レコメンドシステム—— アーキテクチャと処理フローの体系的解説
シリーズの目次
レコメンドシステムのシリーズをここにまとめています。
はじめに
レコメンデーションシステムの普及
現代のデジタル社会において、レコメンデーションシステムは私たちの日常生活に不可欠な存在となっています。その影響力は様々な領域で顕著に表れています:
Eコマースプラットフォームでは、ユーザーの購買履歴や閲覧パターンを分析し、個々の顧客の興味や需要に合致した商品を提案することで、購買意欲の促進と顧客満足度の向上を実現しています。
デジタルメディアの分野では、読者の興味関心や閲覧習慣に基づいて、パーソナライズされたニュースフィードを提供することで、情報消費の効率化とユーザーエンゲージメントの強化を図っています。
動画配信プラットフォームにおいては、視聴履歴や評価データを活用して、ユーザーの嗜好に沿ったコンテンツを推薦することで、サービス滞在時間の延長とコンテンツ消費の最適化を達成しています。
システムの本質的課題
現代のデジタルプラットフォームが直面する最も重要な課題の一つは、膨大な量のコンテンツ(多くの場合、数千万規模)から、いかにして各ユーザーにとって最も価値のあるコンテンツを適切なタイミングで提供するかということです。この課題に対処するため、以下のような複雑な要素を考慮した精密な推薦メカニズムが構築されています:
- ユーザーの明示的な行動(クリック、購入、評価など)
- 暗黙的なフィードバック(閲覧時間、スクロール挙動など)
- コンテキスト情報(時間帯、デバイス、位置情報など)
- コンテンツの特性(カテゴリ、タグ、メタデータなど)
これらの要素を統合的に分析し、効率的かつ効果的な推薦を実現するシステムの構築が求められています。
システムアーキテクチャ
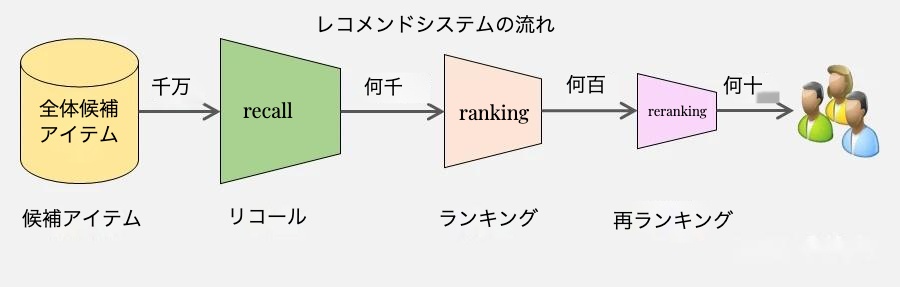
3段階の推薦プロセス
現代の推薦システムは、効率性と精度を両立させるため、通常3つの段階的なフェーズで構成されています。各フェーズは特定の目的を持ち、全体として有機的に機能するように設計されています:
1. リコールフェーズ(Recall)
このフェーズは、推薦プロセスの入り口として極めて重要な役割を果たします:
目的:
- 膨大な候補群から、ユーザーの潜在的興味に合致する可能性の高いアイテムを高速に抽出
- 後続のランキングフェーズで扱える規模までの効率的な絞り込み
特徴:
- 計算効率を重視した軽量な特徴量の使用
- 高速なアルゴリズムの採用(近似最近傍探索など)
- スケーラビリティを考慮した分散処理の実装
2. ランキングフェーズ(Ranking)
このフェーズは推薦システムの中核として機能し、リコールフェーズで選別された候補に対して精密な評価を行います:
目的:
- ユーザーの興味関心に最も適合する商品やコンテンツの特定
- 各候補アイテムの詳細なスコアリングと順位付け
特徴:
- 豊富な特徴量(ユーザー属性、行動履歴、コンテキスト情報など)の活用
