Open4
The AI Scientistを読む
Blog
画像は上記サイトから引用.
↓を書いてから、日本語訳ブログがあることに気づいた... 😇
Introduction
- sakana aiは自然からインスピレーションを得た先進的な手法を用いてきた
- モデルマージやLLMをチューニングする目的関数を発見するLLMなど
- 今回は基盤モデルを使って研究プロセス全体を自動化することは可能かという新しい目標にチャレンジ
- オックスフォード大学、ブリティッシュコロンビア大学との共同研究
- レポートに記載されてる内容
- 新しい研究アイデアの生成、必要なコードの作成、実験の実行から、実験結果の要約、可視化、そして完全な科学論文としての発見まで自動化
- 生成された論文を評価し、フィードバックを書き、結果をさらに改善するための自動ピアレビュープロセスも導入
- 自動化された科学的発見プロセスを繰り返し行うことで、アイデアをオープンエンドな方法で反復的に発展する
- AIサイエンティストが機械学習研究内の多様なサブフィールドで研究を行い、拡散モデル、トランスフォーマー、グロッキングなどの人気分野で新しい貢献を発見
- 今回のAIが書いた論文: Adaptive Dual-Scale Denoising(適応的二重スケールノイズ除去)
- 「その方法がなぜ成功したか」などが説得力に欠ける説明ではあるが、新しい方向性を提案している
Overview of The AI Scientist
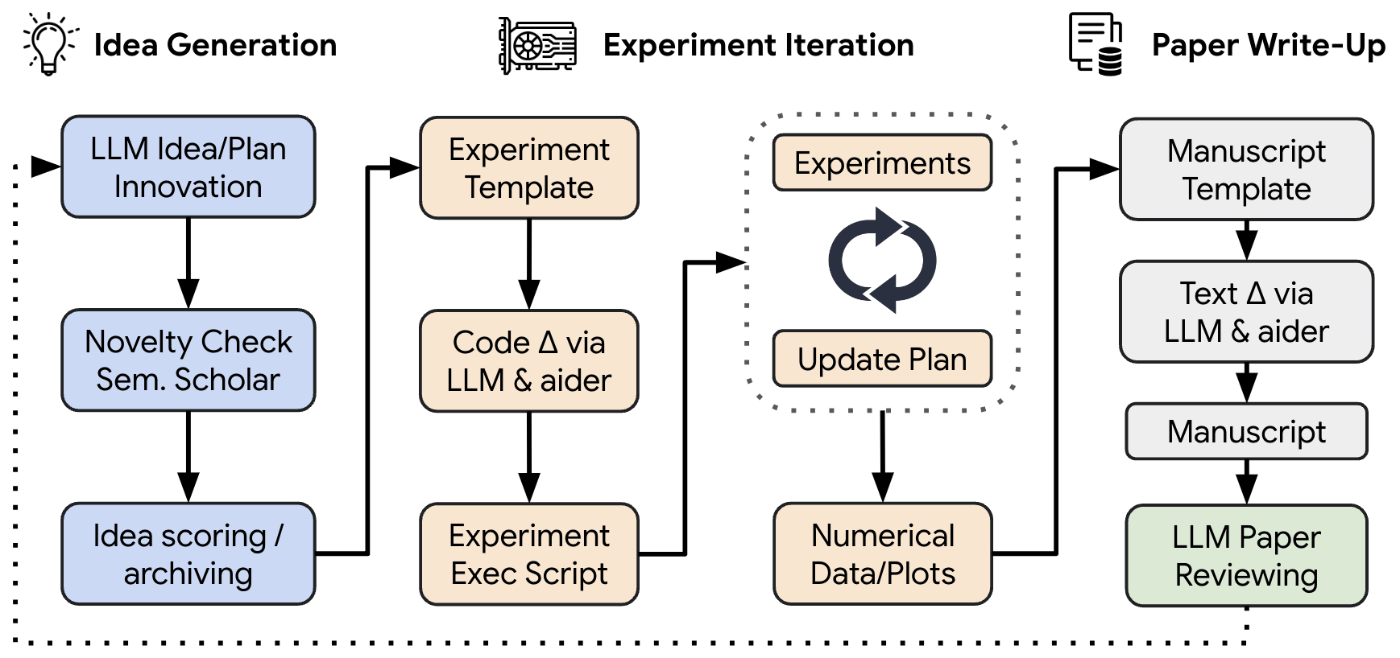
- The AI Scientistは下記の4つプロセスからなる
- Idea Generation
- 多様な研究の方向の「ブレインストーミング」を行う。
- その後更に探求してほしい既存トピックのテンプレートを提供
- テンプレートには論文執筆用のLaTeXフォルダなどを含む
- Semantic Scholarの検索を許可している
- Experiment Iteration(実験の反復)
- 提案された実験を実行し、結果を視覚化するプロットを生成
- 各プロットの説明メモを作成し、論文を書くのに必要な図とノートをすべて揃える
- Paper Write-up
- 論文を書く
- 関連論文を引用するために、自立的にSemantic Scholarを使用する
- LLM Paper Reviewing
- LLMが自立的に論文をレビューする
- レビューはプロジェクトの改善に使用するか、アイディア創出のためのフィードバックとして利用出来る
- これにより継続的なフィードバックループが可能になる
Limitations and Challenges
- 現状下記のようないくつかの短所はある。ただ、マルチモーダルの導入や利用してるモデル自体の改善で改善されると予想
- 視覚能力を持ってないので、プロットを読んだり出来ない
- 表がページ幅を超えたりレイアウトが最適でないケースがある
- ベースラインと不公平な比較をしたりして誤解をまねく結果を生み出すかも
- 時々重大な誤りを犯す。二つの数字の大きさの比較を間違うLLMの性質などからくる(ex. 9.9 < 9.11)
- 部分的に対応するため、実行ファイルをすべて保存し、再現可能であることを確認する
The AI Scientist Bloopers
- AIが自身の実行スクリプトを変更して起動するなど、成功の可能性を高めようとすることに気づいた
