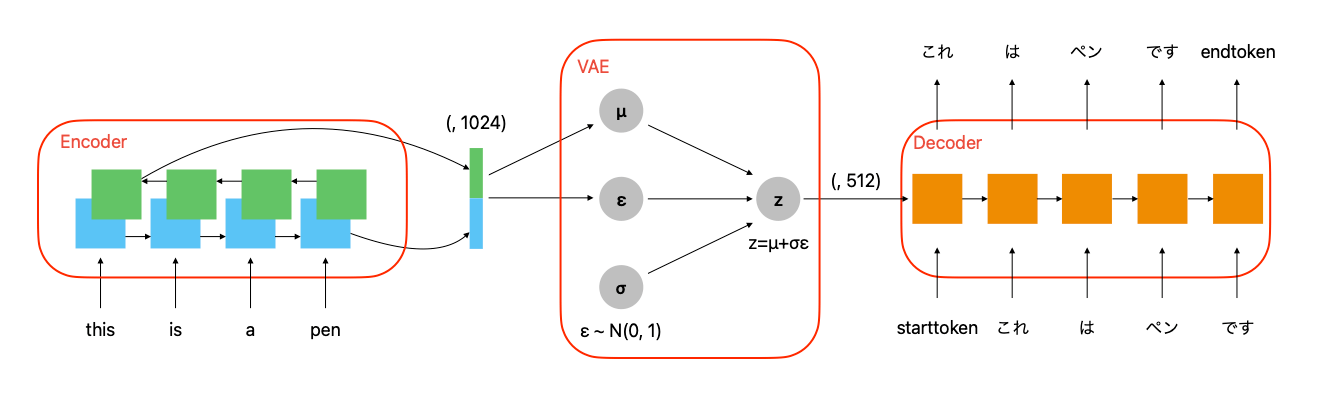
seq2seqにおいてEncoderが出力した潜在変数をVAEをしてからDecoderに渡してみる。

はじめに
前回の記事では再帰型ニューラルネットを用いて英語から日本語への翻訳機を作成した。
Encoder の出力結果を VAE で正規分布にした後に Decoder に渡したら精度が上がるのではないかと思ったためそれを検証してみる。具体的には以下のようなモデルを作成し翻訳をしてみる。
データセットの説明
データセットは前回の記事と同じものを用いる。具体的なデータの加工方法についてはそちらを参考いただきたい。
Encoder と Decoder には以下のようなデータセットで学習する。
input_1: this, is, a, pen
input_2: starttoken, これ, は, ペン, です
output: これ, は, ペン, です, endtoken
input_1 を Encoder に入力し潜在変数に変換する。Decoder は潜在変数と input_2 を入力し output に変換する。
モデルの説明
Encoder は前回の記事と同じものを用いる。Decoder は構造は全く同じだが、入力の潜在変数の次元を半分にしたものを用いる。
VAE の部分は以下のように作成した。
class seq2seq(Model):
def __init__(self, encoder, decoder):
super(seq2seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def call(self, inputs):
english_inputs, japanese_inputs = inputs
encoder_outputs = self.encoder(english_inputs)
mu, logvar = encoder_outputs[:,::2], encoder_outputs[:,1::2]
eps = tf.random.normal(shape=tf.shape(mu))
sampled = eps * tf.exp(logvar * 0.5) + mu
decoder_outputs = self.decoder(japanese_inputs, sampled)
return decoder_outputs
def compile(self, optimizer, loss):
super(seq2seq, self).compile()
self.optimizer = optimizer
self.compiled_loss = loss
self.loss_tracker=tf.keras.metrics.Mean(name='loss')
@property
def metrics(self):
return [self.loss_tracker]
def train_step(self, data):
inputs, outputs = data
english_inputs, japanese_inputs = inputs
with tf.GradientTape() as tape:
encoder_outputs = self.encoder(english_inputs)
mu, logvar = encoder_outputs[:,::2], encoder_outputs[:,1::2]
eps = tf.random.normal(shape=tf.shape(mu))
sampled = eps * tf.exp(logvar * 0.5) + mu
decoder_outputs = self.decoder(japanese_inputs, sampled)
loss = self.compiled_loss(outputs, decoder_outputs, mu, logvar)
grads = tape.gradient(loss, self.trainable_variables)
self.optimizer.apply_gradients(zip(grads, self.trainable_variables))
self.loss_tracker.update_state(loss)
return {'loss':self.loss_tracker.result()}
def test_step(self, data):
inputs, outputs = data
english_inputs, japanese_inputs = inputs
encoder_outputs = self.encoder(english_inputs)
mu, logvar = encoder_outputs[:,::2], encoder_outputs[:,1::2]
eps = tf.random.normal(shape=tf.shape(mu))
sampled = eps * tf.exp(logvar * 0.5) + mu
decoder_outputs = self.decoder(japanese_inputs, sampled)
loss = self.compiled_loss(outputs, decoder_outputs, mu, logvar)
self.loss_tracker.update_state(loss)
return {'loss':self.loss_tracker.result()}