- 高度な機械学習モデル(DeepFM、Wide & Deepなど)の適用
- ビジネス目標との整合性を考慮した最適化
役割:
- 個々のユーザーに対する推薦アイテムの適合度を定量的に評価
- 複数の評価基準を統合した総合的なランキングの生成
3. 再ランキングフェーズ(Re-ranking)
最終フェーズとして、ユーザー体験と事業戦略の両面から推薦リストを最適化します:
実装要素:
- 重複コンテンツの制御:類似したアイテムの適度な分散配置
- 新鮮さの確保:既読コンテンツの除外や新規コンテンツの戦略的配置
- 多様性の実現:異なるカテゴリやジャンルのバランス調整
- 戦略的配置:プロモーションコンテンツや特定カテゴリの露出度管理
役割:
- ユーザー体験の質的向上
- ビジネス要件との整合性確保
- 推薦の多様性と新規性の担保
システムの特徴
推薦システムの各フェーズは、それぞれ異なる最適化目標を持ちます:
リコール:
- 処理速度の最適化が最優先
- スケーラビリティの確保が重要
- 適度な再現率(recall rate)の維持
ランキング:
- 予測精度の最大化を追求
- 複雑なモデルの活用が可能
- 詳細な特徴量の利用
リコール(Recall)フェーズの設計と実装
基本概念と目的
リコールフェーズは、推薦システムの最初の関門として極めて重要な役割を担っています。数百万から数千万に及ぶ候補アイテムの中から、ユーザーの潜在的な興味に合致する可能性の高いアイテムを効率的に選別する必要があります。
このフェーズで特に重要となる要素は以下の3点です:
- 処理速度の最適化
- ミリ秒単位での応答が要求される
- 大規模データの効率的な処理が必須
- メモリ使用量の最適化が重要
- 適度な精度での候補抽出
- 後続のランキングフェーズに十分な質の候補を提供
- 真の興味対象を取りこぼさない再現率の確保
- ノイズの適度な制御
- スケーラビリティの確保
- データ量の増加に対する耐性
- 分散処理による処理能力の向上
- システムリソースの効率的な活用
システムアーキテクチャ
オフライン・オンライン統合アプローチ
効率的なリコールを実現するため、システムはオフラインとオンラインの処理を巧みに組み合わせます:
オフライン処理では:
- 大規模な候補アイテムの事前分析と特徴抽出
- 効率的な検索を可能にするインデックス構造の構築
- 計算コストの高い処理の事前実行と結果のキャッシュ化
オンライン処理では:
- キャッシュされた計算結果の効率的な活用
- リアルタイムデータの軽量な処理
- ミリ秒オーダーでのレスポンス生成
マルチパスリコール戦略
効果的な推薦を実現するため、異なるアプローチを組み合わせた多層的なリコール戦略を採用することが一般的です。この戦略により、様々な角度からユーザーの興味を捉えることが可能となります:
- トレンドベースのリコール
このアプローチでは、現在のトレンドや人気度に基づいてコンテンツを抽出します。具体的には、以下の要素を考慮します:
- 直近の閲覧数やエンゲージメント率
- 時間減衰を加味した人気度スコア
