データオーケストレーションツールDagsterの紹介
データオーケストレーションとは

データオーケストレーションという言葉をご存知でしょうか?日本ではまだ耳慣れない言葉ですが、data orchestrationでgoogle検索すると実に3000万件以上ヒットし、世界的には十分に市民権を得ている言葉です。Databricksではデータオーケストレーションを以下のように説明しています。
データオーケストレーションとは
データオーケストレーションとは、複数のストレージからサイロ化したデータを取り出し、組み合わせて整理し、分析に利用できるようにするための自動化されたプロセスです。
このプロセスでは、レガシーシステム、クラウドベースのツール、データレイクといったあらゆるデータセンターが接続されます。データは標準形式に変換されるため、理解しやすく、容易に意思決定に利用できます。
オーケストレーションとは、コンピュータシステム、アプリケーション、およびサービスにおける、設定、管理、調整の自動化を意味します。これまでは主にワークフローエンジンと呼ばれていたものがオーケストレーションを担っていましたが、時代の移り代わりとともにその重要性が見直され立ち位置も分化し、タスクオーケストレーションやデータオーケストレーションなど色々な名前で呼び習わされるようになり、専門のツールが増えてきました。
日本では世界の流行から約2年遅れで流行を輸入するというジンクスがありますが、私はデータオーケストレーションがこれからの時代を迎えるにあたって重要な位置付けを担う考え方の一つであると考えています。
昨今のデータ利活用状況の総括
データオーケストレーションの重要性について説明する前に、まず日本における昨今のデータ利用状況を取り巻く情勢について簡単に総括してみたいと思います。
AIの急速な台頭と反動形成
ここ最近、ChatGPTがその利便性から一躍脚光を浴び、これまでに例の無い速さで利用者数を増やしました。ChatGPTの機能を担保しているのは過去の膨大なデータの学習の結果によりますが、今後機械学習の流行に伴いデータの重要性と利用シーンがますます増えてくることが予想されます。
ですが、これまでの歴史を振り返ってみても、こうした急速な発展は大きな反動形成を生み出してきました。全く新しいサービスの是非を判断する基準は当然存在しないので法整備も追いつかず、特に慎重さを要する分野においては冷静に導入を判断する必要があるため、一時的に導入を見合わせることがあるのも宜なるかなといったところです。例えば、イタリアではChatGPTの利用を禁止する措置がとられましたし、これから他の国や団体もこれに追随しAIの利用を一時的にでも規制する可能性は出てきます。
今後、データの利用にどの程度制限がかけられるかまだ誰にも正確に予想がついていませんが、世の中の流れとしては欧州諸国のEU一般データ保護規則(GDPR)のようにデータの自由な利用に規制が定められるようになってきており、これまでのように例えばCookieを介して自由に個人データを取得できた時代は終わりに差し掛かっています。その上、そのような方法論は期待されていた程の効果が上がっておらず割に合っていませんでした。そういった状況を鑑みて、今後は企業が各企業独自の手段で必要なデータを蓄え分析し、それを競争力の源泉とする流れが主流になると予想しています。
日本のデータ利活用状況
翻って、昨今の日本におけるデータ利活用の状況を見てみると、多くの企業ではデータをどう扱うか?という段階にすら上がっていない状況です。
