデータを追加するのか、更新するかなどを定義出来ます。
Node(ノード)
NodeはStateの情報を受け取り、実行するクラスです。LangChainのAgentに類似した機能を持ちます。
Edge(エッジ)
EdgeはNode間をつなぐ線で、処理順序や制御を行います。
これらの要素を組み合わせることで、複雑なエージェント間の相互作用や状態遷移を表現できます。
詳しくは、LangGraph公式ドキュメントのコンセプトの章に記述されています。
LangGraphでの実装例
では実際に、先ほどのブログを作成するシステムを実装していきます。
Stateの定義
Stateでは、各ノード間で共有されるメッセージと、次のノードを指定するsenderを定義します。
import operator
from collections.abc import Sequence
from typing import Annotated, TypedDict
from langchain_core.messages import BaseMessage
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
sender: str
routerの定義
routerは、メッセージを受け取り、次にどのノードに移るかを決定する関数です。__end__に遷移すると処理が終了します。
def review_router(state: AgentState) -> Literal["Writer", "continue", "call_tool", "__end__"]:
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "call_tool"
if isinstance(last_message, AIMessage):
if last_message.name == "Reviewer":
content = last_message.content.lower()
score_match = re.search(r"総合評価:\s*(\d+)", content, re.IGNORECASE)
if score_match:
try:
score = int(score_match.group(1))
if score >= 8:
return "__end__"
except ValueError:
print(f"警告: スコアの解析に失敗しました。内容: {content}")
else:
print(f"警告: スコアが見つかりませんでした。内容: {content}")
return "continue"
return "continue"
Node(Agent)の定義
Nodeでは、LLMとツールを受け取り、プロンプトと関連付けます。必要に応じてツールを呼び出せるよう、使用可能なツールのリストも提示します。
"system",
"あなたは他の助手と協力する役立つAIアシスタントです。"
"提供されたツールを使用して、質問に答えるための進展を図ってください。"
"完全に回答できない場合でも問題ありません。別のツールを持つ他の助手が、あなたが中断したところから引き継いで支援します。"
"進展を図るために、できることを実行してください。"
"あなたは以下のツールにアクセスできます:{tool_names}。\n{system_message}",
Agentの実装詳細
class AgentNode:
def __init__(
self, name: str, llm: ChatOpenAI, tools: list[Callable], system_message: str
) -> None:
self.name = name
self.agent = self._create_agent(llm, tools, system_message)
self.tool_used = False # ツール使用フラグを追加
self.llm = llm
self.system_message = system_message
def __call__(self, state: AgentState) -> Any:
if self.tool_used:
result = self._create_agent(self.llm, [], self.system_message).invoke(state)
else:
result = self.agent.invoke(state)
if not isinstance(result, ToolMessage):
result = AIMessage(**result.dict(exclude={"type", "name"}), name=self.name)
self.tool_used = True
self.save_output(result.content)
return {
"messages": [result],
"sender": self.name,
}
def save_output(self, content: str) -> None:
timemin = datetime.now().strftime("%Y%m%d_%H%M")
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = Path("outputs") / timemin / f"{self.name}_{timestamp}.txt"
filename.parent.mkdir(parents=True, exist_ok=True)
if len(content) > 100:
with open(filename, "w", encoding="utf-8") as f:
f.write(content)
print(f"Output saved to {filename}")
def _create_agent(
self, llm: ChatOpenAI, tools: list[Callable], system_message: str
) -> Runnable[Any, Any]:
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは他の助手と協力する役立つAIアシスタントです。"
"提供されたツールを使用して、質問に答えるための進展を図ってください。"
"完全に回答できない場合でも問題ありません。別のツールを持つ他の助手が、あなたが中断したところから引き継いで支援します。"
"進展を図るために、できることを実行してください。"
"あなたは以下のツールにアクセスできます:{tool_names}。\n{system_message}",
),
MessagesPlaceholder(variable_name="messages"),
]
)
prompt = prompt.partial(system_message=system_message)
if tools:
prompt = prompt.partial(tool_names=", ".join([tool.name for tool in tools]))