- 特定のユーザーセグメント内での流行度
- タグベースのリコール
ユーザーの興味を示すタグ情報を活用した推薦を行います:
- ユーザーの過去の行動から抽出した興味タグ
- 明示的に設定された好みのカテゴリ
- タグ間の関連性や階層構造の考慮
- コンテンツ類似性ベースのリコール
ユーザーの過去の行動履歴から類推を行います:
- アイテム間の内容的な類似度の計算
- 協調フィルタリングによる類似ユーザーの行動パターンの活用
- 潜在的な興味の発見
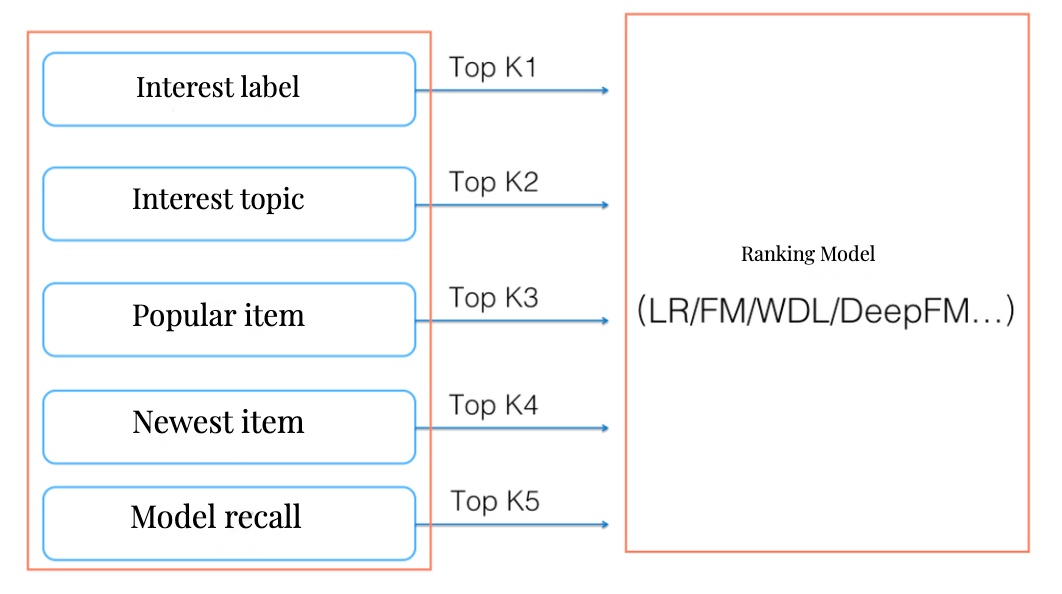
モデルベースのリコール実装
効率的なリコールを実現するためのアーキテクチャは、以下の主要コンポーネントで構成されます:
- 特徴量の分離処理
この段階では、ユーザーとアイテムの特徴を独立して処理します:
- ユーザー特徴:デモグラフィック情報、行動履歴、興味カテゴリなど
- アイテム特徴:コンテンツ属性、メタデータ、人気度指標など
- Embedding生成
特徴量を低次元の密なベクトル表現に変換します:
- 専用の深層学習モデルによる表現学習
- 意味的な類似性を保持した次元削減
- 効率的な検索を可能にする構造化
- オンライン検索の最適化
生成されたEmbeddingを用いて高速な類似度検索を実現します:
- Faissなどの近似最近傍検索エンジンの活用
- インデックス構造の最適化
- 分散処理による並列検索の実現
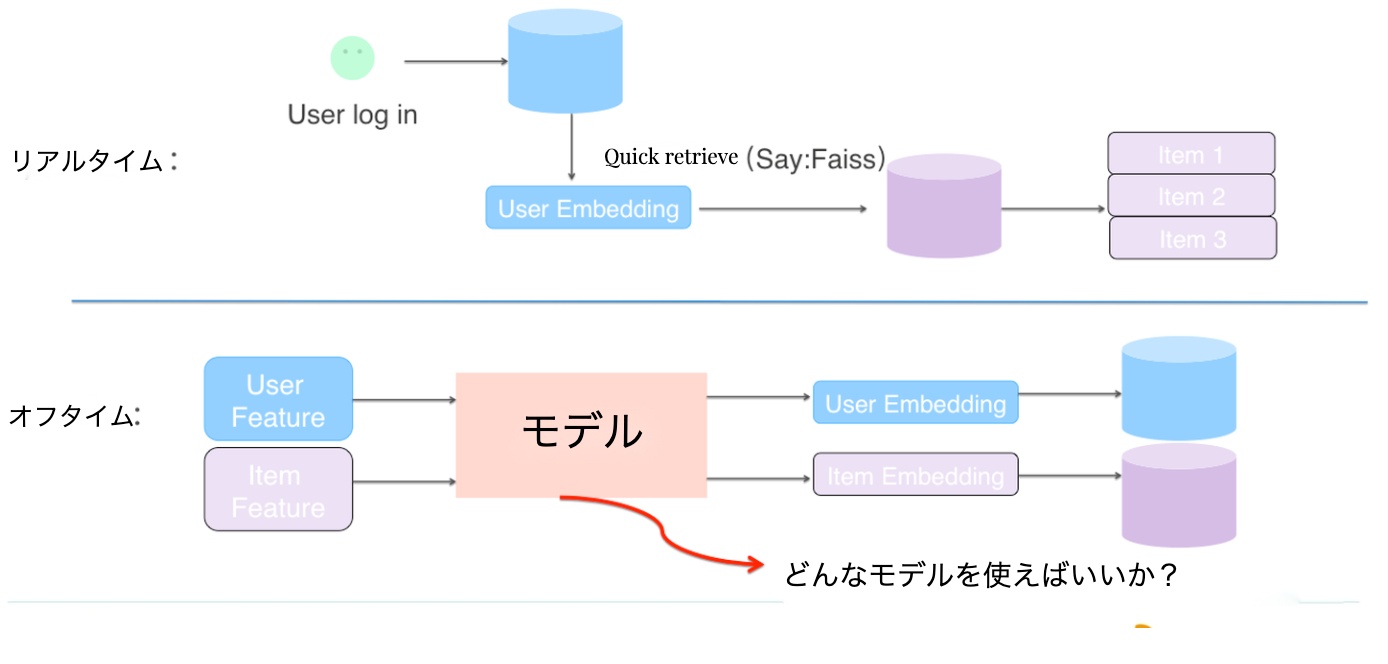
実装可能なモデル
リコールフェーズでは、効率性と精度のバランスを考慮した複数のモデルアプローチが採用可能です:
Factorization Machines (FM)は、特徴間の相互作用を効率的に学習できる優れたモデルです。スパースな入力データに対して特に効果を発揮し、計算効率と予測精度のバランスが取れているため、リコールフェーズでの活用に適しています。具体的な実装詳細は参考文献で解説しています:
Deep Neural Networks (DNN)は、複雑な非線形パターンの学習に優れており、豊富な特徴量が利用可能な場合に特に効果的です。ただし、計算コストとレイテンシーの観点から、リコールフェーズでの使用時には適切な最適化が必要となります。
Dual Tower Architectureは、ユーザー側とアイテム側の特徴を独立して処理する効率的な構造を持ちます。この分離アプローチにより、以下の利点が得られます:
- 特徴処理の並列化が可能
- スケーラビリティの向上
- 計算リソースの効率的な活用
- キャッシュ戦略の最適化
ランキング(Ranking)フェーズ
基本概念と役割
ランキングフェーズは、推薦システムの心臓部として機能します。リコールフェーズで選別された数千件の候補から、ユーザーの嗜好に最も適合する100件程度のアイテムを精密に選定する重要な役割を担います。
このフェーズが推薦システムの中核として重視される理由は主に二つあります:
- 計算リソースの効率的活用の観点から:
- 候補数が適度に絞られているため、複雑なモデルの適用が現実的
- 豊富な特徴量を活用した詳細な分析が可能
- 高度な予測アルゴリズムの実装が可能
- ビジネスインパクトの観点から:
- ユーザーに直接表示される推薦結果を決定
- クリック率や購買率などの重要KPIに直接的な影響
- ユーザー満足度を大きく左右
設計の重点
ランキングフェーズでは、リコールフェーズとは異なる設計の重点を置いています。ここでは、精度と予測品質の最大化が最優先事項となります。
- 特徴量の徹底的な活用
ランキングフェーズでは、利用可能なすべての情報を最大限に活用して、最適な推薦順序を決定します:
アイテム情報の活用:
- コンテンツの詳細な属性(カテゴリ、タグ、作成日時など)
- 品質指標(評価スコア、エンゲージメント率など)
- 時系列的な人気度の推移
ユーザー情報の統合:
- 基本的な属性情報(年齢、性別、地域など)
- 行動履歴(閲覧パターン、購買履歴など)
- 明示的なフィードバック(評価、レビューなど)
- 高度なモデリング
最新の機械学習技術を活用して、複雑な特徴間の相互作用を学習します。主要なモデルとしては:
DeepFMモデル:
- Factorization Machineの特徴と深層学習の利点を組み合わせ
- 低次と高次の特徴相互作用を同時に学習
- 自動的な特徴抽出能力の活用
Wide & Deepモデル:
- 記憶性(メモリゼーション)と汎化性(ジェネラリゼーション)の両立
- 線形モデルとニューラルネットワークの長所を統合
- 柔軟な特徴表現の学習
再ランキング(Re-ranking)フェーズ
必要性の背景
再ランキングフェーズが必要とされる主な理由は、ランキングモデルの特性に起因する課題を解決するためです。ランキングモデルは類似したコンテンツに似通ったスコアを付与する傾向があり、この結果以下のような問題が発生します:
視覚的な単調性:
- 同じカテゴリのコンテンツが連続して表示
- 類似した画像やサムネイルの連続
- ユーザーの視覚的疲労の蓄積
コンテンツの多様性の欠如:
- 特定のトピックへの偏り
- ユーザーの潜在的な興味の見落とし
- 探索的な推薦の機会損失
実装のアプローチ
再ランキングの実装には、システムの規模や要件に応じて様々なアプローチが考えられます。これらのアプローチは主に以下の3つの目的を達成するように設計されています:
- 多様性の確保
推薦リストの多様性を確保することは、ユーザー体験の質を大きく左右します。類似コンテンツの分散配置は、以下の方法で実現できます:
同一カテゴリの分散:
特定のカテゴリのコンテンツが連続して表示されることを防ぐため、カテゴリ間の最小距離を設定します。例えば、同じカテゴリのコンテンツは少なくとも3つ以上の間隔を空けて配置するといったルールを適用します。
トピック分散:
関連性の高いトピック同士も適度な距離を保って配置することで、ユーザーの興味の多様な側面に対応します。これにより、ユーザーは様々なジャンルやテーマのコンテンツに触れる機会を得ることができます。