日本ではDXという名目で企業の情報資産のリストラクチャが今も活発に行われています。しかし、実際にそれが正しく遂行されているかというと議論が分かれるところだと思います。企業のデータ利活用においては国際的に一定の発展段階基準が設けられていますが、この尺度に照らし合わせると、日本でデータの利活用が十分な段階に達している企業はそう多くない印象です。
労働集約型事業と資本集約型事業
日本でデータ利活用が進んでいない理由について、興味深い意見の記事がございました。
記事によると、日本とアメリカでは仕事に対するスタンスが異なり、アメリカでは完全に分業が進んでいるのに対して日本は一人で複数の分野を担うことで成立しているので作業の分離ができないためデータ利活用が進んでいないとのことです。
世界的には、例えばSaas営業においてはSalesforceに代表されるようなTHE MODEL式分業体制が中心となっていますし、分業し効率を定量的に計測できるような仕事は製造業だけではなくなってきました。分業はフェーズや生産ラインごとの効率分析を可能とするのでデータ利活用と相性が良いと言えるでしょう。対して、一人で幾つものフェーズを担当するような仕事は替えが効かない職人芸が必要とされるような職業では理解できますが、そうした仕事はそもそも最初からDXの文脈で語られないのではないかと考えます。
こうしたスタンスについて、どちらが正しいかという話はその携わっている仕事の性質に依るところが大きいと思います。ですが、これまでの日本の仕事は労働集約的な仕事の仕方に支えられてきたのに対し、世界の主流の仕事の進め方やその際に使われるツールがオートメーション化された資本集約的な方法に取って代わっているのに、日本だけが国際的なルールや技術標準に合わない形で独自ルールをいつまで維持し続けることができるかわかりません。
データオーケストレーションツールが必要な理由
一方で、日本でもメガベンチャーのように規模が大きく最新の技術を活発に取り入れている企業は、作業の効率化やオートメーション化を進めておりデータ利活用レベルが高く、部署内、および部門間のデータを統合してデータ分析を進めているケースが多いです。
規模の小さい会社や企業で各部署が持つデータを収集する際には、例えばFivetranやAirbyte、TroccoといったデータパイプラインやETLツールが利用されます。それらはそれぞれ対応するコネクタ数も多く、利用データを統合し状況を可視化するのに十分な働きをします。しかし、企業の規模も大きくなり、統計的な分析や将来予測、部署横断的な分析が必要になった時に、部署毎に最適化したデータをさらに全社的に統合し、データを分析、機械学習に活かすとなるとそれらのツールでは統合性や機能の問題で片手落ちになることがあります。
そうした際に、全社的にデータを統合し一つのプラットフォームでデータ利活用を実現するためのデータオーケストレーションツールが必要になってくるのです。
各種オーケストレーションツールの比較
そこで、現在データオーケストレーションに利用されているツールとして未だ主流のAirflow、その後継と目されるPrefect、そして今回中心となるDagsterの三つを比較したいと思います。なお、比較結果を簡単に表にまとめた結果は以下のアコーディオンパネルをご覧ください。
Airflow、Prefect、Dagsterの比較まとめ
| 機能・特徴 | Airflow | Dagster | Prefect |
|---|---|---|---|
| モジュール性 | タスク指向 | opとパイプライン指向 | タスク指向 |
| 型システム | なし | あり(独自の型システム) | なし |
| テストとデバッグ | コンポーネント依存性が高く制限がある | ・ローカル、クラウド環境双方でユニットテストや統合テストを実行できる ・ユニット単位で入力値や設定を変えてテスト可能 パイプライン入出力値の型、スキーマチェック ・入力フリーのGUI |
