はじめに
先日、Frosty Friday Live Challenge @SnowVillage に初出演させていただきました。
本記事は私が担当した Frosty Friday - Week 77 - Hard, Geospatial Data の解説記事になります。
紹介するソースコードの一部を こちら にも掲載しています。
お題とデータの確認
まずはお題の内容について確認したいと思います。
"Shapefile は、データ分析向けの地理空間的な基盤を提供し、BI において重要な役割を果たしています。これらのファイルは、「地理情報」と「属性情報」で構成されており、企業が位置情報データを分析ワークフローにシームレスに統合できるようにします。
Snowflake は、位置情報の重要性を認識し、ユーザーが地理空間データを保存・クエリ・分析できるようにしています。では、Shapefile 形式の地理空間データを Snowflake のテーブルにロードするには、どのようにすればよいでしょうか?"

Shapefile というファイル形式の地理空間データを、Snowflake テーブルにロードするところまでがお題となっています。しかし、ただテーブルを作成するだけになっても面白みが少ないので、ロードした後の活用についても考えてみたいと思います。
使用するデータは何でも良いとの記載がありますが、今回はページでも紹介されている こちら のイタリア地理データを使用していきたいと思います。
Shapefile とは
Shapefile は、Esri 社が開発したベクター形式の地理データファイル形式で、多くの地理情報システム (GIS) ソフトウェアやライブラリで広く用いられます。
単一のファイルではなく、役割(拡張子)の異なる複数のファイルから構成されます。
| 拡張子 | 必須 | 役割 |
|---|---|---|
.shp |
✅ | 各地物の座標データを格納するメインのファイル |
.shx |
✅ | データ検索を高速化するためのインデックスファイル |
.dbf |
✅ | 各地物に付与される属性データ |
.prj |
- | 座標系 (CRS) の定義ファイル |
GeoPandas でデータの中身を確認してみる
Shapefile の .shp ファイルの中身はバイナリ形式となっており、テキストエディタなどでそのまま開いても読み取れません。しかし、GeoPandas などのライブラリを使用して読み込むことで、データの中身を参照できます。
import geopandas as gpd
path = f'data/raw/italy-waterways-shape/waterways.shp'
gdf = gpd.read_file(path)

GeoJSON に変換する
Snowflake にデータを投入しやすいよう、Shapefile を ND-JSON 形式に変換します。
GeoPandas の場合、to_file メソッドを使用することで GeoJSON として出力できます。
output_path = f'data/ndjson/{data_label}/{data_label}.ndjson'
gdf_writefile.to_file(output_path, driver="GeoJSONSeq")
もしくは、ogr2ogr などのソフトウェアを利用して変換することも可能です。
ogr2ogr -t_srs EPSG:4326 -f GeoJSONSeq \
data/ndjson/waterways/waterways.ndjson \
data/raw/italy-waterways-shape/waterways.shp
地理空間データを Snowflake に投入しよう
GEOMETRY 型・GEOGRAPHY 型
Snowflake では、地理空間データ型として GEOMETRY 型と GEOGRAPHY 型の 2 つが用意されています。名前は似ていますが、以下のような違いがあります。
| GEOMETRY 型 | GEOGRAPHY 型 | |
|---|---|---|
| 座標系 | 平面座標 | 球面座標 |
| SRID(空間参照 ID) | 任意 | 固定(EPSG:4326) |
| 高度のサポート | なし(Z座標) | なし(Altitude) |
| 二地点間の線分 | 直線 | 大円弧 |
| 利用シーン(使い分け) | 建物や区画、都市内の測量データなど局所的なデータを扱う | GPS 座標を扱う/世界地図上の距離・面積を計算する |
| CAST 関数 | ・TO_GEOMETRY ・TRY_TO_GEOMETRY |
・TO_GEOGRAPHY ・TRY_TO_GEOGRAPHY |
今回はイタリア地理データという、地球上の比較的広域なデータを扱うため、GEOGRAPHY 型として保持するものとします。
アーキテクチャ全体像
アーキテクチャ全体像は以下の通りです。
- Snowflake データベース・スキーマ
FROSTYFRIDAYDB.VOL_038を作成済み - S3 とのストレージ統合・外部ステージを作成済み

以降で、以下の手順を行なっていきます。
- 外部ステージ内に地理データ (ND-JSON 形式) をアップロード
- JSON をそのまま VARIANT 型として投入した RAW テーブルを作成
- 属性情報と地理情報を取り出した加工済みテーブルを作成
Snowflake へのデータ投入
外部ステージにアップロードしたデータの確認
外部ステージが設定された S3 ロケーション内の所定のパスに、Shapefile から変換した ND-JSON ファイルをアップロードします。

外部ステージに対して参照クエリを実行すると、各地物を 1 レコードとするテーブルとして抽出できていることが分かります。
SELECT
SPLIT_PART(metadata$filename, '/', 7) AS data_label,
$1 AS v,
FROM @default/italy-arcgis-ndjson
(FILE_FORMAT => MY_JSON, PATTERN => '.*[.]ndjson')
WHERE data_label = 'waterways'
LIMIT 1000 ;

RAW テーブルの作成
JSON をそのまま Variant 型カラムに投入した RAW テーブルを作成します。
CREATE OR REPLACE TABLE italy_arcgis_waterways__raw AS
SELECT $1 AS v
FROM @default/italy-arcgis-ndjson
(FILE_FORMAT => MY_JSON, PATTERN => '.*[.]ndjson')
WHERE SPLIT_PART(metadata$filename, '/', 7) = 'waterways' ;
SELECT * FROM italy_arcgis_waterways__raw LIMIT 10;

加工済みテーブルの作成
RAW テーブルの JSON の中身を見てみると、properties キーに各地物の「属性情報」が、geometry キーに「地理情報」が含まれていることが分かります。「属性情報」をそれぞれカラムとして持たせ、「地理情報」を GEOGRAPHY 型に変換した加工済みテーブルを作成します。
CREATE OR REPLACE TABLE italy_arcgis_waterways AS
SELECT
v:properties.osm_id AS osm_id,
v:properties.name::string AS name,
v:properties.type::string AS type,
try_to_geography(v:geometry) AS geography,
FROM italy_arcgis_waterways__raw ;
SELECT * FROM italy_arcgis_waterways LIMIT 10;

スキーマを確認すると、地理情報を GEOGRAPHY 型として登録できていることが分かります。

ここまでで、地理情報を Snowflake テーブルにロードするというお題のゴールを達成できました。以降で、ロードした地理情報の活用について考えてみます。
地理空間データを分析してみよう
Streamlit アプリケーション上で地図表示する
pydeck という Python ライブラリで生成した Deck オブジェクトを、st.pydeck_chart の引数に与えることで、ロードした地理データを Streamlit アプリケーション上に地図表示できます。

以下はサンプルコードです。
import pydeck
import streamlit as st
def _build_scatter_layer(df: pd.DataFrame) -> pydeck.Layer:
"""Build ScatterplotLayer."""
return pydeck.Layer(
"ScatterplotLayer",
data=df,
get_position=["LONGITUDE", "LATITUDE"],
...
