ゼロから始めるDagster・すぐに使える実践ガイド
はじめに
本ドキュメントは、Dagsterのシステムコンセプトについて基本的な内容を要約・再整理した、Dagster導入のガイドです。
Dagsterの概念は、データオーケストレーションに特化されているところから独特のコンセプトを用いているところがあります。そのため、特に難しく重要な内容を要約し、理解の助けにするところを目指しました。また、公式ドキュメントの構成も十分に整理されていない部分もあり私なりに再構成してあります。用途に応じ目次を参照しつつ拾い読みしながらご活用いただけると幸いです。
Dagsterのシステム概要
以下は公式から引用したDagsterのシステム概要図です。Dagsterのサービス(Long-runnning services) とサービスから生成される Job(Ephemeral Process) の関係を示します。
図にはk8s(Kubernetes)とありますが、ローカル環境やDagster Cloudでもおおよそ同じように考えてもらうことができます。Dagster Cloudの場合、図におけるDaemon(Agent)、 Dagit、DatabaseについてはSaas側で提供されます。

Dagsterのシステム概要図
Ephemeral Processについての詳細は、差し当たって理解しなくても運用は可能なので参照先を示すに留めます。システムは複数のサービスによる冗長(Replica)構成を採っており、単一障害点が生じることを防ぎそれぞれの処理を極力軽量化するように作られています。
| サービス | 説明 |
|---|---|
Dagit |
ユーザーインターフェースを提供するWebサーバで、複数のサーバを立てることができGraphQL APIによりユーザと応答します。 |
Dagster Daemon |
Dagster Instanceの一部で、Schedule、Sensor、およびRun Queueを操作します。 |
Code location Server |
Dagster定義のCollectionに関するメタデータを提供するサーバです。多数のコードロケーションサーバを持つことができ、各コードロケーションはそのサーバーのDefinitionを1つだけ持つことができます。 |
Dagster Job Deploy
DagsterのJobデプロイについて説明します。デプロイにはDagster ProjectとDeploy設定が必要で、それらの設定で特に重要な概念を取り上げます。
Dagster Project構成
Dagsterはローカル、k8sやECSなど様々な環境で使用可能です。まず最初にプロジェクトを作成する必要があり、手順は以下を実行するだけです。詳細はcreate new projectをご覧ください。
プロジェクトはscaffoldで作成可能で、構成物はpythonのsetuptoolで作成されるpythonパッケージの導入手順とほぼ同一なので説明は省略します。公式ドキュメントの参照先はDefault Filesにまとめてあります。
$ pip install dagster
$ dagster project scaffold --name my-dagster-project
Scaffoldで生成されるproject構成
通常のpythonパッケージと違う点は__init__.pyとassets.pyが作成される点で、__init__.pyにはプロジェクト内で定義されたすべての定義を含む Definitions オブジェクトの定義を指し示す必要があります。構成にはAsset、Job、Schedule、Sensor、Resourceなどがあり、構成が複雑になるにつれてそれらをサブモジュールで管理することが推奨されます。
.