・ローカル、クラウド環境双方でのフロー単位でのテスト ・ステートハンドラー |
| コミュニティ | 大規模 | 6600人(slack community) | 11000人 (slack community) |
| 実行環境 | ローカル、オンプレミス、クラウド対応(MWAA composerなど) | ローカル、オンプレミス、クラウド対応 | クラウドネイティブに特化 、ローカル |
| ソースコード可読性 | Python DAG、DSL | Pythonのルール。モジュールやコンポーネント性、型指定。 | Pythonのルール。フローやタスクの直観的な表現 |
| エコシステム | 豊富なプラグイン | 拡張性が高く、様々なライブラリと統合可能 | 拡張性が高く、様々なライブラリと統合可能 |
また、上で一部触れたFivetranなどのETLツールや、他のワークフローエンジンとしてよく挙がるDigdagなどについては、以下の記事に良くまとまっているのでよろしければ参考にしてください。
Airflow
Airflowは、DAG(有向非巡回グラフ)と呼ばれるグラフ理論をもとに作られたワークフローエンジンです。タスクを実行する順番を定義するワークフローの作成や、実行のスケジューリング・監視などの機能があります。ワークフローエンジンとしては歴史のあるツールで、多数のプラグインと大きな開発者コミュニティを持っています。クラウドサービスが主流でない頃から存在していましたが、現在ではMWAA(AWS)やCloud Composer(GCP)といったクラウドサービスも登場しています。
アーキテクチャは主に実行の管理画面「Webserver」、ジョブ実行のスケジュール管理を行う「Scheduler」、ジョブ実行部の「Worker(Executor)」という3つのモジュールで構成されています。システムの実行はスケジューラループを経由し、実行タスクをDAGで定義し、依存関係が解消されたタスクから順次実行されていきます。
このような構成はそれぞれのモジュールで相互に依存性が高く、実行開始後スケジューラが実行終了確認するのを待つ必要があり、挙動が大きくやり直しに向いておらず、今日の開発スタイルと乖離してきました。ローカル開発ループのような素早いフィードバックが得られず、ラグが生じ、本番環境以外でのパイプラインのテスト、開発、レビューを困難にしています。
Airflowの特徴
- タスク指向: タスク(処理単位)を組み合わせてワークフローを構築します。これによりタスクの再利用や組み合わせが容易になります。
- システム間の連携: 豊富なプラグインや組み込みのオペレータ(タスクの実行方法を定義するコンポーネント)が提供されており、様々なデータソースやシステムと連携できます。
- スケーラビリティ: タスクの並行実行や分散実行をサポートしており、大規模なデータ処理も効率的に行えます。

Airflowの動作画面
Prefect
PrefectはAirflowの主要開発者が2017年より新たに開発を始めたツールです。上に挙げたようなAirflowの欠点を克服するために作られました。Prefectという名称はワークフローを簡単にするという意味が込められており、その通りワークフローを簡単に始められるところが特徴です。
Prefectはタスクスケジューラの進化型というイメージで、自らをタスクオーケストレーションツールと呼んでいます。タスクドリブンなツールで思想的にはAirflowを受け継いでいる部分が多いですが、動的なDAGによるタスク管理を取りやめ、単一障害点であったスケジューラへの依存度を低くし、ワークフロー単一での実行や任意の変数の挿入による部分的な実行をサポートするようになりました。Airflow独自の記述様式・管理手法からPython本来の記述様式やGit管理に則る形に代わりました。
