Cortex Framework for SAP をDeployしてみた
本記事ではSAP cortex Frameworkを使用してSAPのデータをBigQueryでデータ分析できるようにしていきたいと思います!!
とは言いつつも、正直自分はSAPに関する知識はかなり素人レベルです、なんとなくSAPのデータをBigQueryでデータ分析しやすくできるFrameworkがあるという噂を聞きつけ、実際にはどんな感じで使えるのかを試行錯誤しながらその実態を掴んでいきたいと思います。
まずは、ざっくりSAP cortex Frameworkとは?
まだ触れてもないので、よくわかっていない前提ですが、
SAP cortex frameworkはSAPのぱっと見わかりにくいデータを人間が見ても分かるようにするためのFrameworkと理解しています!
めちゃくちゃ雑な例えですが、以下のような記号があったときに人間は「何じゃこの英単語の羅列」となりますよね。
bsk
sccr
swm
それを人間が見てもわかりやすく変換するもの。(それに加えて、データ加工も入ってきますので、厳密には間違えています。が今は一旦置いておきます)
bsk → バスケットボール
sccr → サッカー
swm → スイミング
ここまではOKデスネ?恐ろしくざっくりな説明です。
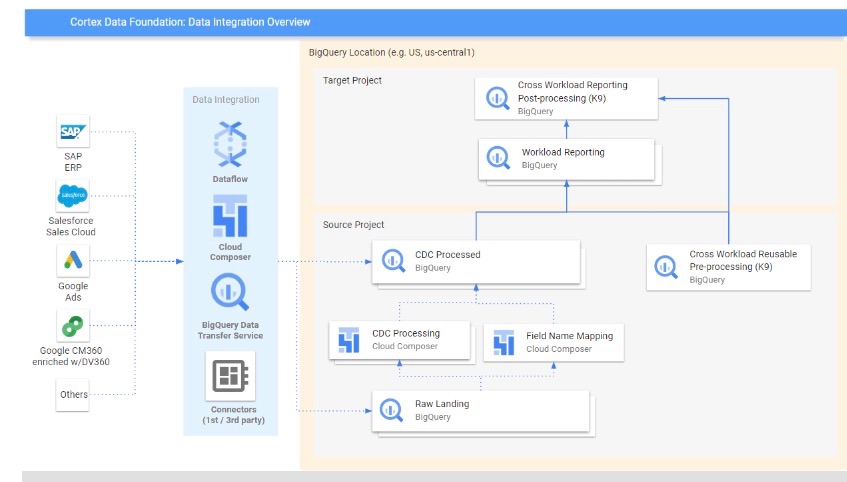
実際にはここのER図のようになります。
そしてなぜそれがフレームワークと呼ばれるのか?というと
そのデータの変換をするために、GCPのサービスが色々とパッケージ化された形で詰まっているからです。
これがCortex Frameworkの中身です。
で、す、が!!!
ここではまだこのアーキテクチャは頭の隅にも置いておくだけでOKです。
何となくBigQueryやCloud Composerなどのコンポーネントが組み合わされたものと言うところまでの理解でOKです。
Cortex frameworkの使い方
Cortex frameworkはGithub上で公開されているフレームワークなので、自身のGCP環境にテンプレートを展開してBuildすることができます。
Google Cloud Cortex Framework for SAPを実際に使ってみる
⓪ 前提条件 - Prerequisites -
-必要なもの-
GCPのプロジェクトを最低限一つ作成しておく (*本番環境では、Rawデータを入れるプロジェクトとデータ加工後のデータを入れるプロジェクトを分けておくのが推奨)
BigQueryのDatasetを作れる状態にしておく (おそらくDefaultで使える状態)
-必ずしも必要ではないもの-
k9 deployer等でデータソースごとの設定をするようだが、テストデータを使用する場合には不要らしい。← 今回やってみて結果不要だった。
対象SAP
SAP cortex framework でカバーしているのは
SAP ECC
SAP HANAです。もちろん、RISE環境であっても対象です (特にon GCP、on Azure、on AWSなど問いません。)
git cloneでrepositoryをclone
まずはGCPのコンソールに入って、Cloud Shellをオープン!!
以下のコマンドを実行します。
git clone --recurse-submodules https://github.com/GoogleCloudPlatform/cortex-data-foundation
cortex-data-foundationというフォルダーが自身のGCP環境にコピーされました。
では、そのフォルダーの配下に移動してみましょう。
cd cortex-data-foundation
lsコマンドで覗いてみると、以下のようにいくつかデプロイするためのファイルが確認できますね。
$ ls
1_click.sh cloudbuild.yaml config deploy.sh docs images LICENSE README.md RELEASE_NOTES.md requirements.in requirements.txt src support.sh
① GCP環境の設定
必要なGCPコンポーネントをEnableする
Cloud Shellで一気にコンポーネントをEnableしていきます。
以下のコマンドでBigQuery、Cloud Build、Cloud Composer、Cloud Storage、Cloud resource manager、DataflowをEnableにしています。
gcloud config set project <SOURCE_PROJECT>
gcloud services enable bigquery.googleapis.com \
cloudbuild.googleapis.com \
composer.googleapis.com \
storage-component.googleapis.com \
cloudresourcemanager.googleapis.com \
dataflow.googleapis.com
出力例
Updated property [core/project].
Operation "operations/acat.p2-598927097921-1e5c0737-b04b-4cdc-81b2-adf1c9317d19" finished successfully.
必要な権限の付与
念の為、Cortex frameworkを実行するユーザーに必要な権限をここに記載しておきます。
Service Usage Consumer
Storage Object Viewer for the Cloud Build default bucket or bucket for logs
Object Writer to the output buckets
Cloud Build Editor
Project Viewer or Storage Object Viewer
ちなみにService Accountを作成して、そのSAに実行権限を付与して実行するということも可能です!