├── README.md
├── my_dagster_project
│ ├── __init__.py
│ └── assets.py
├── my_dagster_project_tests
├── pyproject.toml
├── setup.cfg
├── setup.py
└── tox.ini
OSS DeploymentとCloud Deployment
DagsterをOSS(ローカルやオンプレ環境など)かCloudどちらで使用するかにより、それぞれ追加の設定ファイルが必要になることがあります。以降はそれぞれの構成要素とDagsterの特別な概念であるInstance、locationsを説明します。
なお、Cloud Deploymentについてより詳細に知りたい方は、私がまとめたDagster Cloudの導入チュートリアルの方が詳しいのでよろしければご覧ください。
| ファイル名 | 説明 | OSS | Cloud |
|---|---|---|---|
dagster.yaml |
Dagsterインスタンスを設定します。使用例や利用可能なオプションの詳細はdagster.yaml referenceを参照してください。このファイルは$DAGSTER_HOMEに配置します。一般的にはDagsterプロジェクトのルートディレクトリです。 |
任意 | 任意 |
dagster_cloud.yaml |
Dagster Cloudのコードの場所を定義します。詳細はdagster_cloud.yaml referenceを参照してください。 | 不要 | 推奨 |
deployment_settings.yaml |
Dagster Cloudでのキューの優先度や同時実行制限などを含むフルデプロイメント設定です。詳細についてはDeployment settings referenceを参照してください。※任意にファイル名称変更、Dagster Cloud GUIでも設定可 | 不要 | 任意 |
workspace.yaml |
ローカル開発や自身のインフラストラクチャへのデプロイのための複数のコードの場所を定義します。 | 任意 | 不要 |
Instance
Instanceとは、Job実行時のDagsterの設定と状態を保持するオブジェクトです。設定はdagster.yamlファイルで管理され、特定のインスタンス設定をカスタマイズしDagsterランタイムの挙動を指定します。
Instanceが管理する情報の詳細は以下の表をご覧ください。Dagster CloudのHybrid Deploymentの場合、InstanceはDagsterを運用するための全体的なデプロイメント環境として機能し、データベースや他の環境構成情報を含みます。
Instanceの管理する情報の一部
Instanceが管理する情報
| 機能 | 説明 |
|---|---|
Runs |
Job実行履歴の詳細情報です。実行開始・終了時間、成功・失敗のステータス、ログ出力などが含まれます。 |
Settings |
ログ、デーモンの設定、起動方法(直接ローカルで実行するか、クラウド上で実行するか等)ストレージ(データやJobの実行結果を保存するためのストレージに関する設定)、ランタイム環境(Jobの実行環境。例えば、KubernetesやDockerなど)に関する設定などが含まれます。 |
Schedule & Sensor |
Schedule(定期的にJobを実行する設定)やSensor(特定のイベントに反応してJobを実行する設定)を追跡します。 |
Asset Catalog |
Jobによって生成されたAssetのメタデータを管理します。 |
dagster.yaml設定例
以下で、run_coordinatorはモジュールとクラスを指定、run_monitoringはJobの実行時間やキャンセル時間のタイムアウトなど挙動の監視をします。まだ開発が進められている項目なので、参照先もまとまって整理されていない様子です。
run_coordinator:
module: run_attribution_example
class: CustomRunCoordinator
run_monitoring:
start_timeout_seconds: 1200
cancel_timeout_seconds: 1200
Code locations
DagsterがJobを実行するのに必要な実行環境のパスを指定し、それら一つ一つをLocationと呼びます。設定はworkspace.yamlで管理します。
code locationsは、PythonモジュールまたはPythonコードのパスとして定義することができます。Pythonモジュールの場合、Dagsterはそのモジュールをインポートし、リポジトリまたはJob定義を探します。Pythonコードの場合、Dagsterはそのコードを実行し、コードが返すリポジトリまたはJob定義を探します。
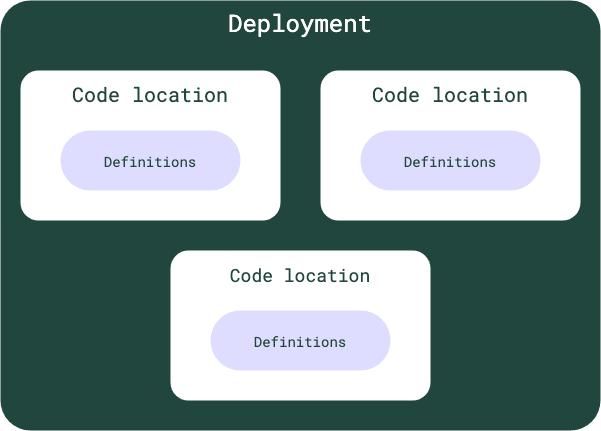
code locationsの模式図
workspace.yaml設定例
ここではまずmy_project.repositoryという名前のPythonモジュールをインポートし、次にmy_other_project/repository.pyというパスのPythonコードを実行します。
以下のようにload_from:ディレクティブを複数指定することで上図のような複数のcode locationsを定義することもできます。指定方法の詳細はConfigure Code Locationsをご覧ください。
load_from:
- python_module:
module_name: my_project.repository
- python_file:
relative_path: my_other_project/repository.py
load_from:
- python_module:
module_name: my_project.repository
- python_file:
relative_path: my_other_project/repository.py
Dagsterのコンセプト
Dagsterは独自の概念や思考モデルを用いているため、コンセプトの理解が重要になります。ここでは特に代表的なコンセプトを挙げていきます。
Definitions
Dagsterのデータパイプラインを構成する主要な構成要素を定義します。Jobパイプラインはops、jobs、resourcesなどを以下のようなイメージで定義しlocationに構成されます。
Definitions設定例
以下はdefinitions設定における最小単位です。assets、jobs、schedules、sensors、resourcesといった設定項目がありますが、特に明示的に指定しなくてもいい場合は省略したり、定義ファイルだけ用意して処理はNOPといったこともできます。
defs = Definitions(
assets=[*dbt_assets],
jobs=[my_job],
schedules=[my_schedule],
sensors=[my_sensor],
)
Op
Dagsterの中心的な概念で、データパイプラインの個々のステップ、または一つの処理をモデル化したものです。デコレーターで入力・出力、設定オプションを指定可能で、パイプラインの実行時の振る舞いを制御することができます。
また、opのコードは再利用可能で規模なデータパイプラインを小さな管理しやすい部品に分割して実行・テスト可能です。
opコーディング例
opは @op というデコレータを指定することで定義できます。ここではopは2つの整数を受け取り、その過程でint型以外のデータ入力をvalidationし、受け取った値を加算して結果を返しています。context引数はDagsterの実行環境に関する情報を提供するもので、追って詳解します。
from dagster import op
@op(ins={"num1": In(int)}, out=Out(int))
def add_numbers(context, num1: int, num2: int) -> int:
return num1 + num2
Job
Dagsterにおける最も基本的な実行単位で、一連のops(またはgraph)を組み合わせて定義したワークフローです。ある特定の作業(データの読み込み、変換、出力など)を達成するためのワークフロー全体をカプセル化します。この設計により、データ依存性を視覚的に把握しやすくなり、また、各opが再利用可能で、テストしやすい独立した単位になります。
Dagsterではjobはjobとasset jobに分類できます。通常のjobがより汎用的なタスクを扱うのに対し、asset jobは特定のデータアセットとそのライフサイクルに焦点を当てて設計されており、データの管理と可視化をより具体的かつ効率的にします。

opのワークフローをjobと呼ぶ 引用元:airbyte tutrials
Jobコーディング例
jobは @job というデコレータを指定することで定義できます。この my_job() の処理では、generate_string() が文字列を生成し、その出力を consume_string() が引き継ぎます。以下のように consume_string(generate_string()) という書き方で順序を規定することができますが、直感的にわかりにくい場合はコメントアウトに記載したような引数や変数を明示した書き方も可能です。
from dagster import job
@op(out=Out(str))
def generate_string(context):
return 'Hello, world!'
@op(ins={"input_str": In(str)})
def consume_string(context, input_str):
context.log.info(input_str)
@job
def my_job():
consume_string(generate_string())
# greeting_str = generate_string()
# consume_string(greeting_str)
Asset Jobコーディング例
DagsterのAsset管理機能と連携しています。特定のData Assetの生成や更新を行うためのjobであり、作成されるデータアセットを明示的に定義し、依存関係の追跡やデータライフサイクルを管理可能にします。Asset Jobの利用の仕方は特殊で、define_asset_job() に使用するジョブの名称や対象とするassetを指定して実行します。
@asset
def asset1():
return [1, 2, 3]
@asset
def asset2(asset1):
return asset1 + [4]
all_assets_job = define_asset_job(name="all_assets_job")
asset1_job = define_asset_job(name="asset1_job", selection="asset1")
Context
Dagsterに登場する特別な概念の一つですが、pythonでは例えばFlaskなどのような一部のフレームワークで登場するcontextとおよそ同じようなものです。
その名の通りJobパイプライン実行におけるコンテキストみたいなものと考えることができます。
Dagsterパイプラインの実行に関連する多くの情報をカプセル化したもので、特定のJobまたはop(操作)の実行に関連する情報を保持し、リソース(データベース接続など)、ログ出力用のオブジェクト、およびJobやopの設定情報などが含まれます。contextはJobまたはopごとに生成され、その実行中だけ存在します。
ContextはDagsterの情報にアクセスする場合にopやassetの第一引数として代入しますが、特に必要がなければ明示的に指定する必要はありません。
Context使用例
以下、前者のopではログに指定のメッセージ(Adding numbers)を出力します。後者のopでは処理でcontextにアクセスしないので記載として省かれていますが、暗黙的には存在します。