Prefectは柔軟性とスケーラビリティに優れ、特にクラウドネイティブな環境でのデプロイメントや分散コンピューティングに力を入れています。
Prefectの特徴
- 管理フレームワーク:データパイプライン全体を効率的に管理する強力な機能(タスクのスケジューリング、状態管理、リトライ機能など)を提供します。
- 柔軟なタスク実行:ローカル実行、分散実行(Dask)、Kubernetesなどのさまざまな実行環境をサポートしています。
- クラウドネイティブ:クラウド利用に大きく特化し、Prefect ServerまたはPrefect Cloudを使用して、フローを管理、監視、スケジューリングします。

Prefectの動作画面
また、Prefectの第二世代と呼ばれるPrefect Orion(Orionとはオーケストレーションのことを指します)というツールが2021年から開発が進められていますが、データ処理や機械学習、CI/CDに力を入れており、後述するDagsterに機能を寄せてきているように見えます。
Dagster
DagsterはPrefectよりもさらに後発で2019年頃より開発が始まり、Prefect同様Airflowを批判的に発展継承する目的で作られました。そういう意味でDagsterはPrefectとよく似た特徴を備えていますが、Prefectとの大きな違いは扱う対象があくまでタスク中心でなくデータ中心であり、データオーケストレーションツールであることを強調している点です。
Dagsterの特徴
- 軽量なマルチ環境テスト:LaunchPadから任意のパラメータによる軽量、即時実行のユニットおよび結合テストを可能にし、実行にローカルからクラウドまで環境を選びません。また入出力データのバリデーションチェックといったデータ実務者にとって重要な機能が標準装備されています。
- アセットベースのアプローチ:オーケストレーションに対してデータドリブンでアセットベースなシステムを提供します。データを繋ぎ合わせ、データパイプラインが作成・維持するテーブル、ファイル、機械学習モデルなどの観点からシステムを考えることができます。
- 強力なビジュアライゼーション:データアセットやデータパイプラインの実行状況や実行結果、保存されている情報資産を視覚化するためのツールが豊富に用意されています。
Prefectが簡易化を目指しているのに対し、Dagsterは複雑であるという声がよく挙がります。できることが多岐に亘る分 却って柔軟性を損なっており、概念を理解するのに学習コストが高いです。そういった意味ではPrefectの方が大きなチームで利用する場合には有利な点があります。そのため、どちらを選択するかは業務やチームの性格によって選択することになるでしょう。

Dagsterの動作画面
実務担当者にとってのDagsterの機能
本項では、データ活用における主要な開発・実務担当者であるデータアナリスト・データサイエンティスト・アナリティクスエンジニアにとってDagsterがどのようにその業務に貢献するか、簡単に例を追いながら紹介していきます。
データサイエンティスト
MLOpsのライフサイクルシステムは、データ処理や特徴量エンジニアリング・メタデータの一覧化・エンドポイントのモニタリングなど、以下の図のようにコア部分を取り巻く周辺機能の方が多いと良く言われますが、Dagsterはそれらの機能を標準で備えています。
