再帰型ニューラルネットで英語から日本語の機械翻訳を実装する方法
はじめに
再帰型ニューラルネットは時系列データや文章の処理に用いられるニューラルネットワークである。この記事では再帰型ニューラルネットの一種である GRU を用いて、英語を日本語に翻訳するモデルの学習を行う。
コードの全体は以下に配置した。この記事では重要な部分だけを解説する。
コードの全体
データの準備
この記事では日本語と英語の対話コーパスとして、JESC データセットを用いる。
このデータセットは 280 万文から構成される。内容は次のような短い英語と日本語の文章が入っている。
you are back, aren't you, harold? あなたは戻ったのね ハロルド?
my opponent is shark. 俺の相手は シャークだ。
口語的な文章も多く含むのが特徴的で、個性的な翻訳機が作成できそうなデータセットである。
データの加工
この章では JESC のホームページからダウンロードしたデータを tf.data の形式に変換する方法を説明する。
日本語の分割
英語は初めからスペースで分割されているが、日本語はそうではないため形態素解析を実施して単語ごとに分離する必要がある。この記事では janome[1]を利用する。
import tensorflow as tf
from janome.tokenizer import Tokenizer
raw_dev_dataset = tf.data.TextLineDataset('./dataset/split/train')
t = Tokenizer(wakati=True)
def preprocess(text):
text_list = text.numpy().decode('utf-8').split('\t')
raw_english_text, raw_japanese_text = text_list[0], text_list[1]
split_japanese_text = "starttoken " + " ".join(t.tokenize(raw_japanese_text)) + " endtoken"
return raw_english_text, split_japanese_text
def tf_preprocess(text):
output = tf.py_function(preprocess, [text], [tf.string, tf.string])
output[0].set_shape(())
output[1].set_shape(())
return output[0], output[1]
preprocessed_dev_dataset = raw_dev_dataset.map(tf_preprocess, num_parallel_calls=tf.data.experimental.AUTOTUNE)
for english_text, japanese_text in preprocessed_dev_dataset.take(1):
print(english_text, japanese_text)
# tf.Tensor(b"it's suliban.", shape=(), dtype=string) tf.Tensor(b'starttoken \xe3\x82\xb9\xe3\x83\xaa \xe3\x83\x90\xe3\x83\xb3 \xe4\xba\xba \xe3\x81\xa7\xe3\x81\x99 endtoken', shape=(), dtype=string)
# tf.Tensor(b'nothing thrills me more than to see kids pollinating plants instead of each other.', shape=(), dtype=string) tf.Tensor(b'starttoken \xe7\x94\x9f\xe5\xbe\x92 \xe3\x81\x8c \xe3\x81\x8a\xe4\xba\x92\xe3\x81\x84 \xe3\x81\xae \xe5\x8f\x97\xe7\xb2\xbe \xe3\x81\x98\xe3\x82\x83 \xe3\x81\xaa\xe3\x81\x8f \xe3\x81\xa6 \xe6\xa4\x8d\xe7\x89\xa9 \xe3\x81\xae \xe5\x8f\x97\xe7\xb2\x89 \xe3\x81\xab \xe7\x86\xb1\xe4\xb8\xad \xe3\x81\x97 \xe3\x81\xa6 \xe3\x81\x8f\xe3\x82\x8c \xe3\x81\xa6\xe3\x82\x8b \xe3\x82\x88 ! endtoken', shape=(), dtype=string)
tf.data の map では tf.function しか呼び出せない。janome は tf.function ではないため、tf.py_function で tf.function に変換してから map に渡す必要がある。その際には set_shape(())で型を指定する必要がある。また、日本語の文には starttoken と endtoken をそれぞれ文頭と文末に付け加える。
ベクトル化レイヤーの準備
文をニューラルネットワークのモデルに入力するためには、それぞれの単語に自然数を割り当てて数値化し、文章を一定の長さに揃えてベクトル化する必要がある。今回は TensorFlow の TextVectorization を使って文章をベクトル化する。
from tensorflow.keras.layers import TextVectorization
import pickle
# Parameters
english_filepath = "./dataset/vectorizer/english_vectorizer.pickle"
VOCAB_SIZE=20000
ENGLISH_SEQUENCE_LENGTH=64
EMBEDDING_DIM=128
BATCH_SIZE=512
# build vectorization layer for english text
english_vectorization_layer = TextVectorization(
max_tokens=VOCAB_SIZE,
output_mode='int',
output_sequence_length=ENGLISH_SEQUENCE_LENGTH
)
english_vectorization_layer.adapt(
preprocessed_dev_dataset.map(
lambda english, japanese: english
).batch(BATCH_SIZE * 8),
batch_size=BATCH_SIZE * 8
)
# save vectorization layer
with open(english_filepath, 'wb') as f:
pickle.dump({
'config': english_vectorization_layer.get_config(),