Cloud Buildアカウントの設定
Cloud Buildのサービスアカウントに必要な権限を付与していきます。
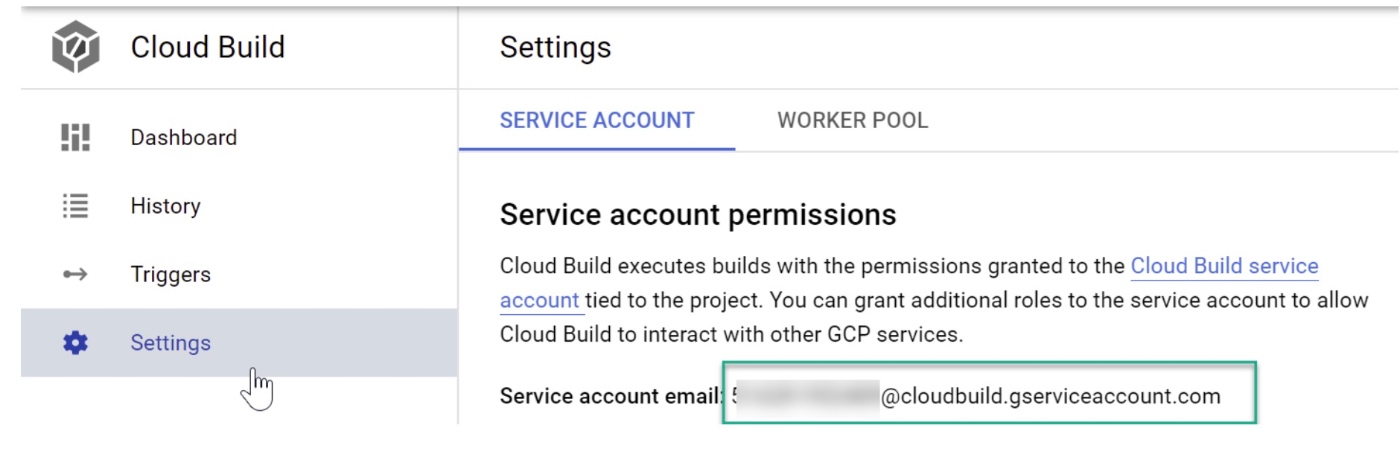
必要な権限は以下の三つ
BigQuery Data Editor
BigQuery Job User
Storage Object Admin (ログをGCSのバケットに出力するために必要)

上記のように権限がついていたらOK!!
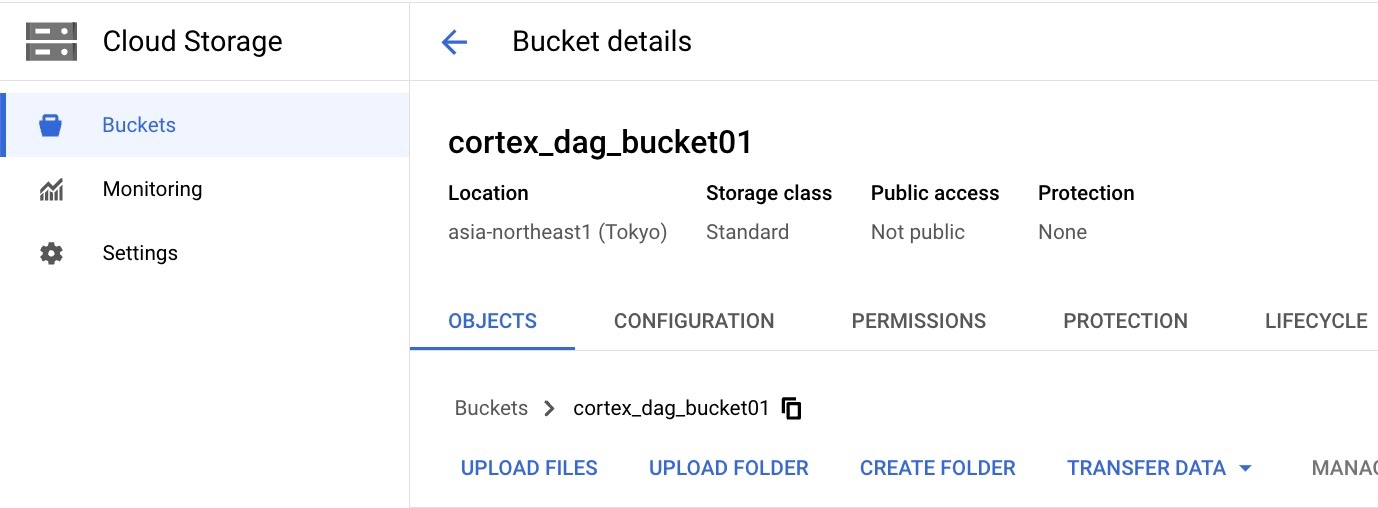
DAG関連のファイルを入れておくためのGCSのバケット作成
BigQueryのデータセット同じリージョンにBucketを作成する。
DAG関連のデータがこのバケットに自動で生成されます。
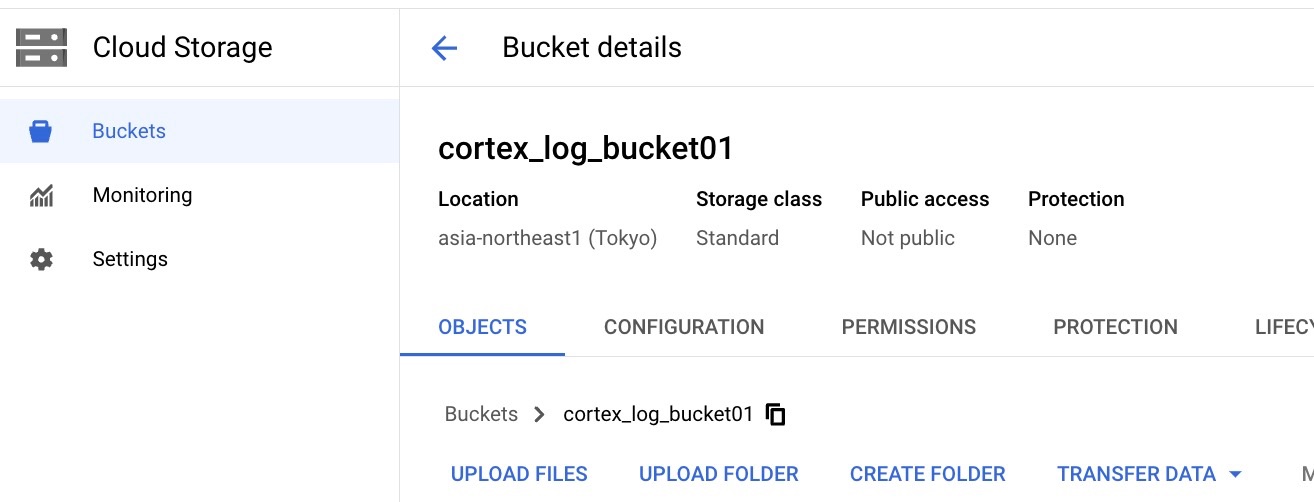
ログの管理のためGCSのバケット作成
BigQueryのデータセット同じリージョンにBucketを作成する。
Cloud Buildのプロセスの過程で出力されたログが入ります。
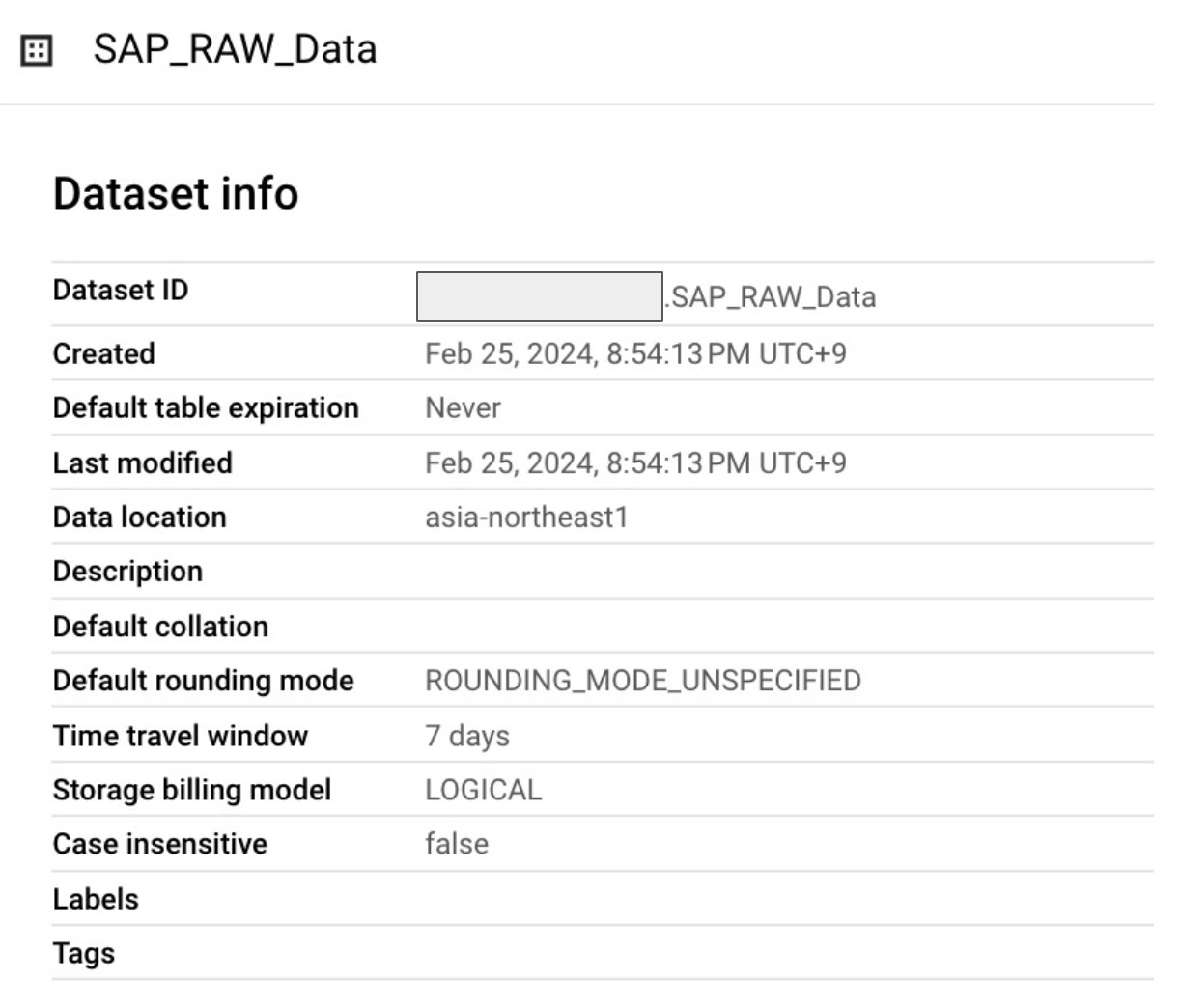
RawデータとCDCデータが入るBigQuery Datasetを作成
Rawデータが入るようのDatasetを作成しておく。リージョンはasia-northeast1 (Tokyo)
Cortexはどこのリージョンにも対応しています
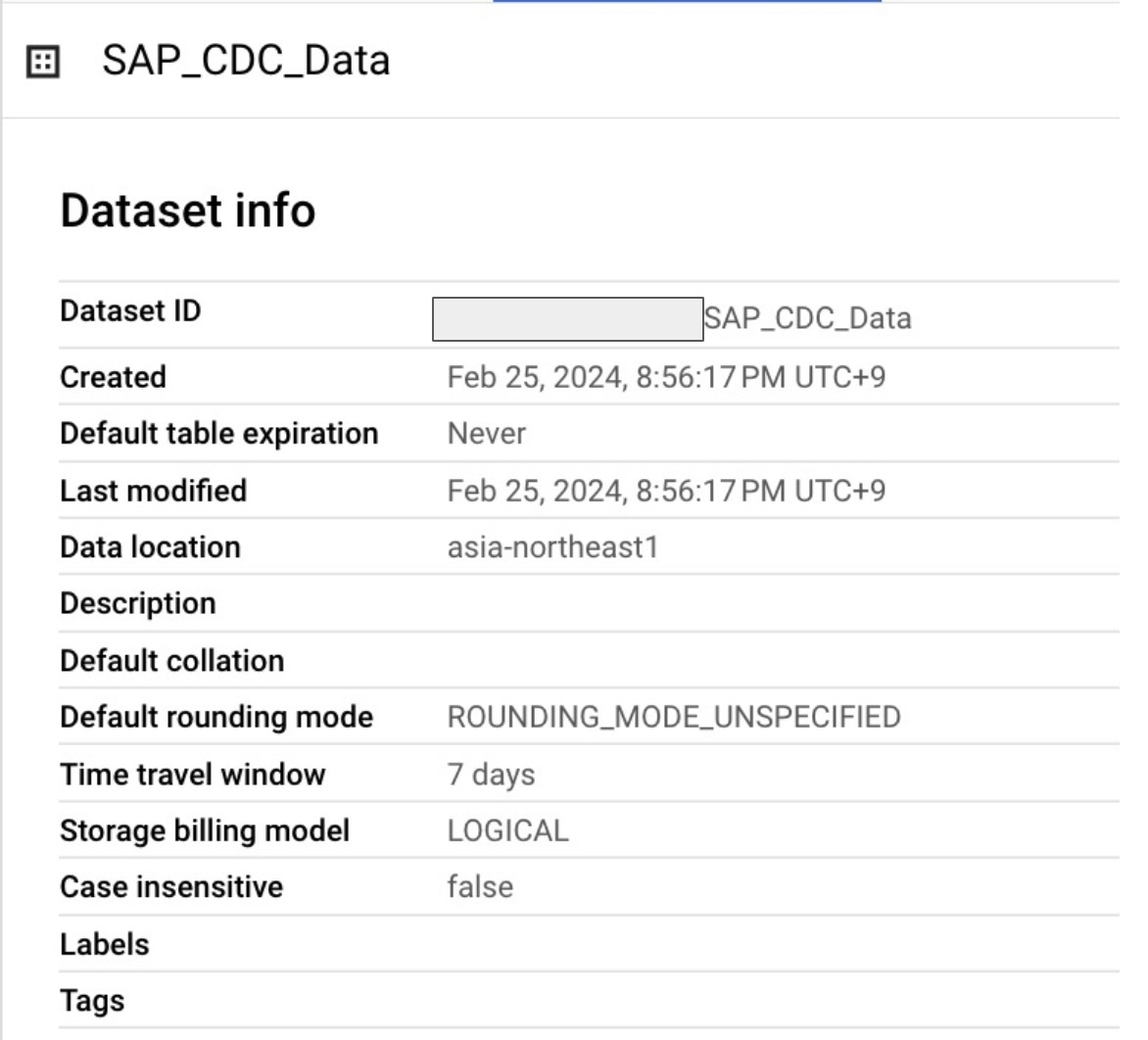
CDCの転送先のDatasetを作成しておく。リージョンはasia-northeast1 (Tokyo)
Cortexはどこのリージョンにも対応しています
- データ連携ツールで差分連携する場合はこのデータセットは不要
Data Meshを作成する (Data Meshが不要の場合はスキップ可能)
一旦このステップはテストなのでスキップして実行してみます。
今後実施した際にはここを埋めたいと思います!
②Deploymentの設定
config.jsonファイルの確認
Cortex Frameworkのdeploymentはconfig.jsonふぁいるで管理されています。
./cortex-data-foundation/config/config.json ← の中に入っています。
なのでまずはそのディレクトリーに移動してみましょう!