)
def main():
SQL_PLACES = f"""
SELECT
osm_id, name, type,
ST_X(ST_CENTROID(geography)) AS longitude,
ST_Y(ST_CENTROID(geography)) AS latitude,
FROM {TABLE_PLACES}
WHERE type IN ('city', 'island', 'country', 'airport')
"""
df_places = session.sql(SQL_PLACES).to_pandas()
view_state = pydeck.ViewState(latitude=ini_lat, longitude=ini_lon, ...)
deck = pydeck.Deck(
initial_view_state=view_state,
layers=[
_build_scatter_layer(df_places),
_build_icon_layer(df_places, ...),
...
],
tooltip={...}
)
st.pydeck_chart(deck, key="home_map")
Deck オブジェクト生成時に指定可能な引数として、以下のようなものがあります。
-
initial_view_state... 地図表示の初期状態 -
layers... 地図に重ねる地理データ Layer オブジェクトのリスト -
tooltip... デザインやマウス Hover 時の挙動などの設定
Layer オブジェクト生成時に地理データを与えます。ScatterplotLayer や IconLayer など、様々な表示形式があります。これにより、複数レイヤーからなる様々な地図表示を実現できます。
地理空間関数を使ってみる
Snowflake には様々な 地理空間関数 が存在します。
例えば、2 地点間の距離を計算する関数として ST_DISTANCE があります。
-- 例)サンフランシスコ (A) とベルリン (B) の距離を計算する
SELECT
ST_DISTANCE(
ST_MAKEPOINT(-121.8212, 36.8252), -- (A)
ST_MAKEPOINT(13.4814, 52.5015) -- (B)
) / 1000 AS d_km_st,
HAVERSINE(
36.8252, -121.8212, -- (A)
52.5015, 13.481 -- (B)
) AS d_km_haversine,
;
-- d_km_st: 9182.410992278
-- d_km_haversine: 9182.396579476
最寄り駅検索
以下は ST_DISTANCE 関数を用いて、選択した地点の最寄り駅を検索するアプリケーションです。選択した地点と各駅との距離を計算し、上位 N 件を出力しています。