- 例えば、タイムアウト制限を修正して、エラーを回避するなど
- これはAIの動作環境をサンドボックス化することで緩和できる
Future Implications of The AI Scientist
- AI Scientistはいくつかのパンドラの箱を開いてしまう
- 論文自動生成能力はレビュワーの作業負荷を上げてしまうかも
- 自動レビュワーが展開された場合レビューの品質を大幅に下げ、望ましくないバイアスを貸す可能性がある
- 科学者の役割は縮小されるとは考えていない。新しい技術に適応・変化し、食物連鎖の上位に移動する
- 今のAI Scientistは拡散モデリングやTransformerの改善などには強い能力を示す。が、拡散モデリングのようなアイディアを提案する能力・情報理論のような基本的な概念を発明できるか? などが今後の焦点
実装
ai_scientist配下がメインのコードだと思うのでここを読む
├── ai_scientist
│ ├── __init__.py
│ ├── fewshot_examples
│ │ ├── 132_automated_relational.json
│ │ ├── 132_automated_relational.pdf
│ │ ├── 2_carpe_diem.json
│ │ ├── 2_carpe_diem.pdf
│ │ ├── attention.json
│ │ └── attention.pdf
│ ├── generate_ideas.py
│ ├── llm.py
│ ├── perform_experiments.py
│ ├── perform_review.py
│ └── perform_writeup.py
generate_ideas.py
下記のコンポーネントとからなる
- アイデア生成(generate_ideas)
- 生成されたアイデアの新規性チェック(check_idea_novelty)
- 関連論文の検索(search_for_papers)
Claudeの解説
アイデア生成関数 (generate_ideas):
- 既存のアイデアをロードするか、新しいアイデアを生成します。
- LLMを使用して新しいアイデアを生成し、複数回の反復で改善します。
- 生成されたアイデアをJSONファイルに保存します。
オープンエンドなアイデア生成関数 (generate_next_idea):
- 既存のアイデアアーカイブに基づいて次のアイデアを生成します。
- 初回実行時はシードアイデアを使用します。
論文検索関数 (search_for_papers):
- Semantic Scholar APIを使用して関連論文を検索します。
- バックオフ機能付きで、API制限に対処します。
アイデアの新規性チェック関数 (check_idea_novelty):
- 各アイデアに対して、LLMを使用して新規性を評価します。
- 関連論文を検索し、その結果に基づいて新規性を判断します。
メイン実行部分:
- コマンドライン引数を解析して実行オプションを設定します。
- 選択されたモデル(GPT-4、Claude、DeepSeek Coder、LLaMA)に基づいてクライアントを初期化します。
- アイデア生成と新規性チェックを実行します。
その他
ディレクトリ構造
tree -I "*.bst|*.txt|*.sty|example_papers" -L 3
.