$ cd cortex-data-foundation/config
$ ls
config_default.json config.json
config.jsonの説明
config.jsonは以下のように二つのパートに分かれています。
① Global Deployment ParametersがSAPに限らず、Cortex Framework全体のパラメータを設定する項目です
② Workload Specific ParametersはSAPなどのWorkload個別のパラメータを設定する項目です
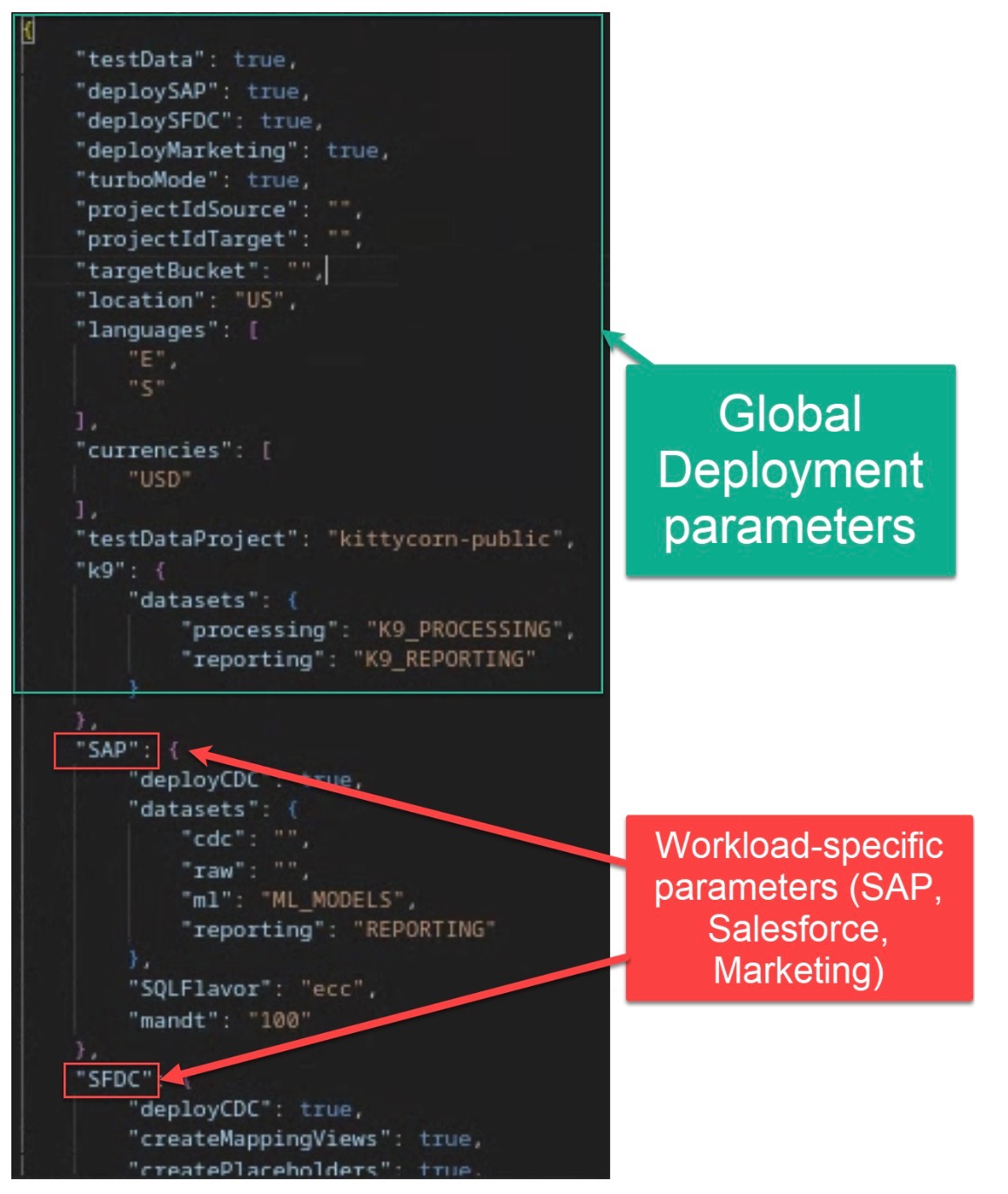
config.jsonのDefaultパラメータの項目
config.jsonのパラメータの中身は以下のリンク先から確認できます。
| パラメータ | 意味 | デフォルト値 | 説明 |
|---|---|---|---|
| testData | テストデータの配置 | true | ソースデータが配置され、ビルドが実行されるプロジェクト |
| deploySAP | SAPの展開 | true | SAPワークロード(ECCまたはS/4HANA)の展開を実行するか |
| deploySFDC | Salesforceの展開 | true | Salesforceワークロードの展開を実行するか |
| deployMarketing | マーケティングの展開 | true | マーケティングソース(Google Ads、CM360、TikTok)の展開を実行するか |
| deployDataMesh | Data Meshの展開 | true | Data Meshの展開を実行するか。詳細はData Mesh READMEを参照 |
| turboMode | ターボモード | true | すべてのビューを単一のCloud Buildプロセス内の1ステップとして並行して、高速に展開する。falseに設定されている場合、各レポートビューは個々のシーケンシャルビルドステップで生成される。テストデータを使用する場合、またはレポート列とソースデータ間の不一致が修正された場合にのみ、trueに設定することを推奨 |
| projectIdSource | ソースプロジェクトID | - | ソースデータセットが存在し、ビルドが実行されるプロジェクト |