return prompt | llm.bind_tools(tools)
prompt = prompt.partial(tool_names="なし")
return prompt | llm
edgeとWorkflow全体の定義
これまで作成したノードとステートを使って、ワークフロー全体を構築します。add_conditional_edgesにrouterを渡すことで、各ノードの出力に基づいて次のノードを動的に決定します。
def create_write_blog_workflow(
agent_state: type[Any],
router: Callable,
write_node: AgentNode,
review_node: AgentNode,
tool_node: ToolNode,
) -> CompiledStateGraph:
workflow = StateGraph(agent_state)
tool_name: str = tool_node.name # type: ignore
workflow.add_node(write_node.name, write_node)
workflow.add_node(review_node.name, review_node)
workflow.add_node(tool_name, tool_node)
workflow.add_conditional_edges(
write_node.name,
router,
{"continue": review_node.name, tool_name: tool_name, END: END},
)
workflow.add_conditional_edges(
review_node.name,
router,
{"continue": write_node.name, END: END},
)
workflow.add_conditional_edges(
"call_tool",
lambda x: x["sender"],
{
write_node.name: write_node.name,
review_node.name: review_node.name,
},
)
workflow.add_edge(START, write_node.name)
graph = workflow.compile()
return graph
完成したワークフローは以下のようになります。graph.get_graph().draw_mermaid())で出力できます。
このワークフローでは、WriterとReviewerが相互に作用し合い、必要に応じてツールを呼び出しながら、ブログ作成のプロセスを進めていきます。
出力結果
下記にLangGraphの結果を示します。プロンプトも簡易なもので、モデルもgpt-4o-miniなので、たいしたアウトプットではないですが、レビューで指摘された観点を修正して改善していることがうかがえます。
初回のブログ
LangGraphのMulti-Agent Systemを利用した技術ブログ
はじめに
最近、AI技術の進化と共に、マルチエージェントシステムが注目を集めています。特に、LangGraphはこの領域において強力なツールとして位置づけられています。本ブログでは、LangGraphのMulti-Agent Systemについて、その機能や利点、実際の活用方法を紹介します。
LangGraphとは?
LangGraphは、LangChainの拡張であり、エージェントおよびマルチエージェントフローを構築するためのプラットフォームです。これにより、開発者は複雑なワークフローを効率的に設計でき、メモリ機能やサイクルフローを組み込むことができます。これらの機能は、エージェントを構築する際に非常に重要です。
Multi-Agent Systemの概念
Multi-Agent System(MAS)は、複数の独立したエージェントが相互に作用し、協力してタスクを遂行するシステムです。LangGraphでは、大規模言語モデル(LLM)を活用して、各エージェントが異なる役割を持つことが可能です。これにより、複雑な問題を効率的に解決することができます。
LangGraphの特徴
-
エージェントの作成: LangGraphを使用すると、異なる役割を持つエージェントを簡単に作成できます。例えば、情報収集エージェント、データ分析エージェント、報告エージェントなど、特定の機能に特化したエージェントを設定できます。
-
メモリ機能: LangGraphにはメモリ機能が組み込まれており、エージェントが過去のインタラクションを記憶し、より効果的にタスクを遂行することが可能です。
-
サイクルフロー: エージェント間の連携を強化するために、サイクルフローを利用できます。これにより、各エージェントが相互に作用し、タスクをより効率的に処理できます。
活用例
LangGraphのMulti-Agent Systemは、さまざまな分野で活用されています。たとえば、カスタマーサポートシステムでは、問い合わせを受けるエージェント、問題を解決するエージェント、フィードバックを収集するエージェントが協力して、顧客のニーズに応じたサービスを提供できます。
また、ビジネス分析やデータサイエンスの分野でも、データ収集エージェント、分析エージェント、レポート作成エージェントが連携することで、迅速かつ正確な意思決定が可能になります。
まとめ
LangGraphのMulti-Agent Systemは、複雑なタスクを効率的に処理するための強力なツールです。エージェント同士の相互作用を活用することで、さまざまな分野での応用が期待されます。今後も、この技術の進化を見守りながら、新たな可能性を探求していきたいと思います。
このブログが、LangGraphのMulti-Agent Systemに関心を持つ方々にとって、有益な情報源となることを願っています。興味がある方は、ぜひLangGraphを試してみてください。
初回のレビュー
この技術ブログの内容をレビューいたします。
評価基準
- 具体的なコードが記述されている (2点): コードの具体例がありません。
- 5000字以上の分量 (3点): 記事は5000字に満たない。
- 読みやすさ (3点): 構成は整っており、読みやすい。
- 独自性 (2点): LangGraphの機能について触れているが、特に独自性が感じられない。
総合評価: 5
全体として、基本的な情報は提供されていますが、具体的なコードや詳細な事例が不足しており、5000字以上の要件も満たしていません。今後の改善点として、具体的なコード例や実際の使用ケースを追加し、分量を増やすことをお勧めします。
2回目のブログ
改善点を反映したLangGraphのMulti-Agent Systemを利用した技術ブログ
LangGraphのMulti-Agent Systemを利用した技術ブログ
はじめに
最近、AI技術の進化と共に、マルチエージェントシステムが注目を集めています。特に、LangGraphはこの領域において強力なツールとして位置づけられています。本ブログでは、LangGraphのMulti-Agent Systemについて、その機能や利点、実際の活用方法を具体的なコード例を交えて紹介します。
LangGraphとは?