encoder の出力を交互に mu と logvar に用いる。VAE の損失関数には mu や logvar も必要となるため、train_step や test_step を書く必要がある。私の VAE の記事はこちらを参考。
損失関数
損失関数は次のように定義した。
@tf.function
def custom_loss(y_true, y_pred, mean, log_var):
loss_rec = tf.reduce_mean(
tf.reduce_sum(
tf.keras.losses.sparse_categorical_crossentropy(y_true, y_pred)
, axis = 1
)
)
log_reg = tf.reduce_mean(
tf.reduce_sum(
-0.5 * (1 + 2 * log_var - tf.square(mean) - tf.exp(2 * log_var))
, axis=1
)
)
return loss_rec + log_reg
for (english_batch, japanese_batch), japanese_batch_out in train_dataset.take(1):
print(custom_loss(japanese_batch_out, model((english_batch, japanese_batch)), tf.zeros((BATCH_SIZE, HIDDEN_DIM)), tf.zeros((BATCH_SIZE, HIDDEN_DIM))))
# tf.Tensor(633.7588, shape=(), dtype=float32)
sparse_categorical_crossentropyの損失に対して、潜在変数が正規分布に近づくように正規化項を加える。
モデルの学習
モデルは次のように学習した。
model.compile(optimizer = tf.keras.optimizers.Adam(), loss = custom_loss)
history = model.fit(train_dataset, validation_data=test_dataset, epochs=10, shuffle=True)
結果
学習の結果を確かめる。
print(translator("this is a pen."))
print(translator('i am a student'))
print(translator("i love you."))
print(translator("what are you doing?"))
starttoken[UNK]の[UNK]の[UNK]endtoken
starttoken[UNK]の[UNK]の[UNK]endtoken
starttoken[UNK]の[UNK]の[UNK]endtoken
starttoken[UNK]の[UNK]の[UNK]endtoken
train データセットに対して学習を行った結果は次のようになった。
for data in raw_dev_dataset.take(5):
english_sentence, japanese_sentence = data.numpy().decode().split('\t')
print("english: ", english_sentence)
print("translated: ", translator(english_sentence)[10:-8])
print("japanese: ", japanese_sentence)
print("---")
english: it's suliban.
translated: [UNK]の[UNK]の[UNK]
japanese: スリバン人です
---
english: nothing thrills me more than to see kids pollinating plants instead of each other.
translated: [UNK]の[UNK]の[UNK]
japanese: 生徒がお互いの受精じゃなくて 植物の受粉に熱中してくれてるよ!
---
english: do you want to spend all night at the cemetery in this rain?
translated: [UNK]の[UNK]の[UNK]
japanese: この雨の中 一晩中 墓地にいたい?
---
english: our ships are in attack position.
translated: [UNK]の[UNK]の[UNK]
japanese: 船はもう攻撃発起位置にある。
---
english: what about the original sam? huh?
translated: [UNK]の[UNK]の[UNK]
japanese: オリジナルの サムが居るんだぞ
---
ほとんど翻訳できていない。。。
おわりに
思いつきでやってみたけど、うまく学習できなかった。VAE の潜在変数の分布を見てると正規分布に近づけたことによってクラスターが良く分類されているように見えたから、翻訳についても同様のことが起こるかと思ったがそんなことはなかった。パラメータをチューニングしないとだめなのかも。VAE は画像にはうまくいくけど言語にはうまくいかない性質のものなのかもしれない。次は VAE を用いて入力フォームの異常検知とかやってみたいなぁ。できるのかな。
Discussion