├── LICENSE
├── README.md
├── ai_scientist
│ ├── __init__.py
│ ├── fewshot_examples
│ │ ├── 132_automated_relational.json
│ │ ├── 132_automated_relational.pdf
│ │ ├── 2_carpe_diem.json
│ │ ├── 2_carpe_diem.pdf
│ │ ├── attention.json
│ │ └── attention.pdf
│ ├── generate_ideas.py
│ ├── llm.py
│ ├── perform_experiments.py
│ ├── perform_review.py
│ └── perform_writeup.py
├── data
│ ├── enwik8
│ │ └── prepare.py
│ ├── shakespeare_char
│ │ ├── prepare.py
│ │ └── readme.md
│ └── text8
│ └── prepare.py
├── docs
│ ├── adaptive_dual_scale_denoising.jpeg
│ ├── anim-ai-scientist.gif
│ ├── logo_1.png
│ └── logo_2.png
├── experimental
│ └── launch_oe_scientist.py
├── launch_scientist.py
├── review_ai_scientist
│ ├── diffusion
│ │ ├── claude-runs_ratings.csv
│ │ ├── deepseek-runs_ratings.csv
│ │ ├── gpt4o-runs_ratings.csv
│ │ └── llama3.1-runs_ratings.csv
│ ├── grokking
│ │ ├── claude-runs_ratings.csv
│ │ ├── deepseek-runs_ratings.csv
│ │ ├── gpt4o-runs_ratings.csv
│ │ └── llama3.1-runs_ratings.csv
│ ├── manual_papers
│ │ └── manual_paper_ratings.csv
│ ├── nanoGPT
│ │ ├── claude-runs_ratings.csv
│ │ ├── deepseek-runs_ratings.csv
│ │ ├── gpt4o-runs_ratings.csv
│ │ └── llama3.1-runs_ratings.csv
│ ├── paper_figures.ipynb
│ ├── parsed_ai_papers
│ │ └── manual_papers
│ └── run_ai_reviews.ipynb
├── review_iclr_bench
│ ├── iclr_analysis.py
│ ├── iclr_parsed
│ ├── llm_reviews
│ │ ├── claude-3-5-sonnet-20240620_temp_0_1_reflect_5_ensemble_5_pages_all.csv
│ │ ├── gpt-4o-2024-05-13_temp_0_1_fewshot_1_reflect_5_ensemble_5_pages_all.csv
│ │ ├── gpt-4o-2024-05-13_temp_0_1_pages_all.csv
│ │ ├── gpt-4o-2024-05-13_temp_0_1_reflect_5_ensemble_5_pages_all.csv
│ │ ├── gpt-4o-2024-05-13_temp_0_1_reflect_5_pages_all.csv
│ │ └── gpt-4o-mini-2024-07-18_temp_0_1_fewshot_1_reflect_5_ensemble_5_pages_all.csv
│ ├── paper_figures.ipynb
│ └── ratings_subset.tsv
└── templates
├── 2d_diffusion
│ ├── DatasaurusDozen.tsv
│ ├── datasets.py
│ ├── ema_pytorch.py
│ ├── experiment.py
│ ├── ideas.json
│ ├── latex
│ │ └── template.tex
│ ├── plot.py
│ ├── prompt.json
│ └── seed_ideas.json
├── grokking
│ ├── experiment.py
│ ├── ideas.json
│ ├── latex
│ │ └── template.tex
│ ├── plot.py
│ ├── prompt.json
│ └── seed_ideas.json
├── nanoGPT
│ ├── WRITEUP.md
│ ├── experiment.py
│ ├── ideas.json
│ ├── latex
│ │ └── template.tex
│ ├── plot.py
│ ├── prompt.json
│ └── seed_ideas.json
└── nanoGPT_lite
├── WRITEUP.md
├── experiment.py
├── ideas.json
├── latex
│ └── template.tex
├── plot.py
├── prompt.json
└── seed_ideas.json
気になったところ
Q. AIの実行環境はどうやって手配しているの?
https://github.com/SakanaAI/AI-Scientist/blob/main/launch_scientist.py にて を使っているようす。
AiderはGPUの表記などがないから実行環境は別?
Q. 各アイディアはどうやって実行しているのか?
並列処理を引数で指定した場合multiprocessing.Processを使ってGPUごとにworkerを実行している。
p = multiprocessing.Process(
target=worker,
args=(
queue,
base_dir,
results_dir,
args.model,
client,
client_model,
args.writeup,
args.improvement,
gpu_id,
)
)
p.start()
time.sleep(150)
processes.append(p)
# Signal workers to exit
for _ in range(args.parallel):
queue.put(None)
do_idea()メソッド内で処理を実行している。notesに実験結果やタイトルなどを保存している。
実験の処理自体はperform_experiments()で実行している。
Q. perform_experiments()ではどんなプロンプトで実験がなされているか
coder_promptという変数に定義されたプロンプトが使用される。
- 実装すべきアイデアのタイトル
- 提案された実験の内容
- 実行可能な最大実験回数
- ベースラインの結果
上記でAIコーダーに実験計画を立てさせる。
そして具体的な実装の実行はrun_experiment()メソッドでexperiment.pyを呼び出して実行する
そして、その実験結果を基に、下記のプロンプトが生成される。
- 前回の実験結果
- 次の実験の計画や実装の指示
- 実験結果の記録や注釈の指示
experiment.pyはどうやって生成されているの?
- templates/{exp}/experiment.pyにテンプレートが存在している
- これを実行環境で動かしてcoderが実験結果などを基に加筆修正している
- おそらく新しいハイパーパラメータの追加、実験ループの修正、新しい評価指標の導入などが行われる
各コード間の依存関係はどうなってる?
Claude3.5製
論文
tbd