@op
def add(context, num1: int, num2: int) -> int:
context.log.info("Adding numbers")
return num1 + num2
@op
def add_numbers(num1: int, num2: int) -> int:
return num1 + num2
Resource
Resourceは、Jobが実行される際に使用されるリソースやサービス(データベース、オブジェクトストレージ、API、その他のIOバウンドなサービス)へのコネクションを指し、特定のタイプのサービスへのコネクションの詳細をカプセル化します。例えば、あるJobでデータベースからデータを取得する場合、そのデータベース接続はresourceとして定義し、Jobやopでそれを使用できるようになります。
Resourceを使用することでJobやopは外部リソースへの接続を意識せずにコードを書くことを可能とし、コードの可読性と再利用性が向上します。異なるopが同じデータベース接続を共有したり、異なるJob実行間で一貫した状態を維持するために使用できます。さらに、Resourcesはセットアップとクリーンアップのライフサイクルメソッドを提供し、リソースが適切に開放されることを保証します。
Resource設定例
例えばjobにおいて以下のように設定することで、以後dbtを使用するopにおいてはデコレータでrequired_resource_keys={"dbt"}と指定すれば、dbtのリソースを利用することが可能となります。
@job(
resource_defs={
"dbt": dbt_cli_resource.configured(
{
"project_dir": DBT_PROJECT_PATH,
"profiles_dir": DBT_PROFILES,
"target": DBT_TARGET,
},
),
},
)
def some_job():
......いずれかの処理
result = dbt_run() # dbtを使用する処理
......いずれかの処理
@op(
required_resource_keys={"dbt"},
tags={"kind": "dbt"},
)
def dbt_run(context):
......いずれかのdbtの処理.....
Configure
JobやOpの動作をカスタマイズする際に使用し、設定の詳細をopまたはresourceのコードから分離し、各実行環境に合わせた調整を可能にします。Dagsterにおける環境変数の使用のようにイメージしていただけると適切かと考えます。
パイプラインが操作するデータの場所・スケジューリング・特定のopの動作などを指定可能で、例えば、あるopが特定のデータベースに接続する際にconfigureを使用して、接続の詳細(ホスト名、ポート、認証情報など)を実行環境ごとに変更し再利用する。といった利用を可能にします。
Configure設定例
この例では、say_hello() はconfigを使用して単語を受け取り、その単語をログに出力します。greeting_job() はconfig_mappingを使用してJobレベルの設定をopの設定にマッピングしています。このようにconfigを使用するとパイプラインの実行時の振る舞いを柔軟に制御できます。
from dagster import op, Field, String, config_mapping, job
@op(config_schema={"word": Field(String)})
def say_hello(context):
context.log.info(f"Hello, {context.op_config['word']}!")
@job(
config_schema={"greeting_word": Field(String)},
config_fn=config_mapping(
config_fn=lambda cfg: {"say_hello": {"config": {"word": cfg["greeting_word"]}}}
),
)
def greeting_job():
say_hello()
I/O Manager
Job全体の入出力を管理します。op間の入出力でデータをどのように保存し、取得するかを管理するコンポーネントです。opの実行結果(出力)の永続化や、その結果を次のopへの入力としてどのように提供するかを決定します。Inを使うと、前のopの出力と現在のopの入力を接続し、Outを使うと、現在のopの出力と次のopの入力を接続し、データがパイプラインを通じてどのように流れるかを制御できます。
これらを使用することで、Dagsterはデータパイプラインの各ステップ間でのデータの流れと依存関係を明示的に制御できます。また、それぞれのopの入力と出力は独立してテストでき、その結果、全体のパイプラインはより堅牢で管理しやすくなります。

I/O Managerの利用イメージ
I/O Manager設定例
全体としてのI/Oを規定する場合はio_managerというキーを使うのですが、以下は全体のIOの管理とは別でs3を使用する場合の利用例で、my_job() でresourceとして"s3_io_manager": S3IOManagerを指定し、my_op() でio_manager_key="s3_io_manager"を指定することで、my_opの処理内におけるI/Oはs3を利用する。という使い方をしています。I/Oの管理は柔軟に変更可能です。詳細はio-managersをご覧ください。
from dagster import job, op, Out
from dagster_aws.s3 import s3_resource, S3IOManager
@op(out=Out(io_manager_key="s3_io_manager"))
def my_op():
return "Hello, world!"