| projectIdTarget | ターゲットプロジェクトID | - | ユーザー向けのデータセット(レポート用と機械学習用)のプロジェクト |
| targetBucket | ターゲットバケット | - | DAGスクリプトの保存先(Dataflowの一時ファイルも)。事前に作成されたバケットを指定する。実際のAirflowバケットの使用は避ける |
| Location | ロケーションまたはリージョン | "US" | BigQueryデータセットやGCSバケットが存在するロケーション |
| languages | フィルタリング言語 | [ "E", "S" ] | テストデータを使用しない場合は、ビジネスに関連する単一言語(例:「[ "E" ]」)または複数言語(例:「[ "E", "S" ]」)を入力する。SQLの中でプレースホルダを置き換えるために使用される(現在はSAPのみ対応 - 詳細はERDを参照) |
| currencies | フィルタリング通貨 | [ "USD" ] | テストデータを使用しない場合は、ビジネスに関連する単一通貨(例:「[ "USD" ]」)または複数通貨(例:「[ "USD", "CAD" ]」)を入力する。SQLの中でプレースホルダを置き換えるために使用される(現在はSAPのみ対応 - 詳細はERDを参照) |
| testDataProject | テストデータ用プロジェクト | kittycorn-public | デモ用配置のテストデータのソース。testDataがtrueの場合に適用 |
| k9.datasets.processing | K9 データセット – 処理 | "K9_PROCESSING" | K9設定ファイルで定義されているクロスワークロードテンプレート(例:日付項目)を実行する。通常、これらは下流のワークロードで必要となる |
| k9.datasets.reporting | K9 データセット – レポーティング | "K9_REPORTING" | K9 設定ファイルで定義されているクロスワークロードテンプレートおよび外部データソース(例:天気)を実行する。デフォルトではコメントアウト |
| DataMesh.deployDescriptions | Data Mesh – アセットの説明 | true | BigQueryアセットスキーマの説明を展開する |