'weights': english_vectorization_layer.get_weights()
}, f)
pickle で保存し、モデルの学習の際には以下の方法でロードして用いる。
# load vectorization layer for english text
with open(english_filepath, 'rb') as f:
d = pickle.load(f)
english_vectorization_layer = TextVectorization.from_config(d['config'])
english_vectorization_layer.set_weights(d['weights'])
日本語も全く同じ方法でベクトル化する。
データセットのベクトル化
データセットに対してベクトル化レイヤーを適用する。さらに RNN の学習に適した形状に変換も行う。
具体的には、次のように変換する。
input_1: this, is, a, pen
input_2: starttoken, これ, は, ペン, です
output: これ, は, ペン, です, endtoken
RNN の翻訳機では、Encoder で input_1 を受け取り文章全体を潜在ベクトルにする。そして Decoder では、潜在ベクトルを初期値として input_2 の単語を1つずつ受け取りながら次の単語を予想するタスクを解くことで学習を行う。
以下のコードで input_1 と input_2 と output を用意する。
# vectorize dataset
def vectorize_text(english_text, japanese_text):
english_vectorized_text = english_vectorization_layer(english_text)
japanese_vectorized_text = japanese_vectorization_layer(japanese_text)
return english_vectorized_text, japanese_vectorized_text
vectorized_dev_dataset = preprocessed_dev_dataset.map(vectorize_text)
train_dataset = vectorized_dev_dataset.map(
lambda english, japanese: ((english, japanese[:-1]), japanese[1:]),
).cache("./dataset/cache/train").shuffle(100 * BATCH_SIZE).batch(BATCH_SIZE)
for (english_batch, japanese_batch), japanese_batch_out in train_dataset.take(1):
print(english_batch.shape, japanese_batch.shape, japanese_batch_out.shape)
# (512, 64) (512, 64) (512, 64)
テストデータの準備
上記の方法をテストデータにも適用する。
# test dataset
raw_test_dataset = tf.data.TextLineDataset('dataset/split/test').cache()
preprocessed_test_dataset = raw_test_dataset.map(tf_preprocess, num_parallel_calls=tf.data.experimental.AUTOTUNE)
vectorized_test_dataset = preprocessed_test_dataset.map(vectorize_text)
test_dataset = vectorized_test_dataset.map(
lambda english, japanese: ((english, japanese[:-1]), japanese[1:]),
).cache("./dataset/cache/test").shuffle(100 * BATCH_SIZE).batch(BATCH_SIZE)
for (english_batch, japanese_batch), japanese_batch_out in test_dataset.take(1):
print(english_batch.shape, japanese_batch.shape, japanese_batch_out.shape)
# (512, 64) (512, 64) (512, 64)
モデルの構築
今回作成するモデルはこのようになる。
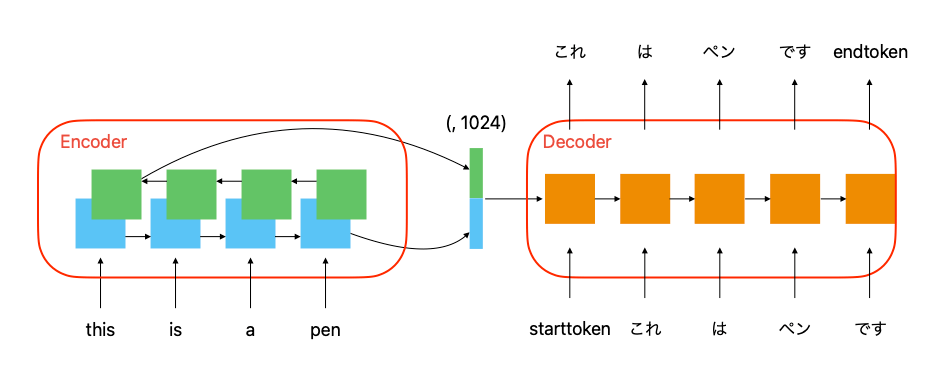
Encoder
以下の方法で Encoder を構築する。
HIDDEN_DIM=512
class encoder(Model):
def __init__(self):
super(encoder, self).__init__()
self.embedding = Embedding(VOCAB_SIZE, EMBEDDING_DIM)
self.gru = Bidirectional(GRU(HIDDEN_DIM))
def call(self, english_inputs):
english_inputs = self.embedding(english_inputs)
outputs = self.gru(english_inputs)
return outputs
今回は再帰型ニューラルネットの一種である GRU を用いる。Bidirectionalを用いて双方向から学習を行うのでこの Encoder の出力は HIDDEN_DIM の倍のサイズになる。
Decoder
以下の方法で Decoder を構築する。
class decoder(Model):
def __init__(self):
super(decoder, self).__init__()
self.embedding = Embedding(VOCAB_SIZE, EMBEDDING_DIM)
self.gru = GRU(HIDDEN_DIM * 2, return_sequences = True)
self.dense = Dense(VOCAB_SIZE, activation='softmax')
def call(self, japanese_inputs, encoder_outputs):
japanese_inputs = self.embedding(japanese_inputs)
hidden_sentences = self.gru(japanese_inputs, initial_state=encoder_outputs)
outputs = self.dense(self.dropout(
hidden_sentences
))
return outputs
GRU を HIDDEN_DIM の倍のサイズにし、途中の系列のデータを全て出力するように設定する。途中の系列のデータを Dence レイヤーに渡し文章の one-hot ベクトルが出力できるようにする。