- 表示の最適化
視覚的な体験を最適化することは、ユーザーエンゲージメントの向上に直接的に寄与します:
レイアウトの考慮:
画面内でのコンテンツの配置バランスを調整します。例えば、画像の大きさや向き、色調などの視覚的特徴を考慮して、見やすい配置を実現します。
コンテキストの活用:
閲覧デバイスや時間帯などのコンテキスト情報に基づいて、表示方法を動的に調整します。モバイルデバイスではよりコンパクトな表示を、大画面では豊富な情報を提供するといった最適化が可能です。
- システム規模に応じた実装
システムの規模や要件に応じて、適切な実装方法を選択することが重要です:
小規模システムの場合:
- シンプルなルールベースのアプローチを採用
- 基本的な分散ルールの適用
- 手動で調整可能なパラメータの設定
大規模システムの場合:
- 機械学習を活用した動的な最適化
- A/Bテストによる継続的な改善
- リアルタイムフィードバックの活用
データのアーキテクチャ
システム構造の多層性
推薦システムの設計において、機能的なアーキテクチャに加えて、データ処理方式に基づいた構造的な分類も重要な観点となります。このデータアーキテクチャは、システムの効率性と信頼性を大きく左右する要素です。
データ処理の観点から見ると、推薦システムは複数の層で構成されており、各層が異なる役割と特性を持っています。これらの層が有機的に連携することで、効率的かつ安定的なシステム運用が実現されます。
実践的課題:動画CTRの計算例
課題の所在
動画コンテンツのCTR(クリック率)を正確に計算し、それをモデルに反映させる過程には、いくつかの技術的な課題が存在します。これらの課題は、データの特性とシステムの制約から生じています:
- 統計的有意性の確保
この課題は、信頼性の高いCTR算出に必要な条件に関連しています:
データ収集期間の要件:
- 最低1週間程度の期間が必要
- 十分なサンプルサイズの確保
- 一時的なトレンドの影響の平準化
計算負荷の課題:
- 大量のログデータの処理
- 集計処理の複雑さ
- システムリソースの効率的な活用
- 厳格な時間制約
リアルタイム推薦において、システムには厳しい時間的制約が課せられます:
レスポンス時間の制限:
- 100ミリ秒以内での応答要求
- ユーザー体験への直接的な影響
- システム全体のパフォーマンスへの影響
特徴量準備の時間制約:
- データの前処理時間
- 計算結果のキャッシュ更新
- リアルタイムデータの統合
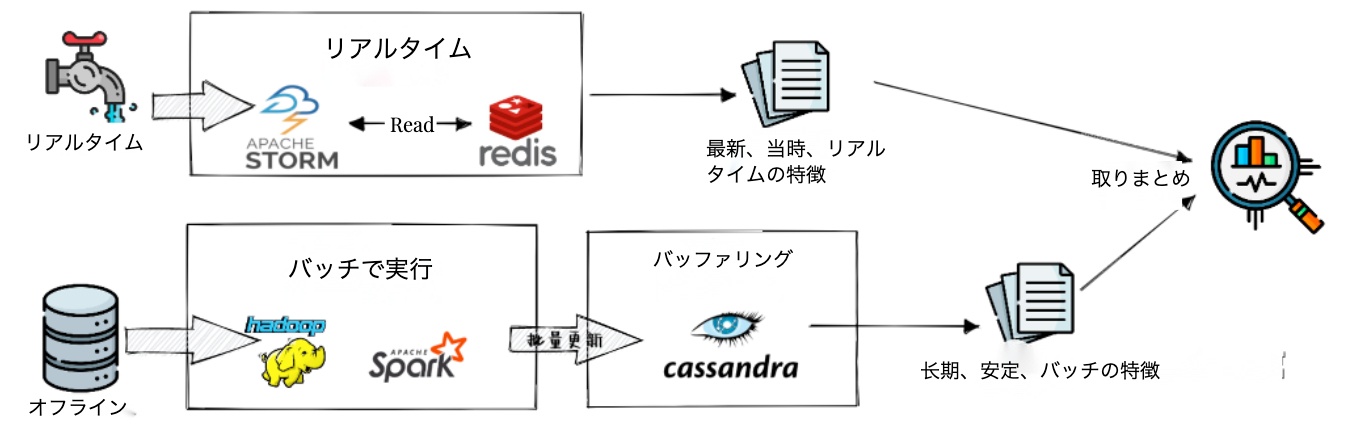
解決アプローチ
データリクエストの最適化
この課題に対処するため、データリクエストを効率的に処理する多層的なアプローチを採用します。これにより、高速なレスポンスと正確な計算の両立を図ることができます。
- リクエストの分割処理
データの特性に応じて、処理を2つの主要なカテゴリに分類します:
コールドデータ処理:
より古い、安定したデータを扱います。このデータは変更頻度が低く、バッチ処理に適しています。例えば、1週間以上前の視聴履歴やエンゲージメントデータがこれに該当します。このデータは事前計算とキャッシュ化が可能であり、アクセス速度の最適化が実現できます。
ホットデータ処理:
最新のユーザー行動データを扱います。このデータはリアルタイムで更新される必要があり、ストリーミング処理に適しています。直近24時間の視聴データやインタラクションログなどが含まれます。
- 階層的処理システム
データ処理を効率化するため、2つの主要なレイヤーを設定します:
オフラインレイヤー:
- コールドデータの定期的なバッチ処理を実行
- 大規模なデータセットに対する詳細な統計計算
- 結果のキャッシュ化による高速アクセスの実現
- 日次または週次での更新スケジュール管理
オンラインレイヤー:
- ストリーミングアルゴリズムによるホットデータのリアルタイム処理
- 増分更新による効率的なデータ管理
- メモリ内処理による高速な演算の実現
- 秒単位での更新頻度の維持
- 結果の統合処理
最終的な特徴量を生成するため、以下のステップで結果を統合します:
- コールドデータとホットデータの重み付け結合
- 時間的な減衰係数の適用
- 統計的な信頼性の検証
- 異常値の検出と処理
おわりに
推薦システムは、複雑な要素が有機的に結合した総合的なシステムです。本稿では、その基本アーキテクチャと処理フローについて概観しましたが、各コンポーネントにはさらに深い技術的な詳細が存在します。
実際の実装においては、システムの規模や要件に応じて適切なアプローチを選択することが重要です。また、継続的なモニタリングと改善のプロセスを確立することで、システムの性能を維持・向上させることができます。
推薦システムの技術は日々進化を続けており、新しいアプローチや手法が常に提案されています。この分野に興味をお持ちの方は、実装の詳細や具体的な技術的課題について、コメントセクションでの議論を通じて理解を深めていただければ幸いです。
データサイエンス君のAI教材シリーズ(未経験OK)
教材のターゲット層:
- 初心者: Pythonとデータ分析の基本を学びたい人
- 中級者: より高度な分析手法や機械学習を習得したい人
- レコメンド(推薦)エンジニア: レコメンデーションエンジンを作り、キャリアアップを目指したい人
AI領域に携わりたい方はぜひ!
datasciencekunのAI教材シリーズ
LINE公式アカウント
データサイエンス君のLINE公式アカウント友達募集中!
今登録すれば、下記の内容をプレゼントします!
- 特典資料:AI教材の一部を無料でお送りします!
- 専門家との相談:メッセージでデータサイエンス領域の不明点が相談できます!
一人で学ぶより、仲間と一緒に成長しませんか?
今すぐ友達登録して、データサイエンスの旅を始めましょう!
LINE公式アカウント:https://line.me/R/ti/p/@datasciencekun?from=page&accountId=datasciencekun

Discussion