LangGraphは、LangChainの拡張であり、エージェントおよびマルチエージェントフローを構築するためのプラットフォームです。これにより、開発者は複雑なワークフローを効率的に設計でき、メモリ機能やサイクルフローを組み込むことができます。これらの機能は、エージェントを構築する際に非常に重要です。
Multi-Agent Systemの概念
Multi-Agent System(MAS)は、複数の独立したエージェントが相互に作用し、協力してタスクを遂行するシステムです。LangGraphでは、大規模言語モデル(LLM)を活用して、各エージェントが異なる役割を持つことが可能です。これにより、複雑な問題を効率的に解決することができます。
LangGraphの特徴
-
エージェントの作成: LangGraphを使用すると、異なる役割を持つエージェントを簡単に作成できます。例えば、情報収集エージェント、データ分析エージェント、報告エージェントなど、特定の機能に特化したエージェントを設定できます。
-
メモリ機能: LangGraphにはメモリ機能が組み込まれており、エージェントが過去のインタラクションを記憶し、より効果的にタスクを遂行することが可能です。
-
サイクルフロー: エージェント間の連携を強化するために、サイクルフローを利用できます。これにより、各エージェントが相互に作用し、タスクをより効率的に処理できます。
コード例
以下は、LangGraphを使用してシンプルなマルチエージェントシステムを構築するためのPythonコードの例です。
from langgraph import Agent, Workflow
# 役割ごとのエージェントを定義
class DataCollector(Agent):
def run(self):
# データ収集のロジック
return "Collected Data"
class DataAnalyzer(Agent):
def run(self, data):
# データ分析のロジック
return f"Analyzed: {data}"
class ReportGenerator(Agent):
def run(self, analysis):
# レポート生成のロジック
return f"Report: {analysis}"
# ワークフローを定義
workflow = Workflow(agents=[DataCollector(), DataAnalyzer(), ReportGenerator()])
# ワークフローを実行
collected_data = workflow.run(0) # DataCollector
analysis = workflow.run(1, collected_data) # DataAnalyzer
report = workflow.run(2, analysis) # ReportGenerator
print(report)
活用例
LangGraphのMulti-Agent Systemは、さまざまな分野で活用されています。たとえば、カスタマーサポートシステムでは、問い合わせを受けるエージェント、問題を解決するエージェント、フィードバックを収集するエージェントが協力して、顧客のニーズに応じたサービスを提供できます。
また、ビジネス分析やデータサイエンスの分野でも、データ収集エージェント、分析エージェント、レポート作成エージェントが連携することで、迅速かつ正確な意思決定が可能になります。
まとめ
LangGraphのMulti-Agent Systemは、複雑なタスクを効率的に処理するための強力なツールです。エージェント同士の相互作用を活用することで、さまざまな分野での応用が期待されます。今後も、この技術の進化を見守りながら、新たな可能性を探求していきたいと思います。
このブログが、LangGraphのMulti-Agent Systemに関心を持つ方々にとって、有益な情報源となることを願っています。興味がある方は、ぜひLangGraphを試してみてください。
この改善により、具体的なコード例を追加し、内容がより充実しました。今後もさらに詳細な情報を追記することで、ブログの価値を高めていきましょう。
2回目のレビュー
評価基準
- 具体的なコードが記述されている (2点): 具体的なコード例が追加され、評価されるべきです。
- 5000字以上の分量 (3点): 記事は5000字には至っていませんが、内容が濃くなりました。
- 読みやすさ (3点): 構成は整っており、読みやすさが向上しました。
- 独自性 (2点): LangGraphの機能について新しい視点が追加されましたが、他に類似の情報が多いため、独自性が強調される余地があります。