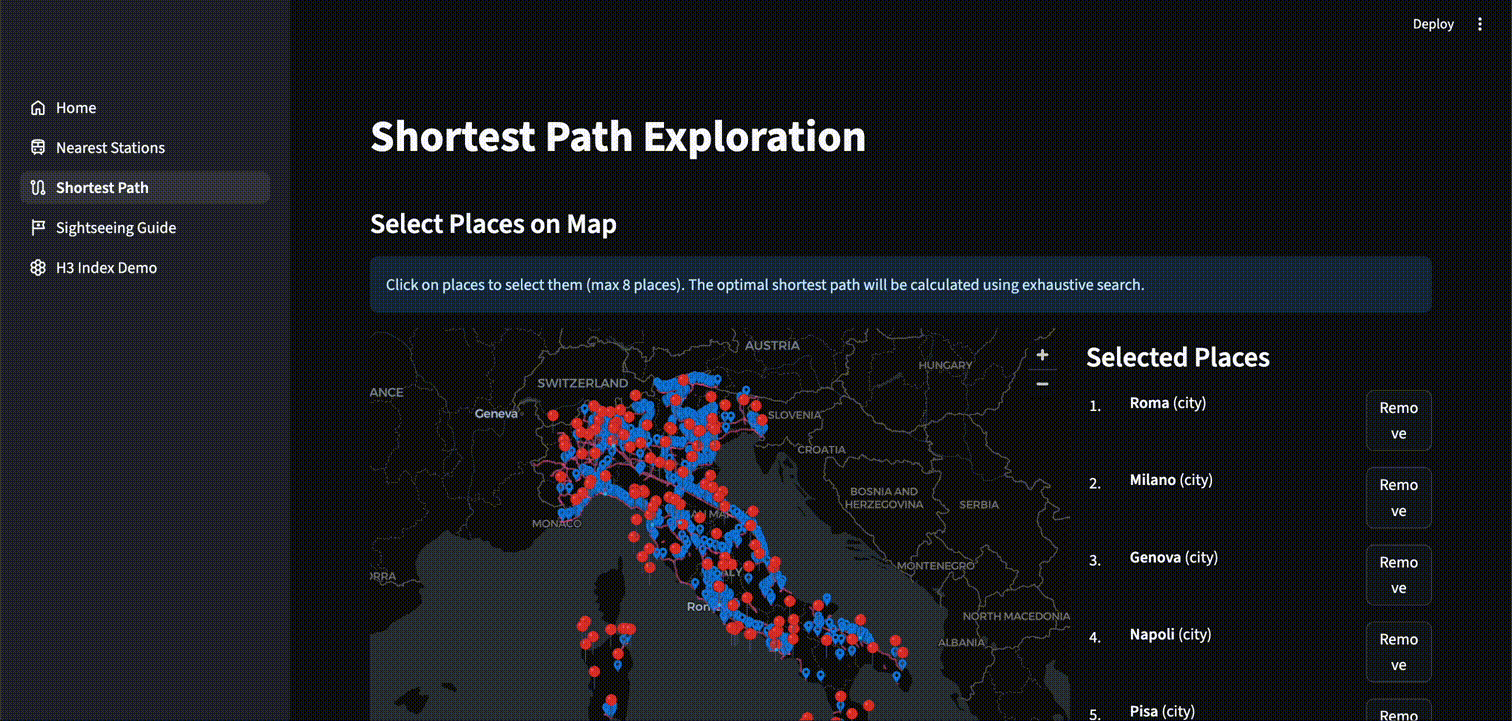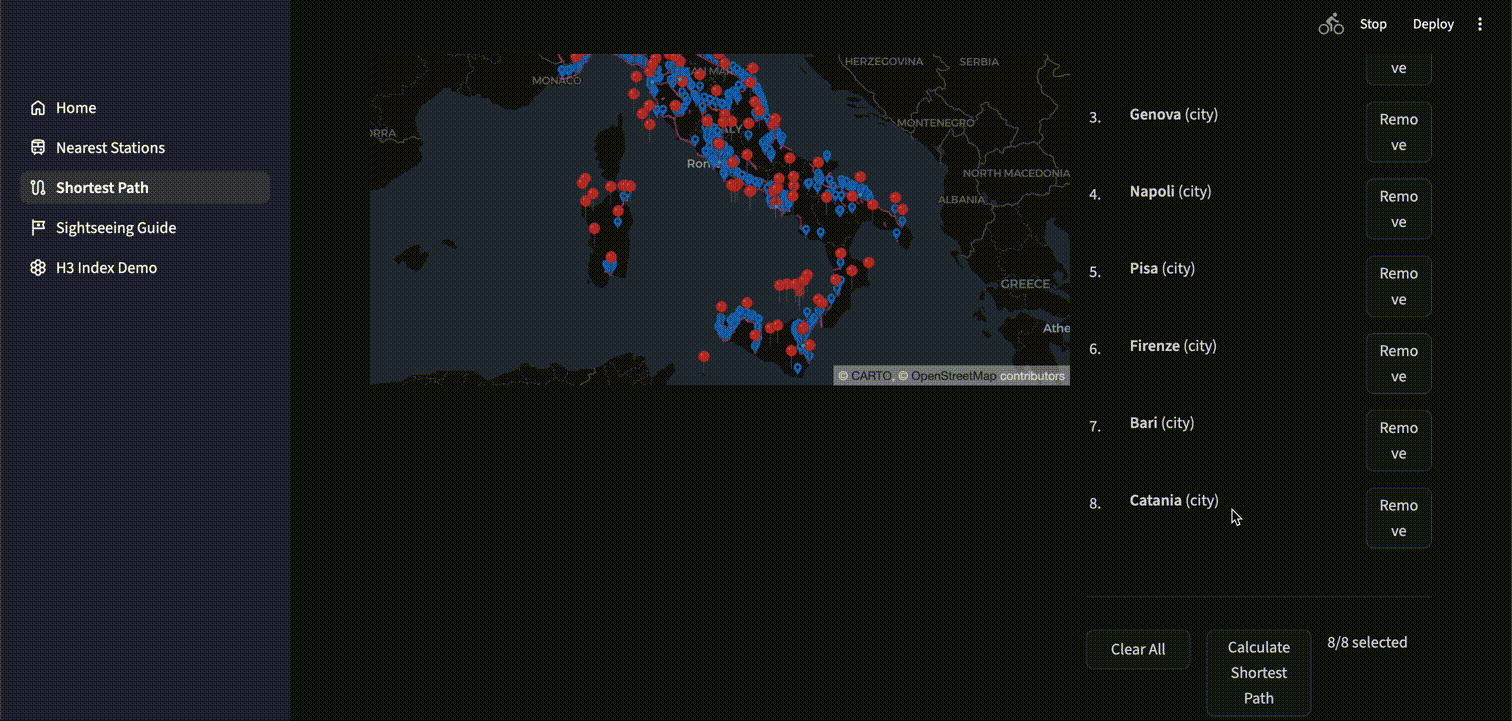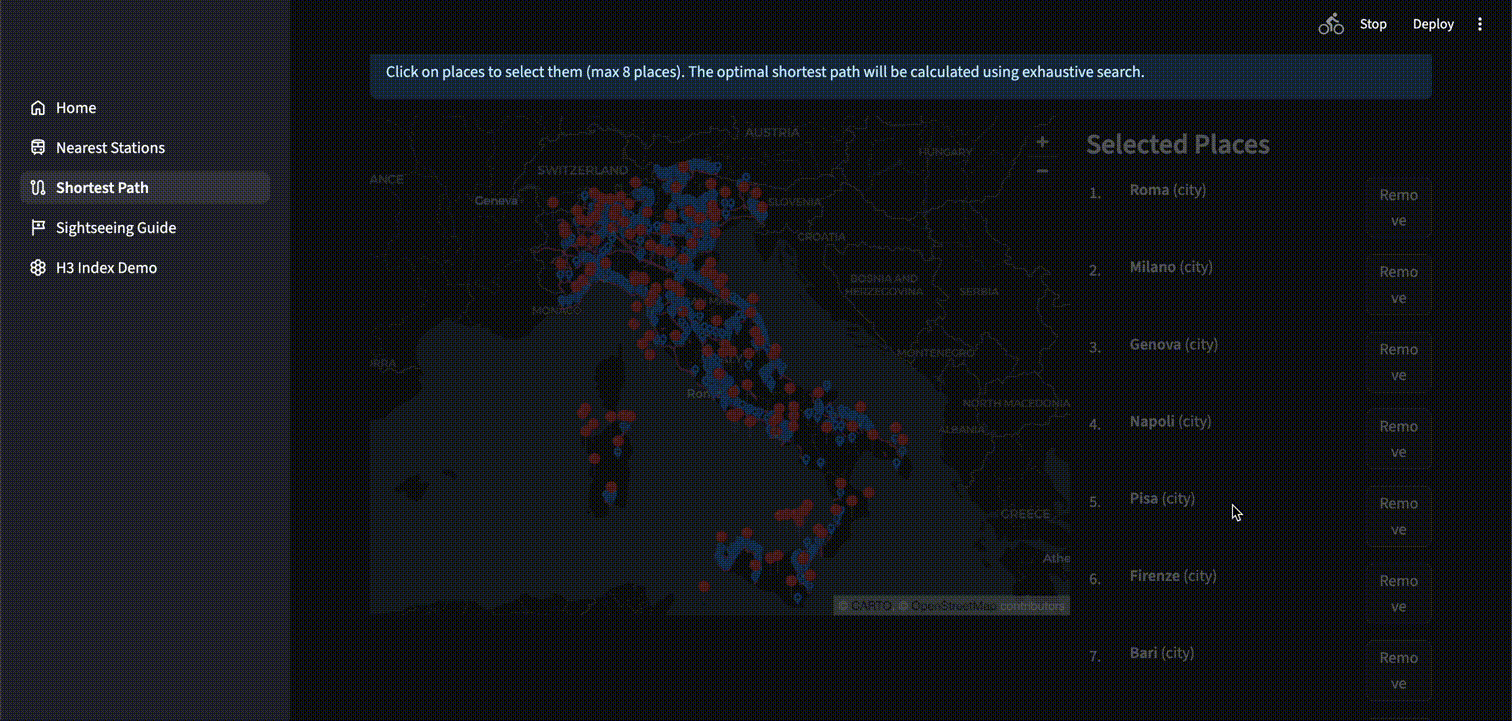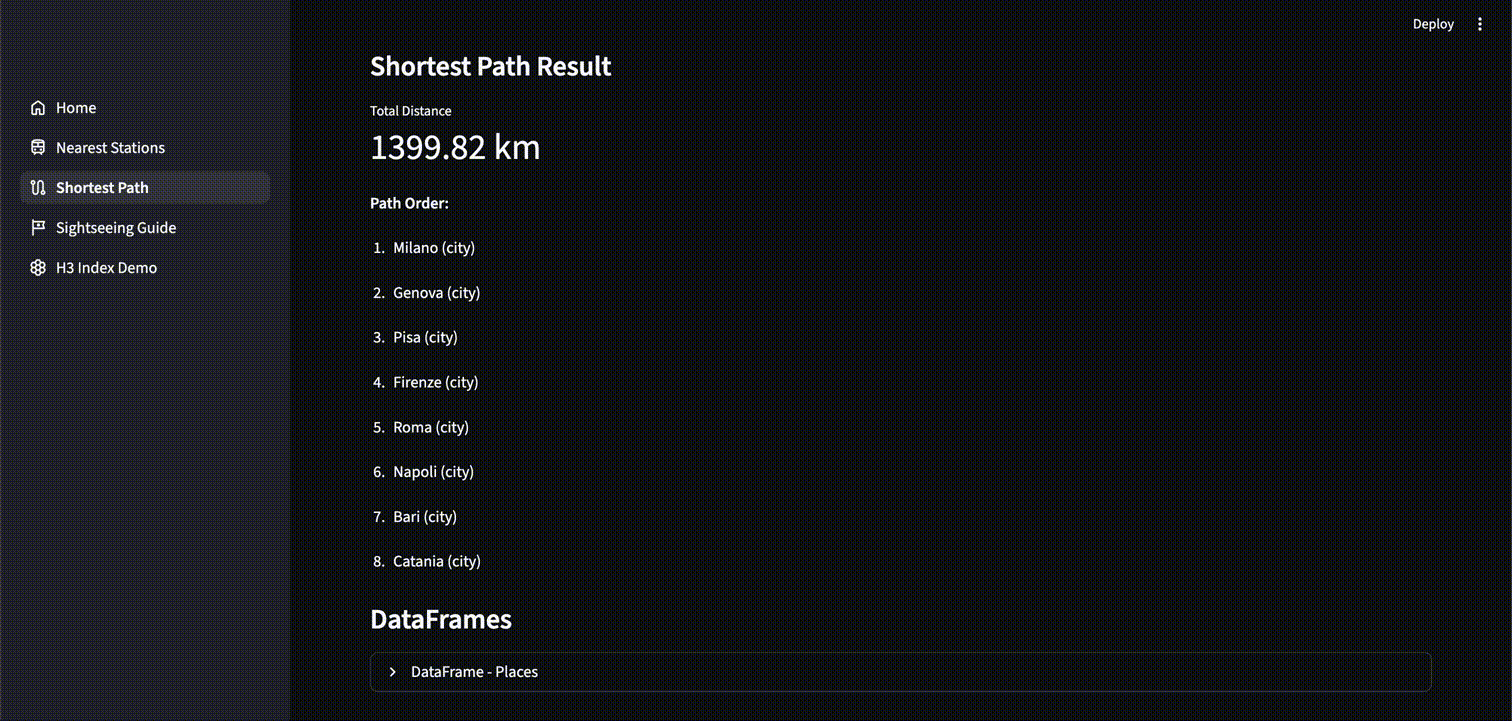
最短経路探索
以下は選択した複数地点を全て一回ずつ巡回する最短経路を特定するアプリケーションです。同じく ST_DISTANCE を使用し、全経路の組合せから最短距離のものを出力・表示しています。
COMPLETE 関数を用いた観光ガイド生成(おまけ)
地理空間データ分析とは関係ありませんが、選択した地点の観光ガイドを生成するアプリケーションを作成してみました。言語は日本語・英語・イタリア語から選択可能です。

Snowflake の COMPLETE 関数を使用しています。Markdown 形式出力したものを st.markdown で出力しています。サンプル Prompt も以下に掲載しておきます。
sql = f"""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'{model_id}',
'{prompt.replace("'", "''")}'