| DataMesh.deployLakes | Data Mesh – レイクとゾーン | false | 処理レイヤーによってテーブルを整理するDataplexのレイクとゾーンを展開する。有効にする前に設定が必要 |
| DataMesh.deployCatalog | Data Mesh – カタログのタグとテンプレート | false | BigQueryアセットやフィールド上のカスタムメタデータを許可するData Catalogタグを展開する。有効にする前に設定が必要 |
| DataMesh.deployACLs | Data Mesh – アクセス制御 | false | BigQuery アセットに対するアセット、行、または列レベルのアクセス制御を展開する。有効にする前に設定が必要 |
SAP独自のパラメータ項目
| パラメータ | 意味 | デフォルト値 | 説明 |
|---|---|---|---|
| SAP.deployCDC | CDC展開 | true | Cloud Composer内でDAGとして実行するためのCDC処理スクリプトを生成する |
| SAP.datasets.raw | 生データセット | - | CDCプロセスによって使用され、SAPからのデータをレプリケーションツールが格納する場所。テストデータを使用する場合は、空のデータセットを作成する |
| SAP.datasets.cdc | CDC処理済みデータセット | - | レポートビュー用のソース、および処理済みDAGのターゲットとなるデータセット。テストデータを使用する場合は、空のデータセットを作成する |
| SAP.datasets.reporting | レポーティングデータセット | "REPORTING" | エンドユーザーがレポート作成に利用できるデータセット名。ビューやユーザー向けのテーブルが配置される |
| SAP.datasets.ml | MLデータセット | "ML_MODELS" | 機械学習アルゴリズムやBQMLモデルの結果をステージングするデータセット名 |
| SAP.SQLFlavor | ソースシステムのSQL形式 | "ecc" | s4またはecc。テストデータの場合はデフォルト値(ecc)のままにする。Demand Sensingでは、現時点ではeccテストデータのみが提供されている |