総合評価: 7
全体として、具体的なコード例を通して、LangGraphのMulti-Agent Systemについてわかりやすく説明されています。しかし、5000字以上の分量と独自性のさらなる強化が求められます。今後、実際のケーススタディや詳細なアプリケーション例を追加することで、より高い評価を得られるでしょう。
LangChainとLangGraphの比較
LangChainとLangGraphでブログ生成エージェントを実装した実装した所感として、正直、このレベルのエージェントであれば、LangGraphよりもLangChainで実装した方が楽かなと思います。状態遷移も事前に静的に決めることが出来るので、Pythonの制御構文で書く方が読みやすいです。
sakana aiのThe Scientist AIは、LangChainすら使っておらず、リッチなプロンプトとコードテンプレート、緻密な制御フローによってAIに論文を書かせておりました。
参考:
LangGraphは、下記のようなサブグラフが存在するようなエージェントを組みたい場合や、制御フローをある程度AI主導で構築したい場合に真価を発揮しそうです。

ただしこのようなエージェントのチューニング・デバッグ・評価はかなり難しいとは思っています。笑
もし上手く使った実装例があれば教えていただきたいです 🙏
AIエージェントの実応用について
AIエージェントの実装を通じて得た知見をもとに、その実応用について考察してみましょう。特に、AIにどこまでタスクを任せるべきか、どのように制御フローを設計するかという点に焦点を当てます。
(※あくまで個人の予想・感想です)
既存のB2BプロダクトにおけるAIエージェントの活用
多くのB2Bプロダクトは、頻繁に行われる作業を高速化・簡略化することを目的としています。
このような業務効率改善を目指す場合、AIに制御フローを任せるのではなく、事前に明確に定義されたワークフローを設計する方が良いかなとおもいます。これにより、プロセスの透明性と予測可能性が高まります。
また、大きなタスクをAIが確実に解決できる小さなサブタスクに分割し、複雑な問題を管理可能な単位に落とし込むこと、各タスクにおいては、AIが適切に機能するためにリッチなコンテキストを提供すること、予測可能な形式に制限する出力のスキーマ制御も重要となりそうです。
AIの大きな利点として、疲労せずに作業を続けられることや、容易にスケールアップできることが挙げられます。
人間のように休憩や交代を必要とせず、需要に応じて処理能力を拡張できるAIの特性は、長期的には大きな価値を生み出します。これらの特性により、厳密なタスク定義や制御にかかる初期コストを、長期的に十分に回収できると考えられます。
柔軟な対応が必要なケースでのAIエージェントの活用
一方で、コンテキストや環境に応じて必要なアクションが大きく変わるケースでは、AIにより主導的な役割を担わせる必要があります。
環境に応じて高度な状況判断が求められるタスクとしては、例えば、要件や既存のコードベースに応じて柔軟な対応が必要なプログラミングや、ユーザーの好みや使用パターンに合わせたUIの動的生成、ゲーム内の状況に応じて自然な振る舞いをするNPCの実装などが挙げられます。
これらのケースでは、事前に全ての可能性を網羅したワークフローを定義することが困難です。そのため、AIがコンテキストを理解し、適切なツールを選択し、動的にタスクを定義・実行する能力が重要になります。
Anthropicも、このような柔軟なAIエージェントの実現に向けて開発を進めているようです。例えば、Claude 3.5 Sonnetの評価項目に「internal agentic coding evaluation」が含まれていることからも、その方向性が窺えます。
まとめ
AIエージェントについて紹介しました。業務効率化から創造的タスクまで、幅広い分野での応用が期待されるのですごくワクワクします!
どんなワークフローを定義し、どう分けて、どんなコンテキストを入力していくかは試行錯誤する必要がありますが、今までよりも周辺ライブラリも整ってきたと感じます。
例えば、Web上のテキストをAIが読みやすい形に整形して収集できるjina.aiやWeb検索ツールTavily、OpenAIが提供している構造化して出力できる Structure Output APIなどが出てきました。これらのツールを上手く組み合わせつつ、今までにない体験を作っていきたいですね!🪄
面白い活用事例や技術が出たら、またまとめていきたいと思います。よければXの方もフォローしていただけると助かります🖐️
最後までお読みいただきありがとうございました!

Discussion