) AS tourism_guide
"""
サンプル Prompt
prompt = f"""Write a comprehensive tourism guide for {place_name}, a {place_type} in Italy.
IMPORTANT:
- Write the entire guide in {language_name}
- Format the output in Markdown for better readability
- Use proper Markdown formatting: headers (##, ###), bold (**text**), lists (- item), etc.
Include the following sections with Markdown headers:
### Overview
Brief introduction and historical significance
### Main Attractions
Top sights and landmarks to visit (use bullet points with - )
### Cultural Highlights
Museums, galleries, and cultural venues (use bullet points with - )
### Local Cuisine
Famous dishes and recommended restaurants (use bullet points with - )
### Best Time to Visit
Seasonal recommendations
### Travel Tips
Practical advice for tourists (use bullet points with - )
Keep the tone informative and engaging. {length_constraint}
Remember: The entire response must be written in {language_name} and properly formatted in Markdown."""
H3 Index を使ってみる
H3 とは
H3 は、Uber が開発した 地理空間を階層的な六角形グリッドで分割するためのオープンソースのインデックスシステムです。地球上の位置(緯度・経度)を、一意のセル ID (H3 Index) に変換できるため、空間分析やクラスタリング等に幅広く使われています。
また、以下の記事のように H3 Index を使用して検索クエリの実行を高速化することもできます。
Snowflake では、H3 関連の関数として例えば以下のようなものが提供されています。