seq2seq
Encoder と Decoder を組み合わせて seq2seq のモデルにする。
class seq2seq(Model):
def __init__(self, encoder, decoder):
super(seq2seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
def call(self, inputs):
english_inputs, japanese_inputs = inputs
encoder_outputs = self.encoder(english_inputs)
decoder_outputs = self.decoder(japanese_inputs, encoder_outputs)
return decoder_outputs
encoder = encoder()
decoder = decoder()
model = seq2seq(encoder, decoder)
model.build(
input_shape=[
(None, ENGLISH_SEQUENCE_LENGTH),
(None, JAPANESE_SEQUENCE_LENGTH)
]
)
model.summary()
モデルの出力は one-hot ベクトルであり、正解ラベルは自然数のため損失関数は sparse_categorical_crossentropy を用いてモデルを学習させる。
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_dataset, validation_data=test_dataset, epochs=10, shuffle=True)

モデルの検証
以下のコードで推論を行う。
def translator(english_sentence):
tokenized_english_sentence = english_vectorization_layer([
english_sentence
])
encoder_outputs = encoder(
tokenized_english_sentence
)
japanese_sentences = ["starttoken"]
for i in range(1, JAPANESE_SEQUENCE_LENGTH + 1):
tokenized_japanese_sentence = japanese_vectorization_layer([
" ".join(japanese_sentences)
])[:, :i]
decoder_outputs = decoder(
tokenized_japanese_sentence,
encoder_outputs
)
decoder_outputs_last_token = tf.argmax(decoder_outputs, axis=-1)[0, -1]
decoder_outputs_last_word = japanese_vocabulary[decoder_outputs_last_token]
japanese_sentences.append(decoder_outputs_last_word)
if decoder_outputs_last_word == 'endtoken':
break
return "".join(japanese_sentences[1:-1])
encoder で英語を潜在ベクトル化し、decoder で一つずつ日本語を推論していく。実験結果は次のようになった。
print(translator("this is a pen."))
print(translator('i am a student'))
print(translator("i love you."))
print(translator("what are you doing?"))
これはペンだ
私は学生だ
愛してる
何をしてるんだ
結構いい感じに翻訳できている。
テストデータに対して推論すると次のようになった。
raw_test_dataset = tf.data.TextLineDataset('dataset/split/test').cache()
for data in raw_test_dataset.shuffle(2000).take(5):
english_sentence, japanese_sentence = data.numpy().decode().split('\t')
print("english: ", english_sentence)
print("translated: ", translator(english_sentence)[10:-8])
print("japanese: ", japanese_sentence)
print("---")
english: or the relative risk of drugs
translated: あるいは[UNK]のリスクを
japanese: ほぼ無関係です
---
english: gail, are you drunk?
translated: ゲイル
japanese: ゲイル 酔ってる?
---
english: be careful.
translated: 気をつけて
japanese: 注意しろ
---
english: last withdrawal was five days ago.
translated: 最後の5日前には[UNK]だ
japanese: 最後の引き出しが 5日前にあった
---
english: unless i kill myself and complete your story.
translated: 私があなたの話をしなければ
japanese: 僕が自殺し 物語を完成させる
---
おわりに
再帰型ニューラルネットを用いて機械翻訳を作成した。短い文章に対しては結構いい感じに翻訳できている。私の英語力よりは強いかもしれない。これは使ったデータセットが大きいもののために、試験に使った文章はそもそもデータセット内に含まれていることが考えられる。一方で、再帰型ニューラルネットの威力も感じた。Encoder として使えば短い文章を 1024 次元の実ベクトルに落としこむことができ、Decoder として使えば文法的に正しい日本語を出力できるという点がすごいと思った。
翻訳の結果を見てて思うのが、文意を 1024 次元に落とし込んでから再度展開するので、細かい単語の違いを取り出すことができていないように思う。そのため Encoder でもreturn_sequences = Trueにして、各層の出力を Decoder の入力に良い感じに回すことで翻訳精度を改善できそうな気がした。それを形にしたのが Attention だと思うので、こちらも勉強したい。
さらなる改善として Subword Units や SentencePiece を利用して出現数が少ない単語にも対応できるようにすることが考えられる。最近では、形態素解析ではなくこちらを用いることの方が多いそうなのでこちらも勉強したい。
Discussion