| SAP.mandt | MandantまたはClient | "100" | SAPのデフォルトのMandantまたはClient。テストデータの場合はデフォルト値(100)のままに。Demand Sensingでは、900を使用する |
config.jsonファイルを編集
デフォルト値は前段で説明しました。
editコマンドで以下のようにconfig.jsonファイルを編集します。
edit config/config.json
よくあるパターンとして、CDCをデータ連携ツールで実装するパターンがあります。
例えば、FivetranなどのツールでSAPのデータをBigQueryに差分連携するパターンです。その場合はcdcレイヤーのデータセットは不要なので、
以下のjsonファイルの"cdc"と"raw"部分は同じデータセット名を指定します。
"cdc": "SAP_CDC_Data"
"raw": "SAP_RAW_Data"
(参考情報)
cortex frameworkのcdcとrawレイヤーの2層構造になっている理由は、データ連携ツールで差分連携しない場合に用意されています。データ連携ツールでRAWデータをとりあえずBigQueryのRAWデータセットに貯めていき、CDCデータセットにはRAWに更新された差分だけを取り込んでいき、そして最終的にそのCDCの差分のみReportingレイヤーに反映されるという仕組みになっています。
{
"testData": true,
"deploySAP": true,
"deploySFDC": false,
"deployMarketing": false,
"deployDataMesh": false,
"turboMode": true,
"projectIdSource": "myproject",
"projectIdTarget": "myproject",
"targetBucket": "cortex_dag_bucket01",
"location": "asia-northeast1",
"languages": [
"E",
"S"
],
"currencies": [
"USD"
],
"testDataProject": "kittycorn-public",
"k9": {
"datasets": {
"processing": "K9_PROCESSING",
"reporting": "K9_REPORTING"
}
},
"DataMesh": {
"deployDescriptions": true,