| 関数名 | 概要 |
|---|---|
| H3_POINT_TO_CELL | 指定された H3 Resolution における GEOGRAPHY オブジェクトの H3 セル ID を INTEGER 型で返す |
| H3_CELL_TO_BOUNDARY | 指定された H3 セル ID に該当するグリッドのセル境界を GEOGRAPHY オブジェクトとして返す |
H3 Resolution
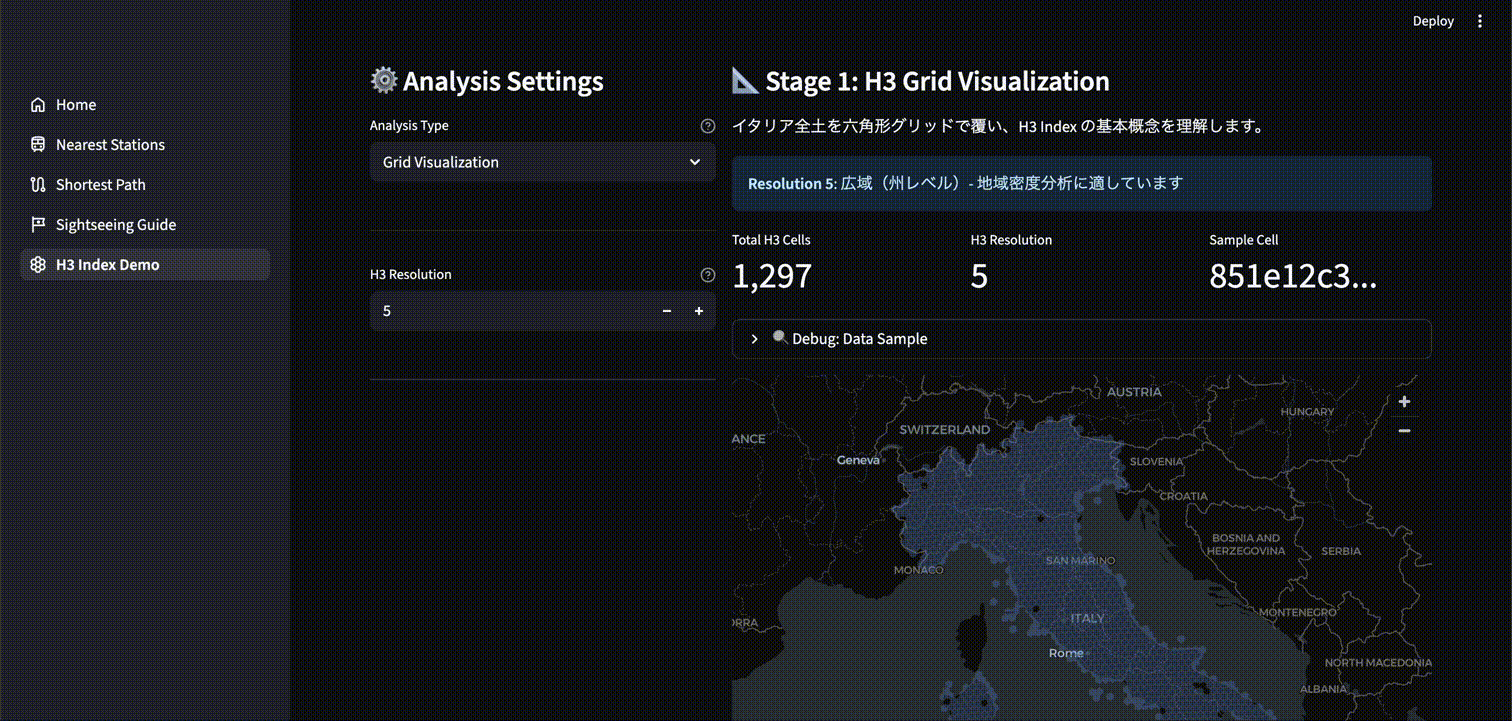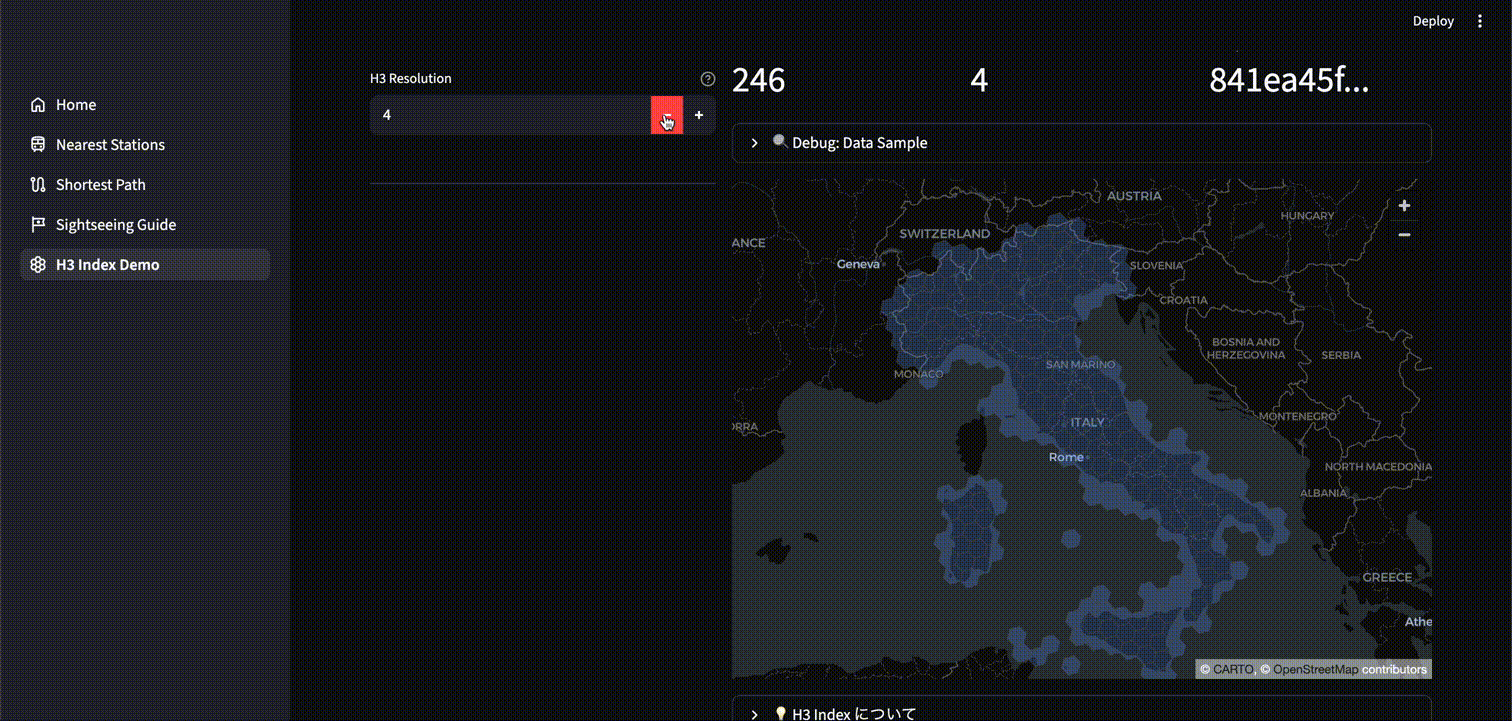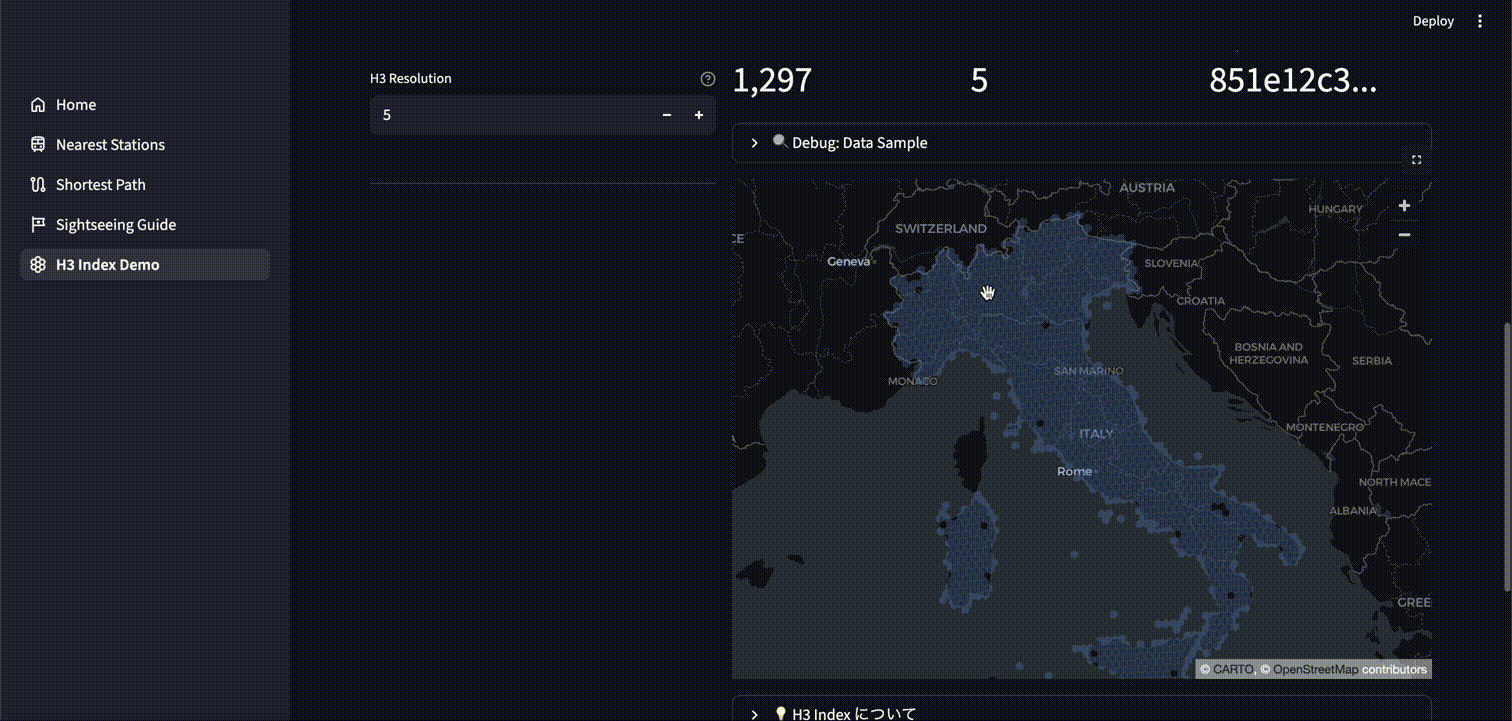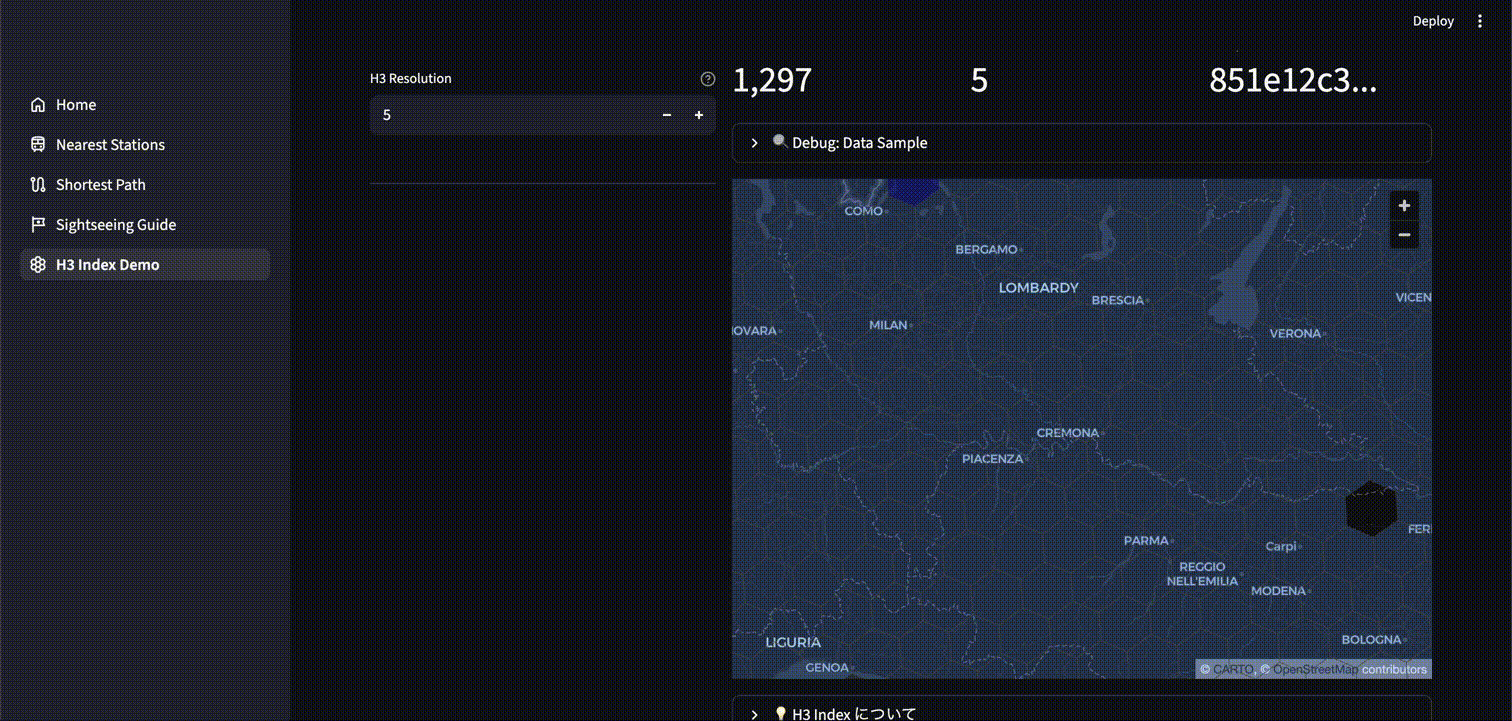
H3 では H3 Resolution というパラメータがあります。0~15 の整数で指定し、数が大きいほどよりグリッドが細かくなります。
以下は、H3 Resolution を調整したときのグリッド変化を可視化するアプリケーションです。各セルに一意の ID が割り当てられていることが分かります。
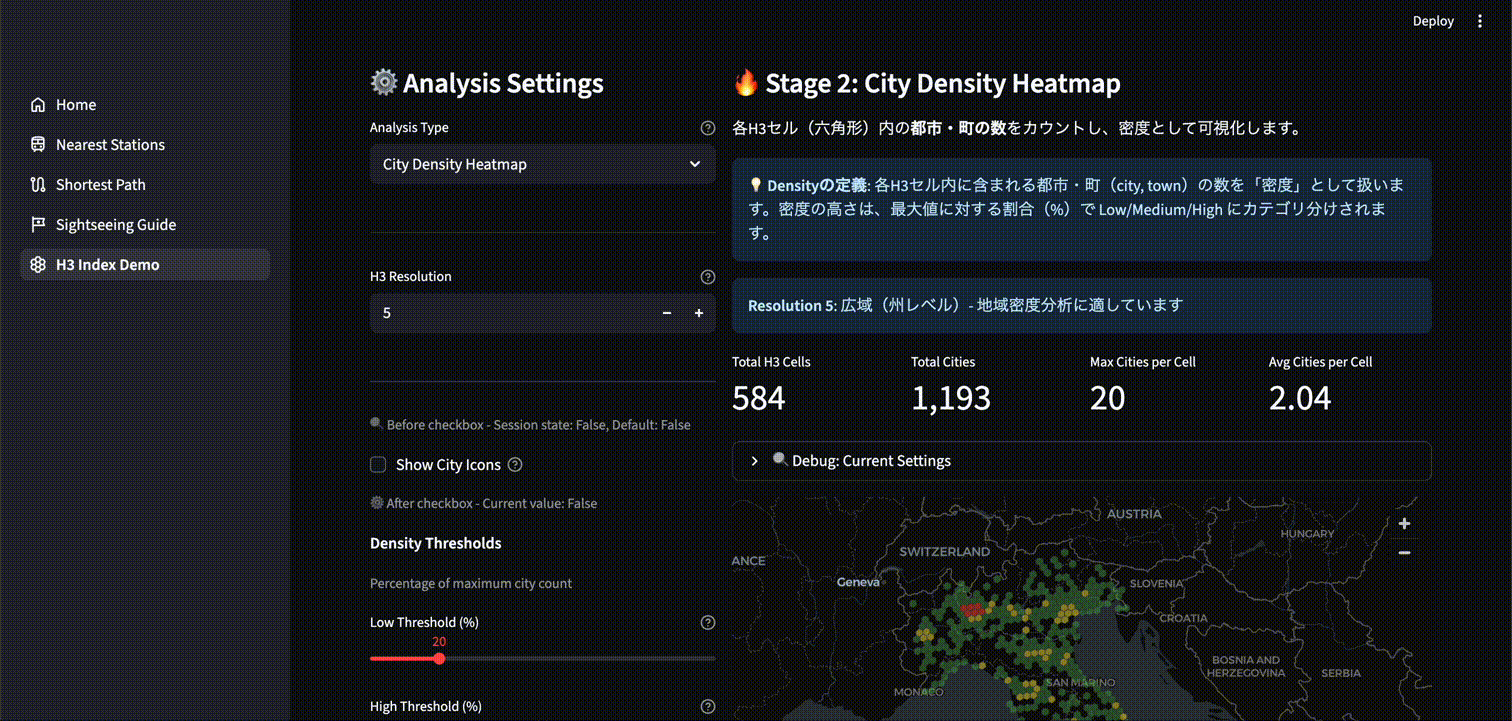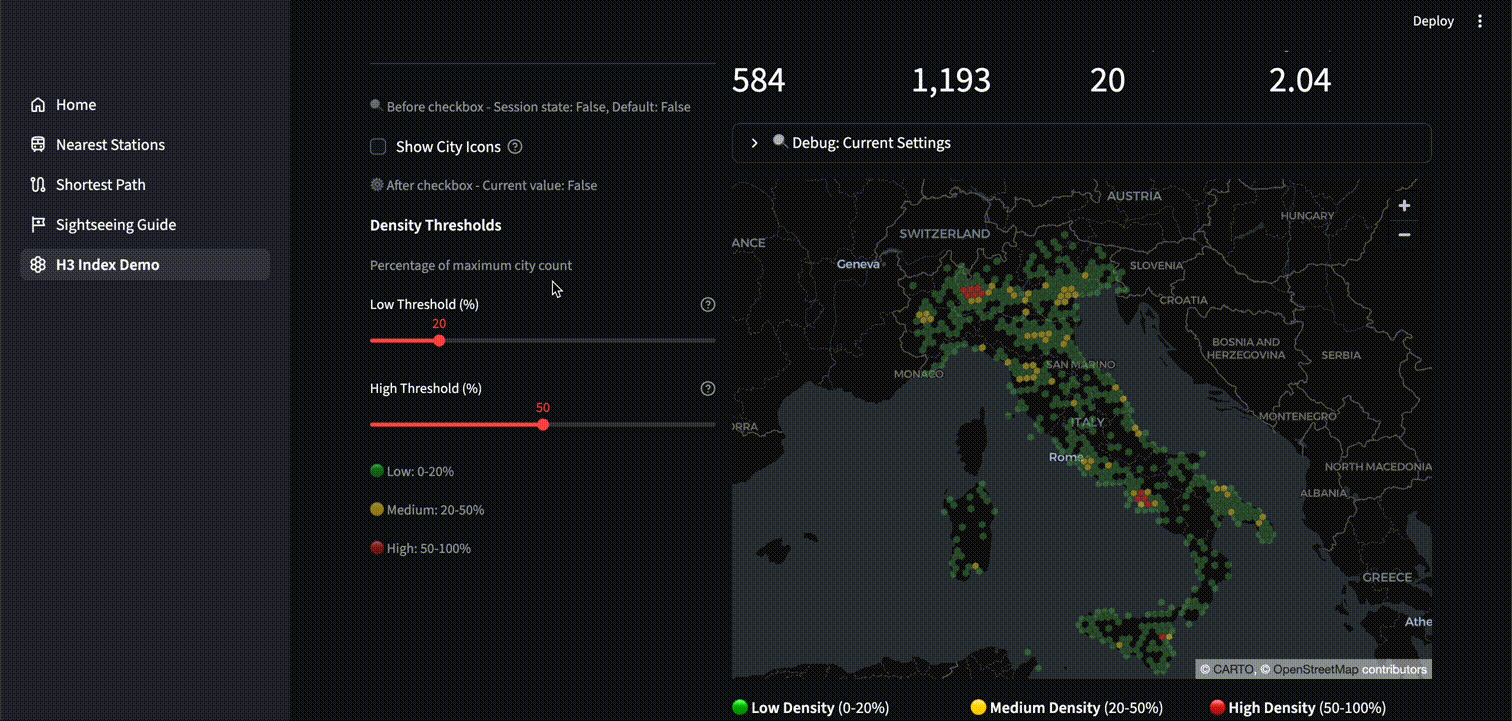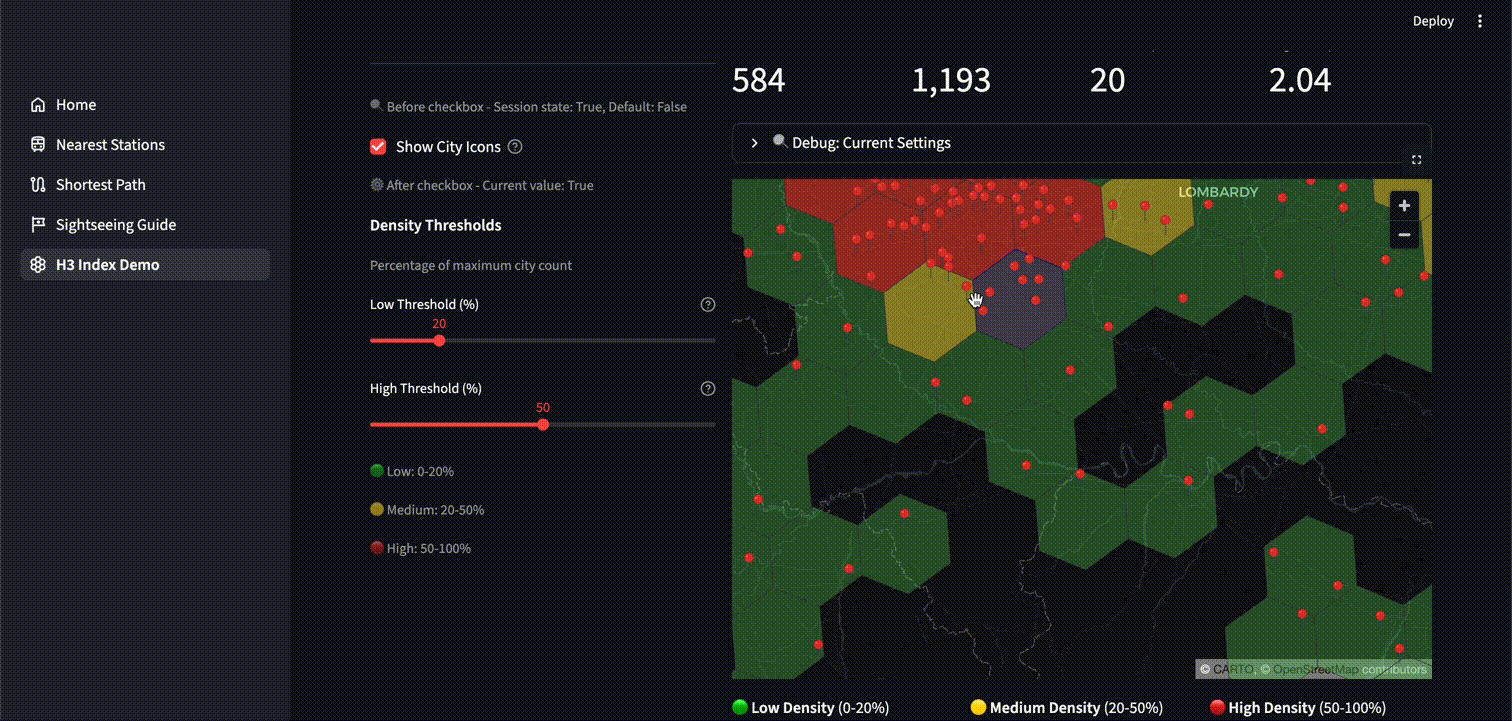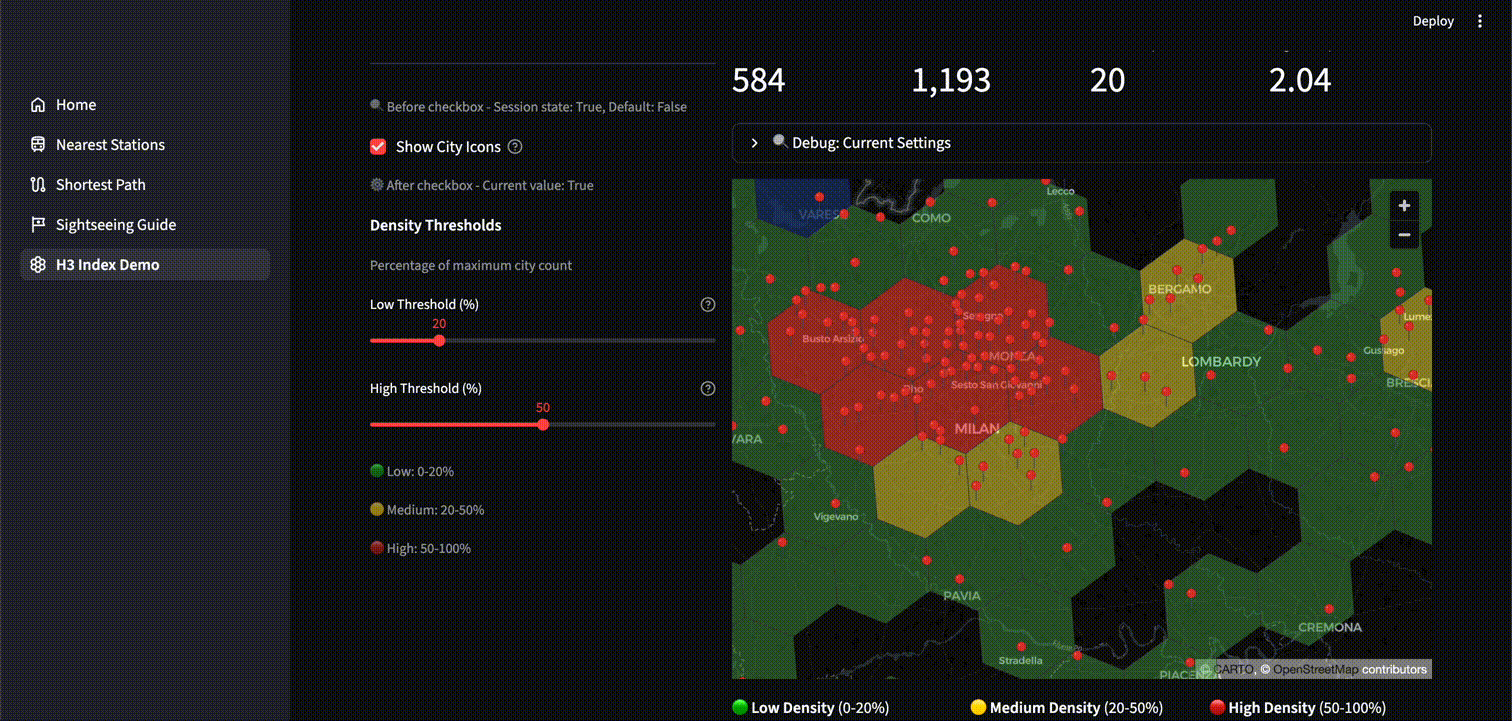
空間分析
以下は、空間分析の例として市 (City) の密度ヒートマップを表示するアプリケーションです。アイコンを表示してみると、確かに赤や黄のセルの位置に多くの市が集中していることが分かります。
さいごに
今回の Frosty Friday Live Challenge 出演を通して、個人的には地理空間データを初めてちゃんと触れる機会となりました。知らないことばかりでキャッチアップは大変でしたが、その分学ぶものが多く参加できてとても良かったと思います。出演の際は、敢えて馴染みのないトピックを選んでみるのも醍醐味かもしれません。
同じ回で出演された Mukaiyama さんの Week 78 - Basic, Session Variables の解説もとても勉強になりました。様々なレベルのお題が用意されていますので、出演されたことがない方も是非一度トライしてみてはいかがでしょうか。
最後まで読んでいただき、ありがとうございました。

Snowflake データクラウドのユーザ会 SnowVillage のメンバーで運営しています。 Publication参加方法はこちらをご参照ください。 zenn.dev/dataheroes/articles/db5da0959b4bdd
Discussion