通常のデータだけでなく機械学習モデルもアセットとして単一のパイプラインに統合することが可能であり、コアデータ・アナリティクスを同じフレームワークの下にまとめデータ管理を容易にします。また、Sensor機能は特徴量の変化がMLモデルに及ぼす影響評価を簡単にします。
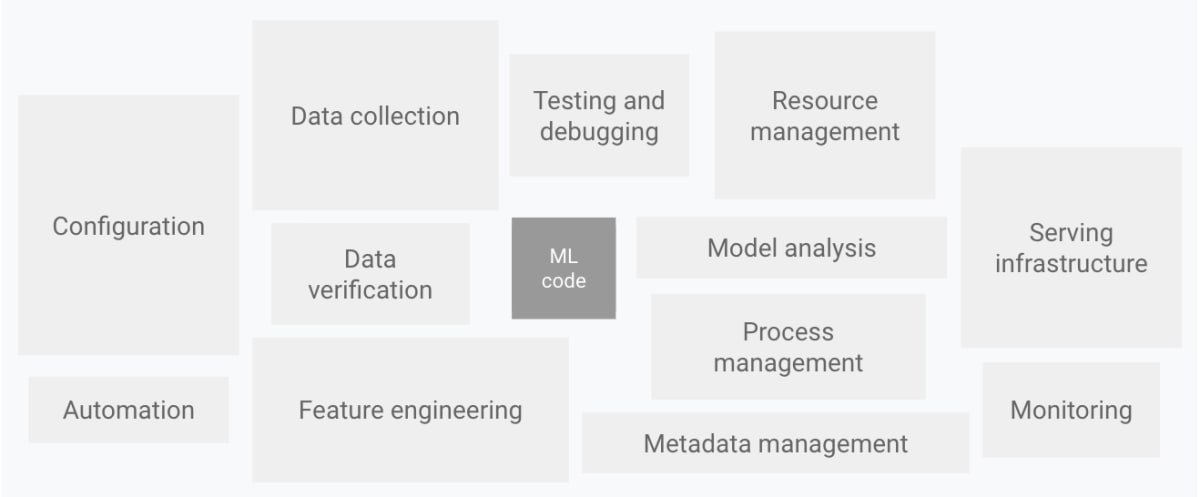
継続的デリバリーと自動化のパイプラインの構成要素
MLパイプラインの整理
MLOpsでは学習済みモデルのリンクや、どのジョブでモデルが生成されたか、ハイパーパラメータの設定、評価メトリクスなどMLパイプラインのメタデータを監視する必要がありますが、DagsterにはSensorという様々な変化のトリガーを追跡する機能があり、パイプラインのメタデータを追跡し、再現性を向上させ、異なるモデルバージョンを比較することを容易にします。
データ前処理と特徴量エンジニアリングの管理
入出力データのバリデーション機能がデータをMLモデルに適した形式に変換します。また、アセット・マテリアライゼーションという機能があり、データパイプラインの途中結果や最終成果物を実行環境に関連付けて保存し、それらのバージョン管理や依存関係を可視化することができます。これにより、データの品質や再現性を向上させ、エンジニアやデータサイエンティストがデータの生成過程を追跡しやすくなります。また、実行中のop(Dagsterにおける様々な処理単位)と特定のキーに対して任意にメタデータを関連付けることができます。
モデルの監視とメンテナンス
Sensor機能が、データの品質監視、モデルのパフォーマンス監視、モデルの変更の監視、警告システムの作成に役立ちます。これにより、MLモデルの訓練や評価に関する設定やパラメータも一元管理できます。また、設定を外部ファイルや環境変数で管理することができ、異なる環境における設定の変更やハイパーパラメータの調整を容易にします。
データアナリスト
Dagsterのパイプラインを構成する各コンポーネントは疎結合であり、パイプラインをユニット・アセット単位で、ローカルまたはクラウドといった環境を問わずUIからテスト・デバッグができます。昨今ビジネスサイドの人でもdbtを使ってデータ分析するようなケースが増えてきていますが、コンポーネントの分離はそのようなスタイルにもマッチし、データ分析の敷居を低くしデータの民主化に貢献することが期待されています。
また、Dagsterはdbtとの親和性が高く、dbt単体で利用するよりさらに強力なビジュアライゼーションを提供します。
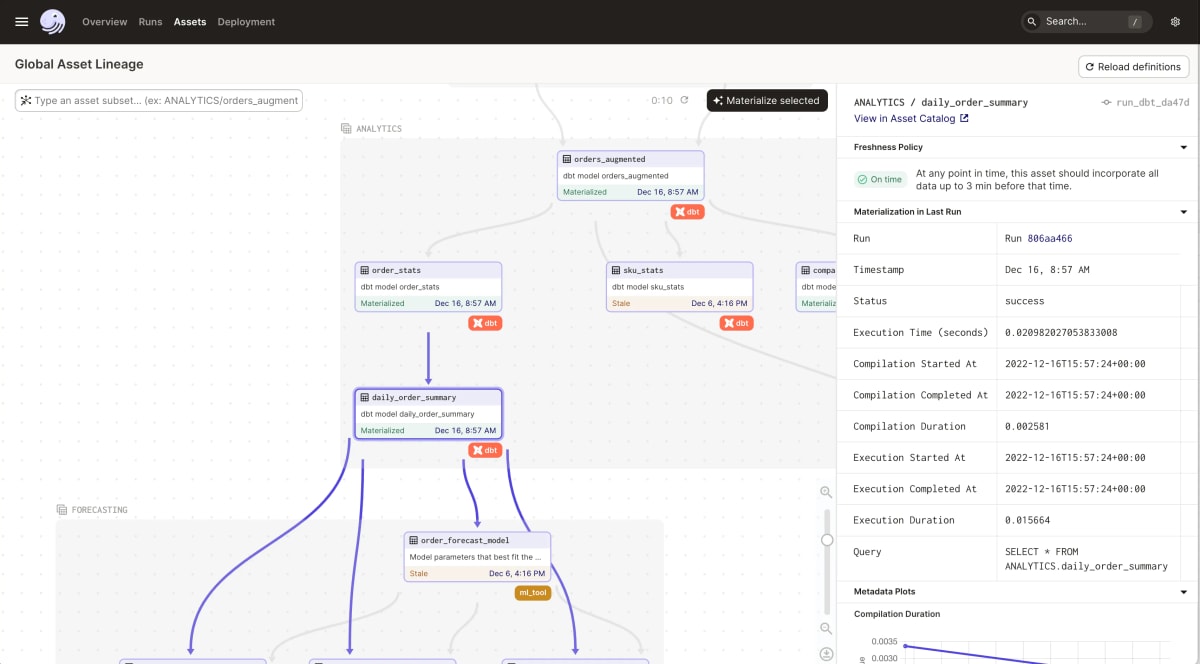
dbtデータリネージの機能を拡充する
データ抽出と前処理データ品質の確保
データアナリストは異なるデータソースからデータを抽出し、前処理を行うパイプラインを構築することができます。さらに、データの品質を維持し整合性やエラーを検出するために、Dagsterのデータ検証と型チェック機能を活用でき、データクレンジングに効果を発揮します。
データ集計と分析・レポート作成
探索的データ分析(EDA)を行うパイプラインを作成することで、データのパターンや相関を特定することを容易にします。例えば、よく使われるNotebookやその拡張機能であるNotableといったプラグインが準備されており、特定のビジネスや統計的な指標を計算するパイプラインを構築するのに役立ちます。そして、分析結果を自動的にレポートにまとめて出力し、定期的なレポート作成やアドホックなデータ分析を効率化することもできます。
データ分析チームの多様性