@job(resource_defs={"s3": s3_resource, "s3_io_manager": S3IOManager})
def my_job():
my_op()
Asset
AssetはDagsterにおける主要な概念です。データパイプラインの実行により生成または変更される具体的なデータアーティファクトを指し、データベースのテーブル、特定のデータセット、物理的なファイル、モデルのパラメータなど、ユーザが任意にメタデータを設定し表現できます。
データパイプラインの結果を追跡、監視、および再利用するためのメカニズムを提供し、パイプラインの各ステップのETLを可視化し、データのライフサイクル全体を通じて一貫性を維持します。
管理するデータの鮮度が問題になることが多いので、staleなどのタグで鮮度を確認したり、data versionなどで情報をバージョン管理できます。
Jobの項目でも触れましたが、Assetをリフレッシュする専用のJobを定義して通常のJobと独立して取り扱うことも可能です。

データモデルの相関とメタデータを確認可 引用元:airbyte tutrials
Assetコーディング例
Assetは @asset というデコレータを指定することで定義できます。
以下の例ではupstream_assetや["some_db_schema", "upstream_asset"]といったassetに依存しており、それらのアセットが生成したデータを受け取っていずれかの処理を行い、新たなデータを生成します。
downstream_asset() は、upstream_assetというアセットの出力を受け取り、そのリストに整数の4を追加して新たなリストを生成。another_downstream_asset() は、["some_db_schema", "upstream_asset"]というキーのアセットの出力を受け取り、そのリストに整数の10を追加して新たなリストを生成します。
# If the upstream key has a single segment, you can specify it with a string:
@asset(ins={"upstream": AssetIn(key="upstream_asset")})
def downstream_asset(upstream):
return upstream + [4]
# If it has multiple segments, you can provide a list:
@asset(ins={"upstream": AssetIn(key=["some_db_schema", "upstream_asset"])})
def another_downstream_asset(upstream):
return upstream + [10]
Dagsterのテスト
Dagsterのテストは、コーディングによるテストも可能ですが LaunchPadを使えばすでに設定済みの項目や変数に対して動的に値を変更してopやJobsを単体、複合テストすることが可能です。
opを選択的に実行する時は例えばsome_op*などと指定したらsome_op以降の後続のopを実行可能です。詳細はOp selection syntaxをご覧ください。
Scaffold missing configをクリックすれば自動的に設定項目の型を生成、右ペインで設定方法例示し、設定が誤っていたら指摘してくれます。その型に合わせて都度任意の変数を代入してJob、opを実行することが可能です。

LaunchPadから任意にopの変数に値を代入して実行できる
さいごに
他にも構成に必要なsensorやschedule、パイプラインを抽象化し再利用可能にしたgraphなどといった概念もございますが、今回は理解にコストがかかりそうなトピックを中心的に取り上げ、最低限理解しておきたい概念に絞って紹介しました。極力少ない文章量で重要な部分だけを説明したく、bookとして展開するよりは短い分量にまとめたつもりですが、より詳細に理解を深めたい方はぜひ正規のDagsterガイドをご覧ください。
Dagsterは最初に理解するコストは高いですが、概念がわかると非常に柔軟な設定が可能となり、特に専門的にデータを扱う業種の方に向けて作られていると感じます。
Dagsterは最近シリーズBにおいて$33Mの資金調達を果たし新たなデータオーケストレーションツールとして将来を嘱望されています。Dagsterの業界における位置付けやユースケースなどはデータオーケストレーションツールDagsterの紹介にまとめましたのでよろしければご覧ください。
Discussion