"deployLakes": false,
"deployCatalog": false,
"deployACLs": false
},
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "SAP_CDC_Data",
"raw": "SAP_RAW_Data",
"ml": "ML_MODELS",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
},
"SFDC": {
"deployCDC": true,
"createMappingViews": true,
"createPlaceholders": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_SFDC"
}
},
"marketing": {
"deployGoogleAds": true,
"deployCM360": true,
"deployTikTok": true,
"deployLiveRamp": true,
"dataflowRegion": "",
"GoogleAds": {
"deployCDC": true,
"lookbackDays": 180,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_GoogleAds"
}
},
"CM360": {
"deployCDC": true,
"dataTransferBucket": "",
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_CM360"
}
},
"TikTok": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_TikTok"
}
},
"LiveRamp": {
"datasets": {
"cdc": ""
}
}
}
}
③ Deploymentの実行
config.jsonが修正できたので、これをbuildしていきます。
$ cd cortex-data-foundation
$ gcloud builds submit --project <データソース側のプロジェクト> \
--substitutions=_GCS_BUCKET=<Cloud Buildのログ格納用のBucket>
$ cd cortex-data-foundation
$ gcloud builds submit --project myproject-363708 \
--substitutions=_GCS_BUCKET=cortex_log_bucket01
実行した後、ログのリンクが出力される。リンク先から実行状況を確認する

成功した場合にはこのようになる!
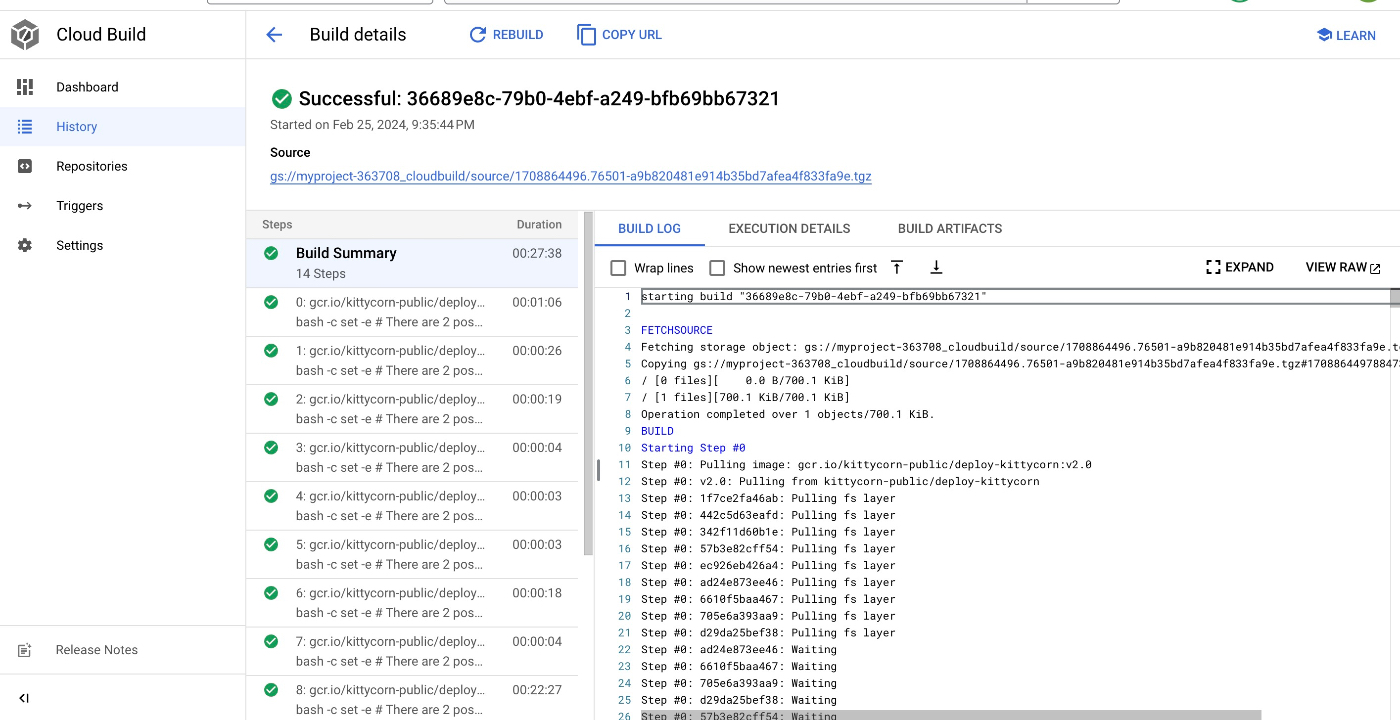
BigQueryで作成しておいたDatasetにデータが格納されていることを確認する。
Rawデータ側のテーブルにサンプルデータが格納されていることが確認できる。
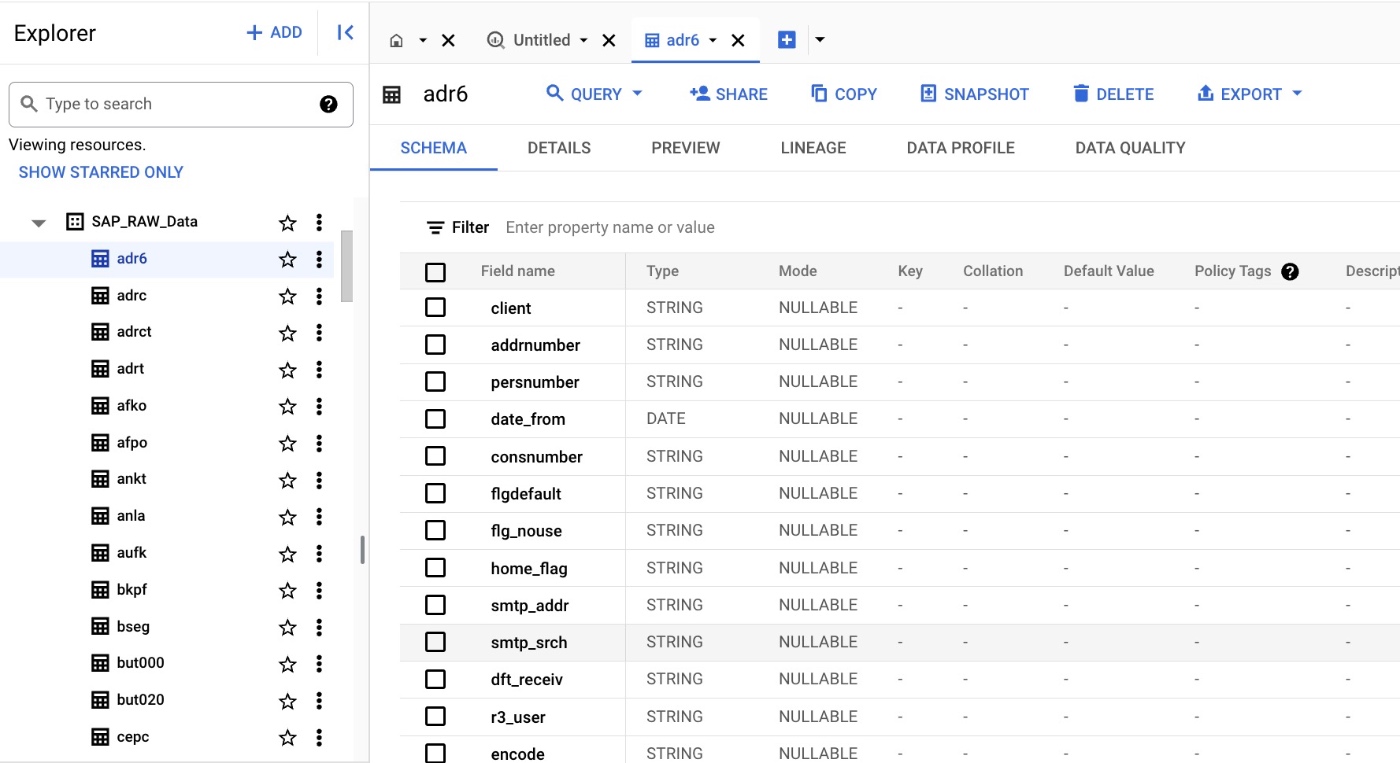
CDCのデータセットにもテーブルが格納されていることを確認。
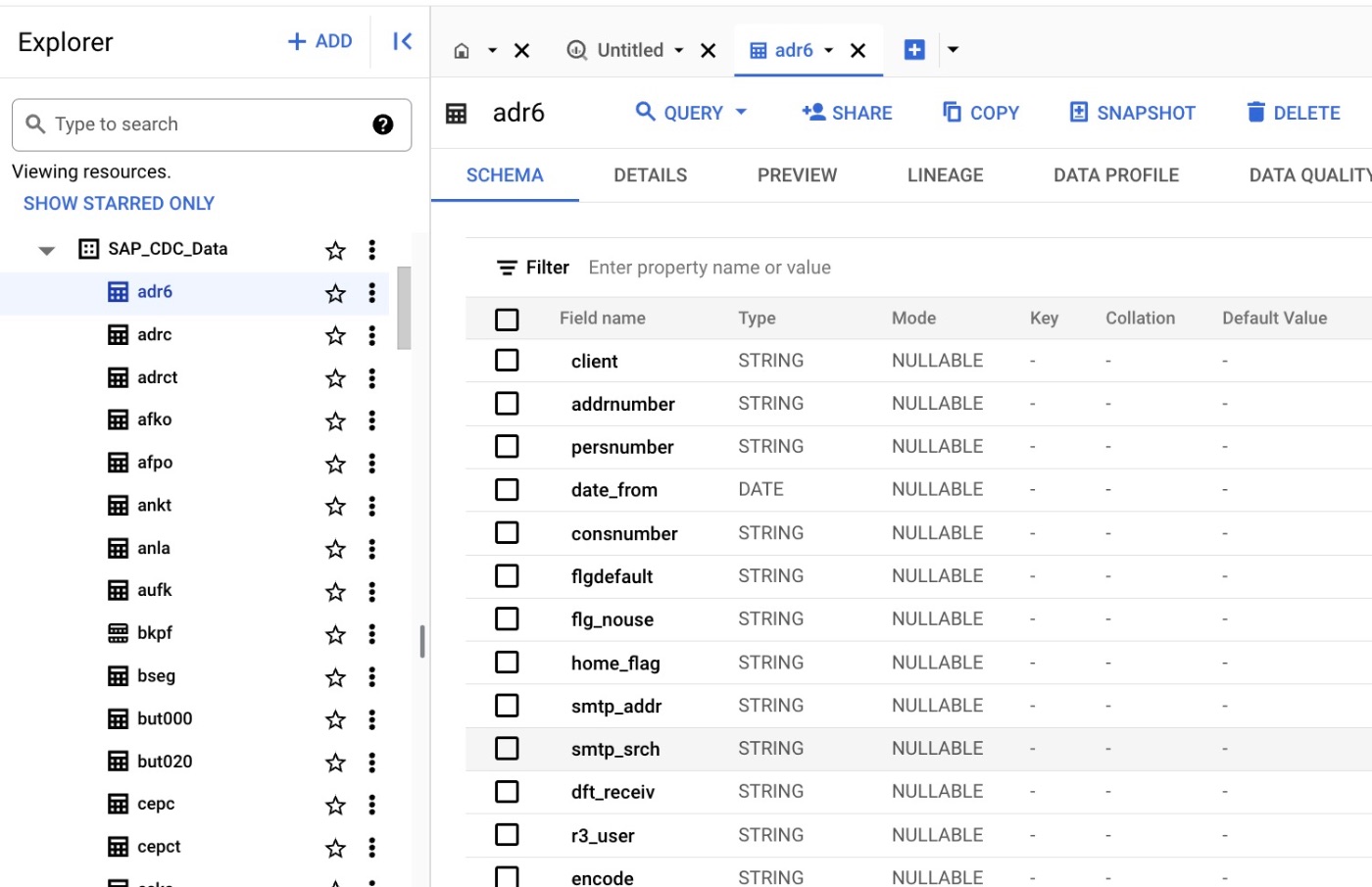
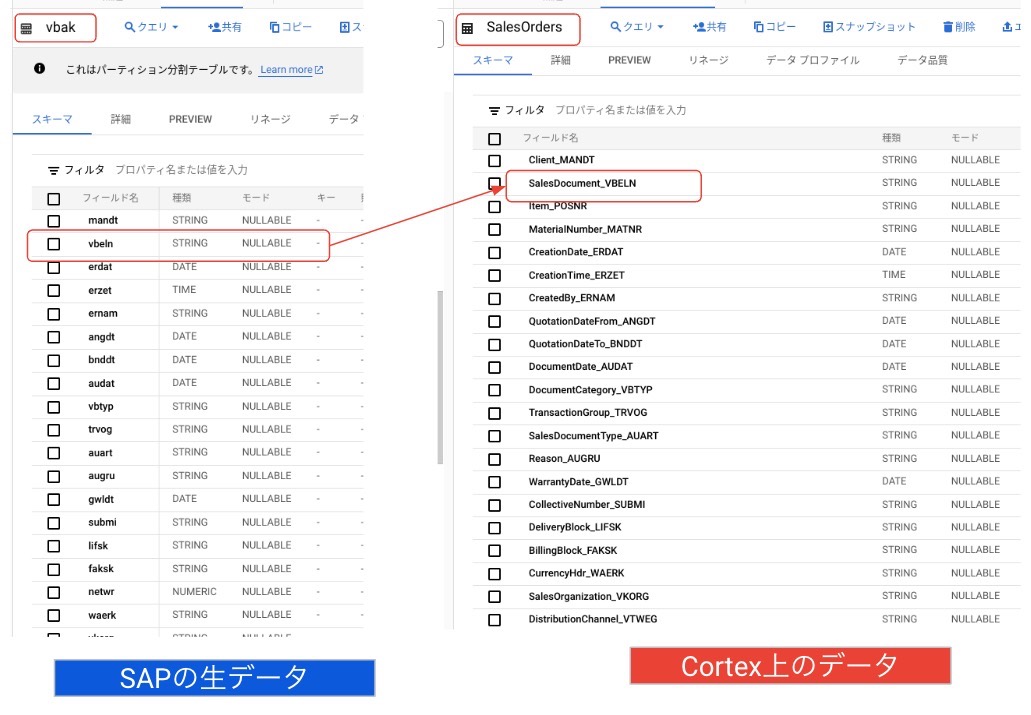
Reporting データセットには新しくSAP Cortex Frameworkによって生成されたReporting用のテーブルが作成されています。SAPのテーブル名ではなく、ある程度どんなテーブルなのかがわかるようになっています。

データのマッピングの一例として、以下のようなデータマッピングになっています。SAPの生データは知る人ぞ知る構造になっているかと思いますが、幾分わかりやすい名前にも変更されています。
まとめ
ということで、ひとまずはサンプルデータを用いてシンプルにDeployするところまでをやりました。
大事なことなのでもう一回言います。
SAPからのデータ抽出はCortexの範囲外です!!
Cloud Data FusionやFivetranなどの3rd party toolでSAPのRAWデータを別途連携する必要があります。そこはご留意いただければと思います
SAPのデータ加工をしている方ともよくお話をしますが、データ加工ロジックの作成が非常に大変だとよくお聞きします。
それをCortex frameworkを一発Buildするだけでここまで作成されるのは非常に便利だと感じました。
続いて、Reportingデータセットのテーブルを使用して、Lookerでそのまま可視化ができるようなので、それを試してみました。
続きはこちら
Discussion