Dagsterはデータ分析チームの多様性を想定して作られています。多くのワークフローエンジンではユーザーコードをツール内のプロセスに直接ロードするため、システム環境とユーザー定義環境が混在し、デプロイメントスケジュールもモノリシックになっていました。しかし、Dagsterではチームは共有インフラを活用しながらも自分たちのツールを使い、自分たちのスケジュールでデプロイすることを可能にします。また、dbtを使えばデータリネージやアセットの視覚化、上に挙げたようなローカルでのテスト機能をさらに拡充します。
アナリティクスエンジニア
アナリティクスエンジニアの役割はデータパイプラインの総合的、恒常的なメンテナンスとビジネスインテリジェンス(BI)への橋渡しです。データアナリストやデータサイエンティストが日常的に行う専門的なタスクや課題に対し、信頼性の高いデータインフラストラクチャ構築とプロセスの効率化を提供する広範な役割を担います。
Dagsterは彼らがより高品質な分析やモデル開発に専念できる環境を整える継続的デリバリーやメンテナンス、プラグインの機能が充実しています。また、Airflowなどの他の既存ワークフローエンジンや各種サービスと統合するプラグインも充実しているため、現存するエコシステムとの共存や段階的なシステム移行にも対応しています。

様々なコンポーネントや環境統合をサポート
データストレージとアーキテクチャの管理
データアナリストやデータサイエンティストが利用するデータストレージやデータアセットを管理します。アセットからはデータの更新日や処理のグラフ、データのプレビューも確認でき、バージョン管理やデータの異常や不備の検知に適しています。
パイプラインの自動デプロイメント
Dagsterはgithubのブランチ毎にパイプライン環境を分けることができ、新しいモデルのテストやバージョンのデプロイメントを管理することができます。
デプロイメントに関しては少々複雑で、私の記事Dagster Cloudの導入チュートリアルに詳しくまとめておりますのでよろしければご覧ください。また、CI/CDと連携しlinterやテスト、dbtドキュメントのデプロイなどの定型処理を自動化可能です。
拡張性とプラグイン
Dagsterは拡張性が高く、様々なインテグレーション用プラグインが準備されています。
AWS、GCP、Azureといった主要クラウドアーキテクチャや、データベース・DWHとの連携、また、AirflowやSparkなどといった大型ワークフローエンジンや分散処理フレームワークとの連携、FivetranやAirbyteといったETLサービスとの統合なども可能にします、
機能面以外の比較
データオーケストレーションの重要性と、Dagsterを中心に紹介してきました。
最後に、DagsterとPrefectを機能面以外の観点でも比較してみました。簡単に結論だけ申し上げると、Dagsterは全ての規模においてPrefectの半分程度ですが、成長速度はおよそ倍程度で徐々にその差は縮まりつつあると考えています。特に、Dagsterはデータの文脈に特化しており、データ中心の利用においてはPrefectとの規模の違いを無視してほぼ同程度利用されている印象でした。
海外には比較サイトがたくさんございます。比較の仕方によって結果も変わるかもしれないので、Dagster、Prefectの利用をご検討されている方はぜひ他の比較サイトも参考にしてみてください。
利用規模と成長率
全体的にDagsterはPrefectの半分より少し多い程度の利用規模ですが、アクティブな成長率はおよそPrefectの倍程度で推移しています。
仕事案件数
こちらもDagsterはPrefectの案件数に比べ約半数で利用者規模の実態を反映しているように見えますが、データ関係の案件ベースで比較すると案件数は大体両者同程度に並びます。
Discussion